
 TL;DR UCX/UCX-Py is an accelerated networking library designed for low-latency high-bandwidth transfers for both host and GPU device memory objects. You can easily get started by installing through conda (limited to linux-64): Introduction RAPIDS is committed to delivering the highest achievable performance for the PyData ecosystem. There are now numerous GPU libraries for high-performance and … Continued
TL;DR UCX/UCX-Py is an accelerated networking library designed for low-latency high-bandwidth transfers for both host and GPU device memory objects. You can easily get started by installing through conda (limited to linux-64): Introduction RAPIDS is committed to delivering the highest achievable performance for the PyData ecosystem. There are now numerous GPU libraries for high-performance and … Continued
This post was originally published on the RAPIDS AI Blog.
TL;DR
UCX/UCX-Py is an accelerated networking library designed for low-latency high-bandwidth transfers for both host and GPU device memory objects. You can easily get started by installing through conda (limited to linux-64):
> conda install -c rapidsai ucx-py ucxIntroduction
RAPIDS is committed to delivering the highest achievable performance for the PyData ecosystem. There are now numerous GPU libraries for high-performance and scalable alternatives to underlying common data science and analytics workflows. cuDF, which implements the Pandas DataFrame API, and cuML, which implements scikit-learn’s machine learning API, are two such accelerated libraries. These “scale-up” solutions, together with Dask, enable significant end-to-end performance improvements by combining state-of-the-art GPUs with distributed processing. However, with any scale-out solution, the bottleneck for distributed computation often lies with communication. We present here how easy it is to get started with our new Python communication library UCX-Py, based on OpenUCX, the Unified Communication X open framework, along with the current benchmarks.
UCX-Py allows RAPIDS to take advantage of hardware interconnects available on the system, such as NVLink (for direct GPU-GPU communication) and InfiniBand (for direct GPU-Fiber communication), thus providing higher bandwidth and lower latency for the application. UCX-Py does not only enable communication with NVLink and InfiniBand — including GPUDirectRDMA capability — but all transports supported by OpenUCX, including TCP and shared memory.
UCX-Py is a high-level library, meaning users are not required to do any complex message passing to be able to use it. The user triggers send on one process and receives on a different process, it’s that simple. More importantly, applications which already scale using Dask, can easily start using UCX with a small, two line change to existing code. Just switch to the UCX protocol, instead of the default TCP protocol.
Just like RAPIDS, UCX-Py is open source and currently hosted at https://github.com/rapidsai/ucx-py. Always up-to-date documentation is available in https://ucx-py.readthedocs.io/en/latest/.
Using UCX-Py with Dask
RAPIDS allows both multi-node and multi-GPU scalability by utilizing Dask, therefore Dask was the first and simplest use case for UCX-Py. While RAPIDS users may already be familiar with the dask-cuda package, one very simple use case is to start a cluster using all GPUs available in the system and connect a Dask client to it. Dask users often start a cluster as follows:
from dask_cuda import LocalCUDACluster
from distributed import Client
cluster = LocalCUDACluster(protocol="tcp")
client = Client(cluster)The code above utilizes Python sockets for all communication over the TCP protocol. To switch to the UCX protocol for communication, there are two changes needed in the LocalCUDACluster constructor:
- Specify the UCX protocol;
- Specify the transport we want to use.
TCP over UCX
The simplest use of the UCX protocol in Dask is enabling TCP over UCX, and it looks as follows:
cluster = LocalCUDACluster(protocol="ucx", enable_tcp_over_ucx=True)The change above does not need any special hardware and can be used in any machine that’s currently using dask-cuda (it also applies to LocalCluster in dask/distributed) as long as the UCX-Py package has been installed as well.
NVIDIA NVLink and NVSwitch
Now that we know how we can get started with UCX-Py in Dask, we can move on to more interesting cases. The first one is using NVLink (including NVSwitch if available) for all GPU-GPU communication, and we only add one more flag as seen below:
cluster = LocalCUDACluster(protocol="ucx", enable_tcp_over_ucx=True, enable_nvlink=True)Note that in the above we also enable TCP over UCX, and it is a required step to allow NVLink. As a facility to users, the code above is equivalent to the one below (enable_tcp_over_ucx=True is implicit):
cluster = LocalCUDACluster(protocol="ucx", enable_nvlink=True)NVIDIA InfiniBand
The last case we will discuss here is enabling InfiniBand. At this stage, you probably guessed that enabling it requires an enable_infiniband=True flag, and you guessed right. However, since InfiniBand requires communication between a GPU and an InfiniBand device, we need to specify the name of the correct InfiniBand interface to be used by each GPU. Suppose there is an InfiniBand interface named mlx5_0:1 available, a cluster could be created as follows:
cluster = LocalCUDACluster(protocol="ucx", enable_infiniband=True, ucx_net_devices="mlx5_0:1")From a topological point-of-view, we prefer to select the InfiniBand device closest to the GPU, ensuring highest bandwidth and lowest latency. A complex system such as a DGX-1 or a DGX-2 may contain several GPUs and several InfiniBand interfaces, in such a case we don’t want to simply choose the first one, but the most optimal for that particular system. To address that, we introduced automatic detection of InfiniBand devices:
cluster = LocalCUDACluster(protocol="ucx", enable_infiniband=True, ucx_net_devices="auto")It is also possible to have a custom configuration passing a function to the ucx_net_devices keyword argument, for that please check the documentation for the LocalCUDACluster class.
TCP, NVLink and InfiniBand
The transports listed above are not mutually exclusive, so you can use all of them together as well:
cluster = LocalCUDACluster(protocol="ucx", enable_tcp_over_ucx=True, enable_nvlink=True, enable_infiniband=True, ucx_net_devices="mlx5_0:1")UCX with dask-cuda-worker CLI
All the options described above are also available in the dask-cuda-worker CLI. To use UCX with that, you must first start a dask-scheduler and choosing the UCX protocol:
DASK_UCX__CUDA_COPY=True DASK_UCX__TCP=True DASK_UCX__NVLINK=True DASK_UCX__INFINIBAND=True DASK_UCX__NET_DEVICES=mlx5_0:1 dask-scheduler --protocol="ucx"The command above will start a scheduler and tell its address, which will be something such as ucx://10.10.10.10:8786 (note the protocol is now ucx://, as opposed to the default tcp://). Note also that we have to set Dask environment variables to that command to mimic the Dask-CUDA flags to enable each individual transport, this is because dask-scheduler is part of the mainline Dask Distributed project where we can’t overload it with all the same CLI arguments that we can with dask-cuda-worker, for more details on UCX configuration with Dask-CUDA, please see the Dask-CUDA documentation on Enabling UCX Communication.
We will then connect dask-cuda-worker to that address, and since the scheduler uses the ucx:// protocol, workers will too without any --protocol="ucx". It is still necessary to specify what transports workers need to use:
dask-cuda-worker ucx://10.10.10.10:8786 --enable-tcp-over-ucx --enable-nvlink --enable-infiniband --ucx-net-devices="auto"Benchmarks
We want to analyze the performance gains of UCX-Py in two scenarios with a variety of accelerated devices. First, how does UCX-Py perform when passing host and device buffers between two endpoints for both InfiniBand and NVLink. Second, how does UCX-Py perform in a common data analysis workload.
When benchmarking 1GB messages between endpoints over NVLink we measured bandwidth of 46.5 GB/s — quite close to the theoretical limit of NVLink: 50 GB/s. This shows that the addition of a Python layer to UCX core (written in C) does not significantly impact performance. Using a similar setup, we configured UCX/UCX-Py to pass messages over InfiniBand. Measurements present a bandwidth of 11.2 GB/s in that case, which is also similarly near the hardware limit (12.5 GB/s) of Connect X-4 Mellanox InfiniBand controllers.
As the numbers above suggest, passing single message GPU objects between endpoints is very efficient and we now ask: how does UCX-Py perform in the context of a common workflow? Dataframe merges are good candidates to benchmark as they are extremely common and require a high degree of communication. Additionally, a merge, performed by Dask-cuDF, will also test critical operations in RAPIDS and Dask libraries which can degrade communications, most notably serialization.
The graph in Figure 1 shows the cuDF merge benchmark performance on a DGX1 with all 8 GPUs in use. This workflow generates two dask-cudf dataframes with random, equally distributed data, and merges both dataframes into one.
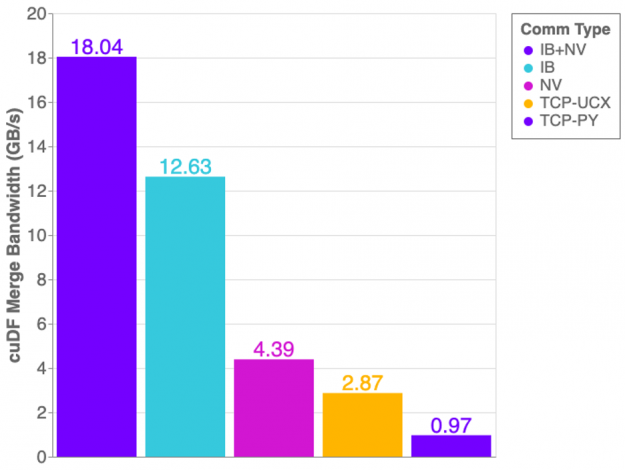
Overall we see improvements using UCX-Py compared to using Python Sockets for TCP communication. However, there are some unexpected results. If NVLink is capable of 32GB/s and InfiniBand is 12GB/s, why then does InfiniBand perform better than NVLink? The answer is: topology! The layout of hardware interconnection is of great importance and can often be complex.
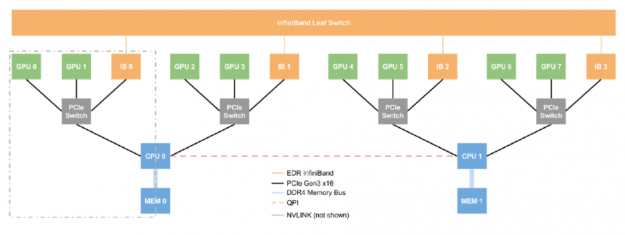
Figure 2 presents the layout of an NVIDIA DGX-1 server — we can think of this single box as a small supercomputer. The DGX-1 has eight P100 GPUs, four InfiniBand devices, and two CPUs. What is the most efficient route to take when passing data between GPU0 and GPU1? What about GPU2 and GPU7? GPU0 and GPU1 are connected via NVLink but GPU2 and GPU7 have direct communication lines, therefore, when passing data, we must perform two costly operations: Device-to-Host (moving data from GPU2 to the host) and Host-to-Device (moving data from the host to GPU7), and transferring data through main memory is expensive. Fortunately, a DGX-1 allows transfers between two GPUs that are not NVLink connected to use a more efficient transfer method than the costly operations described. With InfiniBand and GPUDirectRDMA, two GPUs can communicate without touching the main memory at all, allowing GPU7 to directly read GPU2’s memory via the InfiniBand interconnect only.
Referring back to Figure 1, you can now see why only using InfiniBand outperforms the NVLink connection alone — Host-to-Device/Device-to-Host transfers are costly! However, when combining InfiniBand with NVLink we achieve more optimal performance.
Further improvements
UCX-Py is under constant development, which means changes may occur without notice. Our ultimate commitment is to deliver high-performance communication to Python in a high-quality library package. With that said, we expect in the near future to keep on improving stability and ease-of-use, enabling users to benefit from enhanced performance with little to no effort to configure UCX-Py, thus automatically enabling accelerated communication hardware.
So far, we have tested UCX-Py mostly in DGX-1 and DGX-2 systems, where point-to-point and end-to-end performance was demonstrated. We scaled our testing up to one hundred Dask CUDA workers. We are constantly working to improve performance and stability, particularly for large scale workflows, and encourage users to engage with our team on GitHub and extend the discussion on UCX-Py.