Hey, does anyone have a step by step guide to create an android application, which uses tensorflow, and can detect traffic signs and vehicles ?
I have no experience using tensorflow, but have to make an android app that detects people, traffic signs,and vehicles. A step by step tutorial would be really appreciated, please help
This post covers best practices for variable rate shading on NVIDIA GPUs.
This post covers best practices for variable rate shading on NVIDIA GPUs. To get a high and consistent frame rate in your applications, see all Advanced API Performance tips.
Variable rate shading (VRS) is a graphics feature allowing applications to control the frequency of pixel shader invocations independent of the resolution of the render target. It is available in both D3D12 and Vulkan.
Defining the VRS rate
Depending on your API of choice, you may have up to three options for defining the VRS rate:
A per-draw call rate
A per-primitive rate
A lookup from a screen-space shading rate image that can define different rates in different regions of the screen
Per-draw call
This option is the simplest to implement, and only requires a few extra API calls in the command stream with no additional dependencies. It is the coarsest granularity, so think of it as the “broadest brush”
Per-primitive
This option requires augmenting geometric assets, and thus will likely need changes in how the assets are generated in the art pipeline or loaded and prepared by the application. Use the knowledge of what you are drawing to finely tailor the shading rate to your needs.
Screen-space lookup
This option requires rendering pipeline changes, but generally no asset or art changes.
The most difficult/interesting question is how to generate the shading rate image:
NVIDIA Adaptive Shading (NAS), for example, uses motion vector data plus color variance data to determine what parts of the image need less detail.
To be useful, the performance cost of the algorithm to generate the shading rate image must be less than the performance savings of VRS.
Try to use inexpensive algorithms on data that your rendering engine already generates (for example, motion vectors or previous frame results).
Recommended
Continue using existing techniques for graphics optimization. VRS does not fundamentally change much about the usage of the graphics pipeline. Existing advice about graphics rendering continues to apply. The main difference in operation under VRS is that the relative amount of Pixel Shader workloads may be smaller than when rendering normally.
Look to cross-apply techniques and considerations from working with multisample anti-aliasing (MSAA). VRS operates on similar principles to MSAA, and as such, it has limited utility in deferred renderers. VRS cannot help with improving the performance of compute passes.
Not recommended
Avoid 4×4 mode in cases where warp occupancy is the limiting factor.
Generally speaking, pixel shading workloads scale linearly with the variable shading mode. For example, 1×2/2×1 mode has ½ as many PS invocations, 2×2 mode has ¼ as many, and so on.
The one exception is 4×4 mode, which would ideally have 1/16 pixel shader invocations. However, in 4×4 mode, the rasterizer cannot span the whole pixel range needed to generate a full 32 thread warp all at once. As a result, warps in 4×4 mode are only half active (16 threads instead of 32).
If warp occupancy is a limiting factor, this means that 4×4 mode may not have any performance benefit over 4×2/2×4 mode, since the total number of warps is the same.
Use caution and check performance when using VRS with blend-heavy techniques.
Although VRS may decrease the number of running pixel shaders, blending still runs at full rate, that is, once for every individual sample in the render target. Semi-transparent volumetric effects are a potential candidate for VRS due to often being visually low-frequency, but if the workload is already ROP-limited (blending), using VRS does not change that limitation and thus may not result in any appreciable performance improvement.
Use care with centroid sampling! Centroid sample selection across a “coarse pixel” may work in counter-intuitive ways! Make sure that you are familiar with your API’s specifications.
Do not modify the output depth value from the pixel shader. If the pixel shader modifies depth, VRS is automatically disabled.
The latest release of NVIDIA CloudXR includes some of the most requested features from the developer community, such as support for pre-configuring a remote server.
Since the launch of NVIDIA CloudXR, we have received positive feedback and wide adoption of the SDK. Developers have been busy building solutions that take advantage of remote data center hardware powered by NVIDIA GPUs to render full-fidelity XR experiences remotely. With CloudXR, you can deliver these experiences to low-powered, off-the-shelf consumer devices streaming on networks anywhere in the world.
Our developer community continues to help shape CloudXR and we couldn’t be more excited to launch CloudXR 3.2. This release includes some of the most requested features that help to build even more scalable and powerful experiences for users.
CloudXR 3.2 now supports setting a remote server to be preconfigured with a client device profile before the client device connects to the server. Most XR applications check for a connected headset on launch and won’t proceed until a device is connected. This results in limitations to supporting global orchestration, global scaling, and overall application usefulness.
You can now define a device profile on the remote server that is used by CloudXR during an application’s initial launch. You can then launch your remote application in a waiting state, speeding up application delivery between the server and client.
New networking-focused client API
We’ve introduced an API that enables you to query the quality of service (QoS) and network information from a remote streaming server. You can use this data as-is for troubleshooting or building user interface representations of the data that display indicators of varying performance to end users.
Client application developers can also now specify network interface information that helps CloudXR optimize QoS decisions. These include network topology type (5G, Wi-Fi, LAN) and maximum bitrate. Keep in mind that indicating a maximum bitrate only helps the CloudXR QoS algorithms and does not guarantee this rate will be achieved.
90fps support on Meta Quest 2
The Meta Quest 2 (previously Oculus Quest 2) sample client has been updated to support 90 hz. This allows for even more immersive experiences at the device’s preferred frame rate when streaming from a CloudXR server.
Figure 1. Screenshot of a CloudXR Server streaming to Meta Quest 2 at 90 hz
Support for Swift for iOS developers
There are improvements for iOS developers as well. Logs have been made easier to access by listing them within the Files application. Also, the iOS sample has been updated to Swift, an important step in supporting Apple’s latest libraries.
This version has parity with the Objective-C sample client, but you should start transitioning to Swift. Because Apple’s latest libraries are accessible only with Swift, the Objective-C client will be removed in a future release.
Updates to the programming SDK
CloudXR 3.2 includes new flags that help you select gamma-corrected or linear output (Android only), update projection parameters, or send new interpupillary distance (IPD) adjustments. You can also send user-defined pose IDs with updates, and updated pose transformation mathematics. These additions help in instances where the local device IPD is manually changed and must be updated on the server. It also helps in scenarios where the video in a local headset looks either too bright or too dark.
Resources
The CloudXR SDK is what it is because of your continued support and feedback. The new features in version 3.2 are directly influenced by you, our developer community. Make sure to upgrade or download this latest release from the CloudXR SDK page on the Developer Zone If you’re not already a member of the CloudXR Early Access Program, register to join.
The NVIDIA Developer Forum is also a great place to ask for assistance and offer suggestions to future releases of CloudXR. While there, connect with like-minded developers building clients, applications, and experiences. We’re excited to see what you build next.
NVIDIA Morpheus, now available for download, enables you to achieve up to 99% accuracy for phishing detection, using AI.
Email became one of the most pervasive, powerful communication tools during the digital revolution. Attempts to defraud users by deceptively posing as legitimate people or institutions through email became so widespread that it got its own name: phishing.
Most phishing cybersecurity defenses combine rules-based email filters and human training to detect a fraudulent email. When filters fail, there is a risk that a human will too, despite training to enhance the detection of a suspicious email.
It takes just one human error to cost an enterprise millions of dollars in losses and time-to-resolution. To reduce breaches, it is critical to eliminate phishing from entering any inbox in the first place.
Current rules-based systems are limited in their sight. They can only “see” issues that are known, and fraudsters are typically one step ahead of those systems. Filters to catch these issues can only improve after a breach and weakness have been identified, which is too late.
To get ahead of the phishing problem, machines must be able to anticipate weaknesses, rather than fall prey to them, and develop enhanced sentiment analysis to keep pace and pull ahead of the fraudsters.
Phishing detection with NVIDIA Morpheus
NVIDIA Morpheus, now generally available for download from NVIDIA NGC and the NVIDIA/Morpheus GitHub repo, is an open AI framework for implementing cybersecurity-specific inference pipelines.
With NVIDIA Morpheus, our cybersecurity team applied natural language processing (NLP), a popular AI technique, to create a phishing detection application that correctly classified phishing emails at a 99%+ accuracy rate.
Using the Morpheus pipeline for phishing detection, you can use your own models to improve the accuracy further. As you fine-tune the model with new phishing emails that your company receives, the model continues to improve.
Because Morpheus enables large-scale unsupervised learning, you don’t have to rely on rules-based methods that require a URL or suspicious email address to detect phishing. Instead, Morpheus learns from the emails received, making it a more comprehensive, sustainable approach to managing phishing detection.
Approach
The cybersecurity team followed the first three steps of a typical AI workflow to develop the phishing detection proof of concept (POC):
Data prep
AI modeling
Simulation and testing
They were able to execute rapidly by using pretrained models. We walk through each step to see how the team approached development.
Data prep
To develop an AI model, it must be trained with preexisting relevant data. Normally, much of the development time centers on working with datasets to make it usable for a model-in-training to analyze.
In this case, the team sourced publicly available English-language phishing datasets that already existed and repurposed them to align with the POC needs, expediting the development process significantly.
The POC required a large dataset of emails that were benign and fraudulent for the phishing model to train from. The team started with the SPAM_ASSASSIN dataset, which has a preexisting mix of email data labeled phishing, hard ham, and easy ham. The ham classes are benign emails of various complexities. For our purposes, we simplified the classifications to benign and phishing, combining both hard ham and easy ham classified emails into a single benign category.
While the SPAM_Assassin dataset was a helpful starting point, the model required significantly more training data. The team incorporated the Enron Emails dataset as a benign data source and the phishing class of the Clair dataset as a phishing source. The model was trained and evaluated on various mixes of these datasets.
ML modeling
ML development centers on training and evaluating a model with data that eventually learns to perform the requested function on its own.
Instead of creating a new AI model from scratch, the team sourced a pretrained BERT model as the AI model to refine for the POC. BERT is an open-source, machine learning framework for NLP. BERT is designed to help computers understand the meaning of ambiguous language in text by using surrounding text to establish context.
The team fine-tuned this existing model for phishing detection by training and evaluating it with the earlier datasets.
Simulation and test
This is the stage where the model is tested, evaluated, and trained to perform for phishing detection purposes.
The SPAM_Assassin, Clair, and Enron datasets were all split into training and validation sets at random. Then, the BERT model was trained to classify emails from various mixes of the set as benign or phishing. When the refined BERT model was tested using a validation dataset that combined Enron, Clair, and SPAM_Assassin, it was again 99.68% accurate at interpreting the email in alignment with its classification.
Our tests showed over 99% accuracy of the trained BERT model in detecting phishing or benign emails when used on the validation datasets.
Summary
AI can play a significant role in addressing the cybersecurity issues organizations face every single day, but many organizations are intimidated by developing AI capability in their organization.
NVIDIA is democratizing AI by making it simple and efficient to develop for any enterprise across any use case. This POC was an example of how resources available in NVIDIA Morpheus can shorten and simplify AI-application development for enterprise developers looking to enhance their cybersecurity arsenal.
To accelerate your enterprise’s cybersecurity even more, use the pretrained phishing model available with NVIDIA Morpheus today. The NVIDIA Morpheus AI cybersecurity framework not only demonstrates the transformative capabilities of applying AI to address cybersecurity threats but also makes it easy for an organization to incorporate AI with development cycles like the one described earlier. With more data to train the model, it becomes even stronger.
Morpheus is an open AI framework for developers to implement cybersecurity-specific inference pipelines. Morpheus provides a simple interface for security developers and data scientists to create and deploy end-to-end pipelines that address cybersecurity, information security, and general log-based pipelines. This series is focused on highlighting the various use cases and implementations of Morpheus that can be relevant to any technical cybersecurity strategy.
Learn how to roll out a successful edge AI solution across your organization in just 5 steps.
The demand for edge computing is higher than ever, driven by the pandemic, the need for more efficient business processes, as well as key advances in the Internet of Things (IoT), 5G, and AI. In a study published by IBM in May 2021, 94% of surveyed executives said that their organizations will implement edge computing in the next 5 years.
Edge AI, the combination of edge computing and AI, is a critical piece of the software-defined business. From smart hospitals and cities to cashierless shops to self-driving cars, all are powered by AI applications running at the edge.
Transforming business with intelligence driven by AI at the edge is just that, a transformation, which means it can be complicated. Whether you are starting your first AI project or looking at infrastructure blueprints and expansions, these five steps will help set your edge AI projects up for success.
Figure 1. Steps to get started with edge AI
1. Identify a use case
When it comes to getting started with edge AI, it is important to identify the right use case, whether it be to drive operational efficiency, financial impact, or social initiatives. For example, shrinkage in retail is a $100B problem that can be mitigated by machine learning and deep learning. Even a 10% reduction represents billions in revenue.
When selecting a use case for getting started with edge AI, consider the following factors.
Business impact: Successful AI projects must be of high enough value to the business to make them worth the time and resources needed to get them started.
Key stakeholders: Teams involved in AI projects include developers, IT, security operations (SecOps), partners, system integrators, application vendors, and more. Engage these teams early in the process for the best outcomes.
Success criteria: Define the end goal at the beginning to make sure that projects do not drift due to scope creep.
Timeframe: AI takes time and is an iterative process. Identifying use cases that have a long-term impact on the business will ensure that solutions remain valuable in the long term.
2. Evaluate your data and application requirements
With billions of sensors located at edge locations, it is generally a data-rich environment. This step requires understanding what data is going to be used for training an AI application as well as inference, which leads to action.
Getting labeled data can be daunting, but there are ways to solve this.
Leverage internal expertise: If you are trying to automate a process, use the experts who do the task manually to label data.
Synthetic data: Using annotated information that computer simulations or algorithms generate is a technique often used when there is limited training data or when the inference data will vary greatly from the original data sets.
Crowdsourced data: Leveraging your audience to help label large quantities of data has been effective for some companies. Examples include open-source data sets, social media content, or even self-checkout machines that collect information based on customer input.
If you have the quantity and quality of data required to train or retrain your AI models, then you can move on to the next step.
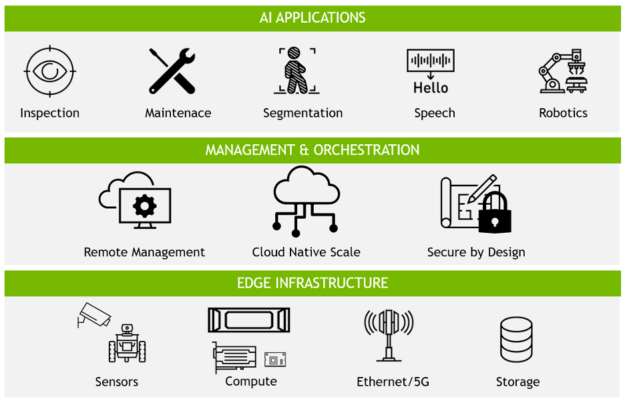
3. Understand edge infrastructure requirements
One of the most important and costly expenses when rolling out an edge AI solution is infrastructure. Unlike data centers, edge computing infrastructure must take into additional considerations around performance, bandwidth, latency, and security.
Start by looking at the existing infrastructure to understand what is already in place and what needs to be added. Here are some of the infrastructure items to consider for your edge AI platform.
Figure 2. Edge AI infrastructure includes hardware, sensors, and AI software
Sensors: Most organizations today are relying on cameras as the main edge devices, but sensors can include chatbots, radar, lidar, temperature sensors, and more.
Compute systems: When sizing compute systems, consider the performance of the application and the limitations at the edge location, including space, power constraints, and heat. When these limiting factors are determined, you can then understand the performance requirements of your application.
Network: The main consideration for networking is how fast of a response you need for the use case to be viable, or how much data and whether real-time data must be transported across the network. Due to latency and reliability, wired networks are used where possible, though wireless is an option when needed.
Management: Edge computing presents unique challenges in the management of these environments. Organizations should consider solutions that solve the needs of edge AI, namely scalability, performance, remote management, resilience, and security.
Infrastructure is directly connected to the immediate use-case solution, but it is important to build with a mind to additional use cases that may be deployed at the same location.
4. Roll out your edge AI solution
When it comes to rolling out an edge AI application, testing AI applications at the edge is critical for ensuring success. An edge AI proof-of-concept (POC) is usually deployed at a handful of locations and can take anywhere from 3-12 months.
To ensure a smooth transition from POC to production, it is important to take into account what the end solution will look like. Here are some things to consider when rolling out an AI application.
Design for scale: POCs are generally limited to one or a handful of locations but if successful, they must scale to hundreds or even thousands of locations.
Constrain scope: AI applications improve over time. Different use cases will have different accuracy requirements that can be defined in the success criteria.
Prepare for change: Edge AI has many variables, which means even the best-laid plans will change. Ensure that the rollout is flexible without compromising the defined success criteria.
5. Celebrate your success
Edge AI is a transformational technology that helps businesses improve experience, speed, and operational efficiency. Many organizations have multiple edge use cases to roll out, which is why celebrating success is so important. Companies that highlight successes are more likely to drive interest, support, and funding for future edge AI projects.
Get started with end-to-end edge AI
As a leader in AI, NVIDIA has worked with customers and partners to create edge computing solutions that deliver powerful, distributed compute; secure remote management; and compatibility with industry-leading technologies.
Organizations can easily get started with NVIDIA LaunchPad, which provides immediate, short-term access to the necessary hardware and software stacks to experience end-to-end solution workflows in the areas of AI, data science, 3D design collaboration, and simulation, and more. Curated labs on LaunchPad help developers, designers, and IT professionals speed up the creation and deployment of modern, data-intensive applications.
Join us on May 26 to learn how you can leverage accelerated AI frameworks to build high performance zero-trust solutions with reduced friction and fewer lines of code.
I’ve originally posted this on self-hosted subreddit and it was really helpful to get me started.
My youngest son has Autism Spectrum Disorder (ASD), he’s 5 now. Recently he developed a habit of taking off his clothes and playing around without any clothes on! I already have a few cameras around the house, however, I was wondering if anyone knows a solution that can detect if my son is moving around the house without any clothes on so I can fire up automation and play a pre-recorded voice note on speakers in the house asking him to put on his clothes again!
So I’ve managed to get a live camera feed into Hom Assistant, using (https://github.com/snowzach/doods2) also was able to detect objects and persons using (tensorflow) and HA saves a snapshot for labels I want to capture, such as “person” or “people”. Seems to be working just fine.
I was looking for some pre-trained models to detect nudity / NSFW and found some such as: https://github.com/minto5050/NSFW-detection. However, I couldn’t manage to upload this model and run it for some reason. I’ve downloaded the model and labels files and placed them in the models and declared it in the config file but it isn’t working.
Can you guys help me? I don’t know how to solve this problem. I copied one of the kaggle works and changed the building part. For LeNet build this code worked but I tried that with VGG16 but it gives me error I couldn’t solve that.

 This post covers best practices for variable rate shading on NVIDIA GPUs.
This post covers best practices for variable rate shading on NVIDIA GPUs.  The latest release of NVIDIA CloudXR includes some of the most requested features from the developer community, such as support for pre-configuring a remote server.
The latest release of NVIDIA CloudXR includes some of the most requested features from the developer community, such as support for pre-configuring a remote server.
 NVIDIA Morpheus, now available for download, enables you to achieve up to 99% accuracy for phishing detection, using AI.
NVIDIA Morpheus, now available for download, enables you to achieve up to 99% accuracy for phishing detection, using AI. Learn how to roll out a successful edge AI solution across your organization in just 5 steps.
Learn how to roll out a successful edge AI solution across your organization in just 5 steps.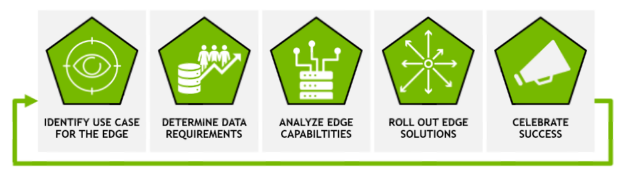
 Join us on May 26 to learn how you can leverage accelerated AI frameworks to build high performance zero-trust solutions with reduced friction and fewer lines of code.
Join us on May 26 to learn how you can leverage accelerated AI frameworks to build high performance zero-trust solutions with reduced friction and fewer lines of code.