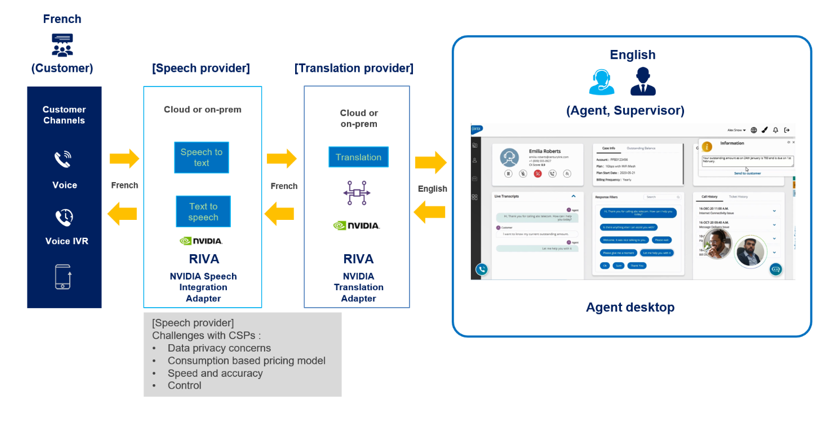
Embedded edge AI is transforming industrial environments by introducing intelligence and real-time processing to even the most challenging settings. Edge AI is…
Embedded edge AI is transforming industrial environments by introducing intelligence and real-time processing to even the most challenging settings. Edge AI is…
Embedded edge AI is transforming industrial environments by introducing intelligence and real-time processing to even the most challenging settings. Edge AI is increasingly being used in agriculture, construction, energy, aerospace, satellites, the public sector, and more. With the NVIDIA Jetson edge AI and robotics platform, you can deploy AI and compute for sensor fusion in these complex environments.
At COMPUTEX 2023, NVIDIA announced the new Jetson AGX Orin Industrial module, which brings the next level of computing to harsh environments. This new module extends the capabilities of the previous-generation NVIDIA Jetson AGX Xavier Industrial and the commercial Jetson AGX Orin modules, by bringing server-class performance to ruggedized systems.
Embedded edge in ruggedized applications
Many applications—including those designed for agriculture, industrial manufacturing, mining, construction, and transportation—must withstand extreme environments and extended shocks and vibrations.
For example, robust hardware is vital for a wide range of agriculture applications, as it enables machinery to endure heavy workloads, navigate challenging bumpy terrains, and operate continuously under varying temperatures. NVIDIA Jetson modules have transformed smart farming, powering autonomous tractors and intelligent systems for harvesting, weeding, and selective spraying.
In railway applications, trains generate vibrations when traveling at high speeds. The interaction between a train’s wheels and the rails also leads to additional intermittent vibrations and shocks. Transportation companies are using Jetson for object detection, accident prevention, and optimizing maintenance costs.
Mining is another space where industrial requirements come into play. For example, Tage IDriver has launched a Jetson AGX Xavier Industrial-based vehicle, ground-cloud–coordinated, unmanned transportation solution for smart mines. The unmanned mining truck requires additional ruggedness for open-mine environments. The NVIDIA Jetson module has sensors such as LiDAR, cameras, and radar that enable the accurate perception needed in the harsh mining environment.
In near or outer space, where radiation levels pose significant challenges, the deployment of durable and radiation-tolerant modules is essential to ensure reliable and efficient operation. Many satellite companies are looking to deploy AI at the edge, but face challenges finding the right compute module.
Together, the European Space Agency and Barcelona Supercomputing Center have studied the effects of radiation on the Jetson AGX Xavier Industrial modules. For more information, see the Sources of Single Event Effects in the NVIDIA Xavier SoC Family under Proton Irradiation whitepaper. Their radiation data showcases that the Jetson AGX Xavier Industrial module combined with a rugged enclosure is a good candidate for high-performance computation in thermally constrained satellites deployed in both low-earth and geosynchronous orbits.
The Jetson modules are transforming many of these space applications, and NVIDIA Jetson AGX Orin Industrial extends these capabilities.
Introducing NVIDIA Jetson AGX Orin Industrial
The Jetson AGX Orin Industrial module delivers up to 248 TOPS of AI performance with power configurable between 15-75 W. It’s form-factor and pin-compatible with Jetson AGX Orin and gives you more than 8X the performance of Jetson AGX Xavier Industrial.
This compact system-on-module (SOM) supports multiple concurrent AI application pipelines with an NVIDIA Ampere architecture GPU, next-generation deep learning and vision accelerators, high-speed I/O, and fast memory bandwidth. It comes with an extended temperature range, operating lifetime, and shock and vibration specifications, as well as support for error correction code (ECC) memory.
Industrial applications under extreme heat or extreme cold require extended temperature support along with underfill and corner bonding to protect the module under these harsh environments. Inline DRAM ECC is required in these applications for data integrity and system reliability. Industrial environments involve critical operations and sensitive data processing. ECC helps to ensure data integrity by detecting and correcting errors in real time.
The following table lists the key new industrial features of the new Jetson AGX Orin Industrial SOM compared with Jetson AGX Orin 64GB module. For more information about the NVIDIA Jetson Orin architecture, see the Jetson AGX Orin Technical Brief and the Jetson Embedded Download Center.
| Jetson AGX Orin 64GB | Jetson AGX Orin Industrial | |
| AI Performance | 275 TOPS | 248 TOPS |
| Module | 2048-core NVIDIA Ampere architecture GPU with 64 Tensor Cores 12-core Arm Cortex A78AE CPU 64-GB LPDDR5 64-GB eMMC | 2048-core NVIDIA Ampere architecture GPU with 64 Tensor Cores 12-core Arm Cortex A78AE CPU 64-GB LPDDR5 with Inline ECC 64-GB eMMC |
| Operating Temperature | -25° C – 80° C at TTP | -40° C – 85° C at TTP |
| Module Power | 15–60 W | 15–75 W |
| Operating Lifetime | 5 years | 10 years 87K hours @ 85° C |
| Shock | Non-operational: 140G, 2 ms | Non-operational: 140G, 2 ms Operational: 50G, 11 ms |
| Vibration | Non-operational: 3G | Non-operational: 3G Operational: 5G |
| Humidity | Biased, 85°C, 85% RH, 168 hours | :85°C / 85% RH, 1,000 hours, Power ON |
| Temperature Endurance | -20°C, 24 hours 45°C, 168 hours (operational) | -40°C, 72 hours 85°C, 1000 hours (operational) |
| Mechanical | 100 mm x 87 mm | 100 mm x 87 mm |
| Underfill | ~ | SoC Corner Bonding & Component Underfill |
| Production Lifecycle | 7 years (until 2030) | 10 years (until 2033) |
Robust software and ecosystem support
Jetson AGX Orin Industrial is powered by the NVIDIA AI software stack, with tools and SDKs to accelerate each step of the development journey for time to market. It combines platforms like NVIDIA Isaac for robotics and NVIDIA Isaac Replicator for synthetic data generation powered by NVIDIA Omniverse; frameworks like NVIDIA Metropolis with DeepStream for intelligent video analytics and NVIDIA TAO Toolkit; and a large collection of pretrained and production-ready models. These all accelerate the process of model development and help you create fully hardware-accelerated AI applications.
SDKs like NVIDIA JetPack provide all the accelerated libraries in a powerful yet easy-to-use development environment to get started quickly with any Jetson module. NVIDIA JetPack also enables security features in the Jetson AGX Orin module to enable edge-to-cloud security and protect your deployments:
- Hardware root of trust
- Firmware TPM
- Secure boot and measured boot
- Hardware-accelerated cryptography
- Trusted execution environment
- Support for encrypted storage and memory
- And more
The vibrant Jetson ecosystem partners in the NVIDIA Partner network are integrating the industrial module into hardware and software solutions for industrial applications:
- Partner cameras enable computer vision tasks such as quality inspection.
- Connectivity partners facilitate data transfer with interfaces such as Ethernet.
- The sensor and connectivity partners with upcoming Jetson AGX Orin Industrial solutions include Silex, Infineon, Basler, e-con Systems, Leopard Imaging, FRAMOS, and D3.
- Hardware partners design carrier boards for industrial edge computing.
This collaborative effort enables you to deploy AI-enabled solutions for industrial automation, robotics, and more.
The following partners will have carrier boards and full systems with the Jetson AGX Orin Industrial module: Advantech, AVerMedia, Connect Tech, Forecr, Leetop, Realtimes, and Syslogic. For more information, see Jetson Ecosystem.
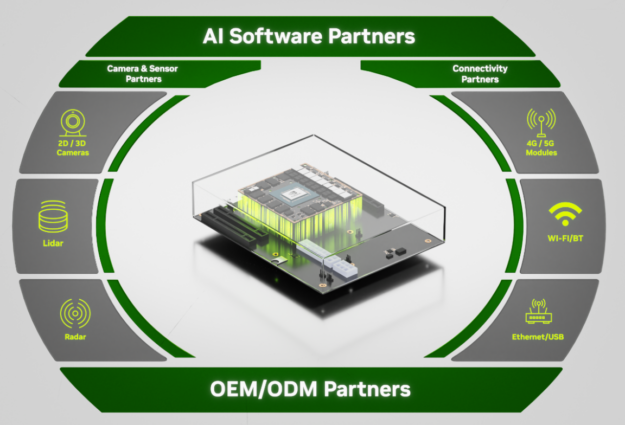
The new Jetson AGX Orin Industrial module will be available in July, and you can reach out to a distributor in your region to place an order now. Because Jetson AGX Orin Industrial and Jetson AGX Orin 64GB are pin– and software-compatible, you can start building solutions today with the Jetson AGX Orin Developer Kit and the latest JetPack.
For more information, see the NVIDIA Jetson AGX Orin Industrial documentation available at the Jetson download center, the NVIDIA Embedded Developer page, and the Jetson forums.
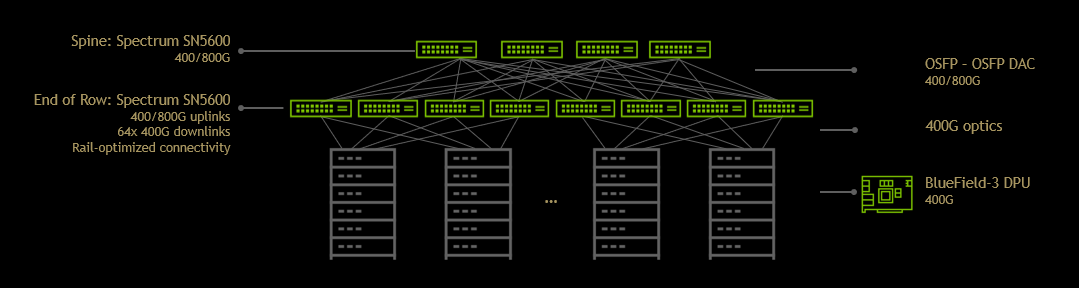
 Large Language Models (LLMs) and AI applications such as ChatGPT and DALL-E have recently seen rapid growth. Thanks to GPUs, CPUs, DPUs, high-speed storage, and…
Large Language Models (LLMs) and AI applications such as ChatGPT and DALL-E have recently seen rapid growth. Thanks to GPUs, CPUs, DPUs, high-speed storage, and…

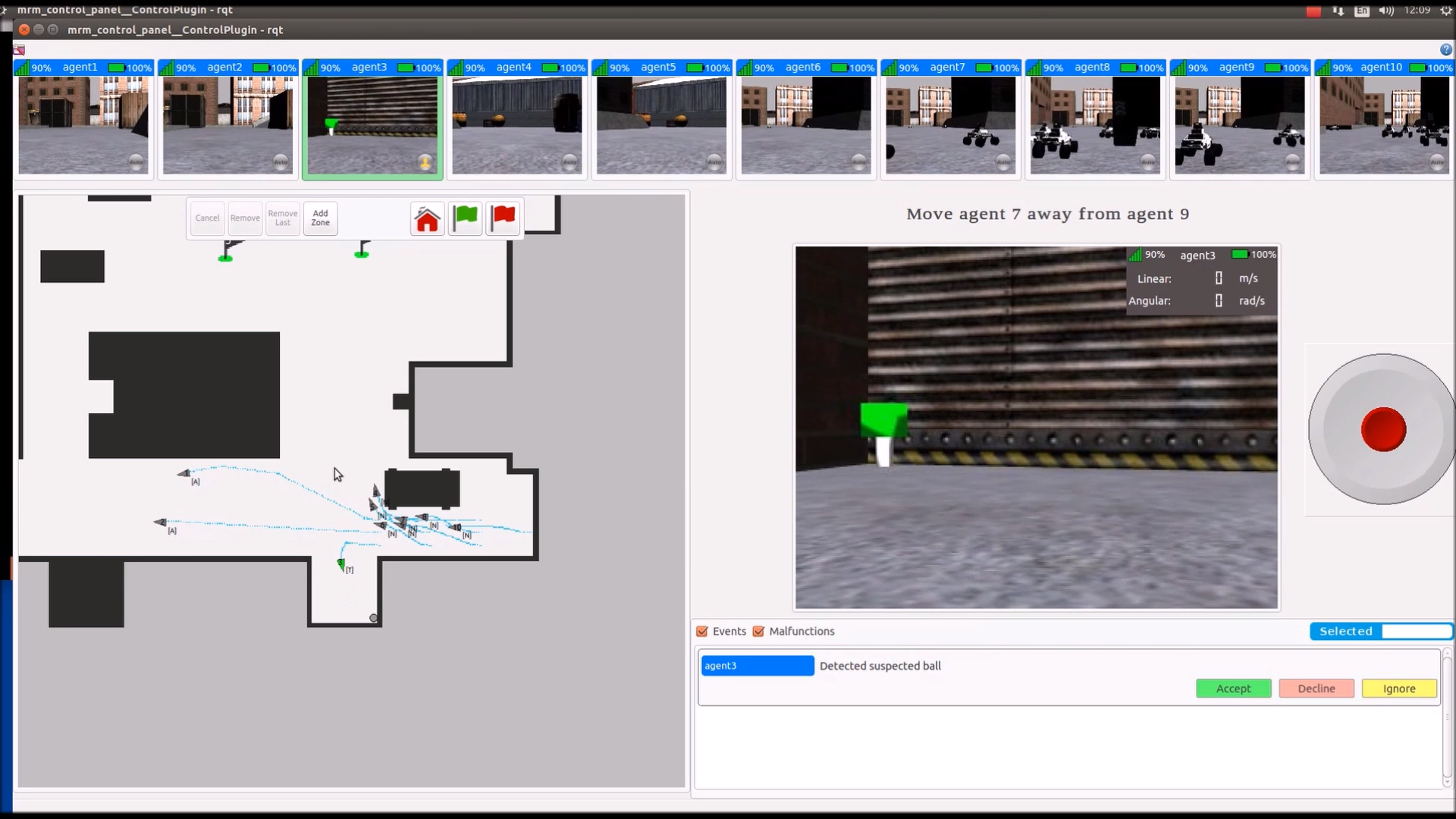
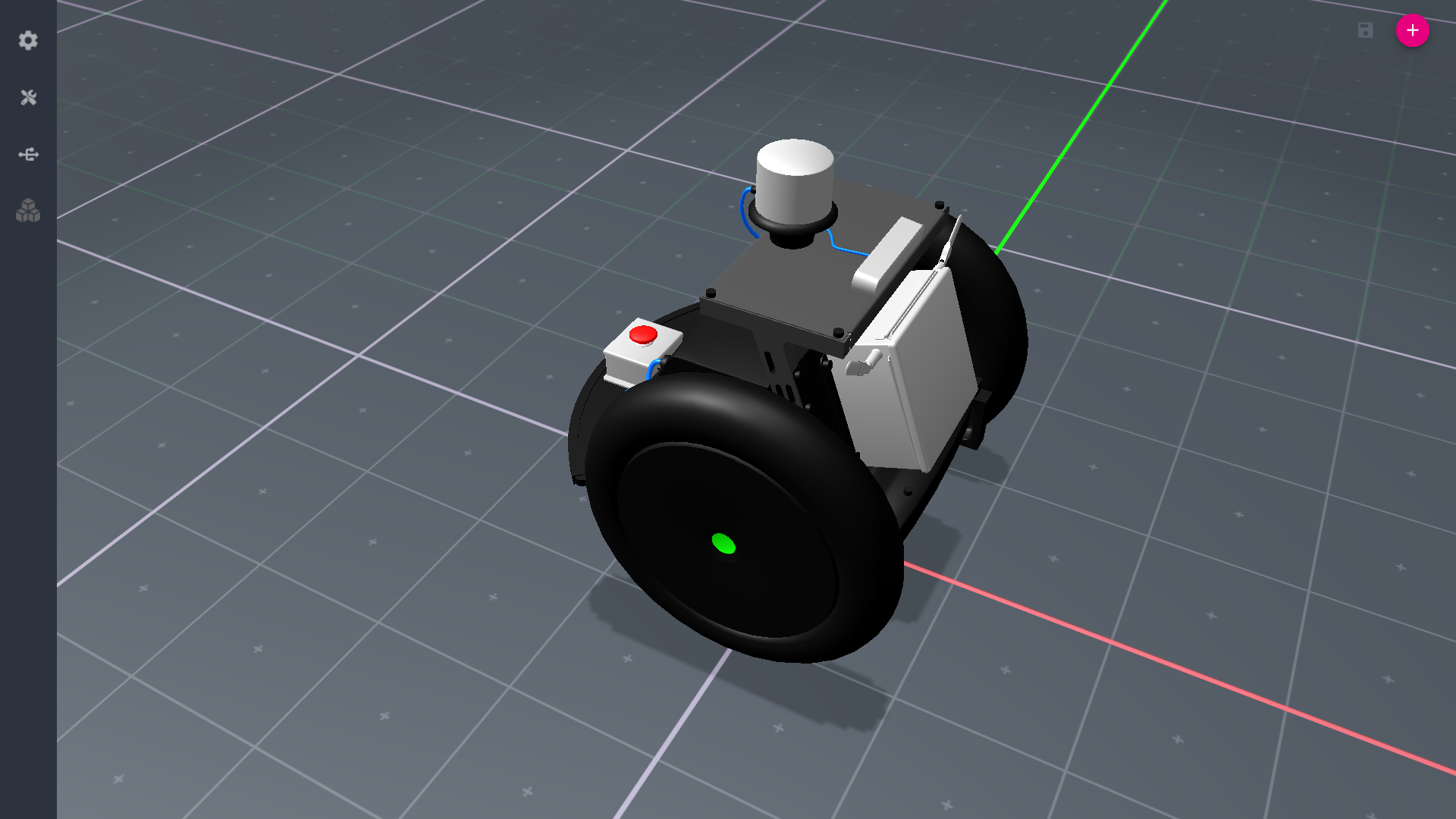
 The need for a high-fidelity multi-robot simulation environment is growing rapidly as more and more autonomous robots are being deployed in real-world…
The need for a high-fidelity multi-robot simulation environment is growing rapidly as more and more autonomous robots are being deployed in real-world…


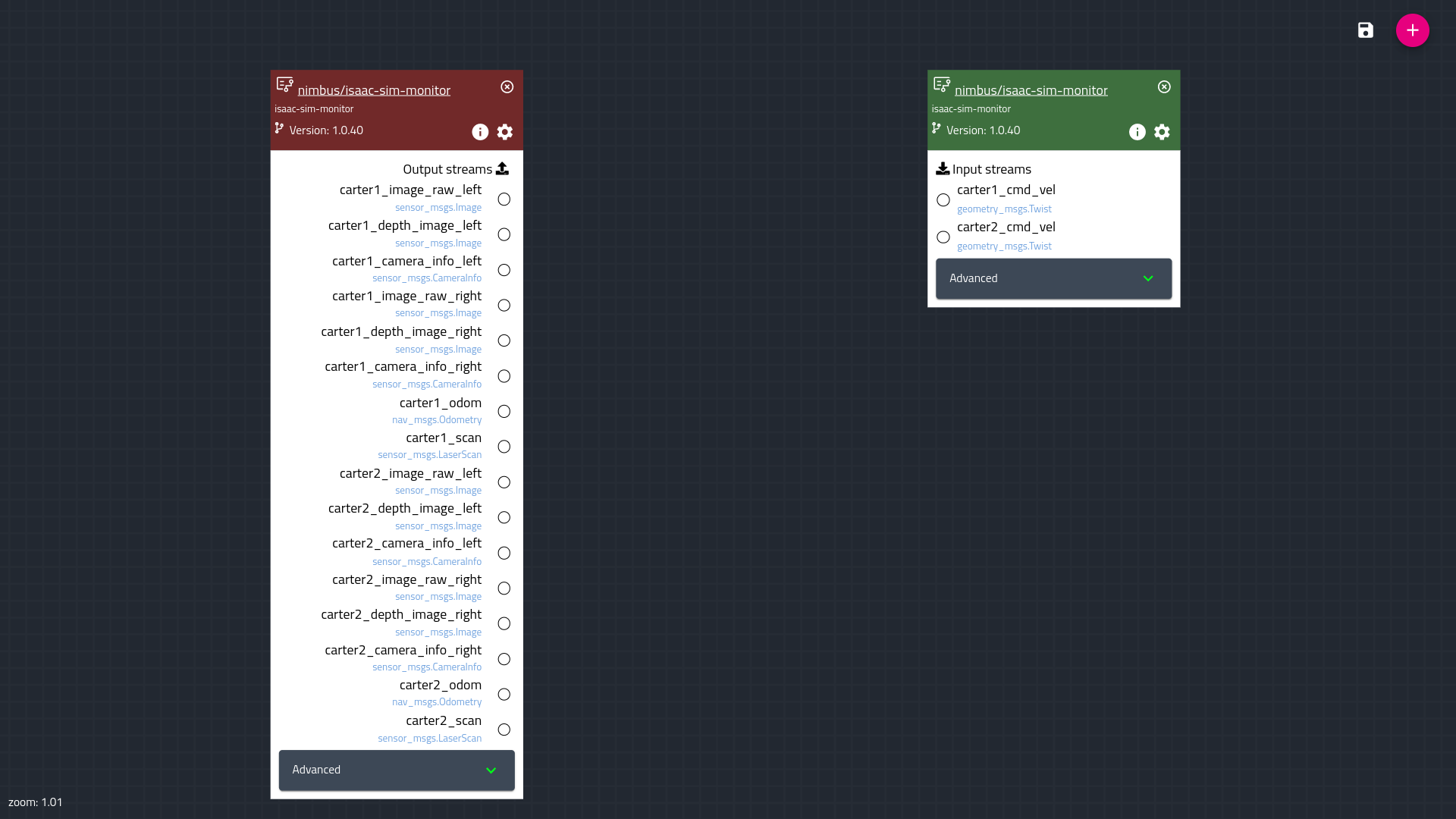
 The telecom sector is transforming how communication happens. Striving to provide reliable, uninterrupted service, businesses are tackling the challenge of…
The telecom sector is transforming how communication happens. Striving to provide reliable, uninterrupted service, businesses are tackling the challenge of…