
 When you are working on optimizing inference scenarios for the best performance, you may underestimate the effect of data preprocessing. These are the operations required before forwarding an input sample through the model. This post highlights the impact of the data preprocessing on inference performance and how you can easily speed it up on the … Continued
When you are working on optimizing inference scenarios for the best performance, you may underestimate the effect of data preprocessing. These are the operations required before forwarding an input sample through the model. This post highlights the impact of the data preprocessing on inference performance and how you can easily speed it up on the … Continued
When you are working on optimizing inference scenarios for the best performance, you may underestimate the effect of data preprocessing. These are the operations required before forwarding an input sample through the model. This post highlights the impact of the data preprocessing on inference performance and how you can easily speed it up on the GPU, using NVIDIA DALI and NVIDIA Triton Inference Server.
Does preprocessing matter?
Regardless of a particular model that you want to run inference on, some degree of data preprocessing is required. In computer vision applications, the input operations usually include decoding, resizing, and normalizing to a standardized format accepted by the neural network. Speech recognition models, on the other hand, may require calculating certain features, like a spectrogram, and some raw audio sample processing, such as pre-emphasis and dithering.
Often, preprocessing routines that you use for inference are similar to the ones used as an input pipeline for the model training. Implementing both using the same tools can save you some boilerplate and code repetition. Ensuring that the preprocessing operations used for inference are defined identically as they were when the model was trained is key to achieving high accuracy.
The more complicated a preprocessing pipeline is for a given model, the bigger fraction of the entire inference time that it takes. It means that accelerating only the network processing time does not yield proportional improvement in overall inference latency. This is especially true if you use CPU to prepare data before feeding it to the model.
What is NVIDIA DALI?
DALI is a data loading and preprocessing library to build highly optimized custom data processing pipelines used in deep learning applications. The set of operations that can be found in DALI includes, but is not limited to, data loading, decoding multiple formats of image, video, and audio, as well as a wide range of processing operators.
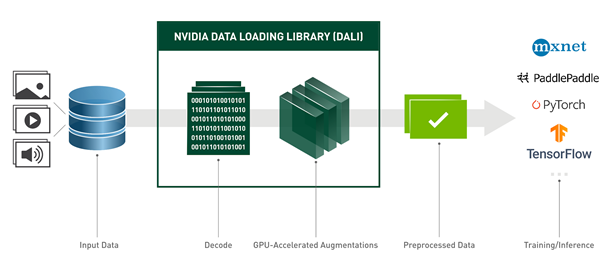
What makes DALI performant is that it offloads most of preprocessing computation to the GPU. It processes the whole batch of data at one time rather than running operators sample by sample, using the parallel nature of GPU computations. Because of that, DALI is successfully used to accelerate the training of many deep learning models in production. For more information, see the following posts:
Another advantage of DALI is its portability. After it’s defined, a pipeline can be used with most of the popular deep learning frameworks, namely TensorFlow, PyTorch, MXNet, and Paddle Paddle. However, the DALI utility is not limited to training. After you have trained your model with DALI as a preprocessing library, you can use the corresponding data processing pipeline for inference.
Triton model ensembles
Triton Inference Server greatly simplifies the deployment of AI models at scale in production. It is an open-source software that provides support for multiple backends that can run your neural network inference. However, running an inference may require more complex pipelines that also include preprocessing and postprocessing stages. All steps are not always all present, but whenever your use case includes more than just calculating the output of a neural network, Triton Server comes with a convenient solution that simplifies building such pipelines.
Among many useful scheduling mechanisms that the Triton Server platform provides is the ensemble scheduler, which is responsible for pipelining models participating in the inference process while ensuring efficiency and optimizing throughput.
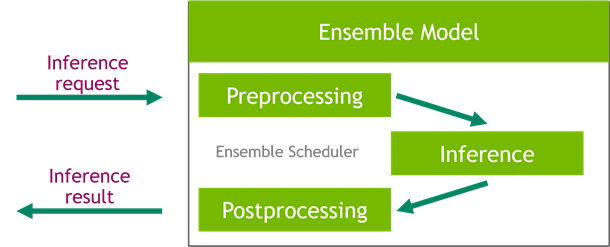
Using ensembles in Triton Server is easy and requires only preparing a single additional configuration file with a description of the pipeline. This file serves as a definition of a special ensemble model that is a facade encapsulating the whole inference process. With such a setup, you can send requests directly to the ensemble model, which hides the complexity of the pipeline. This can also reduce the communication overhead as the preprocessed data already resides on the GPU that is used to run the inference.
Introducing DALI backend
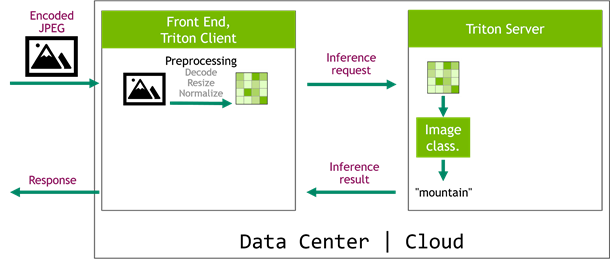
Here’s a real-life example: an image classification system. A picture is captured on the edge device and is sent to a frontend service. The frontend delegates inference to Triton Server that runs an image classification network, for example Inception v3. Typically, such networks require a decoded, normalized, and resized image as an input. Running those operations inside the client service (Figure 3) is time-consuming. On top of that, the decoded images increase network traffic, as they are bigger than the encoded images (Table 1). Still, this solution might be tempting, as it is easy to implement with popular libraries like OpenCV.
| Resolution | Decoded image | Preprocessed image for Inception v3 | Encoded image |
| 720p | 3.1 MB | 1 MB | 500 kB |
| 1080p | 6.2 MB | 1 MB | 700 kB |
On the other hand, a significantly more performant scenario is the one that implements the preprocessing pipeline as a Triton Server backend (Figure 4). In this case, you can take advantage of the GPUs that are already used by the server. The role of the frontend service is now reduced to handling requests from edge devices and sending encoded images directly to Triton Server. This simplifies the architecture of the cloud system as all computationally intensive tasks are moved to the Triton Server, which can be easily scaled later.
The preprocessing part could be implemented as a custom backend but that is quite complicated and low-level. It can also be written in one of the frameworks supported by Triton Server. However, if you’ve already have trained your network using the DALI input pipeline, you would probably like to reuse this code for inference.
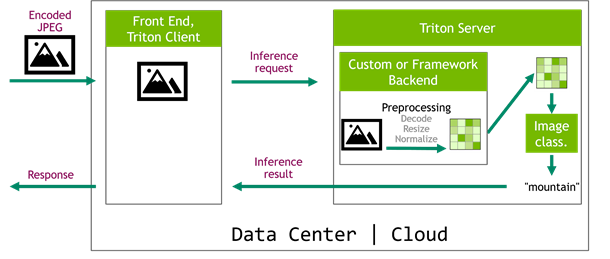
This is where the DALI backend comes in handy. Although DALI was initially designed to remove the preprocessing bottleneck during training, some of the features also come in handy in inference. In the image classification example, you put together a model ensemble, where the first step decodes, resizes, and normalizes the images using DALI GPU operators and sends the input data straight to the inference step (Figure 5).
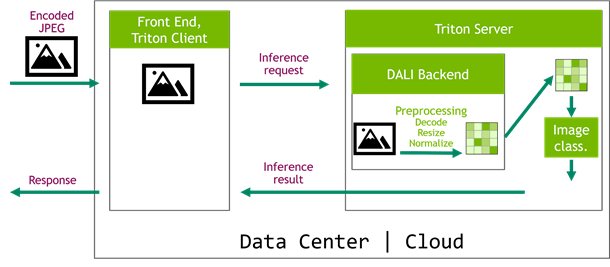
Image classification using Inception v3
How do you obtain a DALI model and put it into the model repository? Look at an example from the DALI backend repository.
Inception v3 is an example of an image classification neural network. All three of the preprocessing operations needed by this model (JPEG decoding, resizing, and normalizing) are good candidates for GPU parallelization. In DALI, they are GPU-powered.
The DALI model is going to be a part of the model ensemble. The following example shows the model repository directory structure, containing a DALI preprocessing model, TensorFlow Inception v3 model, and the model ensemble:
model_repository ├── dali │ ├── 1 │ │ └── model.dali │ └── config.pbtxt ├── ensemble_dali_inception │ ├── 1 │ └── config.pbtxt └── inception_graphdef ├── 1 │ └── model.graphdef └── config.pbtxt
The configuration file config.pbtxt for the preprocessing model is like the other Triton Server models:
name: "dali"
backend: "dali"
max_batch_size: 256
input [
{
name: "DALI_INPUT_0"
data_type: TYPE_UINT8
dims: [ -1 ]
}
]
output [
{
name: "DALI_OUTPUT_0"
data_type: TYPE_FP32
dims: [ 299, 299, 3 ]
}
]
The remaining question is where to get the model.dali file from? This file contains a serialized DALI pipeline that you can get by calling the serialize method on a DALI pipeline instance. The following code example is the DALI preprocessing pipeline for the Inception example:
@dali.pipeline_def(batch_size=256, num_threads=4, device_id=0) def inception_pipeline(): images = fn.external_source(device="cpu", name="DALI_INPUT_0") images = fn.decoders.image(images, device="mixed", output_type=types.RGB) images = fn.resize(images, resize_x=299, resize_y=299) images = fn.crop_mirror_normalize( images, dtype=types.FLOAT, mean=[0.485 * 255, 0.456 * 255, 0.406 * 255], std=[0.229 * 255, 0.224 * 255, 0.225 * 255]) return images pipe = inception_pipeline() pipe.serialize(filename="model_repository/dali/1/model.dali")
The code is rather straightforward. Note the presence of a fn.external_source operator; it’s a placeholder later used by Triton Server to provide data to the pipeline. You must also remember to set the name of fn.external_source the same way that you named the input in the DALI config.pbtxt file. For more information about building DALI pipelines, see NVIDIA DALI Documentation.
Performance results
So how does the performance look? Figure 6 compares two Inception setup scenarios:
- Client preprocessing: Samples are decoded, resized, and normalized in parallel using OpenCV.
- Server preprocessing: The Python client script sends encoded images to the server, where the whole DALI preprocessing happens.
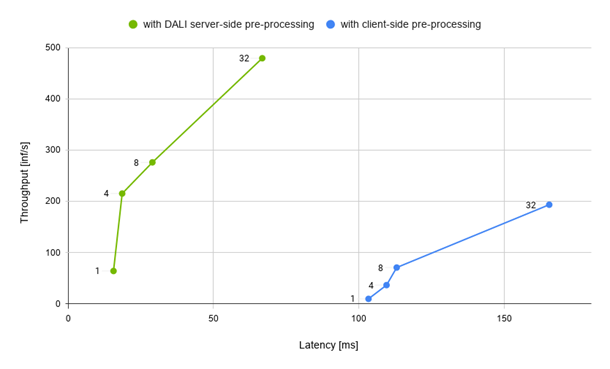
Using DALI gives you significant leverage over client preprocessing. Figure 6 shows that DALI gives significantly better performance results both in terms of overall latency and throughput. This is possible thanks to the fact that DALI takes advantage of full GPU compute capabilities, such as the hardware JPEG decoder. Another important factor is the communication overhead. An example JPEG image used in the inference with the resolution of 1280×720 is about 306 kB whereas the same image after preprocessing yields a tensor that has about 1048 kB. This means that sending preprocessed data might cause about 3x the network traffic.
Naturally, the results differ according to your specific use case and your infrastructure. However, using DALI for preprocessing data in your inference scenario is worth a try.
How to get the DALI backend?
Starting from tritonserver:20.11-py3, DALI Backend is included in the Triton Server Docker container. Just download the latest version and you’re good to go. Moreover DALI, Triton Server, and the DALI backend for Triton Server are all open-source projects so that you can build the most up-to-date versions from source.
We are waiting for your feedback!
If you have any problems or questions, do not hesitate to submit an issue on the triton-inference-server/dali_backend GitHub repository. You can also consult the NVIDIA DALI Documentation and the main NVIDIA/DALI repository.