Technology company CORSAIR and streaming partner BigCheeseKIT step In the NVIDIA Studio this week. A leader in high-performance gear and systems for gamers, content creators and PC enthusiasts, CORSAIR has integrated NVIDIA Broadcast technologies into its hardware and iCUE software. Similar AI enhancements have also been added to Elgato’s audio and video software, Wave Link and Camera Hub.
Australian animator Marko Matosevic is taking jokes from a children’s school dads’ group and breathing them into animated life with NVIDIA Omniverse, a virtual world simulation and collaboration platform for 3D workflows.
Posted by Dustin Tran and Balaji Lakshminarayanan, Research Scientists, Google Research
Deep learning models have made impressive progress in vision, language, and other modalities, particularly with the rise of large-scale pre-training. Such models are most accurate when applied to test data drawn from the same distribution as their training set. However, in practice, the data confronting models in real-world settings rarely match the training distribution. In addition, the models may not be well-suited for applications where predictive performance is only part of the equation. For models to be reliable in deployment, they must be able to accommodate shifts in data distribution and make useful decisions in a broad array of scenarios.
In “Plex: Towards Reliability Using Pre-trained Large Model Extensions”, we present a framework for reliable deep learning as a new perspective about a model’s abilities; this includes a number of concrete tasks and datasets for stress-testing model reliability. We also introduce Plex, a set of pre-trained large model extensions that can be applied to many different architectures. We illustrate the efficacy of Plex in the vision and language domains by applying these extensions to the current state-of-the-art Vision Transformer and T5 models, which results in significant improvement in their reliability. We are also open-sourcing the code to encourage further research into this approach.
Uncertainty — Dog vs. Cat classifier: Plex can say “I don’t know” for inputs that are neither cat nor dog. Robust Generalization — A naïve model is sensitive to spurious correlations (“destination”), whereas Plex is robust. Adaptation — Plex can actively choose the data from which it learns to improve performance more quickly.
Framework for Reliability First, we explore how to understand the reliability of a model in novel scenarios. We posit three general categories of requirements for reliable machine learning (ML) systems: (1) they should accurately report uncertainty about their predictions (“know what they don’t know”); (2) they should generalize robustly to new scenarios (distribution shift); and (3) they should be able to efficiently adapt to new data (adaptation). Importantly, a reliable model should aim to do well in all of these areas simultaneously out-of-the-box, without requiring any customization for individual tasks.
Uncertainty reflects the imperfect or unknown information that makes it difficult for a model to make accurate predictions. Predictive uncertainty quantification allows a model to compute optimal decisions and helps practitioners recognize when to trust the model’s predictions, thereby enabling graceful failures when the model is likely to be wrong.
Robust Generalization involves an estimate or forecast about an unseen event. We investigate four types of out-of-distribution data: covariate shift (when the input distribution changes between training and application and the output distribution is unchanged), semantic (or class) shift, label uncertainty, and subpopulation shift.
Types of distribution shift using an illustration of ImageNet dogs.
Adaptation refers to probing the model’s abilities over the course of its learning process. Benchmarks typically evaluate on static datasets with pre-defined train-test splits. However, in many applications, we are interested in models that can quickly adapt to new datasets and efficiently learn with as few labeled examples as possible.
Reliability framework. We propose to simultaneously stress-test the “out-of-the-box” model performance (i.e., the predictive distribution) across uncertainty, robust generalization, and adaptation benchmarks, without any customization for individual tasks.
We apply 10 types of tasks to capture the three reliability areas — uncertainty, robust generalization, and adaptation — and to ensure that the tasks measure a diverse set of desirable properties in each area. Together the tasks comprise 40 downstream datasets across vision and natural language modalities: 14 datasets for fine-tuning (including few-shot and active learning–based adaptation) and 26 datasets for out-of-distribution evaluation.
Plex: Pre-trained Large Model Extensions for Vision and Language To improve reliability, we develop ViT-Plex and T5-Plex, building on large pre-trained models for vision (ViT) and language (T5), respectively. A key feature of Plex is more efficient ensembling based on submodels that each make a prediction that is then aggregated. In addition, Plex swaps each architecture’s linear last layer with a Gaussian process or heteroscedastic layer to better represent predictive uncertainty. These ideas were found to work very well for models trained from scratch at the ImageNet scale. We train the models with varying sizes up to 325 million parameters for vision (ViT-Plex L) and 1 billion parameters for language (T5-Plex L) and pre-training dataset sizes up to 4 billion examples.
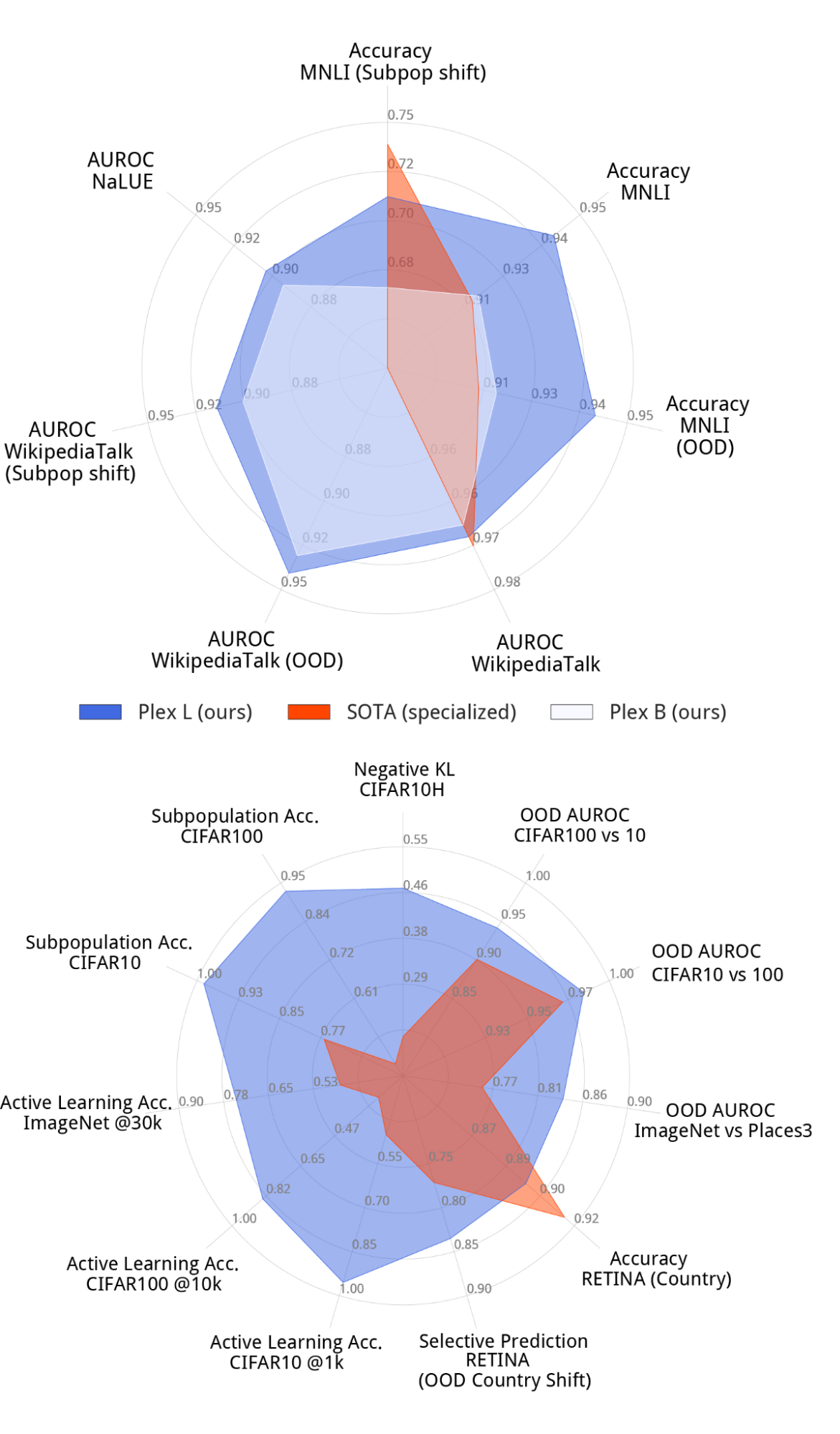
The following figure illustrates Plex’s performance on a select set of tasks compared to the existing state-of-the-art. The top-performing model for each task is usually a specialized model that is highly optimized for that problem. Plex achieves new state-of-the-art on many of the 40 datasets. Importantly, Plex achieves strong performance across all tasks using the out-of-the-box model output without requiring any custom designing or tuning for each task.
The largest T5-Plex (top) and ViT-Plex (bottom) models evaluated on a highlighted set of reliability tasks compared to specialized state-of-the-art models. The spokes display different tasks, quantifying metric performance on various datasets.
<!–
The largest T5-Plex (top) and ViT-Plex (bottom) models evaluated on a highlighted set of reliability tasks compared to specialized state-of-the-art models. The spokes display different tasks, quantifying metric performance on various datasets.
–>
Plex in Action for Different Reliability Tasks We highlight Plex’s reliability on select tasks below.
Open Set Recognition We show Plex’s output in the case where the model must defer prediction because the input is one that the model does not support. This task is known as open set recognition. Here, predictive performance is part of a larger decision-making scenario where the model may abstain from making certain predictions. In the following figure, we show structured open set recognition: Plex returns multiple outputs and signals the specific part of the output about which the model is uncertain and is likely out-of-distribution.
Structured open set recognition enables the model to provide nuanced clarifications. Here, T5-Plex L can recognize fine-grained out-of-distribution cases where the request’s vertical (i.e., coarse-level domain of service, such as banking, media, productivity, etc.) and domain are supported but the intent is not.
Label Uncertainty In real-world datasets, there is often inherent ambiguity behind the ground truth label for each input. For example, this may arise due to human rater ambiguity for a given image. In this case, we’d like the model to capture the full distribution of human perceptual uncertainty. We showcase Plex below on examples from an ImageNet variant we constructed that provides a ground truth label distribution.
Plex for label uncertainty. Using a dataset we construct called ImageNet ReaL-H, ViT-Plex L demonstrates the ability to capture the inherent ambiguity (probability distribution) of image labels.
Active Learning We examine a large model’s ability to not only learn over a fixed set of data points, but also participate in knowing which data points to learn from in the first place. One such task is known as active learning, where at each training step, the model selects promising inputs among a pool of unlabeled data points on which to train. This procedure assesses an ML model’s label efficiency, where label annotations may be scarce, and so we would like to maximize performance while minimizing the number of labeled data points used. Plex achieves a significant performance improvement over the same model architecture without pre-training. In addition, even with fewer training examples, it also outperforms the state-of-the-art pre-trained method, BASE, which reaches 63% accuracy at 100K examples.
Active learning on ImageNet1K. ViT-Plex L is highly label efficient compared to a baseline that doesn’t leverage pre-training. We also find that active learning’s data acquisition strategy is more effective than uniformly selecting data points at random.
Learn more Check out our paper here and an upcoming contributed talk about the work at the ICML 2022 pre-training workshop on July 23, 2022. To encourage further research in this direction, we are open-sourcing all code for training and evaluation as part of Uncertainty Baselines. We also provide a demo that shows how to use a ViT-Plex model checkpoint. Layer and method implementations use Edward2.
Acknowledgements We thank all the co-authors for contributing to the project and paper, including Andreas Kirsch, Clara Huiyi Hu, Du Phan, D. Sculley, Honglin Yuan, Jasper Snoek, Jeremiah Liu, Jie Ren, Joost van Amersfoort, Karan Singhal, Kehang Han, Kelly Buchanan, Kevin Murphy, Mark Collier, Mike Dusenberry, Neil Band, Nithum Thain, Rodolphe Jenatton, Tim G. J. Rudner, Yarin Gal, Zachary Nado, Zelda Mariet, Zi Wang, and Zoubin Ghahramani. We also thank Anusha Ramesh, Ben Adlam, Dilip Krishnan, Ed Chi, Neil Houlsby, Rif A. Saurous, and Sharat Chikkerur for their helpful feedback, and Tom Small and Ajay Nainani for helping with visualizations.
Drug discovery startup Insilico Medicine—alongside researchers from Harvard Medical School, Johns Hopkins School of Medicine, the Mayo Clinic, and others—used AI to identify…
Drug discovery startup Insilico Medicine—alongside researchers from Harvard Medical School, Johns Hopkins School of Medicine, the Mayo Clinic, and others—used AI to identify more than two dozen gene targets related to amyotrophic lateral sclerosis (ALS). The research findings, which included 17 high-confidence and 11 novel therapeutic targets, were recently published in Frontiers in Aging Neuroscience.
Using Insilico’s AI-driven target discovery engine, called PandaOmics, the researchers analyzed massive datasets to discover genes that new drugs could target to improve outcomes for ALS, also known as Lou Gehrig’s disease. Today, patients typically face an average life expectancy of between two and five years after symptom onset.
The research team used NVIDIA GPUs to train the deep learning models for target identification. The PandaOmics AI engine uses a combination of omics AI scores, text-based AI scores, financial scores, and more to rank gene targets.
ALS is a debilitating disease. Patients rapidly lose voluntary muscle movement, affecting the ability to walk, talk, eat, and breathe. The five existing FDA-approved therapies for the disease are unable to halt or reverse this loss of function, which affects more than 700,000 people around the world.
“The results of this collaborative research effort show what is possible when we bring together human expertise with AI tools to discover new targets for diseases where there is a high unmet need,” said Alex Zhavoronkov, founder and CEO of Insilico Medicine, in a press release. “This is only the beginning.”
Insilico Medicine is a Premier member of NVIDIA Inception, a global program designed to support cutting-edge startups with co-marketing, expertise, and technology.
AI uncovers new paths to treat untreatable diseases
The research team used Quiver, a distributed graph learning library, to accelerate its AI models on multiple NVIDIA GPUs. They used natural language processing models including BioBERT, GPT, and OPT, as well as text recognition models including PaddleOCR and docTR.
Figure 1. The PandaOmics AI platform analyzed ALS patient brain samples and other ALS data to identify new gene targets and existing drugs that could be repurposed to treat the disease.
To help identify the genes related to ALS, the researchers used public datasets as well as data from Answer ALS, a global project with clinical data consisting of 2.6 trillion data points from around 1,000 ALS patients. In a preclinical animal model, the team validated that 18 of the 28 identified gene targets were functionally correlated to ALS—and that in eight of them, suppression would strongly reduce neurodegeneration.
The researchers are now working to advance some of these targets toward clinical trials for ALS. The targets will be shared on ALS.AI to help accelerate drug discovery.
Earlier this year, Insilico began a Phase 1 clinical trial for an AI-discovered, AI-designed drug to treat pulmonary fibrosis, another fast-progressing, hard-to-treat disease.
Investigate the ultimate truth this GFN Thursday with Loopmancer, now streaming to all members on GeForce NOW. Stuck in a death loop, RTX 3080 and Priority members can search for the truth with RTX ON — including NVIDIA DLSS and ray-traced reflections. Plus, players can enjoy the latest Genshin Impact event with the “Summer Fantasia” Read article >
Over the last decades, organizations of all sizes across the world have flocked to implement video management systems (VMS) that tie together the components of a video network…
Over the last decades, organizations of all sizes across the world have flocked to implement video management systems (VMS) that tie together the components of a video network infrastructure. By allowing businesses to easily capture, record, store, retrieve, view, and analyze video collected from their cameras, VMS can improve their operations, increase visibility, and enhance safety.
VMS infrastructure is now so pervasive that enterprises can no longer monitor the firehose of video streaming day and night. The growing need for scalable and real-time analysis of video is possibly the greatest driver today of AI in the enterprise. With vast amounts of video data to be analyzed in real time, smart video analytics call for edge AI technology, where the heavy computation executes in the field near sensors like video cameras.
Organizations across all industries are eager to add AI to their existing VMS to maximize the return on their initial investments and take advantage of this valuable data but, unfortunately, it is a difficult task.
Organizations must partner with an independent software vendor who provides an intelligent video analytics (IVA) application. The vendor must then develop, deploy, manage, and support their own integration for every application that the organization wants to run. It is a painstaking process that requires significant time, energy, and expertise to execute.
An NVIDIA Metropolis partner themselves, Milestone Systems is a global leader in VMS helping to address this challenge and make it easier for hundreds of other Metropolis IVA partners to expand accessibility to incredibly valuable vision AI applications.
John Madsen, a senior research engineer at Milestone, explains, “When you have thousands of cameras that are recording 24/7, how do you find the relevant data? With AI, our end users can find recorded events in their logs that they want to find in minutes instead of combing through hours and hours of footage. We want to help our end users find the relevant video footage and run live analytics.”
Introducing AI Bridge
Milestone has embarked on a mission to help their customers get the most out of their existing VMS platforms. The result is Milestone AI Bridge.
AI Bridge is an API gateway that eases the integration of intelligent video analytics (IVA) applications with the Milestone XProtect VMS.
Figure 1. Relationship between the cameras, VMS site, AI Bridge, the partner application, and where it sits on an NVIDIA EGX server.
How AI Bridge works:
A camera sends video data to the VMS site.
The VMS site is connected to AI Bridge and sends video data back and forth.
AI Bridge connects the video from the VMS site to the GPU-accelerated IVA applications to run AI analytics and generate insights.
The insights are then fed back into the VMS so that actions can be taken based on whatever insight is provided from the AI application.
With AI Bridge, Milestone users can now instantly integrate third-party AI models into their own video systems. Milestone users are typically application providers or independent software vendors that help organizations create IVA applications.
To get access to AI Bridge from Milestone, create an account with the NGC catalog.
AI Bridge in action
Another NVIDIA Metropolis partner, DataFromSky is using AI Bridge to provide AI solutions for smart parking, traffic control, and retail.
One of their customers, the Køge Nord Train Station, located near Copenhagen, was experiencing large volumes of commuter congestion. For many commuters, a lack of parking spots and traffic congestion can lead to frustration, wasted time, accidents, and even missed trains or buses.
To solve this, DataFromSky built an intelligent parking application that monitors parking lots for occupancy, enables mobile payments, and navigates drivers to empty parking spots. With the addition of AI, each camera installed on the parking lot is able to monitor up to 400 parking spots in real-time. All this results in commuters having smoother and better travel experiences.
Thanks to AI Bridge, DataFromSky is able to integrate AI solutions into their customers’ existing camera infrastructure easily. This results in a significantly faster installation time, especially critical for larger deployments that may span hundreds of cameras.
Bringing AI Bridge to life
In building AI Bridge, Milestone knew that they needed to work with a partner that had deep roots in the AI community. That is why they chose NVIDIA.
“Our VMS works on a Windows platform which is very different from the AI community which uses modern software such as Linux, Kubernetes, and Docker,” says Madsen, “Working with NVIDIA allows us to modernize our stack and makes it extremely easy for us to work with the AI community.”
Milestone leveraged a wide array of NVIDIA AI products to make AI Bridge possible.
NVIDIA-Certified Systems provide enterprises with optimized hardware to enable quick and efficient video processing and inference that can be scaled across many cameras.
The NVIDIA Metropolis platform is an application framework that simplifies the development and scale of IVA applications for connecting to the AI ecosystem.
NVIDIA Fleet Command is a managed platform for container orchestration that streamlines the provisioning and deployment of systems and AI applications at the edge.
Milestone leverages Fleet Command to deploy the AI Bridge API remotely onto dozens or even thousands of edge systems within minutes.
“A big challenge is not just the integration, but deploying the analytics on-premises and how you manage it,” added Madsen. “This is why we turned to NVIDIA Fleet Command.”
Fleet Command also provides a single control plane for IT administrators to securely manage all AI applications through one dashboard. This makes it the ideal way to accelerate deployments, POCs, and edge infrastructure management.
The use cases of IVA
IVA promises to bring new, intelligent use cases across every industry. Some of the transformational use cases include the following:
You’re invited to connect with NVIDIA experts through a new exclusive series of Ask Me Anything (AMA) sessions. During these live Q&As, members of the NVIDIA Developer Program…
You’re invited to connect with NVIDIA experts through a new exclusive series of Ask Me Anything (AMA) sessions. During these live Q&As, members of the NVIDIA Developer Program can submit questions to our experts, brainstorm about common challenges that developers are facing, and engage in online discussions about NVIDIA technologies. The series will also provide guidance on integrating NVIDIA SDKs.
The AMA series kicks off on July 28 at 10:00 AM, Pacific time. Attendees can get tips on incorporating real-time rendering across their projects from the editors of Ray Tracing Gems II:
Adam Marrs is a principal engineer in the Game Engines and Core Technology group at NVIDIA. He holds a Ph.D. in computer science and has shipped graphics code in various AAA games and commercial game engines. He has written for GPU Zen 2, Ray Tracing Gems, and recently served as the editor-in-chief of Ray Tracing Gems II.
Peter Shirley is a distinguished engineer in the Research group at NVIDIA. He holds a Ph.D. in computer science and has worked in academics, startup companies, and industry. He is the author of several books, including the recent Ray Tracing in One Weekend series.
Ingo Wald is a director of ray tracing at NVIDIA. He holds a Ph.D. in computer science, has a long history of research related to ray tracing in both academia and industry, and is known for authoring and co-authoring various papers and open-source software projects on rendering, visualization, and data structures.
Eric Haines currently works at NVIDIA on interactive ray tracing. He co-authored the books Real-Time Rendering, 4th Edition and An Introduction to Ray Tracing. He edited The Ray Tracing News, and co-founded the Journal of Graphics Tools and the Journal of Computer Graphics Techniques. Most recently, he co-edited Ray Tracing Gems.
Each of these exclusive Q&A sessions will offer the developer community a chance to get answers from experts in real time, along with a forum for collaboration after the event.
To participate, you must be a member of the NVIDIA Developer Program. Sign up if you’re not already a member. Post questions to the dedicated online forum before the event and during the 60-minute live session.
Mark your calendars for the second AMA in the series scheduled for October 26, 2022. We’ll dive into best practices for building, training, and deploying recommender systems.
Effective and robust VQA systems cannot exist without high-quality, semantically and stylistically diverse large-scale training data of image-question-answer triplets. But, creating such data is time consuming and onerous. Perhaps unsurprisingly, the VQA community has focused more on sophisticated model development rather than scalable data creation.
In “All You May Need for VQA are Image Captions,” published at NAACL 2022, we explore VQA data generation by proposing “Visual Question Generation with Question Answering Validation” (VQ2A), a pipeline that works by rewriting a declarative caption into multiple interrogative question-answer pairs. More specifically, we leverage two existing assets — (i) large-scale image-text data and (ii) large-capacity neural text-to-text models — to achieve automatic VQA data generation. As the field has progressed, the research community has been making these assets larger and stronger in isolation (for general purposes such as learning text-only or image-text representations); together, they can achieve more and we adapt them for VQA data creation purposes. We find our approach can generate question-answer pairs with high precision and that this data can successfully be used for training VQA models to improve performance.
The VQ2A technique enables VQA data generation at scale from image captions by rewriting each caption into multiple question-answer pairs.
VQ2A Overview The first step of the VQ2A approach is to apply heuristics based on named entity recognition, part-of-speech tagging and manually defined rules to generate answer candidates from the image caption. These generated candidates are small pieces of information that may be relevant subjects about which to ask questions. We also add to this list two default answers, “yes” and “no”, which allow us to generate Boolean questions.
Then, we use a T5 model that was fine-tuned to generate questions for the candidate, resulting in [question, candidate answer] pairs. We then filter for the highest quality pairs using another T5 model (fine-tuned to answer questions) by asking it to answer the question based on the caption. was . That is, we compare the candidate answer to the output of this model and if the two answers are similar enough, we define this question as high quality and keep it. Otherwise, we filter it out.
The idea of using both question answering and question generation models to check each other for their round-trip consistency has been previously explored in other contexts. For instance, Q2 uses this idea to evaluate factual consistency in knowledge-grounded dialogues. In the end, the VQ2Aapproach, as illustrated below, can generate a large number of [image, question, answer] triplets that are high-quality enough to be used as VQA training data.
VQ2A consists of three main steps: (i) candidate answer extraction, (ii) question generation, (iii) question answering and answer validation.
Results Two examples of our generated VQA data are shown below, one based on human-written COCO Captions (COCO) and the other on automatically-collected Conceptual Captions (CC3M), which we call VQ2A-COCO and VQ2A-CC3M, respectively. We highlight the variety of question types and styles, which are critical for VQA. Overall, the cleaner the captions (i.e., the more closely related they are to their paired image), the more accurate the generated triplets. Based on 800 samples each, 87.3% of VQ2A-COCO and 66.0% VQ2A-CC3M are found by human raters to be valid, suggesting that our approach can generate question-answer pairs with high precision.
Generated question-answer pairs based on COCO Captions (top) and Conceptual Captions (bottom). Grey highlighting denotes questions that do not appear in VQAv2, while green highlighting denotes those that do, indicating that our approach is capable of generating novel questions that an existing VQA dataset does not have.
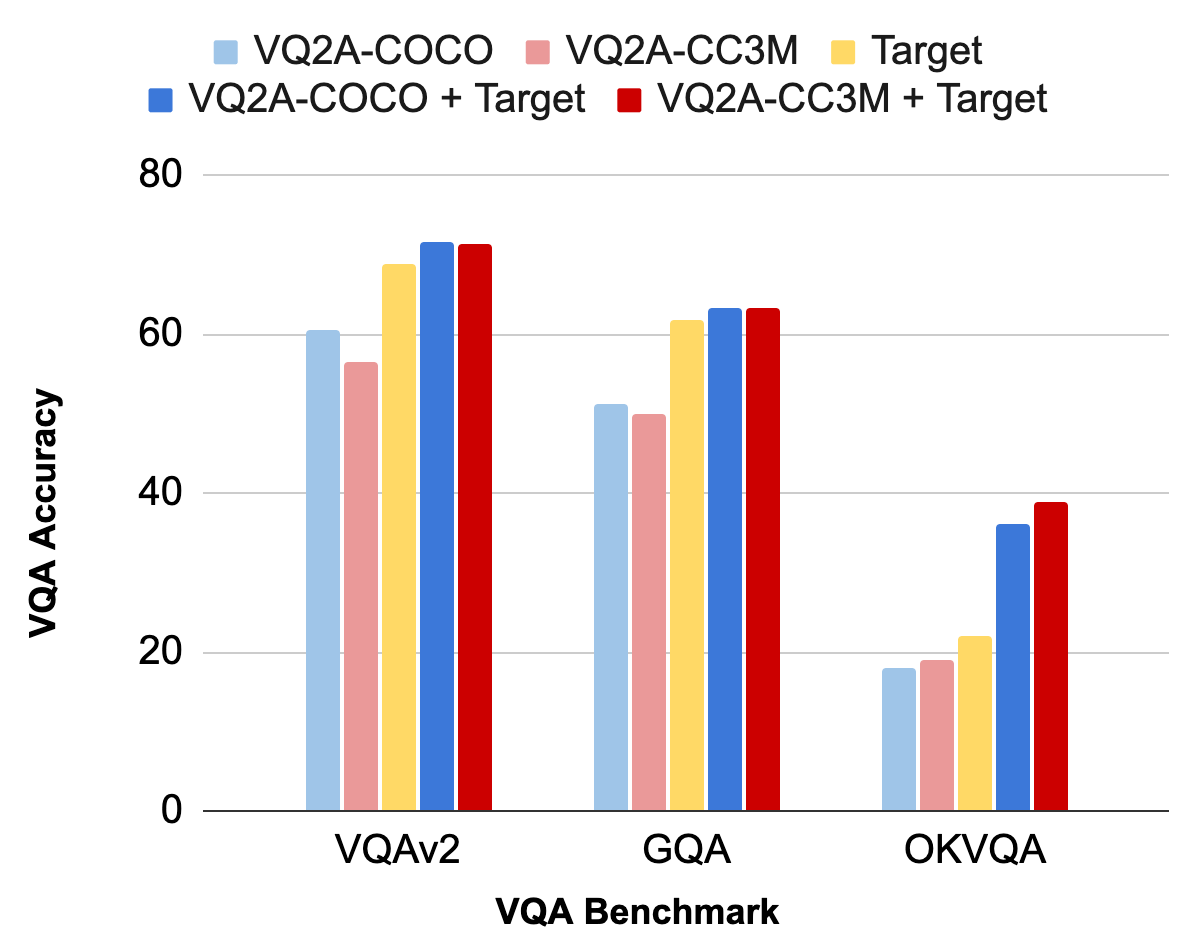
Finally, we evaluate our generated data by using it to train VQA models (highlights shown below). We observe that our automatically-generated VQA data is competitive with manually-annotated target VQA data. First, our VQA models achieve high performance on target benchmarks “out-of-the-box”, when trained only on our generated data (light blue and light red vs. yellow). Once fine-tuned on target data, our VQA models outperform target-only training slightly on large-scale benchmarks like VQAv2 and GQA, but significantly on the small, knowledge-seeking OK-VQA (dark blue/red vs. light blue/red).
VQA accuracy on popular benchmark datasets.
Conclusion All we may need for VQA are image captions! This work demonstrates that it is possible to automatically generate high-quality VQA data at scale, serving as an essential building block for VQA and vision-and-language models in general (e.g., ALIGN, CoCa). We hope that our work inspires other work on data-centric VQA.
Acknowledgments We thank Roee Aharoni, Idan Szpektor, and Radu Soricut for their feedback on this blogpost. We also thank our co-authors: Xi Chen, Nan Ding, Idan Szpektor, and Radu Soricut. We acknowledge contributions from Or Honovich, Hagai Taitelbaum, Roee Aharoni, Sebastian Goodman, Piyush Sharma, Nassim Oufattole, Gal Elidan, Sasha Goldshtein, and Avinatan Hassidim. Finally, we thank the authors of Q2, whose pipeline strongly influences this work.
Join this digital conference from August 2-4 to learn how science is being advanced through the work done at Open Hackathons or accelerated using OpenACC.
Join this digital conference from August 2-4 to learn how science is being advanced through the work done at Open Hackathons or accelerated using OpenACC.









 Drug discovery startup Insilico Medicine—alongside researchers from Harvard Medical School, Johns Hopkins School of Medicine, the Mayo Clinic, and others—used AI to identify…
Drug discovery startup Insilico Medicine—alongside researchers from Harvard Medical School, Johns Hopkins School of Medicine, the Mayo Clinic, and others—used AI to identify…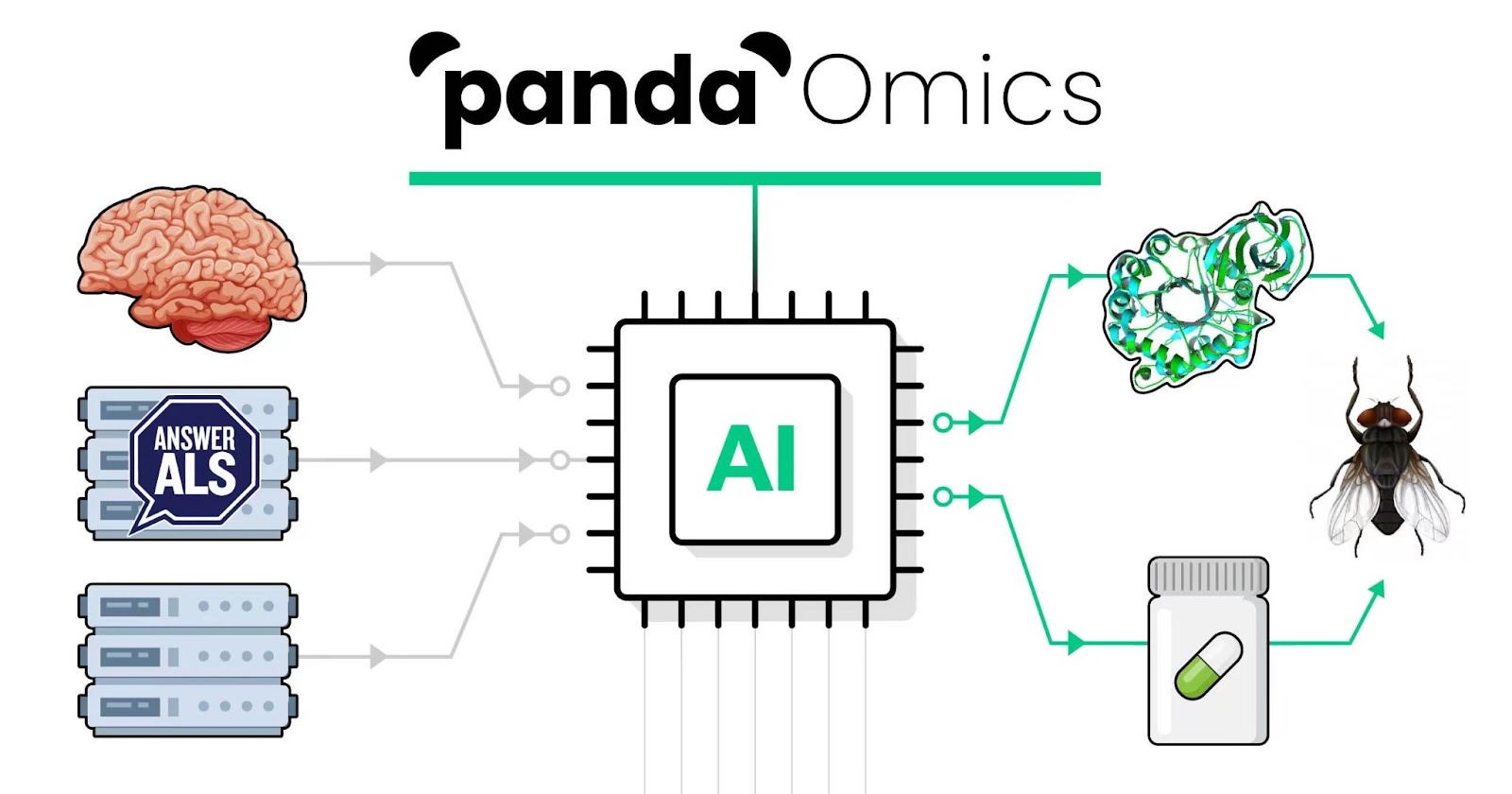
 Over the last decades, organizations of all sizes across the world have flocked to implement video management systems (VMS) that tie together the components of a video network…
Over the last decades, organizations of all sizes across the world have flocked to implement video management systems (VMS) that tie together the components of a video network…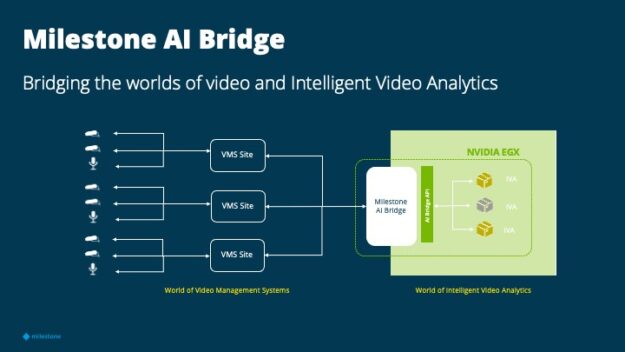
 You’re invited to connect with NVIDIA experts through a new exclusive series of Ask Me Anything (AMA) sessions. During these live Q&As, members of the NVIDIA Developer Program…
You’re invited to connect with NVIDIA experts through a new exclusive series of Ask Me Anything (AMA) sessions. During these live Q&As, members of the NVIDIA Developer Program…
 Join us at SIGGRAPH Aug. 8-11 to explore how NVIDIA technology is driving innovations in simulation, collaboration, and design across industries.
Join us at SIGGRAPH Aug. 8-11 to explore how NVIDIA technology is driving innovations in simulation, collaboration, and design across industries.





 Join this digital conference from August 2-4 to learn how science is being advanced through the work done at Open Hackathons or accelerated using OpenACC.
Join this digital conference from August 2-4 to learn how science is being advanced through the work done at Open Hackathons or accelerated using OpenACC.