
 High-energy physics research aims to understand the mysteries of the universe by describing the fundamental constituents of matter and the interactions between them. Diverse experiments exist on Earth to re-create the first instants of the universe. Two examples of the most complex experiments in the world are at the Large Hadron Collider (LHC) at CERN … Continued
High-energy physics research aims to understand the mysteries of the universe by describing the fundamental constituents of matter and the interactions between them. Diverse experiments exist on Earth to re-create the first instants of the universe. Two examples of the most complex experiments in the world are at the Large Hadron Collider (LHC) at CERN … Continued
High-energy physics research aims to understand the mysteries of the universe by describing the fundamental constituents of matter and the interactions between them. Diverse experiments exist on Earth to re-create the first instants of the universe. Two examples of the most complex experiments in the world are at the Large Hadron Collider (LHC) at CERN and the Deep Underground Neutrino Experiment (DUNE) at Fermilab.
The LHC is home to the highest energy particle collisions in the world and the discovery of the Higgs boson. LHC detectors are like ultra–high-speed cameras that capture the remnants of those collisions every 25 nanoseconds to create a 5D image in space, time, and energy. LHC physicists collect huge datasets to find extremely rare events. Those events may give clues about the Higgs boson as a portal to new physics or the particle nature of dark matter.
The DUNE experiment sends a beam of particles called neutrinos from the west suburbs of Chicago to an underground mine 1,300 km away in South Dakota. There, a massive 40-kton detector is being constructed 1.5 km beneath the earth’s surface to observe these feebly interacting particles. Studying neutrinos can help us answer questions such as the origin of matter in the universe and the behavior of core-collapse supernova in the Milky Way galaxy.
These experiments consist of unique and cutting-edge particle detectors that create massive, complex, and rich datasets with billions of events. They require sophisticated algorithms to reconstruct and interpret the data.
Modern machine learning algorithms provide a powerful toolset to detect and classify particles, from familiar image-processing convolutional neural networks to newer graph neural network architectures. A full reconstruction of these particle collisions requires novel approaches to handle the computing challenge of processing so much raw data. In a series of studies, physicists from Fermilab, CERN, and university groups explored how to accelerate their data processing using NVIDIA Triton Inference Server.
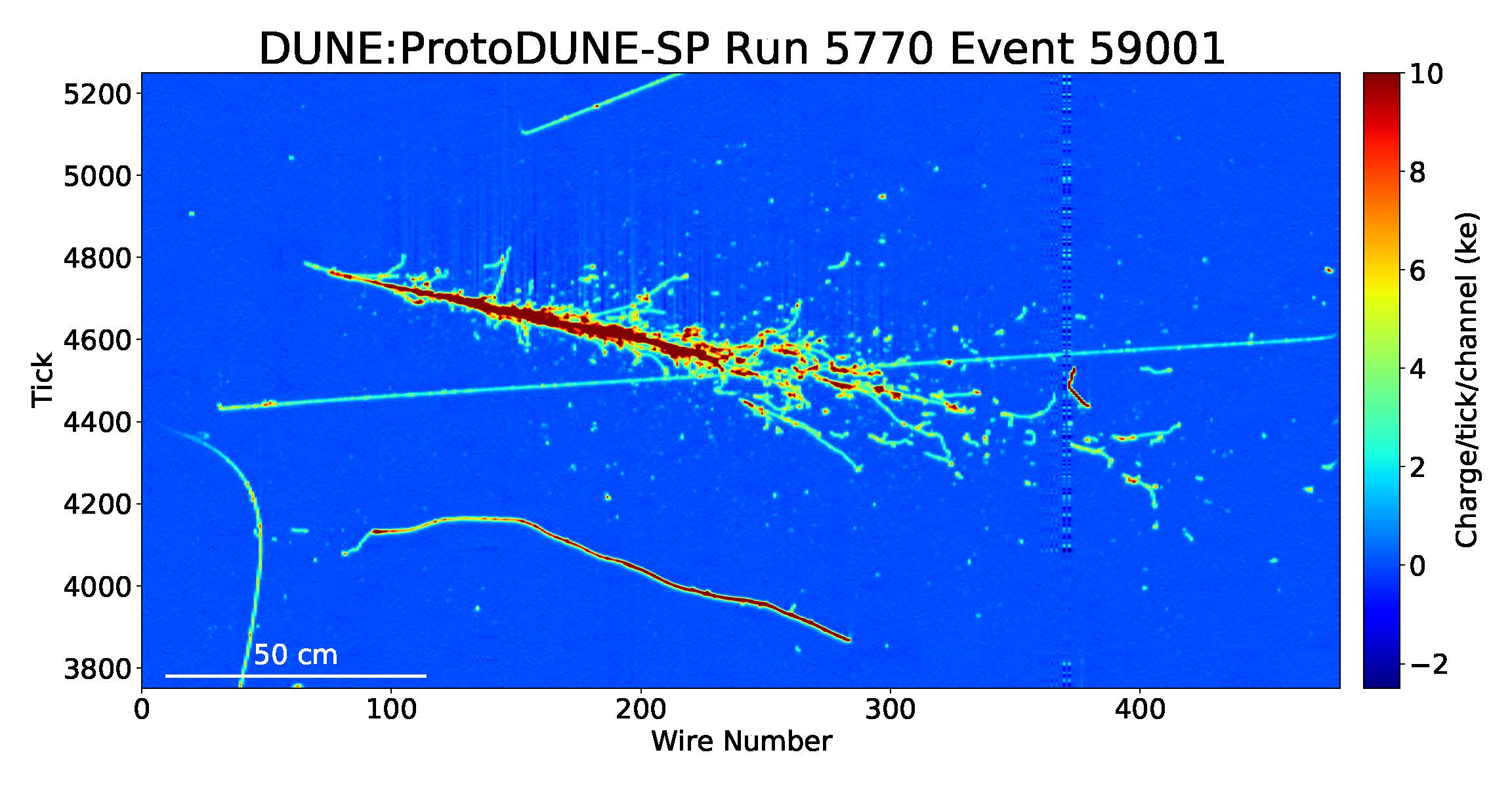
The full offline reconstruction chain for the ProtoDUNE-SP detector is a good representative of event reconstruction in present and future accelerator-based neutrino experiments. For more information, see GPU-accelerated machine learning inference as a service for computing in neutrino experiments.
In each event, charged particles interact with the liquid argon in the detector, liberating ionization electrons that drift across the detector volume under the influence of an electric field. These electrons induce signals as they pass through and are collected by a set of wire planes at the end of the drift path. Two spatial coordinates can be determined from the different angular orientations of the wires in each plane. The third coordinate can be determined from the drift time of the ionization electrons. As a result, a detailed 3D image of the neutrino interaction can be reconstructed.
The most computationally intensive step of the reconstruction process involves an ML algorithm that looks at 48×48 pixel cutouts, or patches. Those patches represent small sections of the full event and the algorithm identifies the particles in them. Importantly, over the entire ProtoDUNE-SP detector, there are thousands of 48×48 patches to be classified, such that a typical event may have approximately 55,000 patches to process. In the following section, we discuss the performance implications of this process and how using NVIDIA Triton Inference Server helps us to scale the deep learning inference.
Similarly, for the LHC, a series of neural networks can be used to process data from low-level cluster calibration and electron energy regression to jet (particle spray) classification.
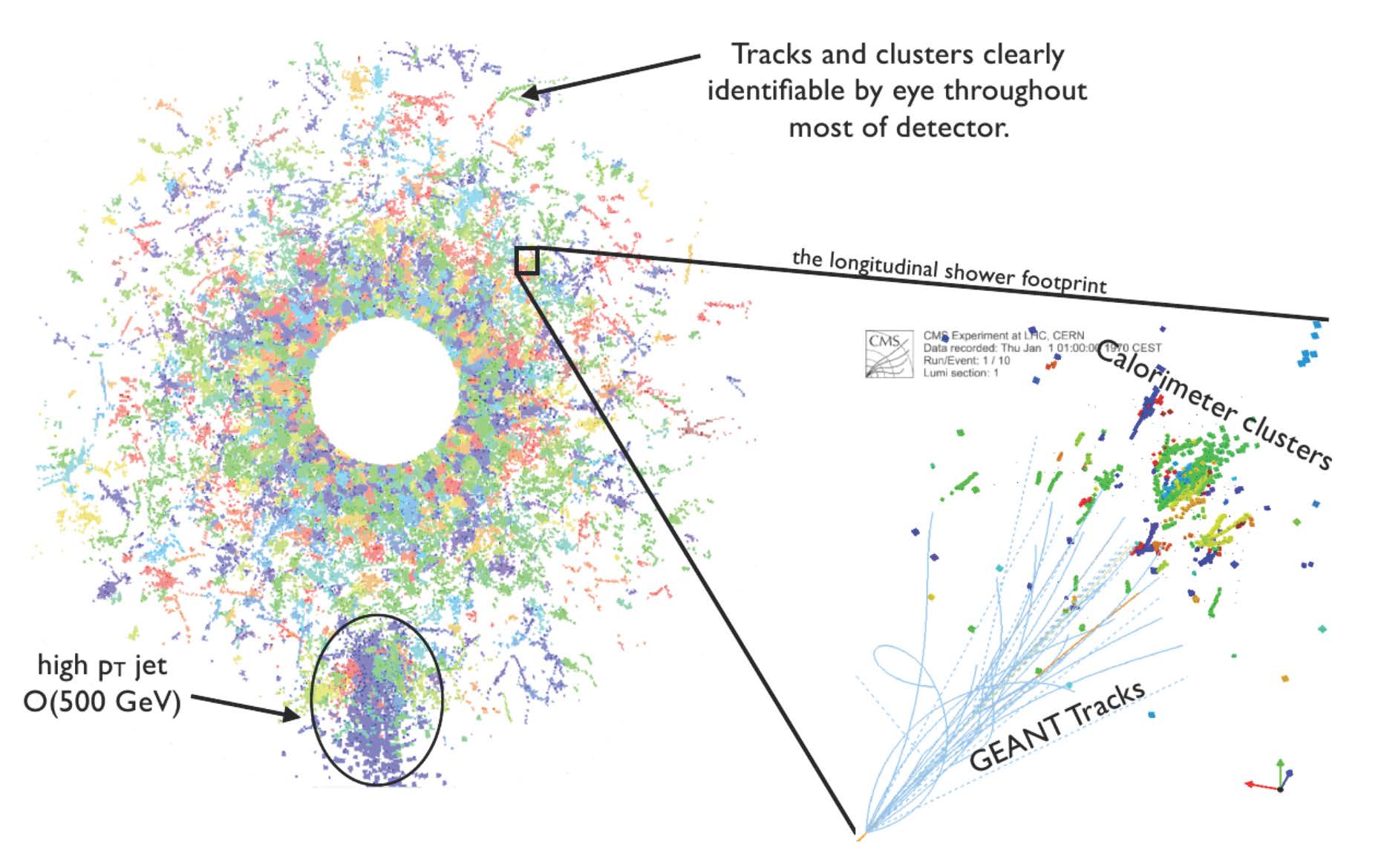
Figure 3 shows how a similar paradigm is used for the LHC. Hits recorded by the calorimeter system are combined into clusters (zoomed-in section at right). These can then be further combined into higher-level reconstructed particle objects, such as the jet indicated at the bottom left. In simulated events such as this one, the reconstructed clusters can be related to the “truth” information from the simulation software (GEANT) to measure the accuracy of the algorithms.
Compute-intensive process
For the ProtoDUNE-SP detector, the reconstruction processing time is dominated by running convolutional neural network inference for the thousands of patches in each event. When you’re running inference on a typical CPU, this consumes 65% of the total time for reconstruction. The current dataset consists of 400 TB from hundreds of millions of neutrino events. The team decided to use NVIDIA T4 GPUs to speed up this most compute-intensive process. In the initial trial phase, they used T4 instances on Google Cloud.
In production, thousands of client nodes feed detector data (images) into the reconstruction process. The scale of computing is so large that a distributed worldwide grid of computing resources is needed. This poses challenges to coordinating and optimizing resources shared by different sites worldwide. To cope with these challenges, the team decided to use a novel inference-as-a-service computing paradigm for the first time.
Inference as a service with NVIDIA Triton Inference Server
The team implemented their generic approach, called SONIC (Services for Optimized Network Inference on Coprocessors), for inference as a service using NVIDIA Triton Inference Server. This technology is available from the NGC Catalog, a hub for GPU-optimized AI containers, models, and SDKs built to simplify and accelerate AI workflows.
NVIDIA Triton simplifies the deployment of AI models at scale in production. It’s an open-source inference serving software package that helps teams deploy trained AI models:
- From any framework: TensorFlow, TensorRT, PyTorch, ONNX Runtime, or a custom framework
- From any storage: Local, Google Cloud Platform, Amazon S3, or Microsoft Azure Storage
- On any GPU- or CPU-based infrastructure: Cloud, data center, or edge
The team deployed the NVIDIA Triton server as a container and used Kubernetes to orchestrate the various cloud resources. Each GPU server in the cluster runs an instance of the NVIDIA Triton server. The clients run on separate, CPU-only nodes and send inference requests using gRPC over the network. Kubernetes handles load balancing and resource scaling for the GPU cluster.
Outcome
The use of T4 GPUs resulted in a 17x speed-up of the most time-consuming ML module of the workflow: track and particle shower hit identification. Overall workflow (event processing time) was accelerated by a factor of 2.7x.
The following are key benefits that the team achieved:
- No disruption. The workflow was accelerated without disruption to any of the other algorithms or experiment software.
- Allocation flexibility. In this deployment, many client nodes sent requests to a single GPU. This allowed heterogeneous resources to be allocated and reallocated based on demand and task, providing significant flexibility and potential cost reduction.
- Reduced dependencies. There’s a reduced dependency on open-source ML frameworks in the experimental code base. Otherwise, the experiment would be required to integrate and support separate C++ APIs for every framework in use.
- Concurrent use. NVIDIA Triton also used all available GPUs automatically when the servers had multiple GPUs, further increasing the flexibility of the server. In addition, NVIDIA Triton can execute multiple models from various ML frameworks concurrently.
- Dynamic batching. NVIDIA Triton provides dynamic batching, which combines multiple requests into optimally sized batches to perform inference as efficiently as possible for the task at hand. This effectively enables simultaneous processing of multiple events without any changes to the experiment software framework.
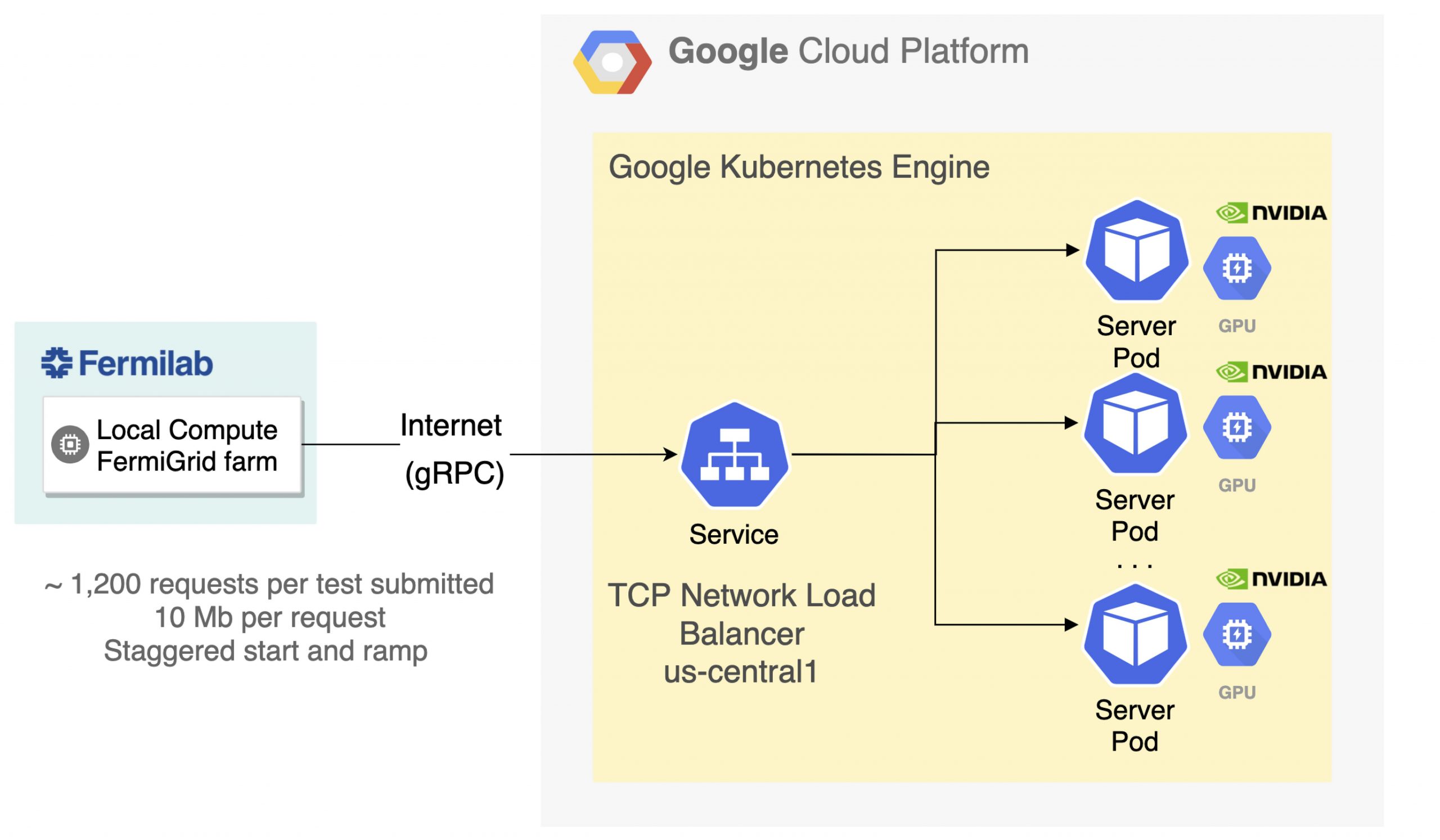
To scale the NVIDIA T4 GPU throughput flexibly, we used a Google Kubernetes Engine (GKE) cluster for server-side workloads. Kubernetes Ingress was used as a load-balancing service to distribute incoming network traffic among the NVIDIA Triton pods. Prometheus-based monitoring was used for the following:
- System metrics from the underlying virtual machine
- Kubernetes metrics for the overall health and state of the cluster
- Inference-specific metrics gathered from NVIDIA Triton through a built-in Prometheus publisher
All metrics were visualized through a Grafana instance, also deployed within the same cluster. The team kept the pod-to-node ratio at 1:1 throughout the studies, with each pod running an instance of NVIDIA Triton Inference Server (v20.02-py3) from NGC. The throughput was maximized when 68 CPU client processes sent requests to a single remote GPU. The exact ratio depends on the algorithm and workflow.
Summary
The offline neutrino reconstruction workflow was accelerated by deploying ML models on NVIDIA T4 GPUs. NVIDIA Triton and Kubernetes helped the team implement inference as a scalable service in a flexible and cost-effective way. Though we focused on a result specific to neutrino physics, a similar result was achieved for the LHC and constitutes a successful proof of concept. These results pave the way for deploying DL inference as a service at scale in high energy physics experiments.
For more information, see the following resources:
- Neutrino (ProtoDUNE) results
- LHC (CMS/ATLAS) results
- SONIC approach
- NVIDIA Triton Inference Server
- NGC Catalog
Acknowledgments
We would like to thank, globally, the multi-institutional team that performed these neutrino and LHC studies. For more information about their work, see fastmachinelearning.org. Featured image of Protodune detector taken by Maximilien Brice from CERN.