
 NVIDIA AI Enterprise is a suite of AI software, certified to run on VMware vSphere 7 Update 2 with NVIDIA-Certified volume servers. It includes key enabling technologies and software from NVIDIA for rapid deployment, management and scaling of AI workloads in the virtualized data center running on VMware vSphere.
NVIDIA AI Enterprise is a suite of AI software, certified to run on VMware vSphere 7 Update 2 with NVIDIA-Certified volume servers. It includes key enabling technologies and software from NVIDIA for rapid deployment, management and scaling of AI workloads in the virtualized data center running on VMware vSphere.
NVIDIA AI Enterprise is a suite of AI software, certified to run on VMware vSphere 7 Update 2 with NVIDIA-Certified volume servers. It includes key enabling technologies and software from NVIDIA for rapid deployment, management and scaling of AI workloads in the virtualized data center running on VMware vSphere. The NVIDIA AI Enterprise suite also enables IT Administrators, Data Scientists, and AI Researchers to quickly run NVIDIA AI applications and libraries optimized for GPU acceleration by reducing deployment time and ensuring reliable performance.
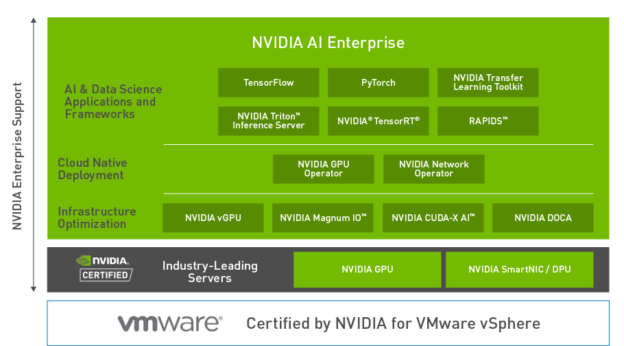
NVIDIA AI Enterprise suite is licensed and supported by NVIDIA. After the joint announcement at VMworld in September 2020, NVIDIA and VMware have continued work to improve the integration between their joint offerings. NVIDIA and VMware are committed to continued collaboration to tightly couple VMware vSphere with the NVIDIA AI Enterprise suite. This article discusses the new features introduced with VMware vSphere 7 Update 2 release and the new NVIDIA AI Enterprise software suite.
The introduction of NVIDIA RDMA capabilities into vSphere for NVIDIA virtualized GPU (vGPU) allows deep learning training to scale out to multiple nodes with near bare metal performance for even the largest deep learning training workloads.
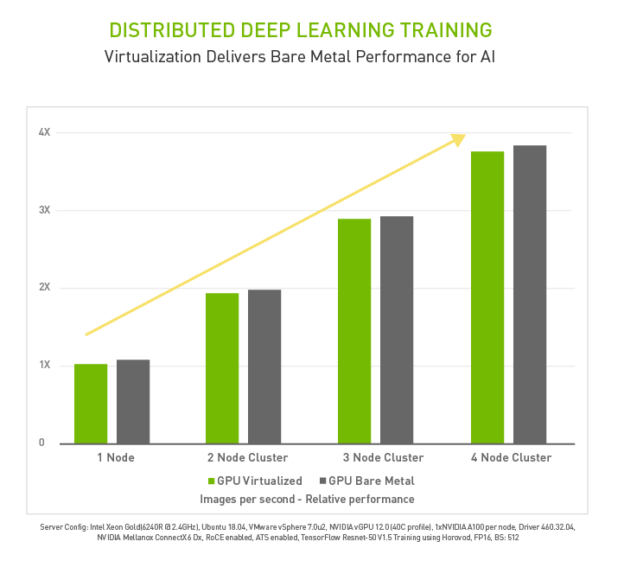
RDMA technology is featured in NVIDIA ConnectX SmartNICs and BlueField DPUs and improves the bandwidth and latency when moving data directly between a network interface card (NIC) and GPU memory.
IT administrators can use the tools they are familiar with, like VMware vCenter, to provision multiple nodes as VMs. These VMs can be configured to use NVIDIA networking and vGPU resources for RDMA.
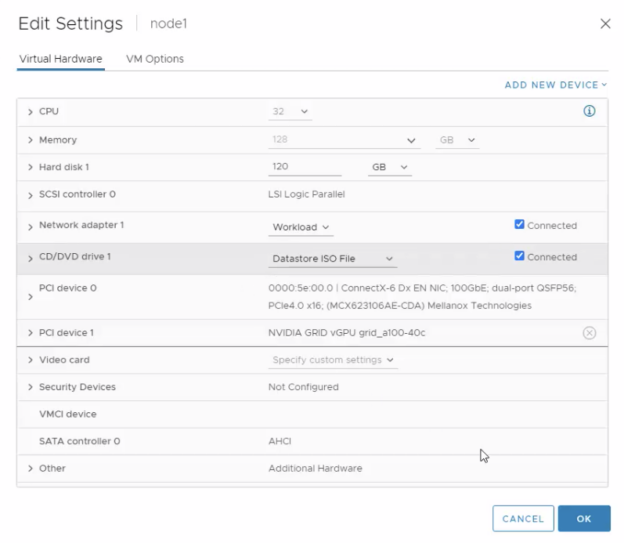
VMware’s integration with RDMA over Converged Ethernet (RoCE) results in AI and ML capabilities that are accelerated faster than ever before. vSphere 7 Update 2 with NVIDIA AI Enterprise software supports RDMA with ATS capabilities on Intel CPUs further optimizing the GPUDirect bandwidth between NIC and GPU so that throughput is not limited by PCIe bus speeds. This means that a data scientist can iterate on new data and re-train many more times in a day, dramatically increasing their productivity.
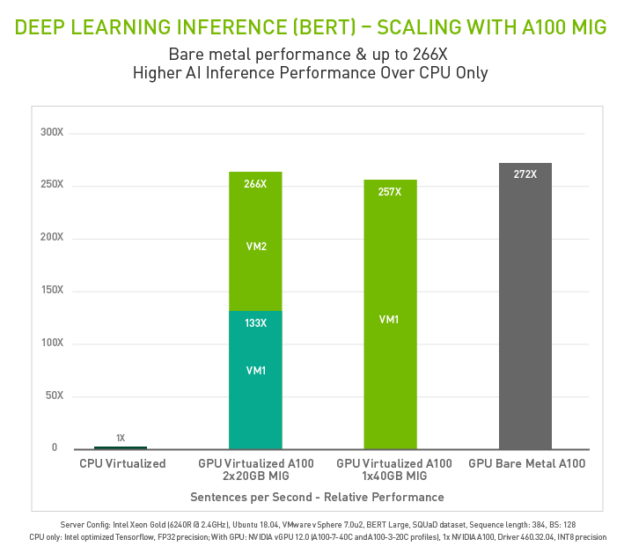
Now let’s look at the new VMware features which have further enabled Deep Learning inferencing workloads. vSphere 7 Update 2 supports the latest GPU Ampere architecture such as the NVIDIA A100 GPU. This GPU can be configured to use Multi-Instance GPU (MIG). This type of GPU partitioning can be particularly beneficial for inferencing workloads that do not fully saturate the GPUs compute capacity and for uses cases which require low latency response and error isolation. The graph below illustrates the performance of natural language inference using virtualized GPUs enabled with MIG compared to virtualized CPU as well as bare metal.
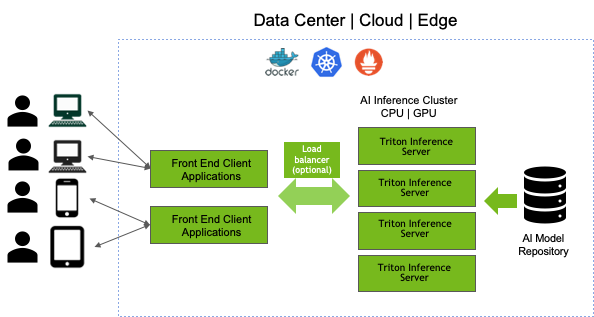
Let’s look at a use case example of how a single NVIDIA A100 configured with MIG mode enabled can be used for multiple inferencing workloads with VMware vSphere. NVIDIA Triton Inference Server is an AI application framework included in the NVIDIA AI Enterprise suite. Available as a Docker container, it integrates with Kubernetes for orchestration and auto-scaling. This solution allows front end client applications to submit inferencing requests from the AI inference cluster and can service models within the AI model repository.
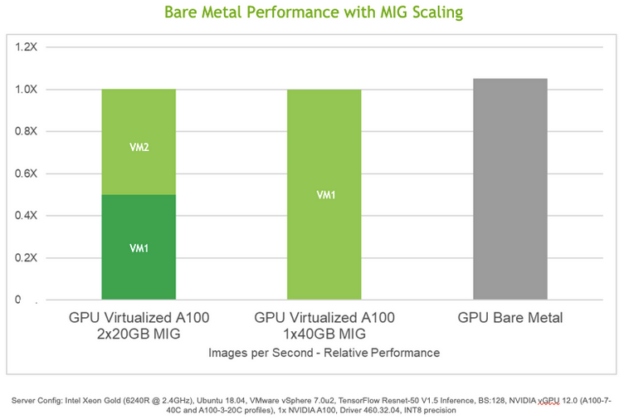
Let’s look further at this use case, for example multiple end users or departments submit inference request to perform object detection on satellite imagery. Within the AI model repository, there are pre-trained object detection models which detect the presence of multiple objects in the satellite imagery, such as buildings, trees, fire hydrants or well pads. A single NVIDIA A100 GPU can be used for servicing the multiple inferencing requests by leveraging MIG spatial partitioning, thereby optimizing the utilization of a valuable and powerful GPU resource within the enterprise. The graph below illustrates the performance of ResNet-50 object detection inference using virtualized GPUs with MIG enabled compared to virtualized CPU only as well as bare metal.
Using Triton Inference Server, with added MIG support in vSphere 7.0 U2, the NVIDIA A100 – 40GB GPU can be partitioned up to 7 GPU slices, each slice or instance has its own dedicated compute resources that run in parallel with predictable throughput and latency. IT administrators use vCenter to assign a VM a single MIG partition. Read VMware’s technical blog post for additional details, “Multiple Machine Learning Workloads Using GPUs: New Features in vSphere 7 Update 2“.
As enterprises move toward AI and cloud computing, a new data center architecture is needed to enable both existing and modern. Accelerated servers can be added to the core enterprise data center and managed with standard tools like VMware vCenter. As a result of NVIDIAs close partnership, VMware has brought in new features to vSphere 7.0 U2 which provides the highest quality of low latency response ML/AI applications backed by vGPU in the enterprise.