
 The end of 2021 and beginning of 2022 saw the two largest commercial CFD tool vendors, Ansys and Siemens, both launch versions of their flagship CFD tools with support for GPU acceleration.
The end of 2021 and beginning of 2022 saw the two largest commercial CFD tool vendors, Ansys and Siemens, both launch versions of their flagship CFD tools with support for GPU acceleration.
When a technology reaches the required level of maturity, adoption transitions from those considered visionaries to early majority adopters. Now is such a critical and transitional moment for the largest single segment of industrial high-performance computing (HPC).
The end of 2021 and beginning of 2022 saw the two largest commercial computational fluid dynamics (CFD) tool vendors, Ansys and Siemens, both launch versions of their flagship CFD tools with support for GPU acceleration. This fact alone is enough proof to show the new age of CFD has arrived.
Evolution of engineering applications for CFD
The past decade saw a wider adoption of CFD as a critical tool for engineers and equipment designers to study or predict the behavior of their designs. However CFD isn’t only an analysis tool, it is now used to make design improvements without having to resort to time-consuming and expensive physical testing for every design/operation point that is being evaluated. This ubiquity is part of why there are so many CFD tools, commercial, and open-source software available today.
The growing need for accuracy in simulations to help minimize testing led to the incorporation of multi-physics capabilities into CFD tools, such as the inclusion of heat transfer, mass transfer, chemical reactions, particulate flows, and more. The other reason for the growth of CFD tools is the fact that capturing all the relevant physics for every type of use case within a single tool is time-consuming to build and validate.
For instance, in the use case of vehicle aerodynamics, a digital wind tunnel can be used to study and evaluate the flow over the geometry and to evaluate the drag produced by the designed surface which has direct implications on vehicle performance. Depending on the intended purpose of the simulation, users get to pick if they want to run a steady or a transient simulation using the traditional Navier-Stokes formulation for fluid flow or use alternative frameworks like the lattice Boltzmann method.
Even within the realm of Navier-Stokes solutions, one has a variety of turbulence models and methodologies, such as what scales are resolved and what are modeled, to choose from for the simulations. The complexity in the model quickly grows when additional physics are considered when making design choices, such as studying automotive aeroacoustics which has an influence on customer perception, passenger safety and comfort, or studying road vehicle platooning.
All the tools used for modeling different flow situations take a staggering amount of compute processing power. As organizations are starting to incorporate CFD earlier on in their design cycles, while simultaneously growing the complexity of their models, both in terms of model size and representative physics, to increase the fidelity of the simulations – the industry has reached a tipping point.
Parallelism equates with performance
It is no longer uncommon for a single simulation to require thousands of CPU core hours to provide a result, and a single design product can require 10,000 to 1,000,000 simulations or more.
Just recently, an NVIDIA partner, Resolved Analytics, published a survey on CFD users and tools. One of the statistics shown is the commonly-used levels of parallelism by CFD users today. In CFD, parallel execution refers to dividing the domain or grid into sub-grids and assigning a processing unit to each sub-grid. At each numerical iteration, the sub-grids communicate boundary information with the adjacent sub-grids and the CFD solution advances toward convergence.
The survey finishes with the conclusion that hardware and software costs continue to limit the parallelization of CFD.
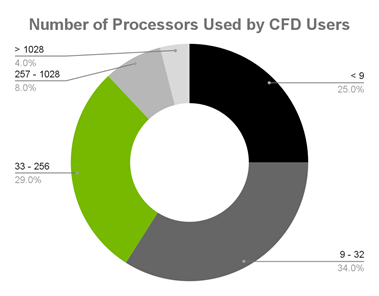
Resolved Analytics surveyed CFD users and found that the overwhelming majority are using fewer than 257 processors, impacting parallel programming capacity:
- 25% of CFD users use less than nine processors.
- 34% use 9-32 processors.
- 29% use 33-256 processors.
- 8% use 257-1,028 processors.
- 4% use more than 1,028 processors.
Another way to think about this is that parallelism equates to performance and runtime equates to minimization. Meaning, you could push performance farther than you do today if you were not limited by hardware and software licenses.
Getting to higher levels of performance is the right thing to do, because it optimizes the most expensive resource: engineer and researcher time. Often skilled personnel time can be 5–10x the cost of the next most expensive resource, which is software licenses or computing hardware. Logic dictates allocating funding to remove bottlenecks caused by these lower-cost resources.
Another NVIDIA partner, Rescale, stated this perspective in a similar way:
Most HPC economic models ignore engineering time or engineering productivity, and it is the most valuable and expensive resource that needs to be optimized first. Assuring that hardware and software assets keep researchers generating IP at a maximum rate is the most rational way to treat the core value generators of an organization.
NVIDIA is pleased to share with the CFD user community that the hardware limitation is lifting. Recently, the two most popular CFD tools—Simcenter STAR-CCM+ from Siemens Digital Industries Software and Ansys Fluent—have made available software versions to help support specific physics. Those physics simulations can take significant advantage of the extreme speed of accelerated GPU computing.
At the time of this post, the Simcenter STAR-CCM+ 2022.1 GPU-accelerated version is generally available, currently supporting vehicle external aerodynamics applications for steady and unsteady simulations. The Ansys Fluent release is currently in public beta.
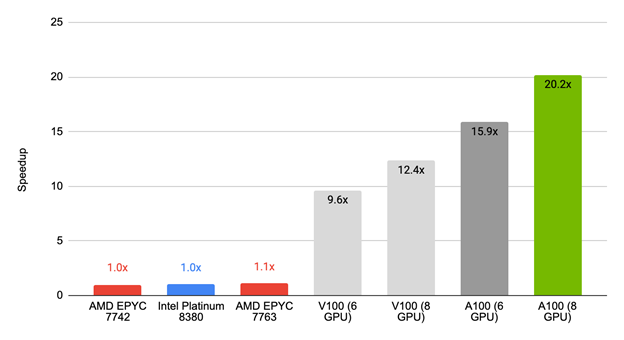
Figure 2 shows the performance of the first release of Simcenter STAR-CCM+ 2022.1 against commonly available CPU-only servers. For the tested benchmark, an NVIDIA GPU-equipped server delivers results almost 20x faster than over 100 cores of CPU.
The AMD EPYC 7763 achieved 10% speedup of 1.1x, compared to the NVIDIA V100 (six GPUs) with a 9.6x speedup, NVIDIA V100 (eight GPUs) with a 12.4x speedup, NVIDIA A100 (six GPUs) with a 15.9x speedup, and NVIDIA A100 (eight GPUs) with a 20.2x speedup.
To put that into more practical terms, this means a simulation that takes a full day on a CPU server could be done in a little over an hour with a single node and eight NVIDIA A100 GPUs.
With the Simcenter STAR-CCM+ team continuing to work on improving and optimizing their GPU offering, you can expect even better performance in upcoming releases.

Corvette C6 ZR1 external aerodynamics, pseudo-steady simulation, 110M cells run with SST-DDES and Moving Reference Frame (MRF) for the wheels. GPU runs on 4xA100 DGX station.
GPU-accelerated runs are delivering consistent results compared to CPU-only runs, and Siemens delivered a product that can be seamlessly moved from CPUs to GPUs to get the results faster and effortlessly. The result is that you can now run simulations on-premises or on the cloud, as A100 GPU instances are available from all the major cloud service providers.
Siemens showed similar results in their announcement of GPU support in version 2022.1 when comparing CPU-only servers on-premises and in the cloud for both previous-generation V100 GPUs and current generation A100 GPUs. They also showed the performance of a large, industrial-scale model and the equivalent number of CPU cores required to get similar run times as that of a single node with eight GPUs on it.
Never to be left behind on technology trends, NVIDIA and Ansys announced the public beta availability of a GPU-accelerated, limited-functionality Fluent at the 2021 GTC Fall keynote.
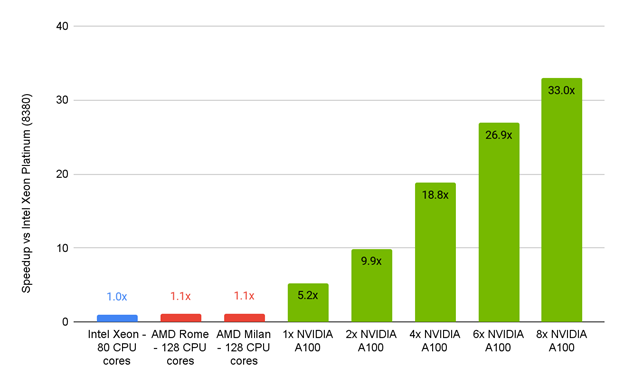
This comparison is based on a 100-iteration timing, steady-state, GEKO turbulence model.
The performance of the Ansys Fluent 2022 beta1 server compared to CPU-only servers shows that Intel Xeon, AMD Rome, and AMD Milan had ~1.1x speedups compared to the NVIDIA A100 PCIe 80GB, which had speedups from 5.2x (one GPU) to an impressive 33x (eight GPUs).
The Ansys Fluent numbers drove some major excitement. They showed that a single GPU accelerated server for their selected benchmark and associated physics could deliver nearly 33x the performance of the standard Intel processor-only servers common today.
Such fast turnaround times are due to GPU acceleration of the two most used commercial CFD applications. This means that design engineers can not only incorporate simulations earlier into their design cycles but also explore several design iterations within a single day. They can make informed decisions about product performance quickly instead of having to wait for weeks.
Other options for GPU acceleration
At such speeds, other bottlenecks in the product research process can emerge. Sometimes a major consumer of engineering time is preprocessing, or the manual process of building the models to be run.
It is especially important to address this problem because it takes engineering person-time to solve. This is different from other factors, like simulation run time, that leave the researcher free to concentrate on other tasks. This is an active area of focus recently highlighted in CFD Mesh Generators: Top 3 Reasons They Slow Analysis and How to Fix Them.
All that said though, GPU acceleration is not an entirely new phenomenon. Some of the more niche tools have either been born in a GPU-accelerated world or have come to it sooner rather than later:
- Altair CFD (NanoFluidX and UltraFluidX)
- Cascade Technologies, CharLES
- ESS Rocky
- CPFD Barracuda
- Dassault, XFlow
- M-STAR CFD
- NASA, FUN3D
NVIDIA has featured exciting and visually stunning results from NASA’s FUN3D tool, including the time Jensen Huang shared a simulation of a Mars lander entering the atmosphere.
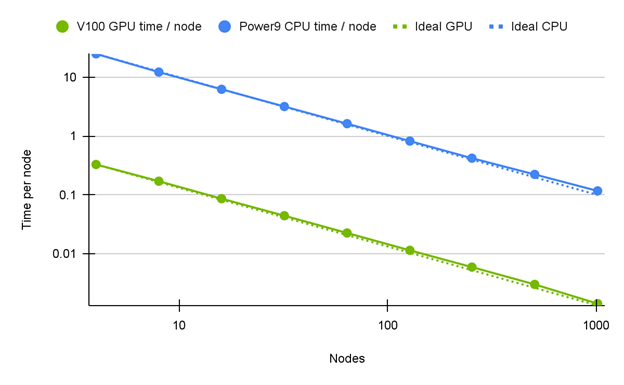
Hardware access provided by ORNL Summit using IBM AC922 Dual Power9 CPUs with 6x NVIDIA V100 SXM2 16 GB 2x EDR InfiniBand.
The most recent Supercomputing Conference featured research by a team that studied algorithmic changes which produce reductions in floating-point atomic updates required by large-scale parallel GPU computing environments. The runtime of several kernels is dominated by the update speeds, and therefore efficiencies found in this area have the potential for large benefits. Also, though FUN3D is a NASA and United States government-only tool, the discussion in this paper has applicability to other unstructured Reynolds-averaged Navier-Stokes CFD tools.
Beyond savings and removing roadblocks, maybe the most exciting part of mainstream CFD tools becoming GPU-accelerated is the new science and engineering that cut runtimes by factors of 15–30x. Until now, without access to leadership-class supercomputing capabilities, investigations into these areas have been too difficult from both a runtime and a problem-size standpoint:
- Vehicle underhood modeling: Turbulent flow with heat transfer
- Large eddy and combustion: Needed for detailed environmental emissions modeling
- Magneto-hydrodynamics: Flows influenced by magnetic fields important to modeling fusion energy generators, internals of stars and gas giant planets
- Machine learning training: Automatic generation of models and solutions that are used to train machine learning algorithms to estimate flow initial conditions, model turbulence, mixing, and so on
For more information about accelerated computing being used for other fluids or industrial simulations, watch the recommended recent GTC 2022 sessions focused on manufacturing and HPC: