
Large language model development is about to reach supersonic speed thanks to a collaboration between NVIDIA and Anyscale. At its annual Ray Summit developers conference, Anyscale — the company behind the fast growing open-source unified compute framework for scalable computing — announced today that it is bringing NVIDIA AI to Ray open source and the Read article >
Month: September 2023

In recent years, we have witnessed rising interest across consumers and researchers in integrated augmented reality (AR) experiences using real-time face feature generation and editing functions in mobile applications, including short videos, virtual reality, and gaming. As a result, there is a growing demand for lightweight, yet high-quality face generation and editing models, which are often based on generative adversarial network (GAN) techniques. However, the majority of GAN models suffer from high computational complexity and the need for a large training dataset. In addition, it is also important to employ GAN models responsibly.
In this post, we introduce MediaPipe FaceStylizer, an efficient design for few-shot face stylization that addresses the aforementioned model complexity and data efficiency challenges while being guided by Google’s responsible AI Principles. The model consists of a face generator and a face encoder used as GAN inversion to map the image into latent code for the generator. We introduce a mobile-friendly synthesis network for the face generator with an auxiliary head that converts features to RGB at each level of the generator to generate high quality images from coarse to fine granularities. We also carefully designed the loss functions for the aforementioned auxiliary heads and combined them with the common GAN loss functions to distill the student generator from the teacher StyleGAN model, resulting in a lightweight model that maintains high generation quality. The proposed solution is available in open source through MediaPipe. Users can fine-tune the generator to learn a style from one or a few images using MediaPipe Model Maker, and deploy to on-device face stylization applications with the customized model using MediaPipe FaceStylizer.
Few-shot on-device face stylization
An end-to-end pipeline
Our goal is to build a pipeline to support users to adapt the MediaPipe FaceStylizer to different styles by fine-tuning the model with a few examples. To enable such a face stylization pipeline, we built the pipeline with a GAN inversion encoder and efficient face generator model (see below). The encoder and generator pipeline can then be adapted to different styles via a few-shot learning process. The user first sends a single or a few similar samples of the style images to MediaPipe ModelMaker to fine-tune the model. The fine-tuning process freezes the encoder module and only fine-tunes the generator. The training process samples multiple latent codes close to the encoding output of the input style images as the input to the generator. The generator is then trained to reconstruct an image of a person’s face in the style of the input style image by optimizing a joint adversarial loss function that also accounts for style and content. With such a fine-tuning process, the MediaPipe FaceStylizer can adapt to the customized style, which approximates the user’s input. It can then be applied to stylize test images of real human faces.
Generator: BlazeStyleGAN
The StyleGAN model family has been widely adopted for face generation and various face editing tasks. To support efficient on-device face generation, we based the design of our generator on StyleGAN. This generator, which we call BlazeStyleGAN, is similar to StyleGAN in that it also contains a mapping network and synthesis network. However, since the synthesis network of StyleGAN is the major contributor to the model’s high computation complexity, we designed and employed a more efficient synthesis network. The improved efficiency and generation quality is achieved by:
- Reducing the latent feature dimension in the synthesis network to a quarter of the resolution of the counterpart layers in the teacher StyleGAN,
- Designing multiple auxiliary heads to transform the downscaled feature to the image domain to form a coarse-to-fine image pyramid to evaluate the perceptual quality of the reconstruction, and
- Skipping all but the final auxiliary head at inference time.
With the newly designed architecture, we train the BlazeStyleGAN model by distilling it from a teacher StyleGAN model. We use a multi-scale perceptual loss and adversarial loss in the distillation to transfer the high fidelity generation capability from the teacher model to the student BlazeStyleGAN model and also to mitigate the artifacts from the teacher model.
More details of the model architecture and training scheme can be found in our paper.
 |
| Visual comparison between face samples generated by StyleGAN and BlazeStyleGAN. The images on the first row are generated by the teacher StyleGAN. The images on the second row are generated by the student BlazeStyleGAN. The face generated by BlazeStyleGAN has similar visual quality to the image generated by the teacher model. Some results demonstrate the student BlazeStyleGAN suppresses the artifacts from the teacher model in the distillation. |
In the above figure, we demonstrate some sample results of our BlazeStyleGAN. By comparing with the face image generated by the teacher StyleGAN model (top row), the images generated by the student BlazeStyleGAN (bottom row) maintain high visual quality and further reduce artifacts produced by the teacher due to the loss function design in our distillation.
An encoder for efficient GAN inversion
To support image-to-image stylization, we also introduced an efficient GAN inversion as the encoder to map input images to the latent space of the generator. The encoder is defined by a MobileNet V2 backbone and trained with natural face images. The loss is defined as a combination of image perceptual quality loss, which measures the content difference, style similarity and embedding distance, as well as the L1 loss between the input images and reconstructed images.
On-device performance
We documented model complexities in terms of parameter numbers and computing FLOPs in the following table. Compared to the teacher StyleGAN (33.2M parameters), BlazeStyleGAN (generator) significantly reduces the model complexity, with only 2.01M parameters and 1.28G FLOPs for output resolution 256×256. Compared to StyleGAN-1024 (generating image size of 1024×1024), the BlazeStyleGAN-1024 can reduce both model size and computation complexity by 95% with no notable quality difference and can even suppress the artifacts from the teacher StyleGAN model.
| Model | Image Size | #Params (M) | FLOPs (G) | |||
| StyleGAN | 1024 | 33.17 | 74.3 | |||
| BlazeStyleGAN | 1024 | 2.07 | 4.70 | |||
| BlazeStyleGAN | 512 | 2.05 | 1.57 | |||
| BlazeStyleGAN | 256 | 2.01 | 1.28 | |||
| Encoder | 256 | 1.44 | 0.60 |
| Model complexity measured by parameter numbers and FLOPs. |
We benchmarked the inference time of the MediaPipe FaceStylizer on various high-end mobile devices and demonstrated the results in the table below. From the results, both BlazeStyleGAN-256 and BlazeStyleGAN-512 achieved real-time performance on all GPU devices. It can run in less than 10 ms runtime on a high-end phone’s GPU. BlazeStyleGAN-256 can also achieve real-time performance on the iOS devices’ CPU.
| Model | BlazeStyleGAN-256 (ms) | Encoder-256 (ms) | ||
| iPhone 11 | 12.14 | 11.48 | ||
| iPhone 12 | 11.99 | 12.25 | ||
| iPhone 13 Pro | 7.22 | 5.41 | ||
| Pixel 6 | 12.24 | 11.23 | ||
| Samsung Galaxy S10 | 17.01 | 12.70 | ||
| Samsung Galaxy S20 | 8.95 | 8.20 |
| Latency benchmark of the BlazeStyleGAN, face encoder, and the end-to-end pipeline on various mobile devices. |
Fairness evaluation
The model has been trained with a high diversity dataset of human faces. The model is expected to be fair to different human faces. The fairness evaluation demonstrates the model performs good and balanced in terms of human gender, skin-tone, and ages.
Face stylization visualization
Some face stylization results are demonstrated in the following figure. The images in the top row (in orange boxes) represent the style images used to fine-tune the model. The images in the left column (in the green boxes) are the natural face images used for testing. The 2×4 matrix of images represents the output of the MediaPipe FaceStylizer which is blending outputs between the natural faces on the left-most column and the corresponding face styles on the top row. The results demonstrate that our solution can achieve high-quality face stylization for several popular styles.
 |
| Sample results of our MediaPipe FaceStylizer. |
MediaPipe Solutions
The MediaPipe FaceStylizer is going to be released to public users in MediaPipe Solutions. Users can leverage MediaPipe Model Maker to train a customized face stylization model using their own style images. After training, the exported bundle of TFLite model files can be deployed to applications across platforms (Android, iOS, Web, Python, etc.) using the MediaPipe Tasks FaceStylizer API in just a few lines of code.
Acknowledgements
This work is made possible through a collaboration spanning several teams across Google. We’d like to acknowledge contributions from Omer Tov, Yang Zhao, Andrey Vakunov, Fei Deng, Ariel Ephrat, Inbar Mosseri, Lu Wang, Chuo-Ling Chang, Tingbo Hou, and Matthias Grundmann.

In today’s digital age, smartphones and desktop web browsers serve as the primary tools for accessing news and information. However, the proliferation of website clutter — encompassing complex layouts, navigation elements, and extraneous links — significantly impairs both the reading experience and article navigation. This issue is particularly acute for individuals with accessibility requirements.
To improve the user experience and make reading more accessible, Android and Chrome users may leverage the Reading Mode feature, which enhances accessibility by processing webpages to allow customizable contrast, adjustable text size, more legible fonts, and to enable text-to-speech utilities. Additionally, Android’s Reading Mode is equipped to distill content from apps. Expanding Reading Mode to encompass a wide array of content and improving its performance, while still operating locally on the user’s device without transmitting data externally, poses a unique challenge.
To broaden Reading Mode capabilities without compromising privacy, we have developed a novel on-device content distillation model. Unlike early attempts using DOM Distiller — a heuristic approach limited to news articles — our model excels in both quality and versatility across various types of content. We ensure that article content doesn’t leave the confines of the local environment. Our on-device content distillation model smoothly transforms long-form content into a simple and customizable layout for a more pleasant reading journey while also outperforming the leading alternative approaches. Here we explore details of this research highlighting our approach, methodology, and results.
Graph neural networks
Instead of relying on complicated heuristics that are difficult to maintain and scale to a variety of article layouts, we approach this task as a fully supervised learning problem. This data-driven approach allows the model to generalize better across different layouts, without the constraints and fragility of heuristics. Previous work for optimizing the reading experience relied on HTML or parsing, filtering, and modeling of a document object model (DOM), a programming interface automatically generated by the user’s web browser from site HTML that represents the structure of a document and allows it to be manipulated.
The new Reading Mode model relies on accessibility trees, which provide a streamlined and more accessible representation of the DOM. Accessibility trees are automatically generated from the DOM tree and are utilized by assistive technologies to allow people with disabilities to interact with web content. These are available on Chrome Web browser and on Android through AccessibilityNodeInfo objects, which are provided for both WebView and native application content.
We started by manually collecting and annotating accessibility trees. The Android dataset used for this project comprises on the order of 10k labeled examples, while the Chrome dataset contains approximately 100k labeled examples. We developed a novel tool that uses graph neural networks (GNNs) to distill essential content from the accessibility trees using a multi-class supervised learning approach. The datasets consist of long-form articles sampled from the web and labeled with classes such as headline, paragraph, images, publication date, etc.
GNNs are a natural choice for dealing with tree-like data structures, because unlike traditional models that often demand detailed, hand-crafted features to understand the layout and links within such trees, GNNs learn these connections naturally. To illustrate this, consider the analogy of a family tree. In such a tree, each node represents a family member and the connections denote familial relationships. If one were to predict certain traits using conventional models, features like the “number of immediate family members with a trait” might be needed. However, with GNNs, such manual feature crafting becomes redundant. By directly feeding the tree structure into the model, GNNs utilize a message-passing mechanism where each node communicates with its neighbors. Over time, information gets shared and accumulated across the network, enabling the model to naturally discern intricate relationships.
Returning to the context of accessibility trees, this means that GNNs can efficiently distill content by understanding and leveraging the inherent structure and relationships within the tree. This capability allows them to identify and possibly omit non-essential sections based on the information flow within the tree, ensuring more accurate content distillation.
Our architecture heavily follows the encode-process-decode paradigm using a message-passing neural network to classify text nodes. The overall design is illustrated in the figure below. The tree representation of the article is the input to the model. We compute lightweight features based on bounding box information, text information, and accessibility roles. The GNN then propagates each node’s latent representation through the edges of the tree using a message-passing neural network. This propagation process allows nearby nodes, containers, and text elements to share contextual information with each other, enhancing the model’s understanding of the page’s structure and content. Each node then updates its current state based on the message received, providing a more informed basis for classifying the nodes. After a fixed number of message-passing steps, the now contextualized latent representations of the nodes are decoded into essential or non-essential classes. This approach enables the model to leverage both the inherent relationships in the tree and the hand-crafted features representing each node, thereby enriching the final classification.
 |
| A visual demonstration of the algorithm in action, processing an article on a mobile device. A graph neural network (GNN) is used to distill essential content from an article. 1. A tree representation of the article is extracted from the application. 2. Lightweight features are computed for each node, represented as vectors. 3. A message-passing neural network propagates information through the edges of the tree and updates each node representation. 4. Leaf nodes containing text content are classified as essential or non-essential content. 5. A decluttered version of the application is composed based on the GNN output. |
We deliberately restrict the feature set used by the model to increase its broad generalization across languages and speed up inference latency on user devices. This was a unique challenge, as we needed to create an on-device lightweight model that could preserve privacy.
Our final lightweight Android model has 64k parameters and is 334kB in size with a median latency of 800ms, while the Chrome model has 241k parameters, is 928kB in size, and has a 378ms median latency. By employing such on-device processing, we ensure that user data never leaves the device, reinforcing our responsible approach and commitment to user privacy. The features used in the model can be grouped into intermediate node features, leaf-node text features, and element position features. We performed feature engineering and feature selection to optimize the set of features for model performance and model size. The final model was transformed into TensorFlow Lite format to deploy as an on-device model on Android or Chrome.
Results
We trained the GNN for about 50 epochs in a single GPU. The performance of the Android model on webpages and native application test sets is presented below:
 |
| The table presents the content distillation metrics in Android for webpages and native apps. We report precision, recall and F1-score for three classes: non-essential content, headline, and main body text, including macro average and weighted average by number of instances in each class. Node metrics assess the classification performance at the granularity of the accessibility tree node, which is analogous to a paragraph level. In contrast, word metrics evaluate classification at an individual word level, meaning each word within a node gets the same classification. |
<!–
| Android Quality | ||||||||||||
| Webpages | Native Apps | |||||||||||
| node metrics | Precision | Recall | F1-score | Precision | Recall | F1-score | ||||||
| non-essential | 0.9842 | 0.9846 | 0.9844 | 0.9744 | 0.9350 | 0.9543 | ||||||
| headline | 0.9187 | 0.9784 | 0.9476 | 0.9183 | 0.8568 | 0.8865 | ||||||
| main-text | 0.9223 | 0.9172 | 0.9197 | 0.8443 | 0.9424 | 0.8907 | ||||||
| macro-average | 0.9417 | 0.9600 | 0.9506 | 0.9124 | 0.9114 | 0.9105 | ||||||
| weighted average | 0.9736 | 0.9736 | 0.9736 | 0.9392 | 0.9353 | 0.9363 | ||||||
| headline + main-text | 0.9510 | 0.9683 | 0.9595 | 0.9473 | 0.9507 | 0.9490 | ||||||
| The table presents the content distillation metrics in Android for webpages and native apps. We report precision, recall and F1-score for three classes: non-essential content, headline, and main body text, including macro average and weighted average by number of instances in each class. Node metrics assess the classification performance at the granularity of the accessibility tree node, which is analogous to a paragraph level. In contrast, word metrics evaluate classification at an individual word level, meaning each word within a node gets the same classification. |
–>
In assessing the results’ quality on commonly visited webpage articles, an F1-score exceeding 0.9 for main-text (essentially paragraphs) corresponds to 88% of these articles being processed without missing any paragraphs. Furthermore, in over 95% of cases, the distillation proves to be valuable for readers. Put simply, the vast majority of readers will perceive the distilled content as both pertinent and precise, with errors or omissions being an infrequent occurrence.
The comparison of Chrome content distillation with other models such as DOM Distiller or Mozilla Readability on a set of English language pages is presented in the table below. We reuse the metrics from machine translation to compare the quality of these models. The reference text is from the groundtruth main content and the text from the models as hypothesis text. The results show the excellent performance of our models in comparison to other DOM-based approaches.
 |
| The table presents the comparison between DOM-Distiller, Mozilla Readability and the new Chrome model. We report text-based metrics, such as BLUE, CHRF and ROUGE, by comparing the main body text distilled from each model to a ground-truth text manually labeled by raters using our annotation policy. |
<!–
| Chrome Model Comparison on Webpages | ||||||
| Metric / Model | DOM Distiller | Mozilla Readability | Our Chrome model | |||
| BLEU | 78.97 | 79.16 | 94.59 | |||
| CHRF | 0.92 | 0.92 | 0.98 | |||
| ROUGE1 | 84.10 | 84.62 | 95.13 | |||
| ROUGE2 | 81.84 | 82.66 | 94.81 | |||
| ROUGE3 | 80.21 | 81.45 | 94.60 | |||
| ROUGEL | 83.58 | 84.02 | 95.04 | |||
| ROUGEL-SUM | 83.46 | 84.03 | 95.04 | |||
| The table presents the comparison between DOM-Distiller, Mozilla Readability and the new Chrome model. We report text-based metrics, such as BLUE, CHRF and ROUGE, by comparing the main body text distilled from each model to a ground-truth text manually labeled by raters using our annotation policy. |
–>
The F1-score of the Chrome content distillation model for headline and main text content on the test sets of different widely spoken languages demonstrates that the Chrome model, in particular, is able to support a wide range of languages.
 |
| The table presents per language of F1-scores of the Chrome model for the headline and main text classes. The language codes correspond to the following languages: German, English, Spanish, French, Italian, Persian, Japanese, Korean, Portuguese, Vietnamese, simplified Chinese and traditional Chinese. |
<!–
| Chrome Model on Different Languages | ||||||||||||||||||||||||||
| F1-score | de | en | es | fr | it | fa | ja | ko | pt | vi | zh-Hans | zh-Hant | average | |||||||||||||
| headline | 0.91 | 0.97 | 0.99 | 0.98 | 0.97 | 0.89 | 0.97 | 0.98 | 0.99 | 0.98 | 0.97 | 0.93 | 0.96 | |||||||||||||
| main text | 0.84 | 0.90 | 0.93 | 0.91 | 0.93 | 0.87 | 0.88 | 0.91 | 0.91 | 0.90 | 0.90 | 0.90 | 0.90 | |||||||||||||
| The table presents per language of F1-scores of the Chrome model for the headline and main text classes. The language codes correspond to the following languages: German, English, Spanish, French, Italian, Persian, Japanese, Korean, Portuguese, Vietnamese, simplified Chinese and traditional Chinese. |
–>
Conclusion
The digital age demands both streamlined content presentation and an unwavering commitment to user privacy. Our research highlights the effectiveness of Reading Mode in platforms like Android and Chrome, offering an innovative, data-driven approach to content parsing through Graph Neural Networks. Crucially, our lightweight on-device model ensures that content distillation occurs without compromising user data, with all processes executed locally. This not only enhances the reading experience but also reinforces our dedication to user privacy. As we navigate the evolving landscape of digital content consumption, our findings underscore the paramount importance of prioritizing the user in both experience and security.
Acknowledgements
This project is the result of joint work with Manuel Tragut, Mihai Popa, Abodunrinwa Toki, Abhanshu Sharma, Matt Sharifi, David Petrou and Blaise Aguera y Arcas. We sincerely thank our collaborators Gang Li and Yang Li. We are very grateful to Tom Small for assisting us in preparing the post.
 The broadcast industry is undergoing a transformation in how content is created, managed, distributed, and consumed. This transformation includes a shift from…
The broadcast industry is undergoing a transformation in how content is created, managed, distributed, and consumed. This transformation includes a shift from…
The broadcast industry is undergoing a transformation in how content is created, managed, distributed, and consumed. This transformation includes a shift from traditional linear workflows bound by fixed-function devices to flexible and hybrid, software-defined systems that enable the future of live streaming.
Developers can now apply to join the early access program for NVIDIA Holoscan for Media, a software-defined platform for developing and deploying media applications on-prem, in the cloud, and at the edge.
Using Holoscan for Media, broadcasters and solution providers can leverage the latest IT and provisioning technologies and a modern container-based approach to development, orchestration, and delivery.
Holoscan for Media is an IP-based solution built on industry standards and APIs including SMPTE ST 2110, AMWA NMOS, RIST, SRT, and NDI.
The platform integrates open-source and ubiquitous technologies, breaking from the proprietary and inflexible nature of SDI and FPGA-based systems. It also enables incorporation of the latest capabilities in production—such as generative AI—without additional infrastructure investments. With Holoscan for Media, countless NVIDIA application frameworks and SDKs are made accessible to the industry for development.
This framework provides several benefits to both broadcasters and solution providers, including:
- Repurposability: Use a single platform for many applications.
- Lower TCO: Benefit from the cyclical cost reductions.
- Flexibility: The platform is cloud-native and independent of location. An application can be developed once and deployed everywhere.
- Sustainability: Provisioning technologies that drive resource sharing means that overall less equipment is required. This means lower power and cooling costs and reduced impact from shipping to and from events. Ultimately, this leads to CO2 reductions.
IP-based platform architecture
NVIDIA Holoscan targets sensor data and media processing applications deployed at-scale across countless industries, in the cloud, on premises, and at the edge. Holoscan for Media tightens the focus on broadcast and live production workflows, with the first target being on-premises deployments.
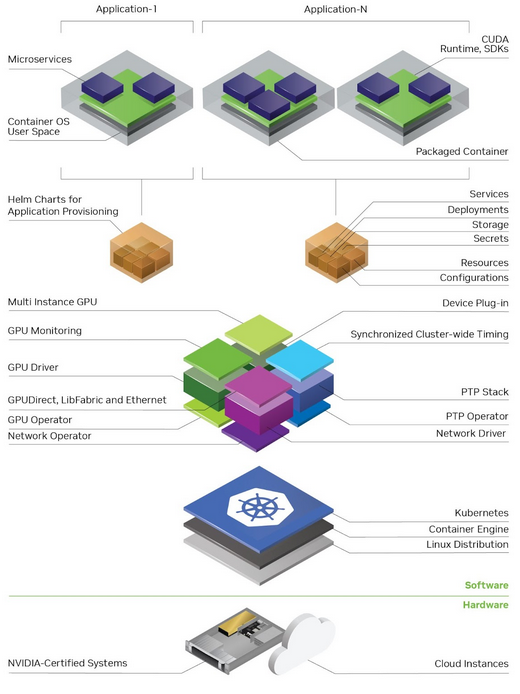
The hardware basis of the platform is therefore NVIDIA-certified systems from our partners, using NVIDIA Ampere architecture or later GPUs and NVIDIA BlueField-2 or later DPUs. The first systems are x86, but the entire software stack is multi-architecture to enable a wide range of systems and use cases with lower power consumption. In production, a minimal Holoscan for Media cluster consists of three nodes, and scales from there.
The software stack begins with Kubernetes, the open-source container orchestration system for automating software deployment, scaling, and management. Partnering with the Red Hat OpenShift Container Platform brings enterprise-grade operation and support.
The inclusion of Kubernetes plug-ins, known as operators, which provide and manage the hardware and underlay services, frees software developers to focus on their unique functionality. The open-source OpenShift Node Tuning Operator, NVIDIA GPU Operator, and NVIDIA Network Operator provide system, GPU, and high-speed secondary networking, tuned for performance and made available to every application that needs them. The GPU Operator can be used to assign one or more entire GPUs to an application.
Support for MIG (Multi-Instance GPU) and vGPU (virtual GPU) enables GPUs to be securely shared between applications. The PTP Operator uses the PTP Hardware Clock on NVIDIA DPUs to provide precise timing from the secondary network to each application through a simple “get time” API. Other operators and plug-ins take care of IP address management (IPAM), DNS zone management, and more.
Holoscan for Media also includes services such as an NMOS Registry and an easy-to-use graph-builder-based NMOS Controller user interface. These can be installed to support development and deployment of applications that act as media nodes and simplify integration with broadcast facility networks.
Applications on the platform are packaged with Helm for simple, consistent deployment. A developer can indicate each container’s required capabilities and resources, including GPU, CPU, memory, and storage. This enables the platform to schedule and monitor applications to ensure each one is appropriately isolated, their requirements are met, and that best use is made of the available hardware.
Developers can build applications using the growing list of NVIDIA SDKs supported on the Holoscan for Media platform. Traditional real-time video encoding and decoding with the Video Codec SDK, GPU-accelerated computer vision by CV-CUDA library, and any parallel compute algorithm using the CUDA toolkit. On top of GPU-accelerated inference through TensorRT SDK or NVIDIA Triton Inference Server, new AI capabilities are offered by SDK and Cloud APIs like Maxine or NVIDIA Avatar Cloud Engine (ACE). Foundational SMPTE 2110 support and optimization of large media transfer is provided through NVIDIA Rivermax SDK. Developers can natively leverage Rivermax on the platform or through the DeepStream SDK, a complete streaming analytics toolkit based on GStreamer for AI-based media processing. Additionally, if developers have wider use cases beyond media, and want to consume and control other sensor types, NVIDIA provides the Holoscan SDK for creating real-time, AI-enabled sensor processing pipelines that meet latency requirements and scale from the data center to the edge.
Full source for a containerized reference application is available to Holoscan for Media developers. This uses NVIDIA DeepStream and can be configured as an NMOS-capable ST 2110 transmitter, receiver or transcoder gateway.
Altogether, this open platform architecture provides the building blocks for the Dynamic Media Facility, using the latest scalable IT and provisioning technologies and open standards to benefit both broadcasters and software vendors.
Get started with Holoscan for Media
Holoscan for Media is now available for early access. Note that you must be registered in the NVIDIA Developer Program to apply for the early access release. You must also be logged in using your organization’s email address. We cannot accept applications from accounts using Gmail, Yahoo, QQ, or other personal email accounts.
To participate, fill out the short application form and provide details about your use case.
 Streamline and accelerate deployment by integrating ETL and ML training into a single Apache Spark script on Amazon EMR.
Streamline and accelerate deployment by integrating ETL and ML training into a single Apache Spark script on Amazon EMR.
Streamline and accelerate deployment by integrating ETL and ML training into a single Apache Spark script on Amazon EMR.
GFN Thursday is downright demonic, as Devil May Cry 5 comes to GeForce NOW. Capcom’s action-packed third-person brawler leads 15 titles joining the GeForce NOW library this week, including Gears Tactics and The Crew Motorfest. It’s also the last week to take on the Ultimate KovaaK’s Challenge. Get on the leaderboard today for a chance Read article >
Categories
New Course: Generative AI Explained
 Explore generative AI concepts and applications, along with challenges and opportunities in this self-paced course.
Explore generative AI concepts and applications, along with challenges and opportunities in this self-paced course.
Explore generative AI concepts and applications, along with challenges and opportunities in this self-paced course.
Generative AI-based models can not only learn and understand natural languages — they can learn the very language of nature itself, presenting new possibilities for scientific research. Anima Anandkumar, Bren Professor at Caltech and senior director of AI research at NVIDIA, was recently invited to speak at the President’s Council of Advisors on Science and Read article >
 Organizations are integrating machine learning (ML) throughout their systems and products at an unprecedented rate. They are looking for solutions to help deal…
Organizations are integrating machine learning (ML) throughout their systems and products at an unprecedented rate. They are looking for solutions to help deal…
Organizations are integrating machine learning (ML) throughout their systems and products at an unprecedented rate. They are looking for solutions to help deal with the complexities of deploying models at production scale.
NVIDIA Triton Management Service (TMS), exclusively available with NVIDIA AI Enterprise, is a new product that helps do just that. Specifically, it helps manage and orchestrate a fleet of NVIDIA Triton Inference Servers in a Kubernetes cluster. TMS enables users to scale their NVIDIA Triton deployments to handle large and varied workloads efficiently. It also improves the developer experience of coordinating the resources and tools required.
This post explores some of the most common challenges developers and MLOps teams face when deploying models at scale, and how NVIDIA Triton Management Service addresses them.
Challenges in scaling AI model deployment
Model deployments of any scale come with their own sets of challenges. Developers need to consider how to balance a variety of frameworks, model types, and hardware while maximizing performance and interfacing with the other components of the environment.
NVIDIA Triton is a powerful solution built to handle these issues and extract the best throughput and performance from the machine it’s deployed on. But as organizations incorporate AI into more of their core workflows, the number and size of inference workloads can grow beyond what a single server can handle. The model deployments have to scale. A new scale of deployment brings with it a new set of challenges—challenges related to the cost and complexity of managing distributed inference workloads.
Cost of deployment
As you deploy more models and find more use cases for them, it can quickly become necessary to scale out deployments to make use of a cluster of resources. A simple approach is to keep scaling your cluster linearly as you add more models, keeping all of your models live and ready for inference at all times.
However, this is not an approach with infinite scale potential. Focusing on expanding the capacity of your serving cluster can result in unnecessary expenses when you have the option to improve utilization of currently available hardware. You will also have to deal with the logistical challenges of adding more resources on premises, or bumping up against quota limits in the cloud.
Other approaches to scaling might appear less expensive, but can lead to steep performance trade-offs. For example, you could wait to load the models into memory until the inference requests come in, leading to long waits and an extended time-to-first-inference. Or you could overcommit your compute resources, leading to performance penalties from context switching during execution and errors from running out of memory on the device.
With careful preplanning and colocation of workloads, you can avoid some of the worst of these issues. Still, that only exacerbates the second major issue of large-scale deployments.
Operational complexity
At a small scale and early in the development of a process that requires model orchestration, it can be viable to manually configure and deploy your models. But as your ML deployments scale, it becomes increasingly challenging to coordinate all of the necessary resources. You need to manage when to launch or scale servers, where to load particular models, how to route requests to the right place, and how to handle the model lifecycle in your environment.
Determining which models can be colocated adds another layer of complexity to these deployments. Large models might exceed the memory capacity of your GPU or CPU if loaded concurrently into the same device. Some frameworks (such as PyTorch and TensorFlow) hold on to any memory allocated to them even after the models are unloaded, leading to inefficient utilization when models from those frameworks are run alongside models from other frameworks.
In general, different models will have different requirements regarding resource allocation and server configuration, making it difficult to standardize on a single type of deployment.
Cost-efficient deployment and scaling of AI models
Triton Management Service addresses these challenges with three main strategies: simplifying Triton Inference Server deployment, maximizing resource usage, and monitoring/scaling Triton inference servers.
Simplifying deployment
TMS automates the deployment and management of Triton server instances on Kubernetes using a simplified gRPC API and command-line tool. With these interfaces, you don’t need to write out extensive code or config files for creating deployments, services, and Kubernetes resources. Instead, you can use the API or CLI to easily launch Triton servers and automatically load models onto these servers as needed.
TMS also employs a method of grouping to optimize GPU or CPU memory utilization. This prevents issues that arise when different frameworks like PyTorch and TensorFlow models run on the same server and fail to release unused GPU or CPU? memory to each other.
Maximizing resources
TMS loads models on-demand and unloads them using a lease system when they are not in use, making sure that models are not kept active in the cluster unnecessarily. To bring up a model, you can submit an API request with a specified timeline or a checking mechanism. The system will keep the model available if it’s being used; otherwise, it will be taken down.
TMS also automatically colocates models on the same device when sufficient capacity is available. To enable this, you need to prespecify the expected GPU memory use of your models during deployment. While there is no automated way to measure this yet, you can rely on Triton Model Analyzer and other benchmarking tools to determine memory requirements beforehand. Together, these features enable you to run more workloads on your existing clusters, saving on costs, and reducing the need to acquire more computational resources.
Monitoring and autoscaling
TMS keeps track of the health and capacity of various Triton servers for high availability reasons. Autoscaling is integrated into the system, enabling TMS to deploy Kubernetes Horizontal Pod Autoscalers automatically based on the model deployment configuration. You can specify metrics for autoscaling, indicating the conditions under which scaling should occur. Load balancing is also applied when autoscaling is implemented across multiple Triton instances.
How Triton Management Service works
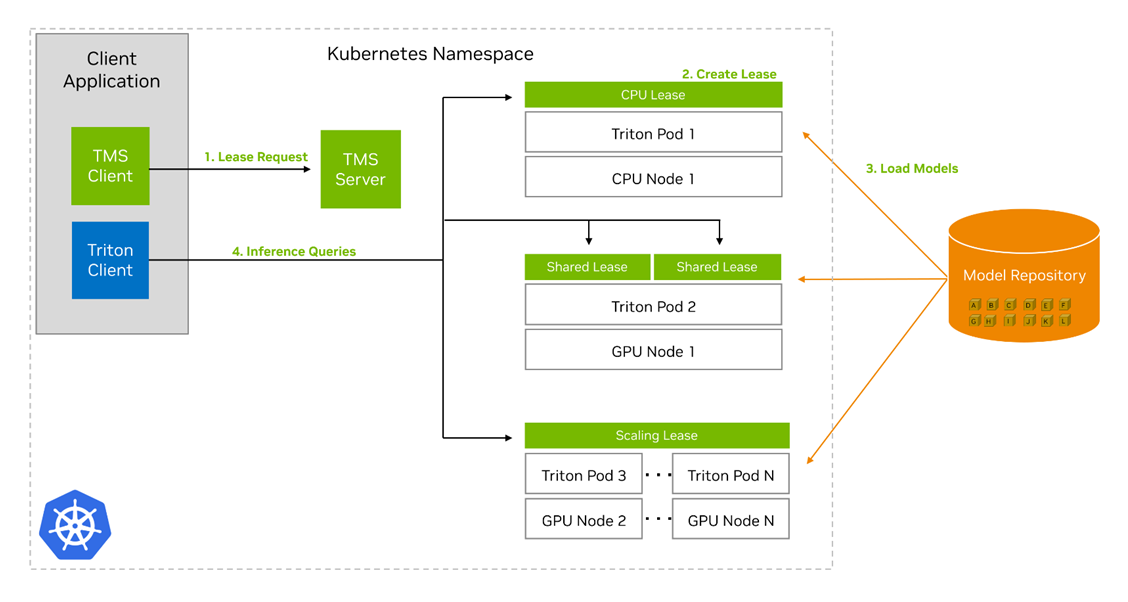
To install TMS, deploy a Helm chart with configurable values into a Kubernetes cluster. This Helm chart delpoys the TMS Server control plane into the cluster, along with a config map that holds many of the configuration settings for TMS. You can operate TMS through gRPC API calls to the TMS Server, or by using the provided tmsctl command-line tool.
The key concept in TMS is the lease. At its core, a lease is a grouping of models and some associated metadata that tells TMS how to treat those models, and what constraints exist for their deployment. Users can create, renew, and release leases. Creating a lease requires specifying a set of models from predefined repositories by a unique identifier, along with metadata including:
- Compute resources required by the lease
- Image/version of Triton to use for this lease
- Minimum duration of the lease
- Window size for detecting activity on the models in the lease
- Metrics and thresholds for scaling the lease
- Constraints on what models or leases with with the new lease can be collected
- A unique name for the lease that can be used to addressed it
When the TMS Server receives the lease request, it performs the actions listed below to create the lease:
- Check the model repositories to see if the models are present and accessible.
- If models are present and accessible, check for existing Triton Inference Servers present in the cluster that meet the constraints of the new lease.
- If none exist, create a new Kubernetes pod containing the Triton Inference Server container and a Triton Sidecar Container.
- Otherwise, choose one of the existing Triton pods to add the lease to.
- In either case, the Triton Sidecar in the Triton Pod will pull the models in your lease from the repository and load them into its paired Triton server.
TMS will also create several other Kubernetes resources to help with management and routing for the lease:
- A deployment that will revive Triton pods if they crash.
- A Kubernetes service based on the lease name that can be used to address the models in the lease.
- A horizontal pod autoscaler to automatically create replicas of the Triton pods based on the metrics and thresholds defined in the lease.
Once the lease has been created, you can use the Triton Inference Server API or an existing Triton client to send inference requests to the server for execution. The Triton client does not need any modifications to work with Triton Inference Servers deployed by Triton Management Service.
Get started with NVIDIA Triton Management Service
To get started with NVIDIA Triton Management Service and learn more about its features and functionality, check out the AI Model Orchestration with Triton Management Service lab on LaunchPad. This lab provides free access to a GPU-enabled Kubernetes cluster and a step-by-step guide on installing Triton Management Service and using it to deploy a variety of AI workloads.
If you have existing compatible on-premises systems or cloud instances, request a 90-day NVIDIA AI Enterprise Evaluation License to try Triton Management Service. If you are an existing NVIDIA AI Enterprise user, simply log in to the NGC Enterprise Catalog.
 Crossing the chasm and reaching its iPhone moment, generative AI must scale to fulfill exponentially increasing demands. Reliability and uptime are critical for…
Crossing the chasm and reaching its iPhone moment, generative AI must scale to fulfill exponentially increasing demands. Reliability and uptime are critical for…
Crossing the chasm and reaching its iPhone moment, generative AI must scale to fulfill exponentially increasing demands. Reliability and uptime are critical for building generative AI at the enterprise level, especially when AI is core to conducting business operations. NVIDIA is investing its expertise into building a solution for those enterprises ready to take the leap.
Introducing NVIDIA AI Enterprise 4.0
The latest version of NVIDIA AI Enterprise accelerates development through multiple facets with production-ready support, manageability, security, and reliability for enterprises innovating with generative AI.
Quickly train, customize, and deploy LLMs at scale with NVIDIA NeMo
Generative AI models have billions of parameters and require an efficient data training pipeline. The complexity of training models, customization for domain-specific tasks, and deployment of models at scale require expertise and compute resources.
NVIDIA AI Enterprise 4.0 now includes NVIDIA NeMo, an end-to-end, cloud-native framework for data curation at scale, accelerated training and customization of large language models (LLMs), and optimized inference on user-preferred platforms. From cloud to desktop workstations, NVIDIA NeMo provides easy-to-use recipes and optimized performance with accelerated infrastructure, greatly reducing time to solution and increasing ROI.
Build generative AI applications faster with AI workflows
NVIDIA AI Enterprise 4.0 introduces two new AI workflows for building generative AI applications: AI chatbot with retrieval augmented generation and spear phishing detection.
The generative AI knowledge base chatbot workflow, leveraging Retrieval Augmented Generation, accelerates the development and deployment of generative AI chatbots tuned on your data. These chatbots accurately answer domain-specific questions, retrieving information from a company’s knowledge base and generating real-time responses in natural language. It uses pretrained LLMs, NeMo, NVIDIA Triton Inference Server, along with third-party tools including Langchain and vector database, for training and deploying the knowledge base question-answering system.
The spear phishing detection AI workflow uses NVIDIA Morpheus and generative AI with NVIDIA NeMo to train a model that can detect up to 90% of spear phishing e-mails before they hit your inbox.
Defending against spear-phishing e-mails is a challenge. Spear phishing e-mails are indistinguishable from benign e-mails, with the only difference between the scam and legitimate e-mail being the intent of the sender. This is why traditional mechanisms for detecting spear phishing fall short.
Develop AI anywhere
Enterprise adoption of AI can require additional skilled AI developers and data scientists. Organizations will need a flexible high-performance infrastructure consisting of optimized hardware and software to maximize productivity and accelerate AI development. Together with NVIDIA RTX 6000 Ada Generation GPUs for workstations, NVIDIA AI Enterprise 4.0 provides AI developers a single platform for developing AI applications and deploying them in production.
Beyond the desktop, NVIDIA offers a complete infrastructure portfolio for AI workloads including NVIDIA H100, L40S, L4 GPUs, and accelerated networking with NVIDIA BlueField data processing units. With HPE Machine Learning Data Management, HPE Machine Learning Development Environment, Ubuntu KVM and Nutanix AHV virtualization support, organizations can use on-prem infrastructure to power AI workloads.
Manage AI workloads and infrastructure
NVIDIA Triton Management Service, an exclusive addition to NVIDIA AI Enterprise 4.0, automates the deployment of multiple Triton Inference Servers in Kubernetes with GPU resource-efficient model orchestration. It simplifies deployment by loading models from multiple sources and allocating compute resources. Triton Management Service is available for lab experience on NVIDIA LaunchPad.
NVIDIA AI Enterprise 4.0 also includes cluster management software, NVIDIA Base Command Manager Essentials, for streamlining cluster provisioning, workload management, infrastructure monitoring, and usage reporting. It facilitates the deployment of AI workload management with dynamic scaling and policy-based resource allocation, providing cluster integrity.
New AI software, tools, and pretrained foundation models
NVIDIA AI Enterprise 4.0 brings more frameworks and tools to advance AI development. NVIDIA Modulus is a framework for building, training, and fine-tuning physics-machine learning models with a simple Python interface.
Using Modulus, users can bolster engineering simulations with AI and build models for enterprise-scale digital twin applications across multiple physics domains, from CFD and Structural to Electromagnetics. The Deep Graph Library container is designed to implement and train Graph Neural Networks that can help scientists research the graph structure of molecules or financial services to detect fraud.
Lastly, three exclusive pretrained foundation models, part of NVIDIA TAO, speed time to production for industry applications such as vision AI, defect detection, and retail loss prevention.
NVIDIA AI Enterprise 4.0 is the most comprehensive upgrade to the platform to date. With enterprise-grade security, stability, manageability, and support, enterprises can expect reliable AI uptime and uninterrupted AI excellence.
Get started with NVIDIA AI Enterprise
Three ways to get accelerated with NVIDIA AI Enterprise:
- Sign up for NVIDIA LaunchPad for short-term access to sets of hands-on labs.
- Sign up for a free 90-day evaluation for existing on-prem or cloud infrastructure.
Purchase through NVIDIA Partner Network or major Cloud Service Providers including AWS, Microsoft Azure, and Google Cloud.