
 The time that it took to discover the COVID-19 vaccine is a testament to the pace of innovation in the healthcare industry. Pace of innovation can be directly linked to the thriving innovator ecosystem and the large number of AI-based healthcare startups. In comparison, the 5G wireless industry takes approximately a decade to introduce next … Continued
The time that it took to discover the COVID-19 vaccine is a testament to the pace of innovation in the healthcare industry. Pace of innovation can be directly linked to the thriving innovator ecosystem and the large number of AI-based healthcare startups. In comparison, the 5G wireless industry takes approximately a decade to introduce next … Continued
The time that it took to discover the COVID-19 vaccine is a testament to the pace of innovation in the healthcare industry. Pace of innovation can be directly linked to the thriving innovator ecosystem and the large number of AI-based healthcare startups. In comparison, the 5G wireless industry takes approximately a decade to introduce next generation systems.
The O-RAN Alliance is pioneering one way of addressing the pace of innovation and post-deployment feature enhancements. The traditional model of opaque design is being disrupted by a transparent paradigm with open and standardized interfaces. Forget using closed and proprietary interfaces, along with having limited options for an ecosystem to introduce new capabilities into deployed equipment.
The new paradigm includes concepts such as the RAN Intelligent Controller (RIC), a key technology that enables third parties to add new capabilities to the network. This provides monetization opportunities for not only the developer ecosystem but also network operators.
Future of wireless
Softwarization, virtualization, and disaggregation are some of the foundational concepts of 5G-and-beyond communication networks. Softwarization of the RAN, and its realization using a software-defined radio (SDR) paradigm, is critical for supporting the three key use cases that are the hallmark of 5G:
- Enhanced mobile broadband (eMBB)
- Ultra-reliable low-latency communication (URLLC)
- Massive machine type communication (mMTC)
A key differentiator between 4G and 5G is the capability, through software, to dynamically bring up and tear down network slices composed of eMBB, URLLC, and mMTC flows. Indeed, it’s a core value proposition of 5G.
Virtualization is an enabler for the efficient sharing of hardware and software assets in support of heterogeneous workloads in mobile edge computing (MEC). Disaggregation represents the dawn of a new ecosystem for the wireless industry. It opens the door to new business opportunities for a broad spectrum and a new generation of hardware developers.
Traditional, monolithic, opaque wireless infrastructure equipment is being disaggregated into the logical entities of the centralized unit (CU), distributed unit (DU), and radio unit (RU). This enables traditional network and emerging private 5G network operators with the flexibility to tailor a system architecture to meet their operational and business needs.
An equally important component of this new approach to wireless networking infrastructure is the standardization of interfaces, both physical and logical, between the hardware and software subsystems. Together with the development of an open software stack, these capabilities enable the rapid deployment of new network features through software. They also enable a new generation of software ecosystem developers to write application code for deployment in a network. These are applications that, by the virtue of these standardized interfaces and APIs, facilitate the control and interaction with entities running in the CU, DU, and RU.
RAN Intelligent Controller
The O-RAN Alliance is standardizing an open, intelligent, and disaggregated RAN architecture. The objective is to enable the construction of an operator-defined RAN using COTS hardware and provision for AI/ML-based intelligent control of 5G and future generation 6G wireless networks. Replace onventional RANs built using proprietary hardware, interfaces, and software with vRANs employing COTS hardware and open interfaces. The new architecture has options to support both proprietary software and applications developed by the ecosystem.
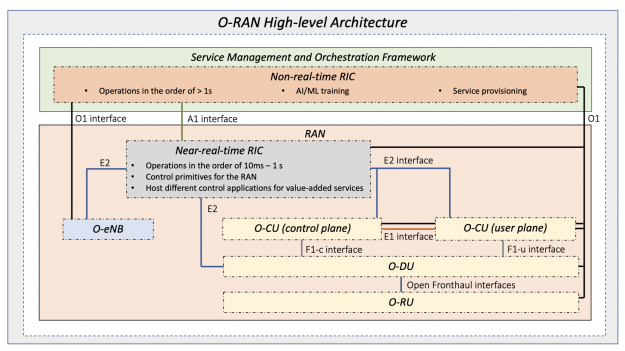
One of the most important elements of the O-RAN standard is the RAN Intelligent Controller (RIC) shown in Figure 1. The RIC consists of two main components:
- Non-real-time RIC (Non-RT RIC): Supports network functions at time scales of >1 second.
- Near real-time RIC (Near-RT RIC): Supports functions operating at time scales of 10 milliseconds–1 second.
As part of the SMO framework, some of the responsibilities of the Non-RT RIC include ML model lifecycle management and ML model selection. It also includes the marshaling, curation, and preprocessing of data gathered from the CU, DU, and even RU, in preparation for model training on the training host.
The Near-RT RIC introduced in the O-RAN architecture brings software-defined intelligence to the system. It includes advanced near-realtime analytics on data streamed from CU and DU, AI model inference, and online retraining of machine learning (ML) models.
Together, the SMO, Non-RT RIC, and Near-RT RIC bring ML techniques to all layers of the network architecture: layer-1 PHY, layer-2, and at the network level itself through AI-based self-organizing network (SoN) capabilities.
To help understand the RIC in more detail, consider an LTE example. The approach is similar for 5G NR. This example employs RIC-enabled AI for cell capacity management by using a long short-term memory (LSTM) traffic prediction model. The objective is to predict traffic for all cells in the network and mitigate future congestion. For more information, see Intelligent O-RAN for Beyond 5G and 6G Wireless Networks.
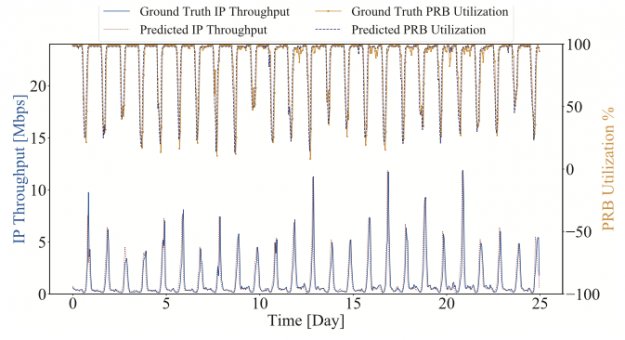
A two-layer LSTM network employs 12 LSTM cells per layer. It is trained using UE throughput measurements and physical resource block (PRB) utilization from 17 LTE eNBs in a real-world, fully operational, wireless network. The inference operation predicts UE throughput and eNB downlink PRB utilization 1 hour into the future.
Figure 2 shows the ground truth (actual) and predictions (LSTM inference) for throughput and PRB utilization for one cell of one eNB. The average prediction accuracy of 92.64% is remarkable. With the ability to forecast cell loadings at up to 1 hour into the future, the eNB can take steps to avoid coverage outages, for example cell splitting.
The role of the SMO in this example is to gather data from the O-CU/DU through the O1 interface (Figure 1) and deliver it to the Non-RT RIC. A Non-RT RIC rApp in turn queries the AI server associated with the SMO. The AI server runs a training process to update the LSTM model parameters based on fresh data collected from the operating network.
GPUs are the natural choice for ML training from both a programming model and compute capability perspective. The training workload is large due to the scale of the wireless network. We are not interested in model training for a single eNB with a few cells. Instead, we’re interested in training for a system that could have 100s to 1000s of base stations, with many 1000s of cells and 1000s to 10,000s of UEs. Having a GPU-powered AI training server provides the option of sharing that infrastructure over many SMO hosts. It is more cost– and power-efficient than a CPU AI training host. In other words, there are both CAPEX and OPEX advantages for the network operator.
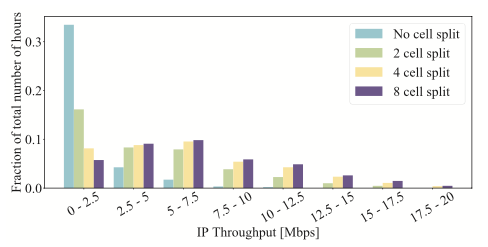
After the training server has updated the LSTM model, the updated model parameters are returned to the Non-RT RIC rApp and the throughput/PRB prediction process continues with the updated model. Figure 3 shows the throughput gains. The vertical axis shows the fraction of the number of operating hours that user throughput for each band is indicated on the horizontal axis.
For example, you can see that, without cell splitting, throughput is in the range of 5-7.5 Mbps for approximately 1% of the time. With predictive cell splitting, throughput is in this same range for approximately 10%, a difference of a factor of 10.
An xApp that NVIDIA is researching is to enable intelligent and predictive multicell joint resource management. This has the potential to significantly improve the energy efficiency of the network.
AI algorithms running on a Non-RT RIC can predict user density and traffic load in each cell within a prediction window (on a seconds-to-minutes time scale). Predictions are based on the traffic history provided by CUs and DUs. Each DU scheduler makes decisions to switch off certain cells with low predicted traffic load to reduce energy consumption. They also trigger coordinated multipoint transmission/reception (CoMP) from neighboring active cells to ensure effective coverage.
The Near-RT RIC can help achieve the efficient multiplexing of eMBB and URLLC data traffic on the same frequency band. Due to significantly diverse service requirements, eMBB and URLLC transmissions are scheduled on two different time scales: time slot and mini-slot levels for eMBB and URLLC, respectively.
An AI-based xApp at the Near-RT RIC could learn and predict URLLC packet arrival patterns based on traffic statistics streamed from the DU over the E2 interface (Figure 1). Such predictive knowledge is used at the DU scheduler to optimize the resource reservation for URLLC mini-slots on top of eMBB data flows. It is also used to minimize the loss of eMBB throughput caused by such multiplexing.
You could also envision an xApp for massive MIMO beamforming optimization to maximize spectral efficiency. In this case, the Non-RT RIC hosts an rApp to perform long-term data analytics. The rApp’s task is to collect and analyze antenna array parameters and continually update an ML model. The Near-RT RIC xApp is implementing ML inference to configure, for example, beam horizontal and vertical aperture and cell shape.
Why GPUs?
The signal processing requirements (MACs/second) of the 5G NR physical layer are immense. The massive parallelism of the GPU brings the hardware resources to bear that can support this class of workload. In fact, a single GPU can support the baseband processing requirements of many 10s of carriers. Specialized hardware accelerators would typically have been employed in previous generation systems. However, the parallel nature of the GPU enables the softwarization of the RAN by providing a C++ abstraction for programming advanced signal-processing algorithms.
However, the value of the GPU extends beyond vRAN signal processing. In a 5G and 6G systems where big-data-meets-wireless, where AI/ML is used to improve network performance, GPUs are the default standard for model training and inference.
A common GPU-based hardware platform can support the tasks of training, inference, and signal processing. However, it’s not only about GPU hardware. An equally important consideration is the software for programming GPUs and SDKs and libraries for application development.
GPUs are programmed using CUDA, the world’s only commercially successful C/C++–based parallel programming framework. There is also a rich set of GPU libraries for developing, for example, data analytics pipelines using the NVIDIA RAPIDS software suite. The data analytics pipeline could be one of the services that the SMO/Non-RT RIC engages to update and fine-tune inference models running under the Near-RT RIC.
VMware and NVIDIA partnership
In early 2021, VMware released the world’s first O-RAN standard–compliant Near-RT RIC for integration and testing with select RAN and xApp vendor partners. To facilitate development of xApps on its Near-RT RIC, VMware provides its xApp partners with a set of developer resources packaged as an SDK.
Today, VMware and NVIDIA are excited to announce that the Near-RT RIC SDK now enables xApp developers to leverage GPU acceleration in their applications. This is an exciting milestone for the industry. It opens the doors for the larger industry to build AI/ML-powered capabilities for modern RANs, including those based on the NVIDIA Aerial gNB stack. Eventually, the VMware RIC and NVIDIA Aerial stack combination will enable the development and monetization of new and innovating xApps that enhance or expand the capabilities of a deployed network.
Conclusion
Openness and intelligence are the two core pillars of the O-RAN initiatives. As the 5G rollout and the ramp of 6G research continues, intelligence will be all-encompassing for the deployment, optimization, and operation of wireless networks.
Transitioning away from the opaque approach historically employed in cellular networks opens the door to a new era of swift innovation and time-to-market of new RAN features. NVIDIA vRAN (NVIDIA Aerial) and AI technology, combined with the VMware RIC, will foster a new generation of wireless and open up new monetization and innovation opportunities.