Modern conversational agents need to integrate with an ever-increasing number of services to perform a wide variety of tasks, from booking flights and finding restaurants, to playing music and telling jokes. Adding this functionality can be difficult — for each new task, one needs to collect new data and retrain the models that power the conversational agent. This is because most task-oriented dialogue (TOD) models are trained on a single task-specific ontology. An ontology is generally represented as a list of possible user intents (e.g., if the user wants to book a flight, if the user wants to play some music, etc.) and possible parameter slots to extract from the conversation (e.g., the date of the flight, the name of a song, and so on). A rigid ontology can be limiting, preventing the model from generalizing to new tasks or domains. For instance, a TOD model trained on a certain ontology only knows the intents in that ontology, and lacks the ability to generalize its knowledge to unseen intents. This is true even for new ontologies that overlap with ones already known to the agent — for example, if an agent already knows how to book train tickets, adding the ability to book airline tickets would require training on completely new data. Ideally, the agent should be able to leverage its existing knowledge from one ontology, and apply it to new ones.
New benchmarks, such as the the Schema Guided Dialogue (SGD) dataset, have been designed to evaluate the ability to generalize to unseen tasks, by distilling each ontology into a schema of slots and intents. In the SGD setting, TOD models are trained on multiple schemas, and evaluated on how well they generalize to unseen ones — instead of how well they overfit to a single ontology. However, recent work shows the top models still have room for improvement.
To address this problem, we introduce two different sequence-to-sequence approaches toward zero-shot transfer for dialogue modeling, presented in the papers “Description-Driven Task-Oriented Dialogue” and “Show, Don’t Tell: Demonstrations Outperform Descriptions for Schema-Guided Task-Oriented Dialogue”. Both models condition on additional contextual information, either slot and intent descriptions, or single demonstrative examples. Results obtained on multiple dialogue state tracking benchmarks show that by doing away with the fixed schemas and ontologies, these new approaches lead to state-of-the-art results on the dialogue state tracking task with more efficient models. The source code for the described approaches can be found here.
Background: Dialogue State Tracking
To address the challenge of zero-shot transfer for dialogue models, we focus on the problem of Dialogue State Tracking (DST). DST is a fundamental problem for conversational agents, in which a model predicts the belief state of a conversation, i.e., the agent’s understanding of the user’s indicated preferences. The belief state is typically modeled as an assignment of values to slots for which the user has indicated a preference in the conversation. An example is shown below.
 |
| An example conversation and its ground truth slots and intents for dialogue state tracking. Here, the active user intent is “Book a train”, and pertinent information for booking this train is recorded in the slot values. |
Description-Driven Task-Oriented Dialogue
In our first paper, we introduce Description-Driven Dialogue State Tracking (D3ST), a DST model that leverages slot and intent descriptions when making predictions about the belief state. D3ST is built on top of the T5 sequence-to-sequence language model, which was shown in previous work to be pretrained effectively for DST problems.
D3ST prompts the input sequence with slot and intent descriptions, allowing the T5 model to attend to both this contextual information and the conversation. Its ability to generalize comes from the formulation of these descriptions. Instead of using a name for each slot, we assign a random index for every slot. For categorical slots (i.e., slots that only take values from a small, predefined set), possible values are also arbitrarily enumerated and then listed. The same is done with intents, and together these descriptions form the schema representation to be included in the input string. This is concatenated with the conversation text and fed into the T5 model. The target output is the belief state and user intent, again identified by their assigned indices. An example is shown below.
 |
| An example of the D3ST input and output format. The red text contains slot descriptions, while the blue text contains intent descriptions. The yellow text contains the conversation utterances. |
This forces the model to predict conversation contexts using a slot’s index, and not that specific slot. By randomizing the index we assign to each slot between different examples, we prevent the model from learning specific schema information. The slot with index 0 could be the “Train Departure” slot in one example, and the “Train Destination” in another — as such, the model is encouraged to use the slot description given in index 0 to find the correct value, and discouraged from overfitting to a specific schema. With this setup, a model that sees enough different tasks or domains will learn to generalize the action of belief state tracking and intent prediction.
Show Don’t Tell
In our subsequent paper, “Show, Don’t Tell: Demonstrations Outperform Descriptions for Schema-Guided Task-Oriented Dialogue”, we employ a single annotated dialogue example that demonstrates the possible slots and values in a conversation, instead of relying on slot descriptions. In this sense, we “show” the semantics of the schema rather than “tell” the model through descriptions — hence the name “Show Don’t Tell” (SDT). SDT is also built on T5, and improves zero-shot performance beyond D3ST.
 |
| n example of the SDT input and output format. The text in red contains the demonstrative example, while the text in blue contains its ground truth belief state. The actual conversation for the model to predict is in yellow. While the D3ST prompt relies entirely on slot descriptions, the SDT prompt contains a concise example dialogue followed by the expected dialogue state annotations, resulting in more direct supervision. |
The rationale for SDT’s single example demonstration is simple: there can still be ambiguities that are not fully captured in a slot or intent description, and require a concrete example to demonstrate. Moreover, from a developer’s standpoint, creating short dialogue examples to describe a schema can often be easier than writing descriptions that fully capture the meaning behind each slot and intent.
Benchmark Results
We evaluate both D3ST and SDT on a number of benchmarks, most notably the SGD dataset, which tests zero-shot generalization to unseen schemas in its test set. We evaluate our state tracking models on joint goal accuracy (JGA), the fraction of dialogue turns for which the model predicts an exactly correct belief state.
Both of our models either match or outperform existing state-of-the-art baselines (T5DST and paDST) at comparable model sizes, as shown below. In general, SDT performs slightly better than D3ST. Note that our models can be trained on different sizes of the underlying T5 language model. In addition, while the baseline models can only make predictions for one slot per forward pass, both our models can decode the entire dialogue state in a single forward pass — a much more efficient method in both training and inference.
 |
| Joint Goal Accuracy on the SGD dataset plotted against model size for existing baselines and our proposed models D3ST and SDT. Note that paDST* includes additional data augmentation. |
Additional metrics are reported in both papers. D3ST exhibits state-of-the-art quality on the MultiWOZ dataset, with 75.9% JGA on MultiWOZ 2.4. Both D3ST and SDT show state-of-the-art performance in the MultiWOZ cross-domain leave-one-out setting. In addition, both D3ST and SDT were evaluated using the SGD-X dataset, and demonstrated strong robustness to linguistic variations in schema. These benchmarks all indicate that D3ST and SDT are state-of-the-art TOD models, with the ability to generalize to unseen tasks and domains.
Zero-Shot Capability
D3ST and SDT sometimes demonstrate a surprising ability to generalize to unseen tasks, and we saw many interesting examples when trying completely new dialogues with the model. We’ve included one such example below:
 |
| A D3ST model trained on the SGD dataset makes predictions (right) for an unseen meta conversation (left) about creating this blog post. The model predicts a completely correct belief state, even though it is not fine-tuned on anything related to blogs, authors or NLP. |
Future Work
These papers demonstrate the feasibility of a zero-shot TOD system that can generalize to unseen tasks or domains. However, we’ve limited ourselves to the DST problem for now — we plan to extend this research to enable zero-shot dialogue policy modeling, allowing TOD systems to take actions following arbitrary instructions. In addition, the current input format can often lead to long input sequences, which can be slow for inference — we’re exploring new and more efficient methods to encode schema information.
Acknowledgements
This post reflects the combined work of Jeffrey Zhao, Raghav Gupta, Harrison Lee, Mingqiu Wang, Dian Yu, Yuan Cao, and Abhinav Rastogi. We’d like to thank Yonghui Wu and Izhak Shafran for their continued advice and guidance.








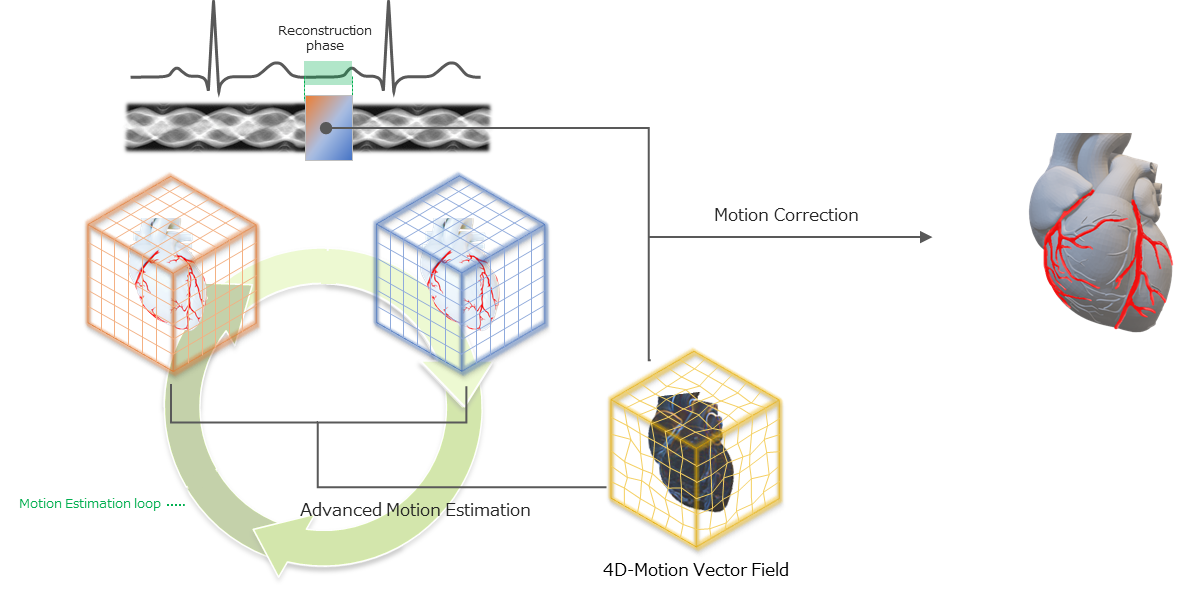
 Using NVIDIA GPUs, Fujifilm Healthcare developed Cardio StillShot to capture cardiac imaging at any heart rate, with 6x better temporal resolution of cardiac CT images.
Using NVIDIA GPUs, Fujifilm Healthcare developed Cardio StillShot to capture cardiac imaging at any heart rate, with 6x better temporal resolution of cardiac CT images.