A pair of new demos running GeForce RTX technologies on the Arm platform unveiled by NVIDIA today show how advanced graphics can be extended to a broader, more power-efficient set of devices. The two demos, shown at this week’s Game Developers Conference, included Wolfenstein: Youngblood from Bethesda Softworks and MachineGames, as well as The Bistro Read article >
Top game artists, producers, developers and designers are coming together this week for the annual Game Developers Conference. As they exchange ideas, educate and inspire each other, the NVIDIA Studio ecosystem of RTX-accelerated apps, hardware and drivers is helping advance their craft. GDC 2021 marks a major leap in game development with NVIDIA RTX technology Read article >
Discover how NVIDIA CloudXR with Teradici’s PCoIP protocol enables XR users to experience seamless streaming. CloudXR uses Teradici’s ability to support high-fidelity video and use of flexible integration options for enterprise IT systems.
NVIDIA CloudXR is an SDK that enables you to implement real-time GPU rendering and streaming of rich VR, AR, and XR applications on remote servers, including the cloud. Applications can connect and stream remotely on low-powered VR devices or tablets where normally they wouldn’t function properly.
However, even when the underlying application executes on a remote NVIDIA CloudXR server, there are times when a facilitator wants to mirror the view of what an XR user sees. Unlike many consumer-driven experiences, enterprise XR applications often require a degree of synchronous interactivity between the user in XR and an external non-VR user.
To achieve connectivity to a NVIDIA CloudXR server for non-XR users, there are many methods available, each with their own considerations. Microsoft RDP supports a “headless” implementation of NVIDIA CloudXR by streaming XR content to a headset or tablet without requiring a host to log in to the server. However, this is not helpful in cases where a trainer or coach is needed to monitor the XR experience streamed to the headset. Virtual Network Computing (VNC), a popular alternative to RDP, must meet strict security requirements in enterprise environments. As such, it’s common for VNC connections to be prohibited.
It supports high-fidelity video and frame rate experiences for host connections.
It enables flexible integration options for enterprise IT requirements.
Deployment can also be orchestrated and streamlined to multiple cloud providers, making it seamless for most NVIDIA CloudXR-powered applications.
“Use of AR and VR is increasing, particularly for our customers in industries like AEC and Game Development. Collaborations, such as this initiative with NVIDIA, ensure that Teradici CAS provides the absolute best user experience for designers and engineers with the trusted security of PCoIP, which keeps proprietary designs safe in the cloud.”
Mirela Cunjalo, director of product management at Teradici
Teradici CAS offers a secure high-performance remote workstation user interface for the CAD designer or content creator developing 3D content, also streamed as a VR session either collaboratively or to the same design.
Teradici offers easy-to-consume marketplace instances for every major cloud provider. This creates a great baseline with a guest OS (Windows Server 2019), NVIDIA drivers and licensing, and the Teradici CAS Ultra software preinstalled.
You can install and configure NVIDIA CloudXR Server, SteamVR, and your favorite AR or VR application, and you’ll instantly have a powerful cloud workstation.
To get started, procure the preferred marketplace offer for Teradici, depending on your cloud service provider of choice:
Next, select an NVIDIA-powered instance type available from the cloud provider. Follow your organization’s networking and security best practices to ensure connectivity to your instances. Download a PCoIP client, based on the client OS, to start a session on the cloud instance. Finally, enter the IP addresses for your instances and define the username and password for the PCoIP client.
With NVIDIA CloudXR, you can further enhance immersive experiences and deliver advanced VR and AR sessions to untethered devices. For more information, see NVIDIA CloudXR.
RTXMU (RTX Memory Utility) combines both compaction and suballocation techniques to optimize and reduce memory consumption of acceleration structures for any DXR or Vulkan Ray Tracing application.
Acceleration structures spatially organize geometry to accelerate ray tracing traversal performance. When you create an acceleration structure, a conservative memory size is allocated.
Upon initial build, the graphics runtime doesn’t know how optimally a geometry fits into the oversized acceleration structure memory allocation.
After the build is executed on the GPU, the graphics runtime reports back the smallest memory allocation that the acceleration structure can fit into.
This process is called compacting the acceleration structure and it is important for reducing the memory overhead of acceleration structures.
Another key ingredient to reducing memory is suballocating acceleration structures. Suballocation enables acceleration structures to be tightly packed together in memory by using a smaller memory alignment than is required by the graphics API.
Typically, buffer allocation alignment is at a minimum of 64 KB while the acceleration structure memory alignment requirement is only 256 B. Games using many small acceleration structures greatly benefit from suballocation, enabling the tight packaging of many small allocations.
The NVIDIA RTX Memory Utility (RTXMU) SDK is designed to reduce the coding complexity associated with optimal memory management of acceleration structures. RTXMU provides compaction and suballocation solutions for both DXR and Vulkan Ray Tracing while the client manages synchronization and execution of acceleration structure building. The SDK provides sample implementations of suballocators and compaction managers for both APIs while providing flexibility for the client to implement their own version.
For more information about why compaction and suballocation are so important in reducing acceleration structure memory overhead, see Tips: Acceleration Structure Compaction.
Why Use RTXMU?
RTXMU allows you to quickly integrate acceleration structure memory reduction techniques into their game engine. Below is a summary of these techniques along with some key benefits in using RTXMU
Reduces the memory footprint of acceleration structures involves both compaction and suballocation code, which are not trivial to implement. RTXMU can do the heavy lifting.
Abstracts away memory management of bottom level acceleration structures (BLASes) but is also flexible enough to enable users to provide their own implementation based on their engine’s needs.
Manages all barriers required for compaction size readback and compaction copies.
Passes back handles to the client that refer to complex BLAS data structures. This prevents any mismanagement of CPU memory, which could include accessing a BLAS that has already been deallocated or doesn’t exist.
Can help reduce BLAS memory by up to 50%.
Gives the benefit of less translation lookaside buffer (TLB) misses by packing more BLASes into 64 KB or 4 MB pages.
RTXMU Design
RTXMU has a design philosophy that should reduce integration complexities for most developers. The key principles of that design philosophy are as follows:
All functions are thread-safe. If simultaneous access occurs, they are blocking.
The client passes in client-owned command lists and RTXMU populates them.
The client is responsible for synchronizing command list execution.
API Function Calls
RTXMU abstracts away the coding complexities associated with compaction and suballocation. The functions detailed in this section describe the interface entry points for RTXMU.
Initialize—Specifies the suballocator block size.
PopulateBuildCommandList—Receives an array of D3D12_BUILD_RAYTRACING_ACCELERATION_STRUCTURE_INPUTS and returns a vector of acceleration structure handles for the client to fetch acceleration structure GPUVAs later during top-level acceleration structure (TLAS) construction, and so on.
PopulateUAVBarriersCommandList – Receives acceleration structure inputs and places UAV barriers for them
PopulateCompactionSizeCopiesCommandList – Performs copies to bring over any compaction size data
PopulateUpdateCommandList—Receives an array of D3D12_BUILD_RAYTRACING_ACCELERATION_STRUCTURE_INPUTS and valid acceleration structure handles so that updates can be recorded.
PopulateCompactionCommandList—Receives an array of valid acceleration structure handles and records compaction commands and barriers.
RemoveAccelerationStructures—Receives an array of acceleration structure handles that specify which acceleration structure can be completely deallocated.
GarbageCollection—Receives an array of acceleration structure handles that specify that build resources (scratch and result buffer memory) can be deallocated.
GetAccelStructGPUVA—Receives an acceleration structure handle and returns a GPUVA of the result or compacted buffer based on state.
Reset—Deallocates all memory associated with current acceleration structure handles.
Suballocator DXR design
The BLAS suballocator works around the 64 KB and 4 MB buffer alignment requirement by placing small BLAS allocations within a larger memory heap. The BLAS suballocator still must fulfill the 256 B alignment required for BLAS allocations.
If the application requests 4 MB or larger suballocation blocks, then RTXMU uses placed resources with heaps that can provide 4 MB alignment.
If the application requests fewer than 4 MB suballocation blocks, then RTXMU uses committed resources, which only provide 64 KB alignment.
The BLAS suballocator reuses freed suballocations within blocks by maintaining a free list. If a memory request is greater than the suballocator block size, then a single allocation is created that can’t be suballocated.
Compaction DXR design
If the build requests compaction, then RTXMU requests that the compaction size be written out to a chunk of video memory. After the compaction size has been copied from video memory to system memory, then RTXMU allocates a suballocated compaction buffer to be used as the destination for the compaction copy.
The compaction copy takes the original build containing unused memory segments and truncates it down to the smallest memory footprint it can fit in. The original noncompacted build and scratch memory gets released back to the suballocator after compaction is complete. The only thing you have worry about is passing in the allow compaction flag and calling GetGPUVA with a BLAS handle. The GPUVA could either be the original build or the compacted build, based on what state the BLAS is in.
How to Use RTXMU
In this section, I detail the RTXMU sequence loop and synchronization.
RTXMU sequence loop
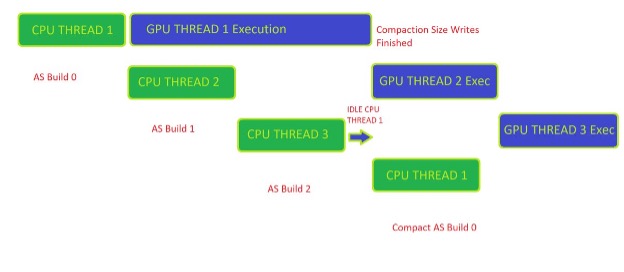
Figure 1 shows a normal usage pattern of RTXMU. The client manages the command list execution, while everything else is a call into RTXMU
First, initialize RTXMU by passing in the suballocator block size and the device responsible for allocating suballocation blocks. In each frame, the engine builds new acceleration structures while also compacting acceleration structures built in previous frames.
After RTXMU populates the client’s command lists, the client is free to execute and manage the synchronization of the initial build to the final compaction copy build. It’s important to make sure that each acceleration structure build has been fully executed before calling PopulateCompactionCommandList. This is left to the client to manage properly.
When an acceleration structure has finally reached the compaction state, then the client can choose to call GarbageCollection, which notifies RTXMU that the scratch and original acceleration structure buffer can be deallocated. If the engine does heavy streaming of assets, then the client can deallocate all acceleration structure resources by calling RemoveAS with a valid acceleration structure handle.
Figure 1. RTXMU flow chart of a typical use case delineating client and RTXMU code
Figure 2 shows the synchronization required by the client to manage compaction-ready workloads properly. The example here is a triple frame buffered loop in which the client can have up to three asynchronous frames being built on the CPU and executed on the GPU.
To get the compaction size available on the CPU side, Build 0 must have finished executing on the GPU. After the client has received a fence signal back from the GPU, the client can then call RTXMU to start the compaction command list recording.
A helpful way to manage the synchronization of compaction for acceleration structures is to employ a key/value pair data structure of some kind that tracks the state of each acceleration structure handle given by RTXMU. The four basic states of an acceleration structure can be described as follows:
Prebuilt—The build command is recorded on a command list but hasn’t finished executing on the GPU.
Built— The initial build has been executed on the GPU and is ready for compaction commands.
Compacted—The compaction copy has been finished on the GPU and is ready for GarbageCollection to release the scratch and initial build buffers.
Released—The client releases the acceleration structure from memory because it is no longer in the scene. At that point, all memory associated with an acceleration structure handle is freed back to the OS.
Figure 2. Client code can only initiate compaction workloads after the initial acceleration structures builds have finished execution on the GPU.
RTXMU Test Scenes
RTXMU was tested with six text scenes to provide real use case data about the benefits of compaction and suballocation. The following figures show just some of the scenes.
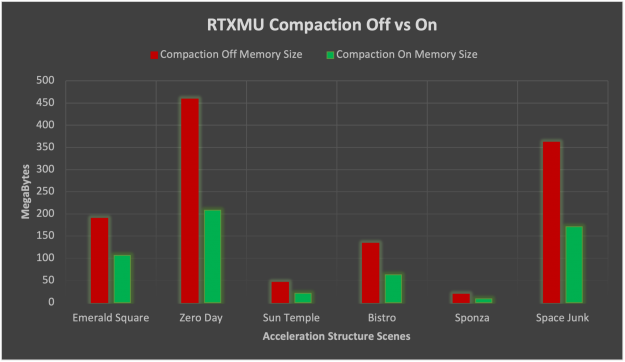
Figure 3. Zero Day scene 10,740 BLAS, uncompacted acceleration structure memory size 458.9 MB, compacted acceleration structure memory size 208.3 MB, 55% memory reduction, suballocating memory saved 71.3 MB
On average, compaction on NVIDIA RTX cards reduced acceleration structure by 52% for the test scenes. The standard deviation of compaction memory reduction was 2.8%, which is quite stable.
Figure 6. Bar graph comparing compaction on versus off on NVIDIA RTX 3000 series GPUs
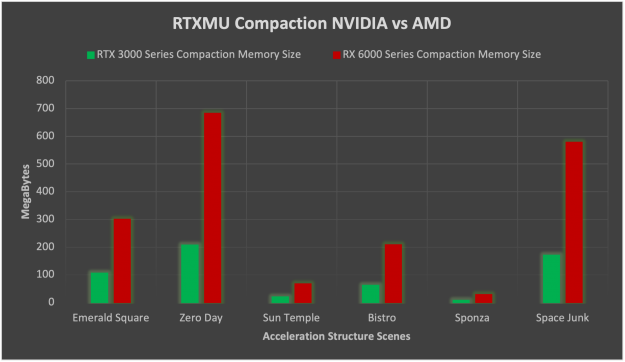
When enabling compaction on NVIDIA and AMD HW, the memory savings on NVIDIA HW is much improved compared to AMD. NVIDIA ends up being on average 3.26x smaller than AMD for acceleration structure memory when enabling compaction. The reason for such a huge reduction in memory footprint on NVIDIA is that AMD without compaction uses double the memory as is when compared to NVIDIA. Compaction then also reduces the NVIDIA memory by another 50% on average while AMD tends to reduce memory only by 75%.
Figure 7. Bar graph comparing compaction of NVIDIA 3000 series versus AMD 6000 series GPUs
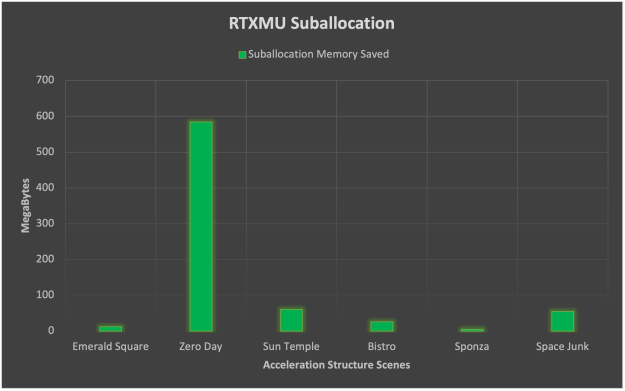
Suballocation tells a slightly different story here in which scenes with many small acceleration structures like Zero Day benefit greatly. The average memory savings from suballocation ends up being 123 MB but the standard deviation is rather large at 153 MB. From this data, we can assert that suballocation is highly dependent on the scene geometry and benefits from thousands of small triangle count BLAS geometry.
Figure 8. Bar graph showing the memory savings of suballocation for specific scenes
Source Code
NVIDIA is open-sourcing the RTXMU SDK along with a sample application integrating RTXMU. Maintaining RTXMU as an open-source project on GitHub helps developers understand the logic flow and provides access to modifying the underlying implementation. The RT Bindless sample application provides an example of an RTXMU integration for both Vulkan Ray Tracing and DXR backends.
Here’s how to build and run the sample application integrating RTXMU. You must have the following resources:
Windows, Linux, or an OS that supports DXR or Vulkan Ray Tracing
CMake 3.12
C++ 17
Git
First, clone the repository using the following command:
Next, open CMake. For Where is the source code, enter the /donut_examples folder. Create a build folder in the /donut_examples folder. For Where to build the binaries, enter the new build folder. Select the cmake variable NVRHI_WITH_RTXMU to ON, choose Configure, wait for it to complete and then click Generate.
If you are building with Visual Studio, then select 2019 and x64version. Open the donut_examples.sln file in Visual Studio and build the entire project.
Find the rt_bindless application folder under /Examples/Bindless Ray Tracing, choose the project context (right-click) menu, and choose Startup Project.
By default, bindless ray tracing runs on DXR. To run the Vulkan version, add -vk as a command-line argument in the project.
Summary
RTXMU combines both compaction and suballocation techniques to optimize and reduce memory consumption of acceleration structures for any DXR or Vulkan Ray Tracing application. The data shows that using RTXMU significantly reduces acceleration structure memory. This enables you to either add more geometry to your ray-traced scenes or use the extra memory for other resources.
Real-time ray tracing has advanced the art of lighting in video games, but it’s a computationally expensive process. Aiming to reduce these costs, NVIDIA has developed a memory utility that combines both compaction and suballocation techniques to optimize and reduce memory consumption of acceleration structures.
RTX Memory Utility (RTXMU) Available Now
Reducing Memory Consumption with an Open Source Solution
Real-time ray tracing has advanced the art of lighting in video games, but it’s a computationally expensive process. Aiming to reduce these costs, NVIDIA has developed a memory utility that combines both compaction and suballocation techniques to optimize and reduce memory consumption of acceleration structures. We’ve turned this solution into an SDK called RTXMU, and we are making it available as an open source release today. It’s built to support any DXR or Vulkan Ray Tracing application.
Compaction of acceleration structures with RTXMU eliminates any wasted memory from the initial build operation. For applications using RTXMU, NVIDIA RTX cards get a ~50% reduction in memory footprint. Additionally, suballocating acceleration structure buffers with RTXMU prevents fragmentation and wasted space. Scenes with thousands of small unique BLAS benefit greatly from suballocation.
How Can RTXMU Help You, Right Away?
RTXMU is easy to integrate, and it provides benefits immediately.
A suballocation and compaction memory manager takes significant engineering time to validate. RTXMU reduces the time it takes for a developer to integrate compaction and suballocation into an RTX title.
RTXMU also abstracts away the memory and compaction state management of the BLAS, and manages all barriers required for compaction size readback and compaction copies.
Diving a bit deeper, RTXMU uses handle indirection to BLAS data structures to prevent any mismanagement of CPU memory, which could include accessing a BLAS that has already been deallocated or doesn’t exist. Also, suballocation gives the benefit of less TLB (Translation Lookaside Buffer) misses by packing more BLASes into 64 KB or 4 MB pages.
Put simply, RTXMU will make your real-time ray traced games and applications run better, without significant effort on your part.
Where can I get RTXMU?
RTXMU is an open source SDK available today, and an update will come this week. For tips on deployment, check out our RTXMU getting started blog.
Nsight Graphics 2021.3 is an all-in-one graphics debugger and profiler to help game developers get the most out of NVIDIA hardware.
Nsight Graphics 2021.3 is an all-in-one graphics debugger and profiler to help game developers get the most out of NVIDIA hardware. From analyzing API setup to solve nasty bugs, to providing deep insight into how your application utilizes the GPU to drain every last bit of performance, Nsight Graphics is the ultimate tool in your arsenal.
We enhanced GPU Trace to support Vulkan/OpenGL interoperability. It is now possible for you to use the latest profiling capabilities on applications that use both the OpenGL and Vulkan graphics APIs. We support capturing OpenGL SwapBuffers calls for overall frame timing, as well as capturing screenshots of windows rendered to by OpenGL. You can also use NVTX to mark user ranges while using OpenGL.
We have enabled Optix support for GPU Trace, including Vulkan applications that trace rays in the compute shader and use OptiX as a denoiser. GPU Trace is able to show NVTX markers, which when used with OptiX can provide helpful contextual information. See NVIDIA OptiX Ray Tracing Engine for more information on OptiX.
Nsight Graphics now ships with sample applications and reports to help you experiment with and understand many of the tool’s features. You can access them via the new Samples submenu menu in the top level Help menu.
The System Trace activity can now directly launch Nsight Systems from Nsight Graphics. This allows you to more easily utilize the powerful CPU and GPU profiling capabilities of Nsight Systems with the same application settings used by Nsight Graphics. Direct launch simplifies parameter management by allowing you to keep these application settings in a single location. This feature is compatible with Nsight Systems version 2021.3 or later.
We have made improvements to the user interface for GPU Trace Analysis by changing the meaning of the severity and certainty icons. The original numeric groups have been refined, and we now use numbers or the ‘+’ icon to denote ranges with potential performance improvements. Further, these indicators scale according to the maximum projected gain, making it easier to find the most important ranges to focus on. All the detailed performance information is sorted and grouped in the tabs below the indicators, and provides a useful explanation of the metric evaluation suggestions, as well as steps to take to improve the performance of the range.
We have added the ability to rename a C++ Capture in the Project Explorer. This allows you to better organize or mark-up your C++ Captures.
Finally, we also added support for Arch Linux and the DirectX 12 Agility SDK
For more details on Nsight Graphics 2021.3, check out the release notes (link). Visit Nsight Graphics to stay informed about the latest updates.
We want to hear from you! Please continue to use the integrated feedback button that lets you send comments, feature requests, and bugs directly to us with the click of a button. You can send feedback anonymously or provide an email so we can follow up with you about your feedback. Just click on the little speech bubble at the top right of the window.
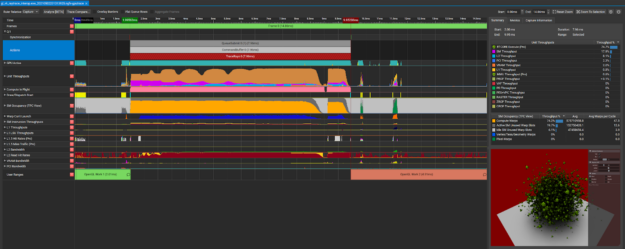
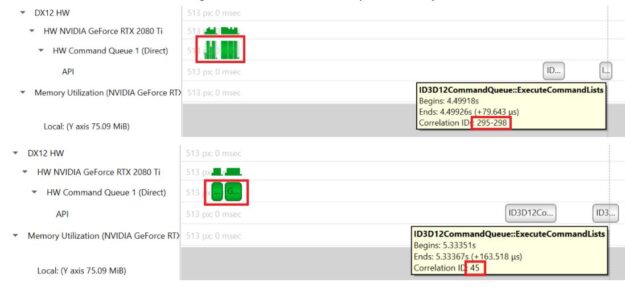
This release introduces several improvements aimed to assist the user with locating issues and improve the profiling experience. User workflows are improved with both the introduction of the Expert System View which identifies problematic patterns, as well as the new ability to load multiple reports into the same timeline to investigate multi-process issues with greater ease. Nsight Systems now supports Windows 21H1 SDK, sample GPU PCIe BAR1 request activity, trace UCX asynchronous API calls, and trace Vulkan QueueSubmit or Direct3D12 ExecuteCommandList GPU workloads as a reduced overhead option.
Fig 1. GPU PCIe BAR1 request activity
Fig 2. Batch command-buffers/command-lists trace
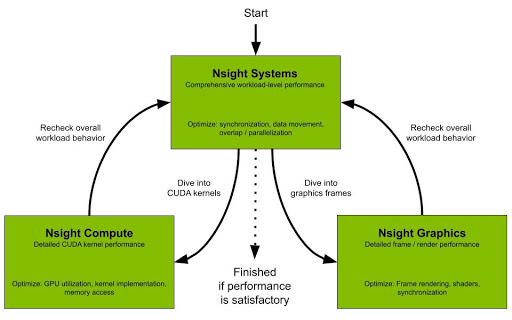
Nsight Systems is part of a larger family of Nsight tools. A developer can start with Nsight Systems to see the big picture and avoid picking less efficient optimizations based on assumptions and false-positive indicators.
NVIDIA has made Deep Learning Super Sampling (DLSS) easier and more flexible than ever for developers to access and integrate in their games. The latest DLSS SDK update (version 2.2.1) enables new user customizable options, delivers Linux support and streamlines access.
Today, NVIDIA has made Deep Learning Super Sampling (DLSS) easier and more flexible than ever for developers to access and integrate in their games. The latest DLSS SDK update (version 2.2.1) enables new user customizable options, delivers Linux support and streamlines access.
NVIDIA DLSS technology has already been adopted and implemented in over 60 games, including the biggest gaming franchises such as Cyberpunk, Call of Duty, DOOM, Fortnite, LEGO, Minecraft,Rainbow Six, and Red Dead Redemption, with support coming soon for Battlefield 2042. DLSS uses the power of RTX Tensor Cores to boost game frame rates through an advanced deep learning temporal super resolution algorithm.
New User & Developer Customizable Options
This DLSS update offers new options to developers during the integration process. A new sharpening slider allows users to make an image sharper or softer based on their own personal preferences. DLSS Auto Mode enables optimal image quality for a particular resolution. For resolutions at or under 1440P, DLSS Auto is set to Quality, 4K set to Performance, and 8K set to Ultra Performance. Lastly, an auto-exposure option offers an automatic way to calculate exposure values for developers. This option can potentially improve the image quality of low-contrast scenes.
Linux Support Available Now
Last month, NVIDIA added DLSS support for Vulkan API games on Proton, enabling Linux gamers to boost frame rates on Proton-supported titles such as DOOM Eternal, No Man’s Sky, and Wolfenstein: Youngblood. Today, the NVIDIA DLSS SDK is adding support for games running natively on Linux with x86. We are also announcing DLSS support for ARM-based platforms.
Easier Access for Developers
Accessing the DLSS SDK is now easier than ever — no application required! Simply download the DLSS SDK 2.2.1 directly from the NVIDIA Developer website, access the Unreal Engine 5 and 4.26 plugin from the marketplace, or utilize DLSS natively in Unity 2021.2 beta.
Make sure to tune into the NVIDIA DLSS virtual session at Game Developers Conference (GDC) July 19 – 23 to learn about best practices on integrating DLSS into your game. And check out the latest DLSS game releases here.
Nsight developer tools is a suite of powerful tools and SDKs for profiling, debugging and optimizing applications focused on improving performance for graphics, gaming and other use cases. Identifying bottlenecks, highlighting code (multi-threading operations, event timing ) to improve efficiency and the unique features offerings for refined user experience.
Nsight developer tools is a suite of powerful tools and SDKs for profiling, debugging and optimizing applications focused on improving performance for graphics, gaming and other use cases. Identifying bottlenecks, highlighting code (multi-threading operations, event timing ) to improve efficiency and the unique features offerings for refined user experience.
Nsight Perf SDK 2021.1.2
The NVIDIA® Nsight Perf SDK is a graphics profiling toolbox for DirectX, Vulkan, and OpenGL, enabling you to collect GPU performance metrics directly from your application.
As the first public release of the SDK, the new features include:
HTML Report Generator in an easy-to-use utility library layer. Gather in-depth GPU profiling reports with only minutes of effort, in under 10 lines of code.
Open source sample code, ready for you to copy & paste into your program, or to post as the #1 solution on Stack Overflow!
Ability to measure whole frames, groupings of GPU workloads, and individual draws and dispatches.
Low-level range profiler APIs, for writing custom tools and automation.
Comment in forums to discuss more on applications of this SDK.
Nsight Aftermath SDK 2021.1
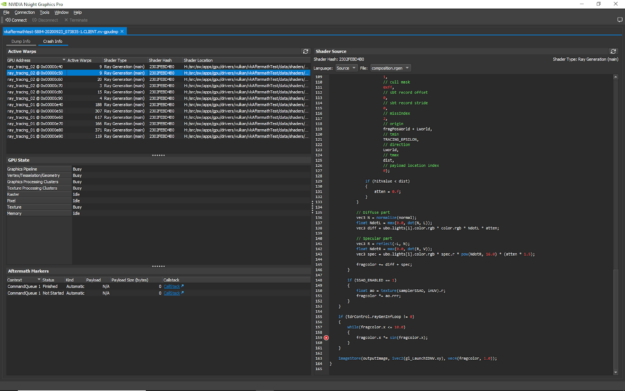
Nsight Aftermath SDK provides valuable data for debugging GPU exceptions. Applications using the latest graphics APIs like Direct3D 12 and Vulkan, along with cutting edge capabilities like Ray Tracing, can push the GPU more than ever. These new powers and exposure to the metal require diligence and tools to ensure the GPU is set up correctly. When there is a problem, Nsight Aftermath is there to provide deep GPU state information and breadcrumbs to what leads to the exception. This latest version has enhanced the UI and data display, as well as provided many driver improvements to increase the reliability of the generated dump information.
Fig 2: Shows an example GPU crash dump, correlating the exception to the offending line of HLSL source code.
Visit Nsight Aftermath SDK to get more information on the tool. Post a comment or question on our developer forums to learn more about the tool.
NVIDIA Nsight Graphics 2021.3
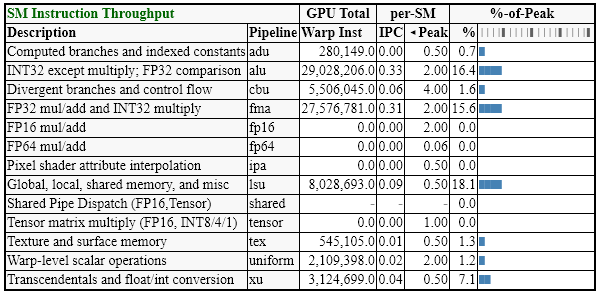
NVIDIA® Nsight Graphics is a standalone developer tool that enables you to debug, profile, and export frames built with high fidelity 3D graphics applications. It supports Direct3D (11, 12, DXR), Vulkan (1.2, NV Vulkan Ray Tracing Extension), OpenGL, OpenVR, and the Oculus SDK.
This latest Nsight Graphics extends support for multiple APIs with the following updates:
Windows 21H1 and DirectX Agility SDK Support
GPU Trace Vulkan/OpenGL Interop Support
GPU Trace OptiX Support
GPU Trace Multi-Window Application Support
Nsight Graphics Sample Applications
Nsight Systems Direct Launch
Details on the features are available in our developer news article.
Fig 3: Sample GPU Trace report from an example Ray Tracing application.
Learn more about the upcoming releases by visiting our developer page.
For questions and comments and to stay up-to-date regarding upcoming releases, visit our developer forums.
Nsight Systems 2021.3
NVIDIA Nsight Systems is a system-wide performance analysis tool, designed to help developers tune and scale software across CPUs and GPUs.
The latest release introduces several improvements aimed to assist the user with locating issues and improve the profiling experience with the following updates and enhancements:
Expert system view to help identify problem patterns
Ability to correlate and load multiple reports for analysis
Windows 21H1 SDK support
Low overhead GPU workload batch trace for Vulkan and Direct3D12
GPU Metrics sampling GPU PCIe BAR1 metrics support
For more details on features, see Nsight System developer news article.
I have a model where I input an image and two labels which are floats. There are 2 outputs, both having linear activation functions. I am using mae loss function if that matters.
When I try to predict images with this model, it gives me absurdly large numbers that like nothing the model was trained on.
Does anyone know why this happens and/or how to fix it?

 Discover how NVIDIA CloudXR with Teradici’s PCoIP protocol enables XR users to experience seamless streaming. CloudXR uses Teradici’s ability to support high-fidelity video and use of flexible integration options for enterprise IT systems.
Discover how NVIDIA CloudXR with Teradici’s PCoIP protocol enables XR users to experience seamless streaming. CloudXR uses Teradici’s ability to support high-fidelity video and use of flexible integration options for enterprise IT systems. RTXMU (RTX Memory Utility) combines both compaction and suballocation techniques to optimize and reduce memory consumption of acceleration structures for any DXR or Vulkan Ray Tracing application.
RTXMU (RTX Memory Utility) combines both compaction and suballocation techniques to optimize and reduce memory consumption of acceleration structures for any DXR or Vulkan Ray Tracing application. 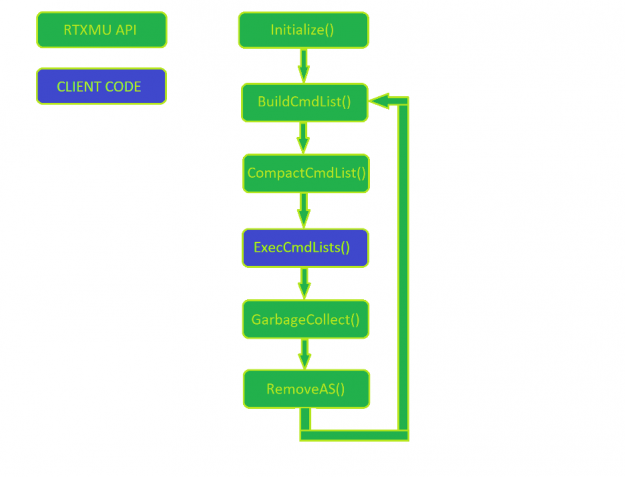



 Real-time ray tracing has advanced the art of lighting in video games, but it’s a computationally expensive process. Aiming to reduce these costs, NVIDIA has developed a memory utility that combines both compaction and suballocation techniques to optimize and reduce memory consumption of acceleration structures.
Real-time ray tracing has advanced the art of lighting in video games, but it’s a computationally expensive process. Aiming to reduce these costs, NVIDIA has developed a memory utility that combines both compaction and suballocation techniques to optimize and reduce memory consumption of acceleration structures. Nsight Graphics 2021.3 is an all-in-one graphics debugger and profiler to help game developers get the most out of NVIDIA hardware.
Nsight Graphics 2021.3 is an all-in-one graphics debugger and profiler to help game developers get the most out of NVIDIA hardware.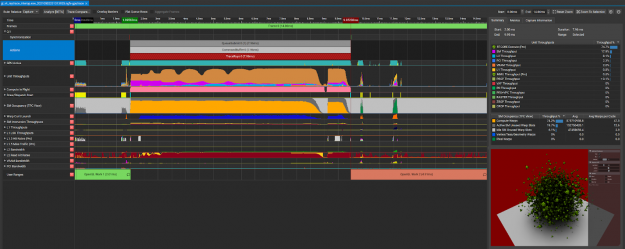
 support for GPU Trace, including Vulkan applications that trace rays in the compute shader and use OptiX
support for GPU Trace, including Vulkan applications that trace rays in the compute shader and use OptiX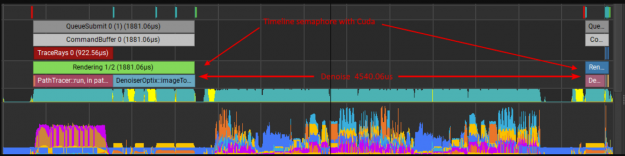
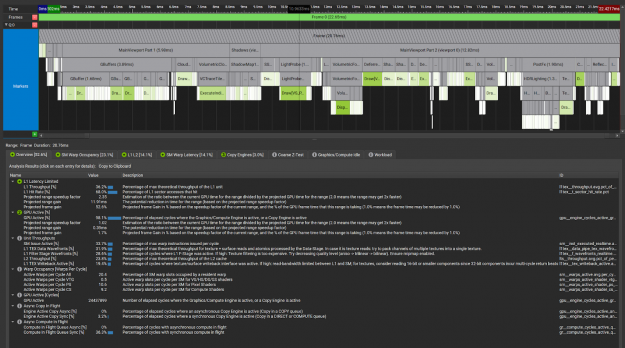
 Nsight Systems is a system-wide performance analysis tool, designed to help developers tune and scale software across CPUs and GPUs.
Nsight Systems is a system-wide performance analysis tool, designed to help developers tune and scale software across CPUs and GPUs. 
 NVIDIA has made Deep Learning Super Sampling (DLSS) easier and more flexible than ever for developers to access and integrate in their games. The latest DLSS SDK update (version 2.2.1) enables new user customizable options, delivers Linux support and streamlines access.
NVIDIA has made Deep Learning Super Sampling (DLSS) easier and more flexible than ever for developers to access and integrate in their games. The latest DLSS SDK update (version 2.2.1) enables new user customizable options, delivers Linux support and streamlines access. Nsight developer tools is a suite of powerful tools and SDKs for profiling, debugging and optimizing applications focused on improving performance for graphics, gaming and other use cases. Identifying bottlenecks, highlighting code (multi-threading operations, event timing ) to improve efficiency and the unique features offerings for refined user experience.
Nsight developer tools is a suite of powerful tools and SDKs for profiling, debugging and optimizing applications focused on improving performance for graphics, gaming and other use cases. Identifying bottlenecks, highlighting code (multi-threading operations, event timing ) to improve efficiency and the unique features offerings for refined user experience.