Posted by Tom Denton, Software Engineer and Scott Wisdom, Research Scientist, Google Research
Birds are all around us, and just by listening, we can learn many things about our environment. Ecologists use birds to understand food systems and forest health — for example, if there are more woodpeckers in a forest, that means there’s a lot of dead wood. Because birds communicate and mark territory with songs and calls, it’s most efficient to identify them by ear. In fact, experts may identify up to 10x as many birds by ear as by sight.
In recent years, autonomous recording units (ARUs) have made it easy to capture thousands of hours of audio in forests that could be used to better understand ecosystems and identify critical habitat. However, manually reviewing the audio data is very time consuming, and experts in birdsong are rare. But an approach based on machine learning (ML) has the potential to greatly reduce the amount of expert review needed for understanding a habitat.
However, ML-based audio classification of bird species can be challenging for several reasons. For one, birds often sing over one another, especially during the “dawn chorus” when many birds are most active. Also, there aren’t clear recordings of individual birds to learn from — almost all of the available training data is recorded in noisy outdoor conditions, where other sounds from the wind, insects, and other environmental sources are often present. As a result, existing birdsong classification models struggle to identify quiet, distant and overlapping vocalizations. Additionally, some of the most common species often appear unlabeled in the background of training recordings for less common species, leading models to discount the common species. These difficult cases are very important for ecologists who want to identify endangered or invasive species using automated systems.
To address the general challenge of training ML models to automatically separate audio recordings without access to examples of isolated sounds, we recently proposed a new unsupervised method called mixture invariant training (MixIT) in our paper, “Unsupervised Sound Separation Using Mixture Invariant Training”. Moreover, in our new paper, “Improving Bird Classification with Unsupervised Sound Separation,” we use MixIT training to separate birdsong and improve species classification. We found that including the separated audio in the classification improves precision and classification quality on three independent soundscape datasets. We are also happy to announce the open-source release of the birdsong separation models on GitHub.
Birdsong Audio Separation
MixIT learns to separate single-channel recordings into multiple individual tracks, and can be trained entirely with noisy, real-world recordings. To train the separation model, we create a “mixture of mixtures” (MoM) by mixing together two real-world recordings. The separation model then learns to take the MoM apart into many channels to minimize a loss function that uses the two original real-world recordings as ground-truth references. The loss function uses these references to group the separated channels such that they can be mixed back together to recreate the two original real-world recordings. Since there’s no way to know how the different sounds in the MoM were grouped together in the original recordings, the separation model has no choice but to separate the individual sounds themselves, and thus learns to place each singing bird in a different output audio channel, also separate from wind and other background noise.
We trained a new MixIT separation model using birdsong recordings from Xeno-Canto and the Macaulay Library. We found that for separating birdsong, this new model outperformed a MixIT separation model trained on a large amount of general audio from the AudioSet dataset. We measure the quality of the separation by mixing two recordings together, applying separation, and then remixing the separated audio channels such that they reconstruct the original two recordings. We measure the signal-to-noise ratio (SNR) of the remixed audio relative to the original recordings. We found that the model trained specifically for birds achieved 6.1 decibels (dB) better SNR than the model trained on AudioSet (10.5 dB vs 4.4 dB). Subjectively, we also found many examples where the system worked incredibly well, separating very difficult to distinguish calls in real-world data.
The following videos demonstrate separation of birdsong from two different regions (Caples and the High Sierras). The videos show the mel-spectrogram of the mixed audio (a 2D image that shows the frequency content of the audio over time) and highlight the audio separated into different tracks.
Classifying Bird Species
To classify birds in real-world audio captured with ARUs, we first split the audio into five-second segments and then create a mel-spectrogram of each segment. We then train an EfficientNet classifier to identify bird species from the mel-spectrogram images, training on audio from Xeno-Canto and the Macaulay Library. We trained two separate classifiers, one for species in the Sierra Nevada mountains and one for upstate New York. Note that these classifiers are not trained on separated audio; that’s an area for future improvement.
We also introduced some new techniques to improve classifier training. Taxonomic training asks the classifier to provide labels for each level of the species taxonomy (genus, family, and order), which allows the model to learn groupings of species before learning the sometimes-subtle differences between similar species. Taxonomic training also allows the model to benefit from expert information about the taxonomic relationships between different species. We also found that random low-pass filtering was helpful for simulating distant sounds during training: As an audio source gets further away, the high-frequency parts fade away before the low-frequency parts. This was particularly effective for identifying species from the High Sierras region, where birdsongs cover very long distances, unimpeded by trees.
Classifying Separated Audio
We found that separating audio with the new MixIT model before classification improved the classifier performance on three independent real-world datasets. The separation was particularly successful for identification of quiet and background birds, and in many cases helped with overlapping vocalizations as well.
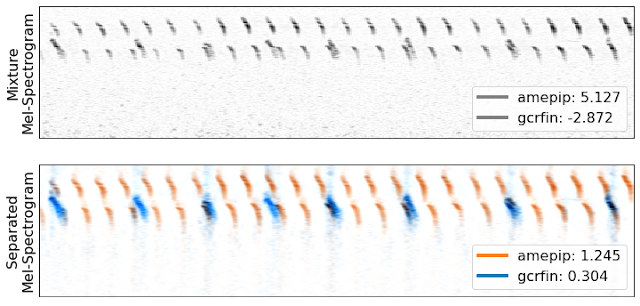 |
| Top: A mel-spectrogram of two birds, an American pipit (amepip) and gray-crowned rosy finch (gcrfin), from the Sierra Nevadas. The legend shows the log-probabilities for the two species given by the pre-trained classifiers. Higher values indicate more confidence, and values greater than -1.0 are usually correct classifications. Bottom: A mel-spectrogram for the automatically separated audio, with the classifier log probabilities from the separated channels. Note that the classifier only identifies the gcrfin once the audio is separated. |
 |
| Top: A complex mixture with three vocalizations: A golden-crowned kinglet (gockin), mountain chickadee (mouchi), and Steller’s jay (stejay). Bottom: Separation into three channels, with classifier log probabilities for the three species. We see good visual separation of the Steller’s jay (shown by the distinct pink marks), even though the classifier isn’t sure what it is. |
The separation model does have some potential limitations. Occasionally we observe over-separation, where a single song is broken into multiple channels, which can cause misclassifications. We also notice that when multiple birds are vocalizing, the most prominent song often gets a lower score after separation. This may be due to loss of environmental context or other artifacts introduced by separation that do not appear during classifier training. For now, we get the best results by running the classifier on the separated channels and the original audio, and taking the maximum score for each species. We expect that further work will allow us to reduce over-separation and find better ways to combine separation and classification. You can see and hear more examples of the full system at our GitHub repo.
Future Directions
We are currently working with partners at the California Academy of Sciences to understand how habitat and species mix changes after prescribed fires and wildfires, applying these models to ARU audio collected over many years.
We also foresee many potential applications for the unsupervised separation models in ecology, beyond just birds. For example, the separated audio can be used to create better acoustic indices, which could measure ecosystem health by tracking the total activity of birds, insects, and amphibians without identifying particular species. Similar methods could also be adapted for use underwater to track coral reef health.
Acknowledgements
We would like to thank Mary Clapp, Jack Dumbacher, and Durrell Kapan from the California Academy of Sciences for providing extensive annotated soundscapes from the Sierra Nevadas. Stefan Kahl and Holger Klinck from the Cornell Lab of Ornithology provided soundscapes from Sapsucker Woods. Training data for both the separation and classification models came from Xeno-Canto and the Macaulay Library. Finally, we would like to thank Julie Cattiau, Lauren Harrell, Matt Harvey, and our co-author, John Hershey, from the Google Bioacoustics and Sound Separation teams.