
Helios: hyperscale indexing for the cloud & edge, Potharaju et al., PVLDB’20
Last time out we looked at the motivations for a new reference blueprint for large-scale data processing, as embodied by Helios. Today we’re going to dive into the details of Helios itself. As a reminder:
Helios is a distributed, highly-scalable system used at Microsoft for flexible ingestion, indexing, and aggregation of large streams of real-time data that is designed to plug into relationals engines. The system collects close to a quadrillion events indexing approximately 16 trillion search keys per day from hundreds of thousands of machines across tens of data centres around the world.
As an ingestion and indexing system, Helios separates ingestion and indexing and introduces a novel bottoms-up index construction algorithm. It exposes tables and secondary indices for use by relational query engines through standard access path selection mechanisms during query optimisation. As a reference blueprint, Helios’ main feature is the ability to move computation to the edge.
Requirements
Helios is designed to ingest, index, and aggregate large streams of real-time data (tens of petabytes a day). For example, the log data generated by Azure Cosmos. It supports key use cases such as finding records relating to specific attributes (e.g. for incident support), impact and drill-down analysis, and performance monitoring and reporting. One interesting use case is in support of GDPR right to be forgotten requests, where it becomes necessary to search 10s of billions of streams to find those containing a user’s information.
Incoming streams can have data rates as high as 4TB/minute, with many columns to be indexed (7+ is common) and high cardinality.
System design
A stream table is defined by a loose schema which defines the sources to be monitored (as a SourceList) and indices to be created. For example:

Based on the CREATE STREAM statement, Helios generates an agent executable to be deployed on every machine producing a log that is part of the stream. It also generates an executable to be run on the server-side ingestion machines. The agent process accumulates and chunks incoming data into data blocks (with frequency determined by the CHUNK EVERY clause). Optionally, and central to how Helios handles high volume and velocity ingest at manageable scale and cost, the agent can also perform local processing (parsing, indexing, and aggregation) and send the resulting index entries to the ingestion clusters in a compact format.
Ingestion servers are stateless, running the user-defined dataflow (based on the CREATE SCHEMA statement) to process incoming blocks. Data blocks are stored in a distributed file system, and once acknowledged by the file system, an entry is written into Helio’s progress log. The progress log is used to track the progress of both data ingestion and index building. Secondary index generation (hydration) then happens asynchronously. The resulting index blocks are merged into a global index which maps (column, value) pairs to data block URIs.
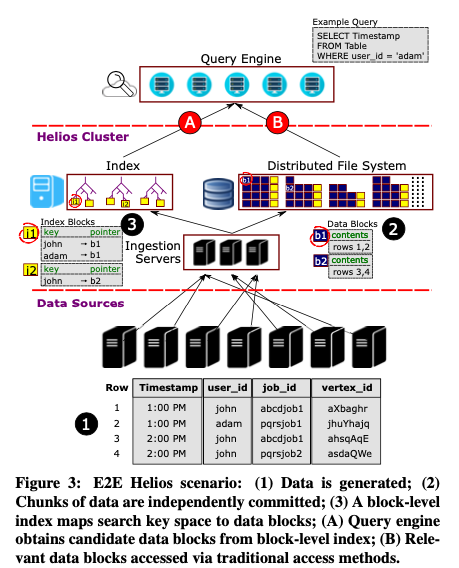
The progress log is the only strongly synchronized component in Helios, and is deployed in quorum based rings of 5 servers. There are multiple replicated logs each governing a partition of the data set. In this manner Helios achieves a consistent rate of 55,000 writes/second for metadata persistence.
Indexing
A key factor in Helios’s success is asynchronous index mangement: Helios maintains eventually consistent indexes against the data, but exposes a strongly consistent queryable view of the underlaying data with best-effort index support.
Helios’ index is a multi-level (tree-based) structure that is built in a bottom-up manner. I.e., information is inserted at the leaves, and the index then ‘grows upwards’ through merge and add operations. The authors point out an interesting similarity to learned index structures here: “At the highest level, a learned index tries to learn a function that maps an index search key to the leaf nodes containing the search key. The Helios structure in its generic form performs exactly the same function, with the different that the mapping is not learned from data but composed from the (typically, hash) partitioning functions used by the different index levels.“
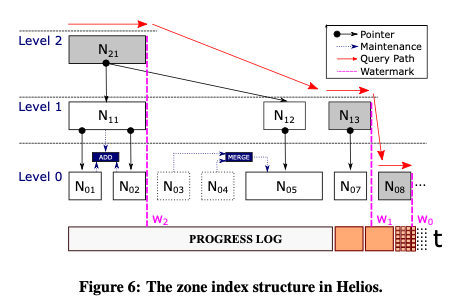
Indexing begins by scanning the progress log from the latest checkpoint, with an initial leaf node at the bottom of the tree (level 0) constructed for each chunk. No global order is imposed here, indexed keys are simply packed into leaf nodes based on arrival order. Multiple nodes at the same level may be combined into one using the merge operator in accordance with a merge policy. Just as level 0 watches blocks arrive in the progress log and follows along creating leaf nodes, so the next level up, level 1 watches the progress of leaf nodes arriving at level 0, and creates a higher level index over the leaf nodes by applying the add operator. Level 2 follows the progress of level 1 in a similar manner, and so on for the desired number of levels. The result is an indexing frontier that moves forward across the levels through a per-level watermark.
An index node is a collection of (key, pointers) pairs. The merge operation combines two index nodes $N_1$ and $N_2$ by taking the union of their keys, and for each key the union of the pointers. E.g. if $N_1 = {K_1 mapsto {P_1, P_2}, K_2 mapsto {P_3}}$ and $N_2 = {K_2 mapsto {P_4}}$ then $N_1 oplus N_2 = { K_1 mapsto {P_1, P_2}, K_2 mapsto {P_3, P_4 }}$. Helios uses a size-based merge policy in which two nodes are merged if they are both below a given size threshold.
The add operation creates a new node at one level up containing the union of the keys in the blocks being added, and pointers to the nodes in the level below containing entries for those keys. E.g. $N_1 + N_2 = {K_1 mapsto {P_{N_1}}, K_2 mapsto {P_{N_1}, P_{N_2}}}$. Helios also uses a size-based add policy, in which nodes are added (at higher and higher levels) until the size of the resulting node reaches a configurable threshold.
Note that the resulting structure may contain orphan nodes (shown in grey in the figure above) that do not have any parent in the layer above. This has implications for query processing that we’ll look at shortly.
Index compaction, which also takes place bottom-up, is triggered when a configurable number of data blocks have been processed.
Federated indexing
Our initial approach towards data and index management focused towards bringing in data from all the sources into an ingestion cluster and performing the required post-processing operations (e.g. parsing, indexing, etc.). However, this approach incurs significant costs… The hierarchical/recursive indexing model gives the freedom of distributing our computation acress the agents and ingestion back-end servers, sharing the same intuition as the current trend of edge computation.
Pre-processing on agents reduces the size of the ingestion cluster required, at the cost of consuming processing power on the source machine. In Helios production deployments, the agent typically consumes 15%-65% of a single CPU core, and stays under an allocated memory budget of 1.6GB. The generated agent and ingestion code utilises a shared library called Quark which provides a selection of parsers, extractors, indexers, partitioners, serializers and compressors as well as query-processing operators with predicate push-down.
Querying
Helios indexes are represented and exposed as data in easily accessible formats, available for any query engine. This allows us to democratise index usage outside of Helios, e.g. query engines can perform their own cost-based index access path selection, and index reads can independently scale without being constrained by compute resources provided by Helios. In fact, we were able to integrate Apache Spark with no changes to its optimizer/compiler.
Due to the existence of orphan nodes, querying can’t proceed in a pure top-down manner. So Helios provides a hybrid index scan operator. Querying starts by moving down the tree from the root nodes (which are orphan nodes by definition), and then recursively repeating this process for each of the orphan nodes at the next level down moving right.
In Figure 6 above for example, we can search down the tree from $N_{21}$, but in doing so we miss any potential hits in the orphan node $N_{13}$ at the next level down. So after processing $N_{21}$ we start a new search from $N_{13}$. This in turn may miss hits in the orphan block $N_{08}$ so we then drop-down once more and move right…
Helios in production
Helios has multiple uses at Microsoft including supporting debugging and diagnostics, workload characterization, cluster health monitoring, deriving business insights, and performing impact analysis.
Helios clusters have been in production for the last five years, collecting close to a quadrillion log lines per day from hundreds of thousands of machines spread across tens of datacenters.