Everyone agrees that open solutions are the best solutions but, there are few truly open operating systems for Ethernet switches. At NVIDIA, we embraced open…
Everyone agrees that open solutions are the best solutions but, there are few truly open operating systems for Ethernet switches. At NVIDIA, we embraced open source for our Ethernet switches. Besides supporting SONiC, we have contributed many innovations to open-source community projects.
This post was originally published on the Mellanox blog in June 2018 but has been updated.
Microsoft runs one of the largest clouds in the world with Azure. In building and deploying Azure, they have gained a lot of insight into managing a global, high-performance, highly available, and secure network.
The network operating system (NOS) Microsoft uses for Azure, SONiC (Software for Open Networking in the Cloud), is built on open source. Their experience with hundreds of data centers and tens of thousands of switches has educated them about what is required:
Use best-of-breed switching hardware.
Ensure that deploying new features won’t affect end users.
Updates must be released securely and reliably across the globe within hours.
Use cloud-scale deep telemetry and automation for failure mitigation.
Enable software-defined networking to quickly provision and manage hardware elements in the network through a unified structure to eliminate duplication and reduce failures.
SONiC, a breakthrough for network switch operations and management, addresses these requirements. Microsoft open-sourced this innovation to the community, making it available on their SONiC GitHub repository.
SONiC is a uniquely extensible platform with a large and growing ecosystem of hardware and software partners that offers multiple switching platforms and various software components.
SONiC system’s architecture comprises multiple modules that interact with each other through a centralized and scalable infrastructure. This infrastructure relies on a Redis-database engine which allows data persistence, replication, and multi-process communication among all SONiC subsystems.
The Redis-engine infrastructure relies on a messaging paradigm of publisher/subscriber so that applications can subscribe only to the data views that they require, avoiding implementation details irrelevant to their functionality.
Figure 1. SONiC architecture
For more information about the SONiC architecture, see Architecture in the SONiC wiki.
NVIDIA Spectrum switches support a variety of Layer 2 and Layer 3 networking connectivity and management features. Table 1 shows the features that SONiC currently supports.
L3
L2
Management
BGP
LAG
SNMP
ECMP
LLDP
Syslog
DHCP Relay
ECN
NTP
IPv6/4
PFC
CoPP
WRED
TACACS+
CoS
Sysdump
Mirroring
ACL
Table 1. Currently supported features
Why should you use NVIDIA Spectrum Switch with SONiC?
When choosing a switch to run SONiC on top, you should look at two main factors:
Is the switch vendor capable of supporting your deployment, ASIC, Switch Abstraction Interface (SAI), and software-wise?
What are the capabilities of the ASIC running underneath?
NVIDIA Spectrum ASIC-based switches
The NVIDIA Open Ethernet Switch portfolio is entirely based on the Spectrum ASIC, providing the lowest latency for 25G/100G in the market, zero packet loss, and a fully shared buffer. It is the ideal combination for cloud networking demands.
SONiC works with the Spectrum ASICs through their unique driver solutions. SONiC uses SAI, an open-source driver solution co-invented by NVIDIA. This open capability of Spectrum also means that any Linux distribution can run on a Spectrum switch.
NVIDIA is the only switch silicon vendor that has contributed their ASIC driver directly to the Linux kernel, enabling support for a mix of SONiC and any standard Linux distributions, like Red Hat or Ubuntu, to run directly on the switch.
Figure 2. The SONiC development community
NVIDIA is the only company participating in all levels of the SONiC development community. We are one of the first companies to develop and adopt SAI. SONiC fully supports all Spectrum family switches and can be deployed on any switch in our Ethernet portfolio. We are also a major and active contributor to the SONiC OS feature set.
Figure 3. NVIDIA switches
All NVIDIA networking platforms support port splitting through the SONiC OS, the only platforms that currently support this feature. Spectrum switches also deliver exceptional network performance compared to a commodity silicon-based switch using real-life mixed frame size, “noisy neighbor,” and microburst absorption scenarios.
NVIDIA Spectrum switch systems are an ideal spine and top-of-rack solution, allowing flexibility, with port speeds ranging from 10 Gb/s to 100 Gb/s per port, and port density that enables full rack connectivity to every server at any speed. These ONIE-based switch platforms support multiple operating systems, including SONiC and leverage the advantages of Open Network disaggregation and the NVIDIA Spectrum ASIC capabilities.
Spectrum adaptive routing technology supports various network topologies. For typical topologies such as CLOS (or leaf/spine), the distance of the multiple paths to a given destination is the same. Therefore, the switch transmits the packets through the least congested port.
In other topologies where distances vary between paths, the switch prefers to send the traffic over the shortest path. If congestion occurs on the shortest path, then the least-congested alternative paths are selected. You can build a high-performing CLOS data center using the NVIDIA switches as your building blocks.
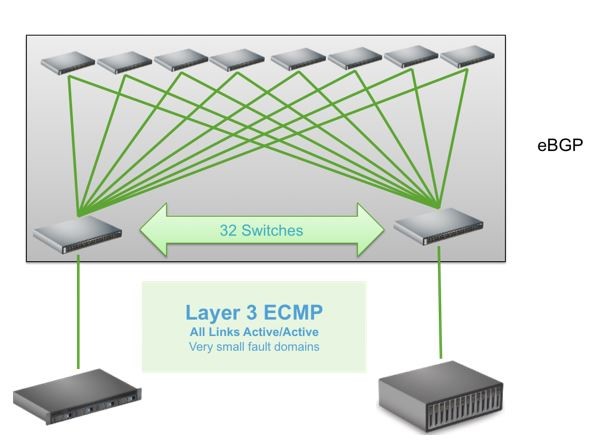
Similarly, Border Gateway Protocol (BGP) is a routing protocol responsible for looking at all the available paths that data could travel and picking the best route. BGP enables communication to happen quickly and efficiently.
Figure 4. Typical leaf-spine pod design with BGP as the routing protocol
Spectrum switches enable PODs. A POD is a network, storage, and compute unit that works together to deliver networking services. A POD is a repeatable design pattern that provides scalable and easier-to-manage data centers.
Figure 5. Scaling to multiple PODs
Finally, the Spectrum family enables a set of advanced network functions that future-proof the switch with the flexibility to handle evolving networking technologies. This includes new protocols that may be developed in the future, enabling custom applications, advanced telemetry, and new tunneling/overlay capabilities. Spectrum combines a programmable, flexible, and massively parallel packet processing pipeline with a fully shared and stateful forwarding database. Spectrum also features What Just Happened (WJH), the world’s most useful switch telemetry technology.
For more information, see the following resources:
Humanity has seen major scientific breakthroughs directly related to discoveries that do not share the glamor of the breakthrough they enabled. Sir Alexander…
Humanity has seen major scientific breakthroughs directly related to discoveries that do not share the glamor of the breakthrough they enabled.
Sir Alexander Fleming’s penicillin gave rise to effective treatments for infections like pneumonia, but penicillin’s importance outshines a technology known as the Petri dish, invented by a German physician. It was in a Petri dish that penicillin was found when Fleming returned from his vacation.
Naturally, the importance of the tools and components that enabled scientific advancements and technological progress are not as celebrated as the new technology, but they are just as important to the discovery.
Today, in a world full of open-source projects, pretrained machine learning models, and affordable computing available at scale, developers and scientists have more resources to combine and create.
Like the Petri dish that enabled penicillin, developers and scientists can use existing components to generate new discoveries of great social impact in the healthcare industry.
NVIDIA Healthcare and Life Sciences Developer Summit
NVIDIA is hosting a free Healthcare and Life Sciences Developer Summit on November 10, 2022, with key webcasts for developers, startups, and industry leaders. The sessions show how NVIDIA technologies are supporting the future of medicine.
The virtual summit offers a full day of technical talks to reach developers and technical leaders in the EMEA region. Led by NVIDIA healthcare team members and startups like Relation Therapeutics, ImFusion, Rhino Health, and Quantib, the day features talks about high-performance computing, large language models, genomics, and medical imaging.
Supporting healthcare startups
NVIDIA has been nurturing more than 12K startups globally through the Inception program, its virtual accelerator, with nearly 2,000 startups in the healthcare industry.
At the latest GTC, success stories from Inception members were shared in the Accelerating Healthcare & Life Science Innovation with Makers and Breakers session. Startups such as Activ Surgical, Instadeep, Haply Robotics, DNAnexus, and Quantib talked about their experiences and recent achievements in medical imaging, medical instruments, and biopharma.
Renee Yao, Global AI Healthcare AI Startups Lead at NVIDIA, has seen several startups achieve success by leveraging NVIDIA technologies, enabling those in the healthcare and life sciences industry to build faster and cheaper.
A lot of innovation is happening in the healthcare space, particularly those contributing to enhancing precision health powered by machine learning. Yao advises startups to consider what scientific and software communities have already built before starting developments from scratch.
David Ruau, NVIDIA Head of Strategic Alliances in Drug Discovery, talks about the upcoming breakthroughs in the biopharma domain, not only through large and traditional companies but also through startups.
“The pace of innovation that AI has applied to drug discovery is still accelerating,” says Ruau. He believes that technologies such as transformers, geometric deep learning, diffusion models, and many other approaches applied to all the steps of the drug discovery process are contributing to giant leaps in innovation.
Ruau explains, “startups must be nimble and agile, as speed is key in this domain.” He points out the importance of funding and lowering the entry requirements for innovating with machine learning. Software developers and scientists can use NVIDIA open-source frameworks in the cloud, on-premises, or in a hybrid approach. This enables faster results by any healthcare technology startup, regardless of their funding stage.
Figure 1. Transformer-based large language models are creating new possibilities for real-time exploration of the chemical universe
Enabling with technology
NVIDIA technologies are used by organizations all over the world to accelerate their research and fuel new discoveries.
NVIDIA recently announced BioNeMo, a transformer-based framework and cloud service. It can process SMILES and protein sequences to predict structures and accelerate the discovery of druggable targets. BioNeMo has been built on top of NVIDIA NeMo Megatron, a 3B parameters model, and it is already optimized for GPU.
Another major announcement came from Project MONAI, a PyTorch-based, open-source framework for deep learning in healthcare imaging. The latest version, 1.0, includes new and enhanced features, which include preprocessing for multidimensional medical imaging data, automated segmentation, GPU data parallelism, and more.
Useful for creating state-of-the-art, end-to-end training workflows for healthcare imaging, MONAI provides researchers with the optimized and standardized way to create and evaluate deep learning models.
Relation Therapeutics, a drug discovery startup from London, is using transformer-based machine learning and ActiveGraph technology to better understand the biology of diseases. They aim to discover and develop new therapeutics, help humanity understand why patients become sick, and ultimately cure disease.
Their technology can understand combinatorial relationships between genes, proteins, and drugs. It involves calculations that require efficient use of computational resources and an exceptional interdisciplinary team of researchers, machine learning, data scientists, and engineers to devise these models.
Relation Thereapeutics is currently training a transformer-based DNA-to-gene-expression model on 80 NVIDIA A100 GPUs. The GPUs are hosted on Cambridge-1, the UK’s most powerful supercomputer. It has 400 petaflops of AI performance that leverages NCCL and cuDNN for GPU-optimized workflows.
By using existing technologies, such as NVIDIA GPUs and an optimized software stack, Relation Therapeutics can create novel approaches that push the boundaries of what is known about biology. They are becoming one of the best modern-day examples of how to leverage existing technologies to create new ones and positively impact human health.
The future of medicine
Our society is already witnessing historical breakthroughs powered by computational methods, and startups play a crucial role in achieving such advancements.
A new era of scientific discovery and computational biology has begun, and NVIDIA technologies are the reliable ground in which innovation can be built upon. Speeding up scientific development or serving as a catalyst of novel stunning technologies, like the key tools that enabled penicillin to exist.
NVIDIA is enabling thousands of individuals and organizations across all industries through its optimized computing stack, enabling major technological transformation. Register now for the Healthcare and Life Sciences Developer Summit on November 10, 2022 to see how key startups are defining the future of medicine with the power of AI.
Reducing the amount of carbon released to the atmosphere is a political priority. The current U.S. administration plans to achieve net-zero carbon emissions…
Reducing the amount of carbon released to the atmosphere is a political priority. The current U.S. administration plans to achieve net-zero carbon emissions from the power grid by 2035, and industry-wide by 2050.
To achieve this goal, a variety of techniques are being developed that capitalize on the efficiency of AI to fight against climate change. For power plants, developing techniques to reduce carbon emissions, carbon capture, and storage processes requires a detailed understanding of the associated fluid mechanics and chemical processes throughout the facility. This requires scientifically accurate simulations of fluid mechanics, heat transfer, chemical reactions, and their degree of interaction.
Figure 1. To achieve net-zero carbon emissions, digital twins can be used to scale up several carbon capture, storage, and removal systems. Credit: National Energy Technology Laboratory media team
One important focus for industrial use cases is the development of more efficient fuel conversion devices. The goal is to create devices that are more flexible so that the equipment can integrate with renewable resources in a more reliable way.
It is crucial to have better design optimization, uncertainty quantification, and accurate digital twins so that design and control of energy conversion devices can be handled adequately without causing billions of dollars in damage. AI is a natural choice to be used for developing such digital twins that can provide near real-time predictions without compromising the accuracy.
This post explains how the physics-informed machine learning (ML) framework, NVIDIA Modulus, is being used to bypass the conventional methods to enable large-scale scientific modeling, and to develop power plant digital twins that can help move towards net-zero carbon emissions.
Simulating industrial power plants with physics-ML
Flow field predictions for new operating conditions, such as changes in input conditions or geometrical configuration of the boiler components, require new computational fluid dynamics simulations. This can become very expensive and time consuming if simulations cover large parameters of space, such as those used for uncertainty quantification studies. Also, in most cases, the entirety of a flow field is not of interest. A neural network, once trained, can predict the flow field at the required points in the affected area in a fraction of a second.
Together with the National Energy Technology Laboratory (NETL), NVIDIA Modulus researchers are developing a digital twin of a power plant boiler capable of modeling turbulent reacting flows. The digital twin will use machine learning to replicate the flow conditions inside a boiler with a high level of fidelity, and be capable of providing near-instantaneous flow predictions for the operating conditions of interest.
Understanding of the internal velocity, temperature, and species fields is crucial for taking steps towards mitigating emission of greenhouse gasses and pollutants. Physics-informed ML, otherwise known as physics-ML, can be used to model predictive control to help plant operators optimize boiler operating conditions for efficiency and performance.
While not part of this study, it should be noted that digital twins can also be deployed for cybersecurity purposes to act as digital ghosts to distract intruders from the intended targets. These digital ghosts provide copies of the operating conditions with synthetic variations in the state of the system to the control room. If an intruder accesses control room data, they will not be able to distinguish between the real operational data and these copies. This framework can be extended to model other power plant components with moderate effort.
Enhancing proxy models with real-time feedback
The proxy model can also be coupled with the live feedback from sensors attached to the boiler to constantly improve itself with the assimilation of field data.
A typical power plant boiler includes dozens of concentration sensors, hundreds of temperature sensors, and thousands of sensors that measure the flow data. The placement of these sensors should be optimized so that the harsh boiler operating conditions, where temperatures can exceed 1,000℃, do not melt or damage these sensors. These sensors can provide a stream of data to the proxy model to constantly update the model through data assimilation and online learning to improve the model’s accuracy and reliability.
Additionally, a lot of uncertainty surrounds the parameters of physical models, such as reaction kinetics and viscosity. Using sensor data can reduce these uncertainties by assimilating field data into the proxy model. Failure to account for these uncertainties can cause significant monetary damages and power outages for days or even months.
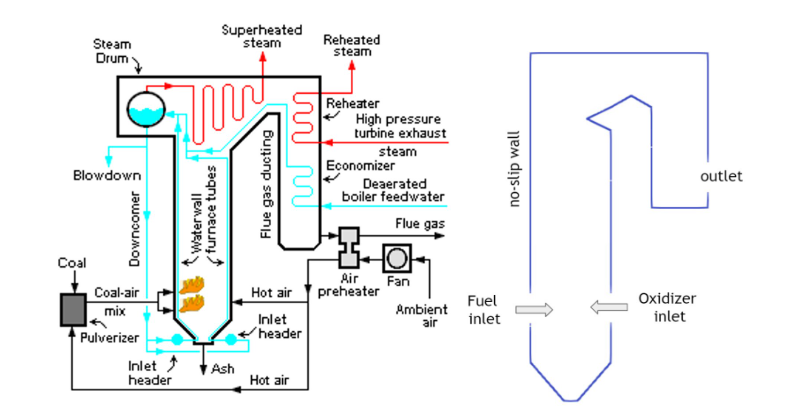
Figure 2. Due to power plant boilers’ complicated designs (left), this study uses a simplified version (right) to test for flow field, temperature, and species mass concentration. Credit: Mbeychok
Figure 2 illustrates the simplified boiler used in this study to solve for the flow field, temperature, and species mass concentration where methane and oxygen react to form carbon dioxide and water. The water flowing through the boiler tubes is heated and converted to vapor that is directed through the turbines for power generation. The reaction products, CO2 and H2O, are released into the air. If captured, they can be injected underground.
The oxidizer inlet velocity directly controls the flow conditions within the boiler, and subsequently its efficiency and performance. Changes in the oxidizer input velocity influences the combustion processes within the boiler which in turn, affects the temperature and species distributions throughout the system.
It is important to control the temperature inside the boiler as it directly influences the temperature and state of the working fluid, which in this study is water. This is so critical that the thermal constraints for different components outside of the boiler itself, including the water tubes and turbines, must be met.
Additionally, the oxidizer inlet velocity controls the amount of air that enters the reactor per unit time which directly affects the residence time of the species and the overall mixing behavior. If the residence time is too short, the reactions may not take place properly within the boiler and if it is too long, additional reactions leading to excessive pollutant emissions, such as CO, NOx, and CO2 may take place. Therefore, the inlet velocity is a key variable for optimizing the combustion processes and power generation.
Equation Name
Equation
Continuity
Species Mass Fraction
Momentum
Temperature
Kinetics-Controlled Single Step Irreversible Reaction
Species Source/Sink Terms
Temperature Source Term
Table 1. Commonly used equations to determine flow field, temperature, species mass concentration, and other key metrics for generic boiler environments
How to build a boiler digital twin using physics-informed ML
NVIDIA Modulus offers a collection of models that can be trained purely based on physics or data, or a combination of data and physics. By parameterizing these models, and leveraging the optimized inference pipeline, NVIDIA Modulus is capable of predicting the system behavior under varying operational and environmental conditions as a post-processing step.
As previously outlined, NVIDIA Modulus was used to develop a parameterized model trained on the governing laws of physics for a generic boiler. Once trained, this model provides near-instantaneous predictions of the temperature inside the boiler, species mass concentration, and flow velocity, and pressure for any given inlet velocity for species. No training data is used, and the loss function is formulated solely on how well the neural network solution satisfies the governing equations and the boundary conditions.
For this problem, the temperature at the inlets has been fixed at 650K, and the walls are at 350K.The parameter space for this simplified case is spanned by the varying oxidizer inlet velocity that ranges between 1 and 5 m/s.
A zero-equation formulation is used to model the turbulent Reynolds stresses. The Sinusoidal Representation Network (SiReN) in NVIDIA Modulus is used as the network architecture. A key component of this network architecture is the initialization scheme in which the weight matrices of the network are drawn from a uniform distribution. The input of each Sin activation has a normal distribution and the output of each Sin activation has an arcSin distribution. This preserves the distribution of activations allowing deep architectures to be constructed and trained effectively.
The first layer of the network is scaled by a factor to span multiple periods of the Sin function. This was empirically shown to give good performance and is in line with the benefits of the input encoding in the Fourier networks. Several NVIDIA Modulus features such as L2 to L1 loss decay and spatial loss weighting using Signed Distance Function (SDF) are used to improve accuracy. Time-to-convergence is minimized by utilizing NVIDIA Modulus performance upgrades such as Just-In-Time (JIT) compilation and CUDA graphs.
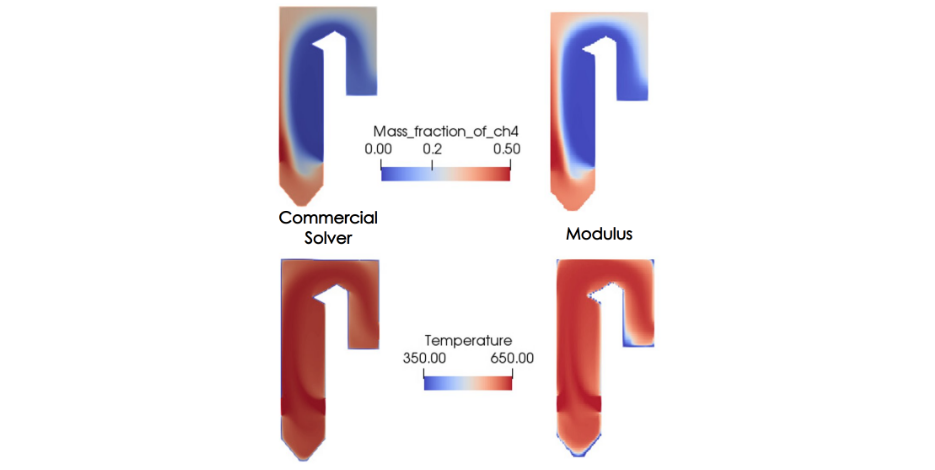
Figure 3. Species and temperature distributions designed in NVIDIA Modulus compare well against commercial solver results
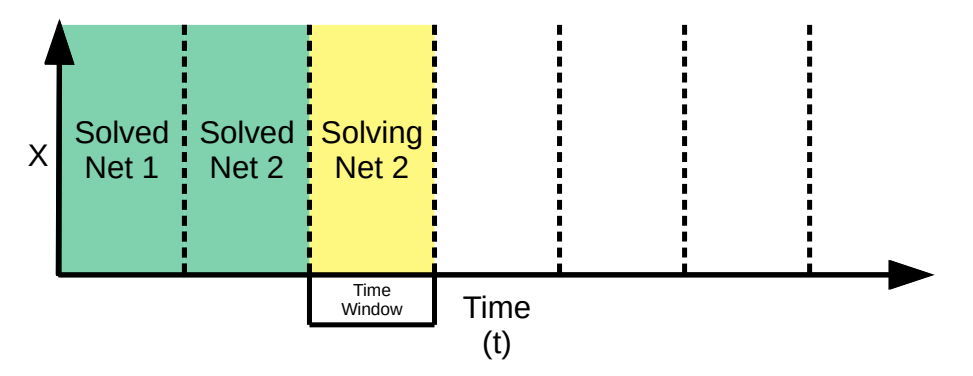
A moving-time window method developed by the NVIDIA Modulus team is used for transient flow modeling. Solving transient simulations with only the conventional continuous time method can be difficult for long time durations. The moving-time window method iteratively solves for small consecutive time windows. The continuous time method is used for solving inside a particular window, and the solution at the end of each time window is used as the initial condition for the next window.
Figure 4. The moving-time window method developed by NVIDIA Modulus researchers used to model transient flow
Selective Equation Terms Suppression
For modeling combustion, a novel approach developed by NETL researchers, called Selective Equation Terms Suppression (SETS), is used to drastically improve the training convergence.
For several partial differential equations (PDEs), the terms in the physical equations have different scales in time and magnitude (sometimes also known as stiff PDEs). For such PDEs, the loss equation can appear to be minimized despite poor treatment of the smaller terms.
Using the SETS approach to tackle this, you can create multiple instances of the same PDE and freeze certain terms. During the optimization process, this forces the optimizer to use the value from the former iteration for the frozen terms. Thus, the optimizer minimizes each term in the PDE and efficiently reduces the equation residual.
This prevents any one term in the PDE dominating the loss gradients. Creating multiple instances with different frozen terms in each instance allows the overall representation of the physics to remain the same, while allowing the neural networks to better learn the dynamic balance between all the terms in the equations.
However, creating multiple instances of the same equation (with different frozen terms) also creates multiple loss terms, each of which can be weighted differently. Several other formulations were also developed to efficiently handle the stiff PDEs:
Ramping up the source terms gradually during training to allow the neural networks to adjust better to the problem.
Having better control over the coupling between the species equations and the temperature equation by adjusting the order in which they are trained and their relative number of training instances.
Residual Normalization
Another novel approach used for improving the training convergence is Residual Normalization or ResNorm. The predominant approach used in loss balancing of the neural network solvers is to multiply a parameter to each of the individual loss terms to balance out the contribution of each term to the overall loss. However, tuning these parameters manually is not straightforward, and also requires treating these parameters as constants. ResNorm minimizes an additional loss term that encourages the individual losses to take similar relative magnitudes. The loss weights are dynamically tuned throughout the training based on the relative training rates of the different constraints.
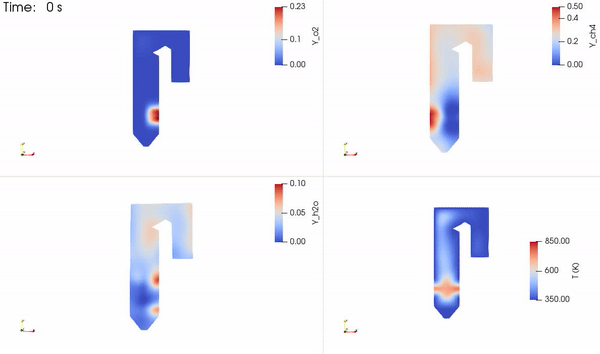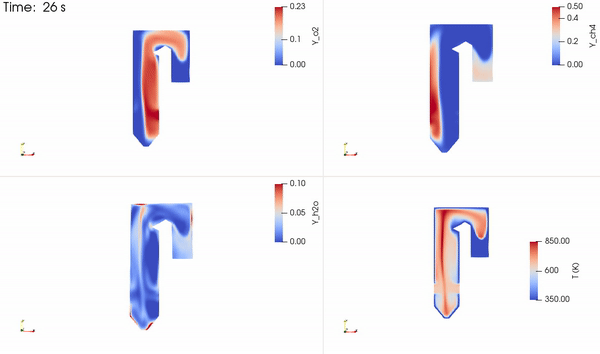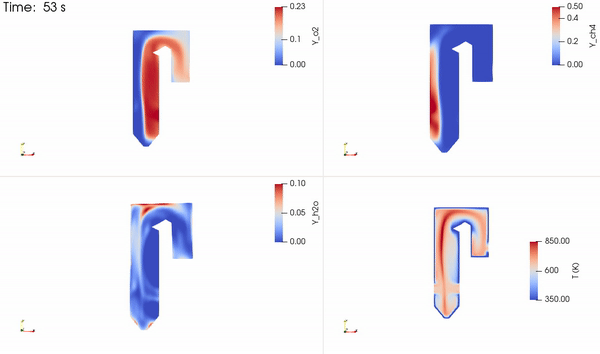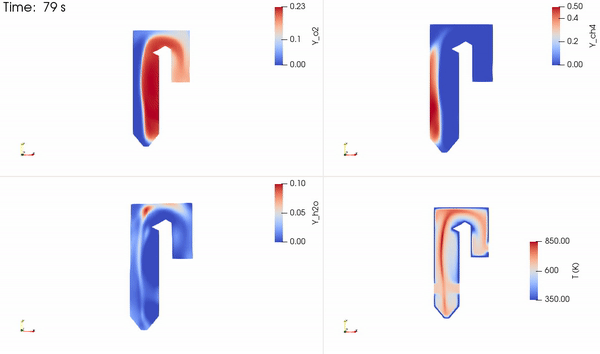
The distribution of the two reacting species, a product species and temperature, is shown in Figure 5. The reactants come into contact to form the thin reaction zone where products are formed. Energy is then released that increases the local temperature, which is advected and diffused throughout the domain.
Figure 5. Time evolution of the two reactants (O2+CH4), one product (H2O), and temperature fields obtained using NVIDIA Modulus PINN solver
3D design integration with NVIDIA Omniverse
NVIDIA Omniverse is an easily extensible platform for 3D design collaboration and scalable multi-GPU, real-time, true-to-reality simulation. The NVIDIA Omniverse extension for NVIDIA Modulus enables real-time, virtual-world simulation and full-design fidelity visualization. The built-in pipeline can be used for common visualizations such as streamlines and isosurfaces for the outputs of the NVIDIA Modulus model.
Another benefit from this integration is being able to visualize and analyze the high-fidelity simulation output in near real-time as the design parameters are varied. In the final part of the power plant boiler project, the NVIDIA Omniverse extension for NVIDIA Modulus will be used to develop a boiler digital twin that uses the final trained model to provide near-instantaneous prediction and visualization of the flow, temperature, pressure, and species mass concentration inside the boiler under varying operating conditions.
Figure 6. Components of an NVIDIA Omniverse digital twin for physical systems
Disclaimer: This project was funded by the United States Department of Energy, National Energy Technology Laboratory, in part, through a site support contract. Neither the United States Government nor any agency thereof, nor any of their employees, nor the support contractor, nor any of their employees, makes any warranty, express or implied, or assumes any legal liability or responsibility for the accuracy, completeness, or usefulness of any information, apparatus, product, or process disclosed, or represents that its use would not infringe privately owned rights. Reference herein to any specific commercial product, process, or service by trade name, trademark, manufacturer, or otherwise does not necessarily constitute or imply its endorsement, recommendation, or favoring by the United States Government or any agency thereof. The views and opinions of authors expressed herein do not necessarily state or reflect those of the United States Government or any agency thereof.
Green computing, also called sustainable computing, aims to maximize energy efficiency and minimize environmental impact in the ways computer chips, systems,…
Green computing, also called sustainable computing, aims to maximize energy efficiency and minimize environmental impact in the ways computer chips, systems, and software are designed and used.
Many organizations today run applications in containers to take advantage of the powerful orchestration and management provided by cloud-native platforms based…
Many organizations today run applications in containers to take advantage of the powerful orchestration and management provided by cloud-native platforms based on Kubernetes. However, virtual machines continue to remain as the predominant data center infrastructure platform for enterprises, and not all applications can be easily modified to run in containers. For example, applications requiring older operating systems, custom kernel modules, or specialized hardware require more effort to containerize.
KubeVirt and OpenShift Virtualization are add-ons to Kubernetes that provide virtual machine (VM) management. These solutions eliminate the need to manage separate clusters for VM and container workloads. KubeVirt is a community-supported open source project, and it also serves as the upstream project for the OpenShift Virtualization feature from Red Hat.
NVIDIA GPUs have been accelerating applications that are virtualized for many years, and NVIDIA has also created technology to support GPU acceleration for containers managed by Kubernetes. The latest release of the NVIDIA GPU Operator adds support for KubeVirt and OpenShift Virtualization. Now, GPU-accelerated applications running as virtual machines can be orchestrated by Kubernetes too, just like ordinary enterprise applications, enabling unified management.
GPUs in KubeVirt and OpenShift Virtualization
NVIDIA GPU Operator v22.9 enables GPU-accelerated containers and GPU-accelerated virtual machines, using either NVIDIA Virtual GPU (vGPU) or PCI passthrough, to run alongside each other in the same cluster. This version introduces new software components that support virtual machines.
Additionally, the operator is responsible for providing automation to manage the deployment, configuration, and lifecycle of this software, easing the operational overhead on cluster administrators. More detailed information about these components is provided below.
The vfio-pci driver (Virtual Function I/O) provides a secure user space driver that is needed when using a physical GPU for PCI passthrough. PCI passthrough presents the entire GPU as a PCI device to a virtual machine. When using PCI passthrough, the GPU cannot be shared, but provides the highest performance.
The NVIDIAvGPU Manager is the driver installed on the hypervisor that enables NVIDIA Virtual GPU technology. NVIDIA vGPU enables multiple virtual machines to have simultaneous, time-based shared access to a single physical GPU.
The NVIDIAvGPU Device Manager is responsible for interacting with the vGPU Manager and creating vGPU devices on the worker node.
The NVIDIA KubeVirt device plug-in discovers and advertises both physical and NVIDIA vGPU devices to kubelet so that they can be requested and assigned to VMs. Kubelet is an agent running on every node in the cluster, responsible for communication between the node and the Kubernetes control plane.
Planning for deployment
Prior to deployment, it is important to be aware of some of the limitations. Currently, MIG-backed vGPU instances are not supported. Additionally, a given GPU worker node can only run GPU workloads of single type—containers, VMs with PCI passthrough, or VMs with NVIDIA vGPU—but not a combination.
To enable this new functionality, set sandboxWorkloads.enabled to true in ClusterPolicy. When enabled, the GPU Operator will manage and deploy the new software components needed for supporting virtual machines. This option is disabled by default, meaning that the GPU Operator will only provision worker nodes for container workloads.
Administrators have the ability to control where workloads get deployed through the use of Kubernetes node labels. GPU Operator v22.9 introduces a new node label, nvidia.com/gpu.workload.config, which dictates which software components get deployed by the GPU Operator and consequently controls what type of GPU workloads a node supports. This node label can take on the values container,vm-passthrough, and vm-vgpu which correspond to the different workloads now supported.
This concept allows administrators to have pools of machine types, each with different capabilities, and managed by a common control plane. If the nvidia.com/gpu.workload.confignode label is not present on a GPU worker node, the GPU Operator will use the default workload type, which is configurable in ClusterPolicy through the sandboxWorkloads.defaultWorkloadfield.
Conclusion
GPU Operator v22.9 brings with it additional capabilities required to run GPU-powered workloads on Kubernetes with KubeVirt and OpenShift Virtualization. VMs in Kubernetes can attach GPU devices using PCI passthrough or NVIDIA vGPU. This flexibility speeds the adoption of cloud-native platforms by removing the need to refactor GPU-accelerated applications to support containerization. Administrators can continue to run these applications in VMs alongside other container native applications, with Kubernetes performing the orchestration.
One of the biggest names in racing is going even bigger. Performance automaker Lotus launched its first SUV, the Eletre, earlier this week. The fully electric vehicle sacrifices little in terms of speed and outperforms when it comes to technology. It features an immersive digital cockpit, lengthy battery range of up to 370 miles and Read article >
Artists deploying the critically acclaimed GeForce RTX 4090 GPUs are primed to receive significant performance boosts in key creative apps. Plus, a special spook-tober edition of In the NVIDIA Studio features two talented 3D artists and their Halloween-themed creations this week.
The future is autonomous, and AI is already transforming the transportation industry. But what exactly is an autonomous vehicle and how does it work? Autonomous…
The future is autonomous, and AI is already transforming the transportation industry. But what exactly is an autonomous vehicle and how does it work?
Autonomous vehicles are born in the data center. They require a combination of sensors, high-performance hardware, software, and high-definition mapping to operate without a human at the wheel. While the concept of this technology has existed for decades, production self-driving systems have just recently become possible due to breakthroughs in AI and compute.
Specifically, massive leaps in high-performance computing have opened new possibilities in developing, training, testing, validating, and operating autonomous vehicles. The Introduction to Autonomous Vehicles GTC session walks through these breakthroughs, how current self-driving technology works, and what’s on the horizon for intelligent transportation.
From the cloud
The deep neural networks that run in the vehicle are trained on massive amounts of driving data. They must learn how to identify and react to objects in the real world—an incredibly time-consuming and costly process.
A test fleet of 50 vehicles generates about 1.6 petabytes of data each day, which must be ingested, encoded, and stored before any further processing can be done.
Then, the data must be combed through to find scenarios useful for training, such as new situations or situations underrepresented in the current dataset. These useful frames typically amount to just 10% of the total collected data.
You must then label every object in the scene, including traffic lights and signs, vehicles, pedestrians, and animals, so that the DNNs can learn to identify them as well as checking for accuracy.
NVIDIA DGX data center solutions have made this onerous process into a streamlined operation by providing a veritable data factory for training and testing. With high-performance compute, you can automate the curation and labeling process, as well as run many DNN tests in parallel.
When a new model or set of models is ready to be deployed, you can then validate the networks by replaying the model against thousands of hours of driving scenarios in the data center. Simulation also provides the capability to test these models in the countless edge cases an autonomous vehicle could encounter in the real world.
NVIDIA DRIVE Sim is built on NVIDIA Omniverse to deliver a powerful, cloud-based simulation platform capable of generating a wide range of real-world scenarios for AV development and validation. It creates highly accurate, digital twins of real-world environments using precision map data.
Figure 1. NVIDIA DRIVE Sim provides a physically accurate digital twin of the world for comprehensive AV validation
It can run just the AV software, which is known as software-in-the-loop, or the software running on the same compute as it would in the vehicle for hardware-in-the-loop testing.
You can truly tailor situations to your specific needs using the NVIDIA DRIVE Replicator tool, which can generate entirely new data. These scenarios include physically based sensor data, along with the corresponding ground truth, to complement real-world driving data and reduce the time and cost of development.
To the car
Validated deep neural networks run in the vehicle on centralized, high-performance AI compute.
Redundant and diverse sensors, including camera, radar, lidar, and ultrasonics, collect data from the surrounding environment as the car drives. The DNNs use this data to detect objects and infer information to make driving decisions.
Processing this data while running multiple DNNs concurrently requires an incredibly high-performance AI platform.
NVIDIA DRIVE Orin is a highly advanced, software-defined compute platform for autonomous vehicles. It achieves 254 trillion operations per second, enough to handle these functions while achieving systematic safety standards for public road operations.
Figure 2. NVIDIA DRIVE Orin is the current generation software-defined platform for centralized autonomous vehicle compute
In addition to DNNs for perception, AVs rely on maps with centimeter-level detail for accurate localization, which is the vehicle’s ability to locate itself in the world.
Proper localization requires constantly updated maps that reflect current road conditions, such as a work zone or a lane closure, so vehicles can accurately measure distances in the environment. These maps must efficiently scale across AV fleets, with fast processing and minimal data storage. Finally, they must be able to function worldwide, so AVs can operate at scale.
NVIDIA DRIVE Map is a multimodal mapping platform designed to enable the highest levels of autonomy while improving safety. It combines survey maps built by dedicated mapping vehicles with AI-based crowdsourced mapping from customer vehicles. DRIVE Map includes four localization layers—camera, lidar, radar, and GNSS—providing the redundancy and versatility required by the most advanced AI drivers.
Continuous improvement
The AV development process isn’t linear. As humans, we never stop learning, and AI operates in the same way.
Autonomous vehicles will continue to get smarter over time as the software is trained for new tasks, enhanced, tested, and validated, then updated to the vehicle over the air.
This pipeline is continuous, with data from the vehicle constantly being collected to continuously train and improve the networks, which are then fed back into the vehicle. AI is used at all stages of the real-time computing pipeline, from perception, mapping, and localization to planning and control.
This continuous cycle is what turns vehicles from their traditional fixed-function operation to software-defined devices. Most vehicles are as advanced as they will ever be at the point of sale. With this new software-defined architecture, automakers can continually update vehicles throughout their lives with new features and functionality.
One of China’s popular battery-electric startups now has the brains to boot. NETA Auto, a Zheijiang-based electric automaker, this week announced it will build its future electric vehicles on the NVIDIA DRIVE Orin platform. These EVs will be software defined, with automated driving and intelligent features that will be continuously upgraded via over-the-air updates. This Read article >

 Everyone agrees that open solutions are the best solutions but, there are few truly open operating systems for Ethernet switches. At NVIDIA, we embraced open…
Everyone agrees that open solutions are the best solutions but, there are few truly open operating systems for Ethernet switches. At NVIDIA, we embraced open…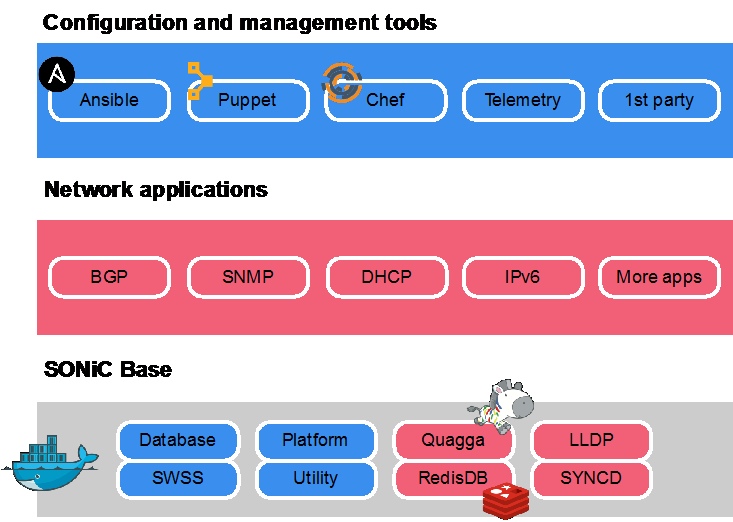



 Humanity has seen major scientific breakthroughs directly related to discoveries that do not share the glamor of the breakthrough they enabled. Sir Alexander…
Humanity has seen major scientific breakthroughs directly related to discoveries that do not share the glamor of the breakthrough they enabled. Sir Alexander…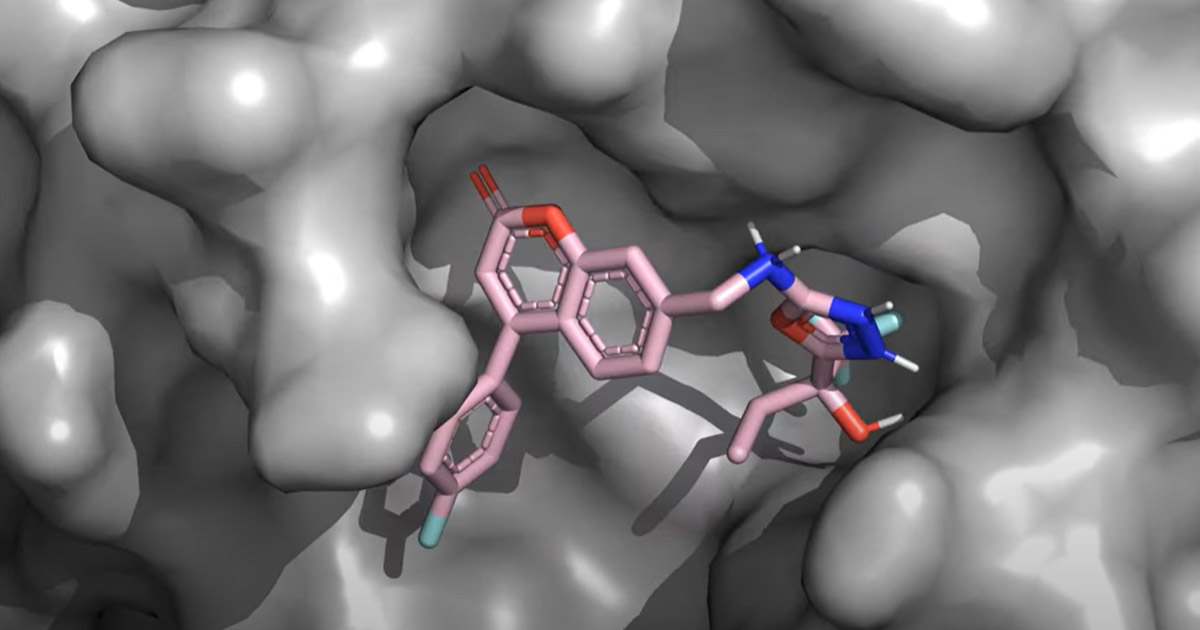
 A digital twin is a virtual representation synchronized with physical things, people, or processes.
A digital twin is a virtual representation synchronized with physical things, people, or processes. Reducing the amount of carbon released to the atmosphere is a political priority. The current U.S. administration plans to achieve net-zero carbon emissions…
Reducing the amount of carbon released to the atmosphere is a political priority. The current U.S. administration plans to achieve net-zero carbon emissions…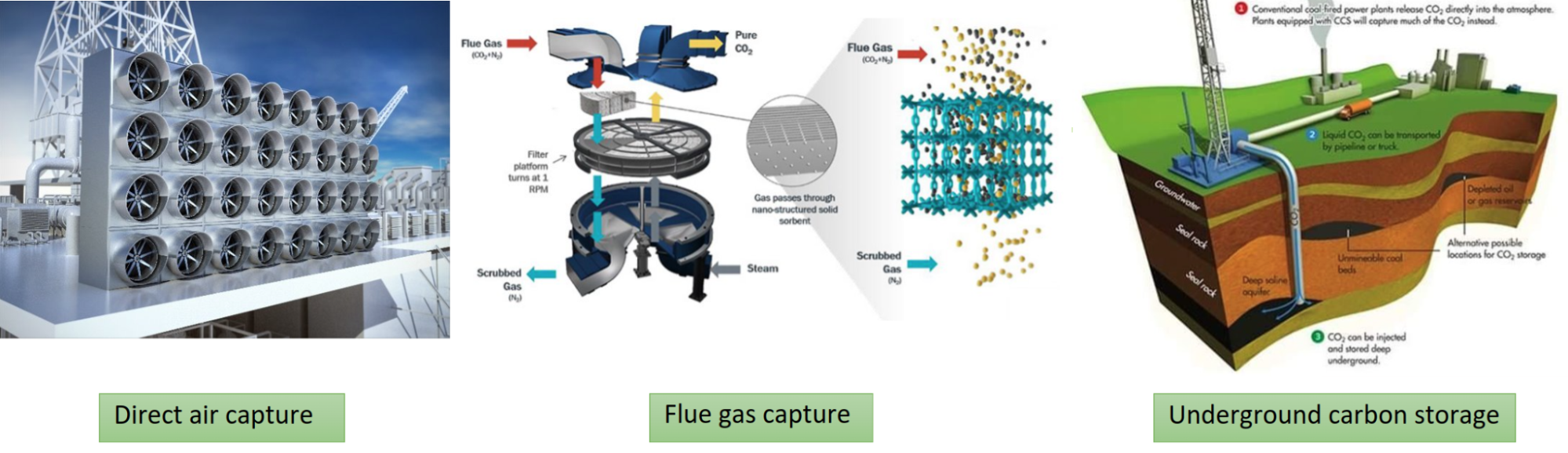





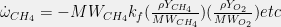

 Green computing, also called sustainable computing, aims to maximize energy efficiency and minimize environmental impact in the ways computer chips, systems,…
Green computing, also called sustainable computing, aims to maximize energy efficiency and minimize environmental impact in the ways computer chips, systems,…") Many organizations today run applications in containers to take advantage of the powerful orchestration and management provided by cloud-native platforms based…
Many organizations today run applications in containers to take advantage of the powerful orchestration and management provided by cloud-native platforms based… The future is autonomous, and AI is already transforming the transportation industry. But what exactly is an autonomous vehicle and how does it work? Autonomous…
The future is autonomous, and AI is already transforming the transportation industry. But what exactly is an autonomous vehicle and how does it work? Autonomous…
