
 Join expert speakers and the developer community at WeAreDevelopers World Congress June 14-15, to exchange ideas, share knowledge, and facilitate networking.
Join expert speakers and the developer community at WeAreDevelopers World Congress June 14-15, to exchange ideas, share knowledge, and facilitate networking.
Join NVIDIA speakers in person at the WeAreDevelopers World Congress, held June 14-15 in Berlin, Germany. Over 2 days, the event brings together the developer world with over 200 speakers and 5,000 developers gracing the show floor.
Speakers and thought leaders from companies like GitHub, Google, and Stripe will discuss a multitude of developer topics. From programming languages and frameworks to DevOps and containers to machine learning and smart devices, there is a session for every developer.
Take a look at the WeAreDevelopers World Congress schedule.
Learn from NVIDIA experts
Below is a preview of what NVIDIA experts will be speaking about at the conference.
Graph Neural Networks: What’s Behind the Hype?
Stage 5 | Wednesday, June 15 | 9:50 – 10:20 a.m.
Ekaterina Sirazitdinova, data scientist at NVIDIA
Graph neural networks (GNNs) are AI models designed to derive insights from unstructured data described by graphs. For different segments and industries, GNNs find suitable applications such as molecular analysis, drug discovery, prediction of developments in stock market, thermodynamics analysis, and even modeling of the human brain. Unlike conventional CNNs, GNNs address the challenge of working with data in irregular domains.
In this talk, Ekaterina will provide an introductory overview of the theory behind GNNs, take a closer look at the types of problems that GNNs are well suited for, and discuss several approaches to model unstructured problems as classification or regression at various levels.
Enhancing AI-based Robotics with Simulation Workflows
Stage 5 | Wednesday, June 15 | 11:50 a.m. – 12:20 p.m.
Teresa Conceicao, senior solutions architect at NVIDIA
With an ever-growing AI and data-centric world, robots will become more intelligent, flexible, and robust. However, with these new paradigms, some challenges arise. AI Robots need data, training, and testing—and lots of it. Acquiring real data can be costly and laborious, training in the real world is not scalable, and finding real-world scenarios for difficult use cases can be near impossible. While testing cycles are time consuming and slow down development iterations.
In this session, Teresa will go over how Simulation can play a key role in enabling AI-based Robotics, and how to get started enhancing AI workflows with the NVIDIA Omniverse and NVIDIA Isaac platforms.
Natural Language Processing: Changing the Way We Tell Machines What We Want Them To Do
Available on-demand during the conference
Adam Grzywaczewski, senior deep learning data scientist at NVIDIA
Software development processes involve describing the desired functionality using a formal programming language, such as C++ or Python. Recent progress in NLP brings us closer to a point where formal programming languages are no longer necessary, and can be replaced by a plain text description of program’s behavior. An early example of this capability can be seen in GitHub coPilot.
In this talk, Adam will discuss the most recent breakthroughs in NLP and the reasons for their success. He’ll focus on how advances in AI have changed the software development process for NLP models to learn new, previously unseen tasks. He’ll conclude by sharing how tools such as NVIDIA Megatron-LM can be used to build SOTA NLP models like GPT-3 and deploy them to production.
WeAreDevelopers job board
Browse over 2,900 jobs across Europe, covering every type of developer role. Frontend, backend, full-stack, software, JavaScript, PHP, C#… whatever your skill set, they have a job listing for it.
See the WeAreDevelopers job board. >>
Hands-on labs, tutorials, and resources from NVIDIA
Join the NVIDIA Developer Program for free and exclusive access to SDKs, technical documentation, peer, and domain expert help. NVIDIA offers tools and training to accelerate AI, HPC, and graphics applications.
Discover the NVIDIA Deep Learning Institute for resources covering diverse learning needs—from learning materials to self-paced and live training to educator programs—giving individuals, teams, organizations, educators, and students tools to advance AI, accelerated computing, data science, graphics, and simulation knowledge.
Connect with NVIDIA at the WeAreDevelopers World Congress 2022. >>








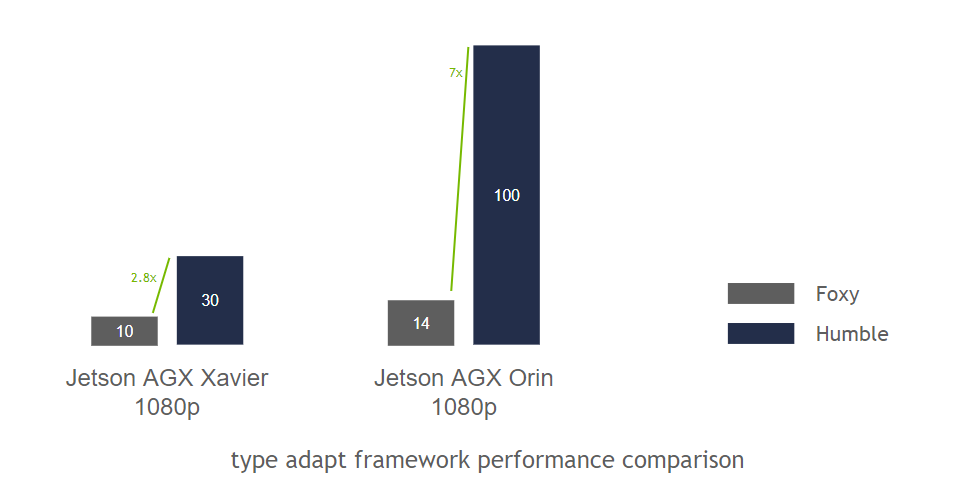
") Announcing NVIDIA Isaac Transport for ROS (NITROS) pipelines that use new ROS Humble features developed jointly with Open Robotics.
Announcing NVIDIA Isaac Transport for ROS (NITROS) pipelines that use new ROS Humble features developed jointly with Open Robotics.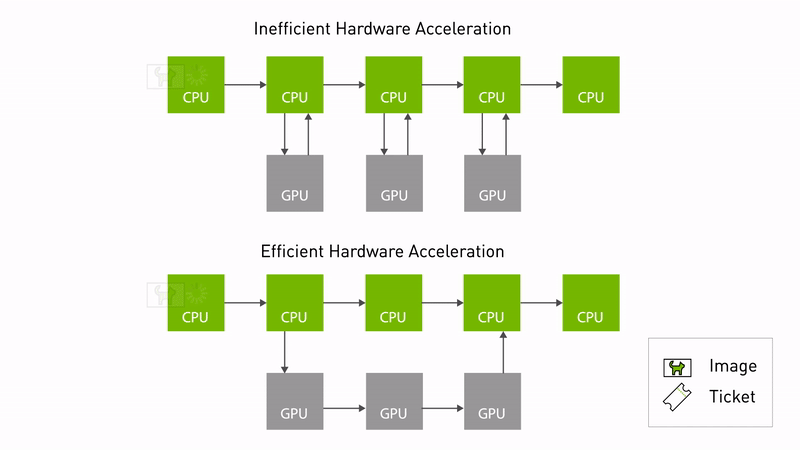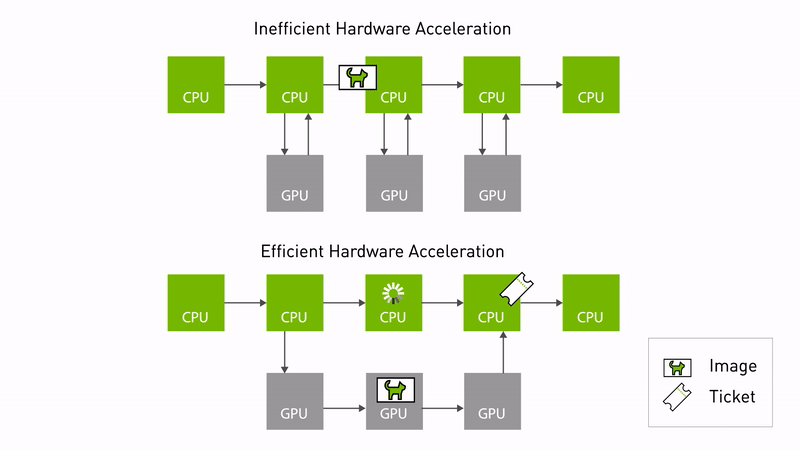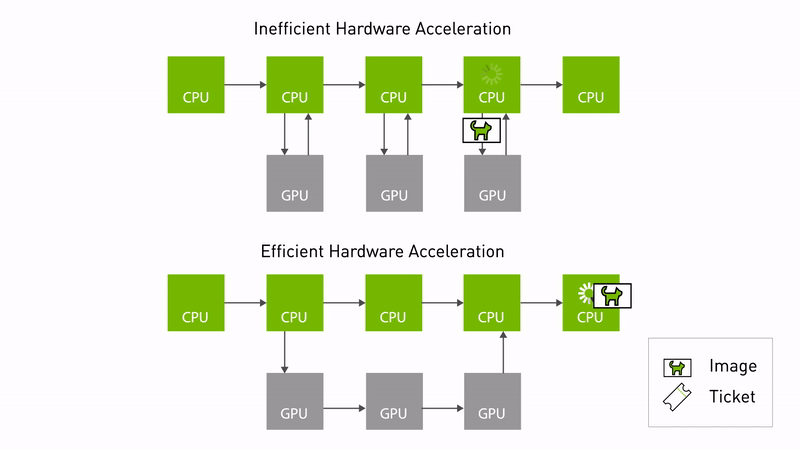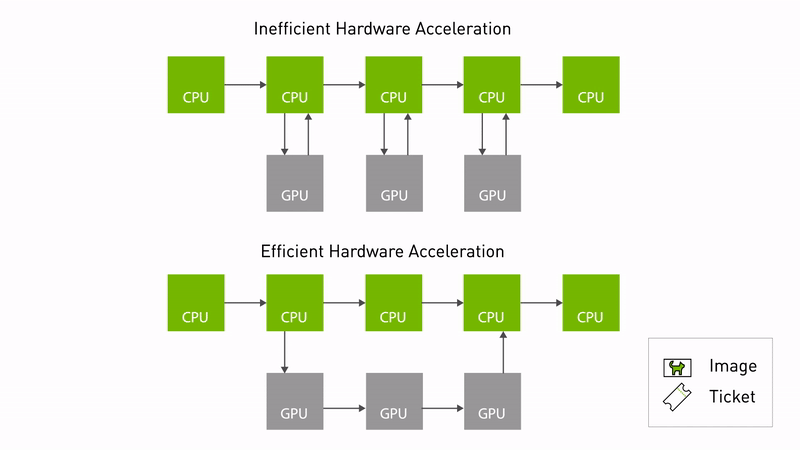


 Users can now produce 3D virtual worlds at human scale with the new Omniverse XR App available in beta from the NVIDIA Omniverse launcher.
Users can now produce 3D virtual worlds at human scale with the new Omniverse XR App available in beta from the NVIDIA Omniverse launcher.