
 Tensor Cores, which are programmable matrix multiply and accumulate units, were first introduced in the V100 GPUs where they operated on half-precision (16-bit) multiplicands. Tensor Core functionality has been expanded in the following architectures, and in the Ampere A100 GPUs (compute capability 8.0) support for other data types was added, including double precision. Access to … Continued
Tensor Cores, which are programmable matrix multiply and accumulate units, were first introduced in the V100 GPUs where they operated on half-precision (16-bit) multiplicands. Tensor Core functionality has been expanded in the following architectures, and in the Ampere A100 GPUs (compute capability 8.0) support for other data types was added, including double precision. Access to … Continued
Tensor Cores, which are programmable matrix multiply and accumulate units, were first introduced in the V100 GPUs where they operated on half-precision (16-bit) multiplicands. Tensor Core functionality has been expanded in the following architectures, and in the Ampere A100 GPUs (compute capability 8.0) support for other data types was added, including double precision.
Access to programming Tensor Cores in CUDA C became available in the CUDA 9.0 release for Volta GPUs through the WMMA (Warp Matrix Multiply and Accumulate) API, which was extended in CUDA 11.0 to support Ampere GPUs. This post describes a CUDA Fortran interface to this same functionality, focusing on the third-generation Tensor Cores of the Ampere architecture.
With the WMMA interface, a single warp of 32 threads performs D = A∗B +C. This operation is the building block to construct GEMM-like operations. The size of the matrices (C and D are m×n, A is m×k, and B is k×n) in this operation depends on the precision:
- For real(2) multiplicands, m×n×k can be 16×16×16, 32×8×16, or 8×32×16.
- For real(4) data using the TensorFloat32 format, m×n×k is 16×16×8.
- For real(8) data, m×n×k is 8×8×4.
For the case where the multiplicands A and B contain real(2) data, C and D can be either both real(2) or both real(4) matrices. The Volta and Turing architectures support only the cases where the multiplicands are real(2) data. All this is summarized in Table 1. Before the WWMA operation can take place, the operand matrices must be loaded into registers and then distributed amongst the threads in the warp. The mapping of threads to matrix elements is opaque, where the WMMA submatrix datatype (equivalent to the fragment in CUDA C), is used to represent the elements each thread holds of the matrix represented by the warp of threads, along with other metadata.
In this post, I focus on the WMMA interface for double precision or real(8) data.
| Multiplicand Precision | Accumulator Precision | WMMA Tile Sizes (m×n×k) | Architecture |
| real(2) / 16-bit | real(2) / 16-bit real(4) / 32-bit |
16×16×16 32×8×16 8×32×16 |
Volta, Turing, NVIDIA Ampere |
| real(4) / TF32 | real(4) / TF32 | 16×16×8 | NVIDIA Ampere |
| real(8) / 64-bit | real(8) / 64-bit | 8×8×4 | NVIDIA Ampere |
CUDA Fortran wmma module
The use of Tensor Cores through the WMMA API in CUDA Fortran requires the wmma module as well as the cuf_macros.CUF macro file. These provide Tensor Core–specific data types, along with routines to load and store data and perform warp-based matrix multiplications using these data types.
WMMASubMatrix datatype
Tiles of matrices used by a warp of threads to perform matrix multiplication are stored in variables of the WMMASubMatrix datatype in device code. For those familiar with the CUDA C API to Tensor Cores, WMMASubMatrix corresponds to the fragment template. There are different WMMASubMatrix types based on use (i.e., which operand in D = A ∗ B + C), precision, storage order, and dimensions, which are specified as type parameters in CUDA Fortran. Typical declarations of WMMASubMatrix variables used in device code are:
WMMASubMatrix(WMMAMatrixA, 8, 8, 4, Real, WMMAColMajorKind8) :: sa WMMASubMatrix(WMMAMatrixB, 8, 8, 4, Real, WMMAColMajorKind8) :: sb WMMASubMatrix(WMMAMatrixC, 8, 8, 4, Real, WMMAKind8) :: sc
The first parameter indicates the operand, corresponding to the A matrix, B matrix, and the accumulator. The following three parameters are the tile sizes, in this case m×n×k = 8×8×4. The datatype Real is specified next and is currently the only allowed value. The last parameter in WMMAMatrixA and WMMAMatrixB matrix declaration specifies row- or column-ordering (WMMAColMajor) as well as the precision (Kind8). The storage order for the accumulators is not specified at declaration, therefore the last parameter in the WMMAMatrixC declaration specifies only the precision.
Compilation
When compiling code using Tensor Cores for the A100 GPU, a compute capability of 8.0 and a CUDA runtime version of at least 11.0 should be used (-cuda -gpu=cc80,cuda11.0).
In addition, the preprocessor must be invoked due to the included macro file cuf_macros.CUF, either explicitly through the -Mpreprocess compiler option or implicitly by using an uppercase file extension such as .CUF or .F90. The cuf_macros.CUF file is included in the HPC SDK in the examples/CUDA-Fortran/TensorCores/Utils directory.
WMMA programming basics
This section presents a sequence of small example programs showing the concepts of WMMA programming in CUDA Fortran. The sequence begins with launching a kernel using a single warp of threads that performs a matrix multiplication of an 8×4 by and 4×8 matrix. Then, each following example adds complexity until performance issues can be addressed, in the Performance of WMMA code section.
Example 1: 8×8×4 matrix multiply
The simplest possible matrix multiply using WMMA is the operation C = A ∗ B where the matrix sizes correspond to the WMMA tile sizes, where A, B, and C are 8×4, 4×8, and 8×8, respectively. The kernel code for this is as follows:
#include "cuf_macros.CUF" module m integer, parameter :: wmma_m = 8 integer, parameter :: wmma_n = 8 integer, parameter :: wmma_k = 4 contains ! kernel for C = A B (C(8x8), A(8x4), B(4x8)) using wmma ! Should be launched with one block of 32 threads attributes(global) subroutine wmma_single(a, b, c) use wmma implicit none real(8) :: a(wmma_m,*), b(wmma_k,*), c(wmma_m,*) WMMASubMatrix(WMMAMatrixA, 8, 8, 4, Real, WMMAColMajorKind8) :: sa WMMASubMatrix(WMMAMatrixB, 8, 8, 4, Real, WMMAColMajorKind8) :: sb WMMASubMatrix(WMMAMatrixC, 8, 8, 4, Real, WMMAKind8) :: sc integer :: lda, ldb, ldc lda = wmma_m ldb = wmma_k ldc = wmma_m sc = 0.0_8 call wmmaLoadMatrix(sa, a(1,1), lda) call wmmaLoadMatrix(sb, b(1,1), ldb) call wmmaMatMul(sc, sa, sb, sc) call wmmaStoreMatrix(c(1,1), sc, ldc) end subroutine wmma_single end module m
This is launched in host code with a single thread block containing a single warp of threads:
call wmma_single>>(a_d, b_d, c_d)
The device arrays a_d, b_d, and c_d are declared in host code with dimensions corresponding to the WMMA submatrices:
integer, parameter :: m = wmma_m, n = wmma_n, k = wmma_k
real(8), device :: a_d(m,k), b_d(k,n), c_d(m,n)
Because the matrices passed in as arguments to the kernel are the same sizes as the WMMA submatrices, the matrix multiplication is accomplished by initializing the C WMMA submatrix to 0.0, loading the A and B matrices from global memory to WMMA submatrices, performing the matrix multiplication on the submatrices, and storing the result in the WMMA submatrix to global memory:
sc = 0.0_8
call wmmaLoadMatrix(sa, a(1,1), lda)
call wmmaLoadMatrix(sb, b(1,1), ldb)
call wmmaMatMul(sc, sa, sb, sc)
call wmmaStoreMatrix(c(1,1), sc, ldc)
You may have noticed that the thread index threadIdx does not appear at all in this code. This underlies the important concept to take away from this example: the threads in a warp work collectively to accomplish these tasks. So, when dealing with the WMMA submatrices, you are doing warp-level programming rather than thread-level programming.
This kernel is launched with a single warp of 32 threads, yet your WMMA C submatrix has 8×8 or 64 elements. When the sc = 0.0_8 initialization statement is executed, each thread sets two elements in the 8×8 submatrix to zero. For those familiar with the CUDA C Tensor Core API, assignment to WMMA submatrices is overloaded to invoke the fill_fragment method. The mapping of threads to submatrix elements is opaque for this and other operations involving WMMA submatrices. From a programming standpoint, you only address what happens collectively by a warp of threads on WMMA submatrices.
The following statements load A and B from global memory to WMMA submatrices:
call wmmaLoadMatrix(sa, a(1,1), lda)
call wmmaLoadMatrix(sb, b(1,1), ldb)
They also work collectively. In these calls, the WMMA submatrices are specified as the first argument. The second arguments contain the addresses of the upper-left element of the tiles in global or shared memory to be loaded to the WMMA submatrices. The leading dimension of the matrices in global or shared memory is the third argument. The arguments passed to wmmaLoadMatrix are the same for all threads in the warp. Because the mapping of elements to threads in a warp is opaque, each thread just passes the address of the first element in the 8×4 or 4×8 matrix along with the leading dimension as the third parameter, and the load operation is distributed amongst the threads in the warp.
The matrix multiplication on the WMMA submatrices is performed by the following statement:
call wmmaMatMul(sc, sa, sb, sc)
This statement is again performed collectively by a warp of threads. Here, you have used the same accumulator submatrix for the first and last arguments in the wmmaMatMul call, which is why its initialization to zero was required.
The following wmmaStoreMatrix call is analogous to the prior wmmaLoadMatrix calls:
call wmmaStoreMatrix(c(1,1), sc, ldc)
Here, however, the first argument is the address of the upper left element of the tile in global memory, and the second argument is the WMMA submatrix whose values are stored. When both wmmaLoadMatrix and wmmaStoreMatrix are called with accumulator (WMMAMatrixC) arguments, there is an optional fourth argument that specifies the storage order—recall that declarations for WMMA accumulators do not specify storage order. In CUDA Fortran, the default order is WMMAColMajor or column-major storage order.
One final note on arguments to the wmmaLoadMatrix and wmmaStoreMatrix routines. There is a requirement that the leading dimension of the matrices, specified by the third argument of these routines, must be a multiple of 16 bytes, such as two real(8) elements, four real(4) elements, or eight real(2) elements. This becomes important when you use shared memory for the input arrays or more specifically, when you pad shared memory arrays.
Example 2: 8×8×16 matrix multiply
The second example performs the matrix multiplication C = A ∗ B where A is 8×16 and B is 16×8. A common theme in all these examples of this section is that a warp of threads calculates an 8×8 tile of the resultant matrix. As such, this kernel is still launched with a single warp of threads. The kernel for this code is as follows:
#include "cuf_macros.CUF"
module m
integer, parameter :: wmma_m = 8
integer, parameter :: wmma_n = 8
integer, parameter :: wmma_k = 4
contains
! kernel for wmma on a single blockwise row in A
! C(8x8) = A(8xK) B(Kx8)
! with K a multiple of 4
! Launched with a single block of 32 threads
attributes(global) subroutine wmma_row(a, b, c, k)
use wmma
implicit none
real(8) :: a(wmma_m,*), b(k,*), c(wmma_m,*)
integer, value :: k
integer :: i
WMMASubMatrix(WMMAMatrixA, 8, 8, 4, Real, WMMAColMajorKind8) :: sa
WMMASubMatrix(WMMAMatrixB, 8, 8, 4, Real, WMMAColMajorKind8) :: sb
WMMASubMatrix(WMMAMatrixC, 8, 8, 4, Real, WMMAKind8) :: sc
integer :: lda, ldb, ldc
lda = wmma_m
ldb = k
ldc = wmma_m
sc = 0.0_8
do i = 1, k, wmma_k
call wmmaLoadMatrix(sa, a(1,i), lda)
call wmmaLoadMatrix(sb, b(i,1), ldb)
call wmmaMatMul(sc, sa, sb, sc)
enddo
call wmmaStoreMatrix(c(1,1), sc, ldc)
end subroutine wmma_row
end module m
The only difference between this kernel and the kernel from the previous example is that the loading of A and B submatrices and the matrix multiplication on these submatrices occur inside a loop, where for each iteration a matrix multiplication of 8×4 by 4×8 tiles is performed. The second argument to wmmaLoadMatrix is again the same for all threads in the warp, it is the address of the first element of the 8×4 or 4×8 tile used in that iteration. The results are accumulated in the submatrix sc because the first and last arguments in wmmaMatMul are the same.
Example 3: 16×16×16 matrix multiply
For this example, you move past launching a kernel with a single warp of threads. The kernel still uses a single warp to calculate each 8×8 tile of the resultant matrix, but for a 16×16 resultant matrix, the host code now launches the kernel with four warps of threads, for now with one warp per thread block. The associated parameters in host code are as follows:
! m=n=k=16
integer, parameter :: m_blocks = 2, n_blocks = 2, k_blocks= 4
integer, parameter :: m = m_blocks*wmma_m, &
n = n_blocks*wmma_n, &
k = k_blocks*wmma_k
The host code launches the kernel with the following:
grid = dim3(m_blocks,n_blocks,1) call wmma_8x8>>(a_d, b_d, c_d, m, n, k)
The kernel itself is as follows:
#include "cuf_macros.CUF"
module m
integer, parameter :: wmma_m = 8
integer, parameter :: wmma_n = 8
integer, parameter :: wmma_k = 4
contains
! kernel where each block performs matmul for a 8x8 submatrix of C
attributes(global) subroutine wmma_8x8(a, b, c, m, n, k)
use wmma
implicit none
real(8) :: a(m,*), b(k,*), c(m,*)
integer, value :: m, n, k
integer :: i, row_t, col_t
WMMASubMatrix(WMMAMatrixA, 8, 8, 4, Real, WMMAColMajorKind8) :: sa
WMMASubMatrix(WMMAMatrixB, 8, 8, 4, Real, WMMAColMajorKind8) :: sb
WMMASubMatrix(WMMAMatrixC, 8, 8, 4, Real, WMMAKind8) :: sc
integer :: lda, ldb, ldc
lda = m
ldb = k
ldc = m
row_t = (blockIdx%x - 1)*wmma_m + 1
col_t = (blockIdx%y - 1)*wmma_n + 1
sc = 0.0_8
do i = 1, k, wmma_k
call wmmaLoadMatrix(sa, a(row_t,i), lda)
call wmmaLoadMatrix(sb, b(i,col_t), ldb)
call wmmaMatMul(sc, sa, sb, sc)
enddo
call wmmaStoreMatrix(c(row_t,col_t), sc, ldc)
end subroutine wmma_8x8
end module m
Each thread block (consisting of a single warp of threads) calculates the results in the tile c(row_t:row_t+7, col_t:col_t+7). With one warp of threads per thread block, the row_t and col_t indices can be calculated from the blockIdx values:
row_t = (blockIdx%x - 1)*wmma_m + 1
col_t = (blockIdx%y - 1)*wmma_n + 1
While this kernel code is general and can be used for large matrices, with only 32 threads
per block it is inefficient. In the next example, I address this inefficiency.
Example 4: 16×16×16 single-block matrix multiply
In this example, the kernel performs the same matrix multiplication as in example 3, but uses a single block of four warps of threads rather than four blocks of one warp each. The kernel is launched with the following code:
tpb = dim3(tile_m/wmma_m*32, tile_n/wmma_n, 1)
grid = dim3((m-1)/tile_m+1, (n-1)/tile_n+1, 1)
call wmma_tile>>(a_d, b_d, c_d, m, n, k)
The module containing the kernel is as follows:
module m
integer, parameter :: wmma_m = 8
integer, parameter :: wmma_n = 8
integer, parameter :: wmma_k = 4
! tile_m and tile_n are the size of submatrix of C that
! gets calculated per thread block and should be
! integral multiples of wmma_m and wmma_n, respectively
integer, parameter :: tile_m = 16, tile_n = 16
contains
! launch with blocksize of
! dim3(tile_m/wmma_m*32, tile_n/wmma_n, 1)
! [= dim3(64, 2, 1) in this case]
attributes(global) subroutine wmma_tile(a, b, c, m, n, k)
use wmma
use cudadevice
implicit none
real(8) :: a(m,*), b(k,*), c(m,*)
integer, value :: m, n, k
WMMASubMatrix(WMMAMatrixA, 8, 8, 4, Real, WMMAColMajorKind8) :: sa
WMMASubMatrix(WMMAMatrixB, 8, 8, 4, Real, WMMAColMajorKind8) :: sb
WMMASubMatrix(WMMAMatrixC, 8, 8, 4, Real, WMMAKind8) :: sc
integer :: lda, ldb, ldc
type(dim3) :: warpIdx
integer :: i, row_t, col_t
lda = m
ldb = k
ldc = m
warpIdx%x = (threadIdx%x - 1)/warpsize + 1
warpIdx%y = threadIdx%y
row_t = (blockIdx%x-1)*tile_m + (warpIdx%x - 1)*wmma_m + 1
col_t = (blockIdx%y-1)*tile_n + (warpIdx%y - 1)*wmma_n + 1
sc = 0.0_8
do i = 1, k, wmma_k
call wmmaLoadMatrix(sa, a(row_t,i), lda)
call wmmaLoadMatrix(sb, b(i,col_t), ldb)
call wmmaMatMul(sc, sa, sb, sc)
enddo
call wmmaStoreMatrix(c(row_t,col_t), sc, ldc)
end subroutine wmma_tile
end module m
The parameters tile_m=32 and tile_n=32 denote the size of the tile of C that gets calculated per thread block. It is convenient to define a warpIdx variable of type(dim3) that is analogous to threadIdx, as all the WMMA operations are done on a per-warp basis. The threadIdx variable appears in the code but is only used to calculate the warpIdx values. The row_t and col_t indices now depend on the warpIdx values as well as the blockIdx values, but aside from that the code is like the code in Example 3.
While this code addresses the low occupancy of previous examples, it is inefficient in that it loads each 8×4 tile of A and 4×8 tile of B twice. The performance impact of such redundant loads is addressed in the next section.
Performance of WMMA code
One of the most important aspects affecting performance of Tensor Core code is data reuse. The following code example is an artificial benchmark that helps quantify the cost of performing loads from global memory to the WMMA submatrices, which live in registers, as well as the cost of the store operation from WMMA submatrices to global memory. This code example uses the same 8×4 A and 4×8 B matrices to calculate their product in a tile of a larger C matrix:
attributes(global) subroutine dmma_peak(a, b, c, m, n, niter)
use cudadevice
use wmma
implicit none
real(8) :: a(wmma_m,wmma_k), b(wmma_k,wmma_n), c(m, n)
integer, value :: m, n, niter
WMMASubMatrix(WMMAMatrixA, 8, 8, 4, Real, WMMAColMajorKind8) :: sa
WMMASubMatrix(WMMAMatrixB, 8, 8, 4, Real, WMMAColMajorKind8) :: sb
WMMASubMatrix(WMMAMatrixC, 8, 8, 4, Real, WMMAKind8) :: sc
type(dim3) :: warpIdx
integer :: i, row_t, col_t
warpIdx%x = (threadIdx%x - 1)/warpsize + 1
warpIdx%y = threadIdx%y
row_t = (blockIdx%x-1)*tile_m + (warpIdx%x - 1)*wmma_m + 1
col_t = (blockIdx%y-1)*tile_n + (warpIdx%y - 1)*wmma_n + 1
sc = 0.0_8
call wmmaLoadMatrix(sa, a, wmma_m)
call wmmaLoadMatrix(sb, b, wmma_k)
do i = 1, niter
call wmmaMatMul(sc, sa, sb, sc)
Enddo
call wmmaStoreMatrix(c(row_t,col_t), sc, m)
end subroutine dmma_peak
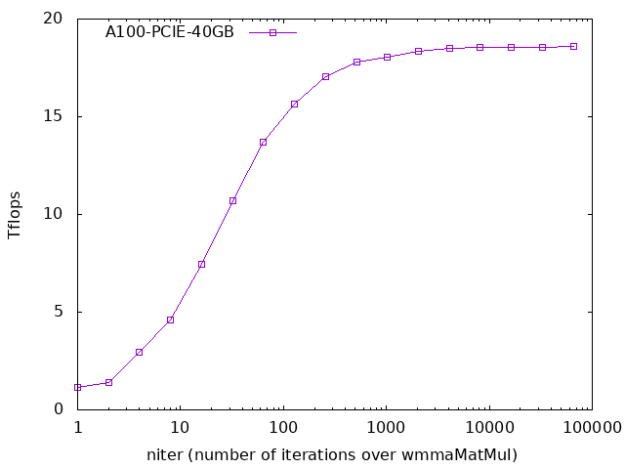
A loop in the host code launches the kernel with different values of niter, the number of times a matrix multiplication occurs using a single load/store of the input/output matrices. CUDA events are used to time the kernel and the resulting teraflops are reported.
Figure 1 shows that for large values of niter, the cost of loading and storing matrices is largely amortized away. The wmmaMatMul performance tapers off at about 18.5 TFlops. However, if there is no reuse of the A and B submatrices, so each load is used in only one mmaMatMul call, the kernel operates at around 1 TFlops. As a result, the first step in achieving good performance is to reuse the input matrices as much as possible, which brings you to the next example.
Example 5: Shared-memory matrix multiply
From this point on, the performance of code is measured and therefore larger matrix sizes are used. For example, the following code example has values of m, n, and k of 3,200. To illustrate the shared memory strategy, each thread block calculates a 32×32 tile of C. The parameters for this case are as follows:
! dmma tile sizes integer, parameter :: wmma_m = 8 integer, parameter :: wmma_n = 8 integer, parameter :: wmma_k = 4 ! C tile of size tile_m x tile_n is calculated per thread block ! tile_m must be a multiple of 32 integer, parameter :: tile_m = 32 integer, parameter :: tile_n = tile_m/wmma_m*wmma_n ! problem matrix sizes ! m, n, and k must be multiples of tile_m, tile_n, and wmma_k integer, parameter :: m = (3200/tile_m)*tile_m integer, parameter :: n = (3200/tile_n)*tile_n integer, parameter :: k = (3200/wmma_k)*wmma_k ! shared memory padding for A tile in terms of real(8) elements ! padding must be a multiple of 16 bytes, so smPad must be a multiple of 2 integer, parameter :: smPad = 0 ! Number of times kernel is called and timed integer, parameter :: nRuns = 20 ! dependent parameters integer, parameter :: blockRows_as = tile_m/wmma_m
The expression for tile_n evaluates to 32. The parameter smPad specifies shared memory padding, which I discuss shortly. The parameter nRuns specifies the number of times that this kernel is run and its performance measured. When performed on an idle GPU, a single run may complete before the clocks reach their optimal level. Because these BLAS-like routines are typically used in large code blocks where such transitional periods are a small part of the overall run, you want to measure the asymptotic state. Alternatively, you could run untimed kernels before measuring performance as was done in the code that produced Figure 1. Another option is to fix the GPU clocks using nvidia-smi -ac.
A strategy for optimizing reuse of data in WMMA submatrices is to load the 32×4 A tile into shared memory, and for each warp of threads to load a single 4×8 submatrix of B and use that to calculate a 32×8 column of the C tile that is calculated by the thread block (Figure 2). To load the 32×4 A tile used here, this kernel is launched with four warps of threads per thread block.
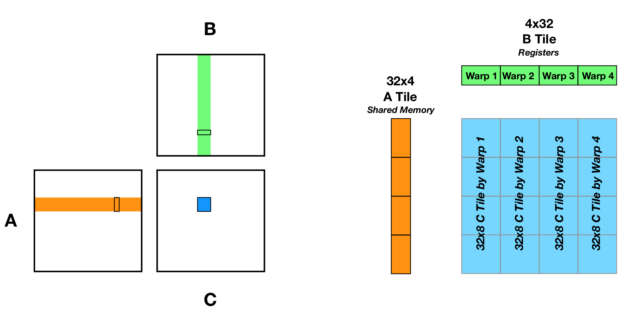
In the kernel, the shared memory and WMMA submatrix declarations are as follows:
real(8), shared :: a_s(tile_m+smPad, wmma_k)
WMMASubMatrix(WMMAMatrixA, 8, 8, 4, Real, WMMAColMajorKind8) :: sa
WMMASubMatrix(WMMAMatrixB, 8, 8, 4, Real, WMMAColMajorKind8) :: sb
WMMASubMatrix(WMMAMatrixC, 8, 8, 4, Real, WMMAKind8) :: &
sc(blockRows_as)
To avoid shared memory bank conflicts, a variable amount of padding is added to the first index of the shared memory tile. This padding can be specified using the smPad parameter. The leading dimension of the source matrix, for the shared memory array a_s, is as follows:
lda_s = tile_m + smPad
This must be a multiple of 16 bytes, thus the smPad parameter must be a multiple of 2. Because each warp of threads is calculating a 32×8 tile of matrix C, an array of 4 (blockRows_as) submatrix accumulators is required. The kernel code performs the following index calculations prior to entering the main loop over the k
! row and column indices to the first element
! in the tile_m x tile_n tile of C
row_t = (blockIdx%x-1)*tile_m + 1
col_t = (blockIdx%y-1)*tile_n + 1
! C column index for each warp
col_w = col_t + (warpIdx-1)*wmma_n
col_w is the column index used to load the warp’s B tile. After initializing the array of accumulator submatrices, the main loop over the k dimension and the loop to store the resultant C submatrices are as follows:
do i = 1, k, wmma_k ! load the tile_m x wmma_k tile of A into shared memory, call syncthreads() a_s(rowIdx_as, colIdx_as) = & a(row_t-1 + rowIdx_as, i-1 + colIdx_as) ! load B into wmma submatrices, ! each warp gets a different 4x8 block call wmmaLoadMatrix(sb, b(i,col_w), ldb) ! for a_s call syncthreads() ! loop down column of C tile calculating sc() do j = 1, blockRows_as ! each warp loads the same 8x4 block of A call wmmaLoadMatrix(sa, a_s(1+(j-1)*wmma_m, 1), lda_s) call wmmaMatMul(sc(j), sa, sb, sc(j)) enddo end do do j = 1, blockRows_as call wmmaStoreMatrix(c(row_t+(j-1)*wmma_m,col_w), sc(j), ldc) end do
For each iteration over the k dimension, the tile_m×4 A tile is loaded into shared memory. The size of the shared memory tile is chosen largely to keep the indexing for loading A into shared memory as simple and efficient as possible. By restricting tile_m to be a multiple of 32, multiple warps can load in a single column of the A tile facilitated by the mappings:
colIdx_as = (threadIdx%x - 1)/(tile_m) + 1
rowIdx_as = threadIdx%x - (colIdx_as-1)*(tile_m)
These mappings are only used when reading in shared memory on the line:
a_s(rowIdx_as, colIdx_as) = &
a(row_t-1 + rowIdx_as, i-1 + colIdx_as)
The number of warps used to read in a tile of A into shared memory dictates the number of warps per thread block and hence the number of columns in the B and C tiles:
integer, parameter :: tile_m = 32
Integer, parameter :: tile_n = tile_m/wmma_m*wmma_n
In the main loop of the kernel over the k dimension, after issuing loads for the shared memory A tile, each warp of threads loads a B WMMA submatrix using the col_w index. A thread synchronization ensures all the elements in a_s are available to all threads. The code then loops over block rows, loading the WMMA submatrices from shared memory and performing the matrix multiplication. After the main loop over the k dimension completes, the results in the sc(j) tile are stored to global memory.
The code can be compiled with the following command:
nvfortran -cuda -gpu=cc80,cuda11.1 -O3 -o tensorCoreR8SharedA tensorCoreR8SharedA.CUF
Executing the code should produce comparable results to the following:
$ ./tensorCoreR8SharedA
Device: A100-PCIE-40GB
M = 3200, N = 3200, K = 3200
tile_m = 32, tile_n = 32
thread block = 128x1x1
grid = 100x100x1
shared memory padding (elements): 0
nRuns: 1
Test passed, TFlops: 6.324040
Adding padding to the shared memory tile to avoid bank conflicts, you obtain a significant bump in performance:
$ ./tensorCoreR8SharedA
Device: A100-PCIE-40GB
M = 3200, N = 3200, K = 3200
tile_m = 32, tile_n = 32
thread block = 128x1x1
grid = 100x100x1
shared memory padding (elements): 2
nRuns: 1
Test passed, TFlops: 8.234760
Table 2 shows the results for various cases.
| Kernel | smPad = 0 | smPad = 2 | smPad = 4 | smPad = 6 |
| 32×32×4 | 6.3 | 8.2 | 9.2 | 8.2 |
| 64×64×4 | 6.6 | 8.8 | 10.0 | 8.8 |
| 96×96×4 | 4.9 | 6.2 | 6.3 | 6.2 |
| 128×128×4 | 6.6 | 9.3 | 9.6 | 9.3 |
Tensor Core submatrices are register-intensive. While a single submatrix is declared for the A and B matrices, an array of submatrices is declared for the accumulator. With the number of submatrices per block column growing with the C tile size, as well as the number of block columns, register utilization becomes a limiting factor in performance. In the next example, I investigate a way to increase data reuse without increasing register usage.
Example 6: Matrix multiply with multiple wmma_k blocks
The code in Example 5 used a single block of wmma_k=4 for the A and B tiles. In this section, you generalize this to allow tile_k to be multiples of wmma_k. Increasing the size of the k dimension in the A and B tiles increases data reuse without increasing the register utilization by the Tensor Core submatrices, which is a function of tile_m and tile_n.
To facilitate the larger sizes of the A and B tiles in this example, both A and B tiles are placed in shared memory. In doing so, a single thread block may require more shared memory than the limit of 48KB of static shared memory. As a result, you use dynamic shared memory. When multiple dynamic shared memory arrays are declared in a kernel, all such arrays point to the head of the dynamic shared memory block, and it is up to you to do the bookkeeping needed to partition that block to different arrays. This can be accomplished with defining offsets, but to accommodate multiple two-dimensional arrays of different shapes, use Cray pointers. Declare a block of dynamic shared memory in the kernel with the following line:
real(8), shared :: dynSM(*)
You also declare Cray pointers used to partition this array into the A and B tiles:
real(8), shared :: a_s(tile_m+smPadA, tile_k); pointer(a_sCrayP, a_s)
real(8), shared :: b_s(tile_k+smPadB, tile_n); pointer(b_sCrayP, b_s)
The pointers a_sCrayP and b_sCray are associated with portions of the dynamic shared memory array in the block:
block
integer :: offset
offset = 0
a_sCrayP = loc(dynSM(offset+1))
offset = offset + (tile_m+smPadA)*tile_k
b_sCrayP = loc(dynSM(offset+1))
end block
After the pointers are associated, the pointees a_s and b_s can be used as any two-dimensional array would be used. In host code, you must set the amount of shared memory used with the cudaFuncSetAttribute function, as the amount of dynamic shared memory needed may exceed the default maximum.
smSizeInBytes = 8*((tile_m+smPadA)*tile_k &
+ (tile_k+smPadB)*tile_n)
i = cudaFuncSetAttribute(dmm, &
cudaFuncAttributeMaxDynamicSharedMemorySize, &
smSizeInBytes)
In Example 5, you used shared memory for the A tile rather than the B tile. With a leading dimension of tile_m+smPad, where tile_m is a multiple of 32, the A tile can be loaded into shared memory in a coalesced fashion, and relatively little shared memory is used for padding. On the other hand, for the B tile with a leading dimension of wmma_k+smPad, loading data into shared memory would not be coalesced and a significant portion of shared memory would be dedicated to the padding for any non-zero padding. The choice of having a warp of threads calculate a block column of the C tile fell out of using shared memory for the A tile.
With both A and B tiles in shared memory, and with typical values of tile_k equal to or greater than tile_m, having a warp of threads calculate a block row or block column of C are both valid from a performance standpoint. It ends up that having a warp of threads calculate a block row of C performs better. The following example code performs the WMMA submatrix loads and matrix multiplications after loading the A and B tiles into shared memory:
! nested loop over WMMA submatrices
!
! k is outermost loop so 8x4 WMMA submatrix of A is reused
do kt = 1, tile_k, wmma_k
! each warp gets a different 8x4 block of A
call wmmaLoadMatrix(sa, a_s(rowIdx_w, kt), lda_s)
! now go across block row of B/C
do j = 1, blockCols_bs
nt = (j-1)*wmma_n + 1
! each warp gets the same block of B
call wmmaLoadMatrix(sb, b_s(kt,nt), ldb_s)
call wmmaMatMul(sc(j), sa, sb, sc(j))
enddo
enddo
Figure 3 shows a graphical depiction of the process. For the first iteration of the outermost loop over the k dimension, the warps in a thread block collectively load a block column of the A matrix, where each warp loads a different 8×4 submatrix of A. Each warp then loads the same 4×8 submatrix of B, and C is updated with the resulting matrix multiplications. With the same submatrices in A, the kernel iterates over block columns of B, updating the corresponding C submatrices within each iteration. The kernel then advances to the next block in k, loading the second block column of A and iterating over the second block row of B. Placing k as the outermost loop here facilitates the reuse of data already loaded into submatrices (the block column of A).
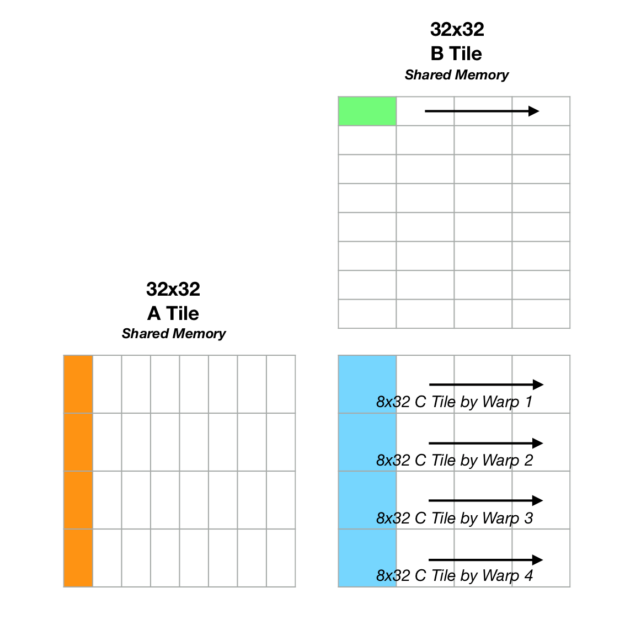
Table 3 shows the results for a sample of parameters. This is just a small sampling of the available parameter space. To keep the indexing relatively simple when loading shared memory, choice of tile_k is limited, in addition to the previous restrictions on tile_m and tile_m.
| tile_m × tile_n | tile_k = 32 | tile_k = 64 | tile_k = 96 | tile_k = 128 |
| 32×32 | 10.6 | 9.0 | – | 6.4 |
| 64×64 | 14.5 | 14.4 | – | 8.65 |
| 96×96 | 10.7 | 10.9 | 11.5 | – |
| 128×128 | 12.86 | 13.5 | – | – |
Conclusion
I’ve included the source code for all the examples in this post: tensorCore_source_code.zip.
As mentioned earlier, to keep the indexing used to load the shared memory tiles simple in the examples, I’ve restricted the parameter space of tile_m, tile_n, and tile_k. These restrictions can be relaxed with some additional indexing arithmetic and guards to prevent out-of-bounds accesses. Even with a limited parameter space and relatively simple kernels, you were able to get 14.5 out of a peak 18.5 TFlops.
The earlier examples can be used as a template for other code blocks that use Tensor Cores on double precision data. Another, more hands-off approach to leveraging the power of Tensor Cores is through the cuTensor library, which has CUDA Fortran interfaces. For more information, see Bringing Tensor Cores to Standard Fortran.