Speech impairments affect millions of people, with underlying causes ranging from neurological or genetic conditions to physical impairment, brain damage or hearing loss. Similarly, the resulting speech patterns are diverse, including stuttering, dysarthria, apraxia, etc., and can have a detrimental impact on self-expression, participation in society and access to voice-enabled technologies. Automatic speech recognition (ASR) technologies have the potential to help individuals with such speech impairments by improving access to dictation and home automation and by enhancing communication. However, while the increased computational power of deep learning systems and the availability of large training datasets has improved the accuracy of ASR systems, their performance is still insufficient for many people with speech disorders, rendering the technology unusable for many of the speakers who could benefit the most.
In 2019, we introduced Project Euphonia and discussed how we could use personalized ASR models of disordered speech to achieve accuracies on par with non-personalized ASR on typical speech. Today we share the results of two studies, presented at Interspeech 2021, that aim to expand the availability of personalized ASR models to more users. In “Disordered Speech Data Collection: Lessons Learned at 1 Million Utterances from Project Euphonia”, we present a greatly expanded collection of disordered speech data, composed of over 1 million utterances. Then, in “Automatic Speech Recognition of Disordered Speech: Personalized models outperforming human listeners on short phrases”, we discuss our efforts to generate personalized ASR models based on this corpus. This approach leads to highly accurate models that can achieve up to 85% improvement to the word error rate in select domains compared to out-of-the-box speech models trained on typical speech.
Impaired Speech Data Collection
Since 2019, speakers with speech impairments of varying degrees of severity across a variety of conditions have provided voice samples to support Project Euphonia’s research mission. This effort has grown Euphonia’s corpus to over 1 million utterances, comprising over 1400 hours from 1330 speakers (as of August 2021).
 |
 |
| Distribution of severity of speech disorder and condition across all speakers with more than 300 utterances recorded. For conditions, only those with > 5 speakers are shown (all others aggregated into “OTHER” for k-anonymity). ALS = amyotrophic lateral sclerosis; DS = Down syndrome; PD = Parkinson’s disease; CP = cerebral palsy; HI = hearing impaired; MD = muscular dystrophy; MS = multiple sclerosis |
To simplify the data collection, participants used an at-home recording system on their personal hardware (laptop or phone, with and without headphones), instead of an idealized lab-based setting that would collect studio quality recordings.
To reduce transcription cost, while still maintaining high transcript conformity, we prioritized scripted speech. Participants read prompts shown on a browser-based recording tool. Phrase prompts covered use-cases like home automation (“Turn on the TV.”), caregiver conversations (“I am hungry.”) and informal conversations (“How are you doing? Did you have a nice day?”). Most participants received a list of 1500 phrases, which included 1100 unique phrases along with 100 phrases that were each repeated four more times.
Speech professionals conducted a comprehensive auditory-perceptual speech assessment while listening to a subset of utterances for every speaker providing the following speaker-level metadata: speech disorder type (e.g., stuttering, dysarthria, apraxia), rating of 24 features of abnormal speech (e.g., hypernasality, articulatory imprecision, dysprosody), as well as recording quality assessments of both technical (e.g., signal dropouts, segmentation problems) and acoustic (e.g., environmental noise, secondary speaker crosstalk) features.
Personalized ASR Models
This expanded impaired speech dataset is the foundation of our new approach to personalized ASR models for disordered speech. Each personalized model uses a standard end-to-end, RNN-Transducer (RNN-T) ASR model that is fine-tuned using data from the target speaker only.
 |
| Architecture of RNN-Transducer. In our case, the encoder network consists of 8 layers and the predictor network consists of 2 layers of uni-directional LSTM cells. |
To accomplish this, we focus on adapting the encoder network, i.e. the part of the model dealing with the specific acoustics of a given speaker, as speech sound disorders were most common in our corpus. We found that only updating the bottom five (out of eight) encoder layers while freezing the top three encoder layers (as well as the joint layer and decoder layers) led to the best results and effectively avoided overfitting. To make these models more robust against background noise and other acoustic effects, we employ a configuration of SpecAugment specifically tuned to the prevailing characteristics of disordered speech. Further, we found that the choice of the pre-trained base model was critical. A base model trained on a large and diverse corpus of typical speech (multiple domains and acoustic conditions) proved to work best for our scenario.
Results
We trained personalized ASR models for ~430 speakers who recorded at least 300 utterances. 10% of utterances were held out as a test set (with no phrase overlap) on which we calculated the word error rate (WER) for the personalized model and the unadapted base model.
Overall, our personalization approach yields significant improvements across all severity levels and conditions. Even for severely impaired speech, the median WER for short phrases from the home automation domain dropped from around 89% to 13%. Substantial accuracy improvements were also seen across other domains such as conversational and caregiver.
 |
| WER of unadapted and personalized ASR models on home automation phrases. |
To understand when personalization does not work well, we analyzed several subgroups:
- HighWER and LowWER: Speakers with high and low personalized model WERs based on the 1st and 5th quintiles of the WER distribution.
- SurpHighWER: Speakers with a surprisingly high WER (participants with typical speech or mild speech impairment of the HighWER group).
Different pathologies and speech disorder presentations are expected to impact ASR non-uniformly. The distribution of speech disorder types within the HighWER group indicates that dysarthria due to cerebral palsy was particularly difficult to model. Not surprisingly, median severity was also higher in this group.
To identify the speaker-specific and technical factors that impact ASR accuracy, we examined the differences (Cohen’s D) in the metadata between the participants that had poor (HighWER) and excellent (LowWER) ASR performance. As expected, overall speech severity was significantly lower in the LowWER group than in the HighWER group (p < 0.01). Intelligibility and severity were the most prominent atypical speech features in the HighWER group; however, other speech features also emerged, including abnormal prosody, articulation, and phonation. These speech features are known to degrade overall speech intelligibility.
The SurpHighWER group had fewer training utterances and lower SNR compared with the LowWER group (p < 0.01) resulting in large (negative) effect sizes, with all other factors having small effect sizes, except fastness. In contrast, the HighWER group exhibited medium to large differences across all factors.
 |
| Speech disorder and technical metadata effect sizes for the HighWER-vs-LowWER and SurpHighWER-vs-LowWER pairs. Positive effects indicated that the group values of the HighWER group were greater than LowWER groups. |
We then compared personalized ASR models to human listeners. Three speech professionals independently transcribed 30 utterances per speaker. We found that WERs were, on average, lower for personalized ASR models compared to the WERs of human listeners, with gains increasing by severity.
 |
| Delta between the WERs of the personalized ASR models and the human listeners. Negative values indicate that personalized ASR performs better than human (expert) listeners. |
Conclusions
With over 1 million utterances, Euphonia’s corpus is one of the largest and most diversely disordered speech corpora (in terms of disorder types and severities) and has enabled significant advances in ASR accuracy for these types of atypical speech. Our results demonstrate the efficacy of personalized ASR models for recognizing a wide range of speech impairments and severities, with potential for making ASR available to a wider population of users.
Acknowledgements
Key contributors to this project include Michael Brenner, Julie Cattiau, Richard Cave, Jordan Green, Rus Heywood, Pan-Pan Jiang, Anton Kast, Marilyn Ladewig, Bob MacDonald, Phil Nelson, Katie Seaver, Jimmy Tobin, and Katrin Tomanek. We gratefully acknowledge the support Project Euphonia received from members of many speech research teams across Google, including Françoise Beaufays, Fadi Biadsy, Dotan Emanuel, Khe Chai Sim, Pedro Moreno Mengibar, Arun Narayanan, Hasim Sak, Suzan Schwartz, Joel Shor, and many others. And most importantly, we wanted to say a huge thank you to the over 1300 participants who recorded speech samples and the many advocacy groups who helped us connect with these participants.

 From award-winning research demos to photorealistic graphics created with NVIDIA RTX and Omniverse, see how NVIDIA is breaking boundaries in AI, graphics, and virtual collaboration.
From award-winning research demos to photorealistic graphics created with NVIDIA RTX and Omniverse, see how NVIDIA is breaking boundaries in AI, graphics, and virtual collaboration.  Sign up for webinars with NVIDIA experts and Metropolis partners on Sept. 22, featuring developer SDKs, GPUs, go-to-market opportunities, and more.
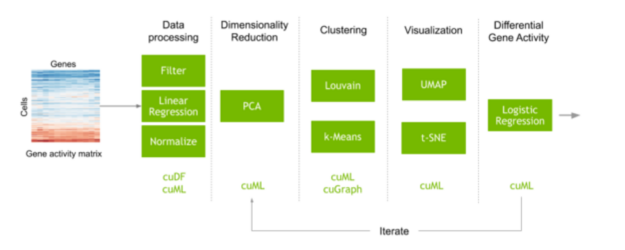
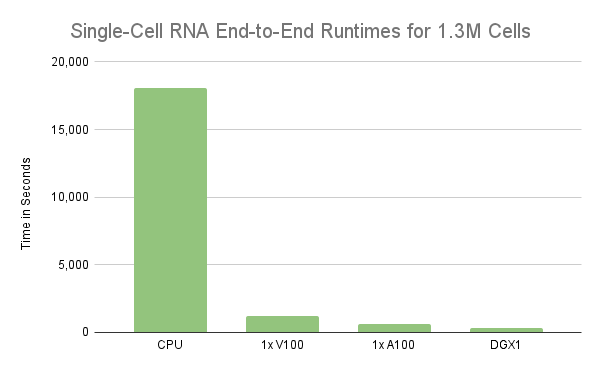
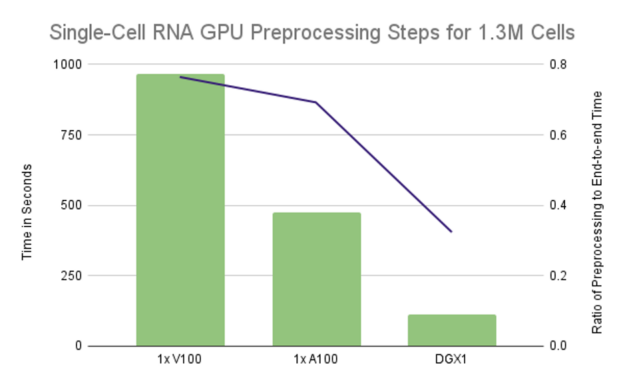
Sign up for webinars with NVIDIA experts and Metropolis partners on Sept. 22, featuring developer SDKs, GPUs, go-to-market opportunities, and more.  Learn how the use of RAPIDS to accelerate the analysis of single-cell RNA-sequence on a single NVIDIA V100 GPU shows a massive performance increase.
Learn how the use of RAPIDS to accelerate the analysis of single-cell RNA-sequence on a single NVIDIA V100 GPU shows a massive performance increase.