I’m pretty new to Tensorflow world and have implemented some models using existing layers like convolution, dense and LSTM. Now I wanted to implement Elman Neural Network (wiki page) in tensorflow 2, and because it seems there isn’t any existing implementation in Tensorflow, so I decided to implement myself. Although there are couple of implementations in the web for Elman neural network but non of them have implemented via subclassing Tensorflow’s Model class. I thought it would be lot easier to implement via subclassing Model class. Following is my implementation. The problem is when I call .fit on a train dataset batch_size variable in call method is None, and I couldn’t determine how to solve this problem. Any Ideas?
Fortnite on GeForce NOW with touch controls on mobile is now available to all members, streaming through the Safari web browser on iOS and the GeForce NOW Android app. The full launch — including the removal of the waitlist — follows a successful beta period in which more than 500,000 participants streamed over 4 million Read article >
Edge AI and high-performance computing are modernizing the electric grid, from power generation to transmission and distribution to the grid-edge.
Utilities are challenged to integrate distributed clean energy resources—such as wind farms, rooftop solar, home batteries, and electric vehicles—onto legacy electric grid infrastructure. Existing systems were built to manage a one-way flow of power from a small number of industrial-scale generation plants, often run using coal, natural gas, or nuclear.
Energy output from these sites was predictable and controllable to align power generation with electricity demand. Scheduling outages for maintenance was a routine task that limited service disruptions for customers counting on a reliable grid to keep the lights on.
However, the global shift to accelerate the energy transition and achieve net-zero emissions has exposed the flaws of existing grid infrastructure. Output is difficult to predict and control because there are numerous energy resources that each generate small amounts of power that can either be consumed or redirected back to the grid. These resources are distributed in different locations and generate varying amounts of power, making them difficult to manage.
To manage distributed energy resources, a new approach to power grid management is needed that’s based on edge AI and high-performance computing (HPC). This combination creates an accelerated computing platform that enhances grid resiliency through demand forecasting, optimal power flow, grid simulation, and predictive maintenance of existing infrastructure to transform legacy grids into software-defined smart grids.
Powering the next generation of industrial power plants
The first step to digitizing grids starts with power generation. Globally, industrial plants generate 24,000 terawatt-hours (TWh) of electricity per year, with nearly 38% produced by nuclear, hydro, wind, solar, and renewables.
Heavy machinery—such as generators, turbines, pumps, and reactors—requires routine maintenance, but unplanned downtime can prevent effective service delivery, impact revenue, and lead to expensive repairs. Manually intensive inspections reduce productivity, create unnecessary risks to worker health and safety, and could damage industrial equipment.
Siemens Energy
To minimize maintenance disruptions, energy companies are building industrial digital twins of real-world power generation sites. Siemens Energy, a global energy technology provider, created a virtual replica of their heat recovery steam generator (HRSG) using NVIDIA Modulus (a physics-machine learning framework) and NVIDIA Omniverse (a 3D design collaboration and physically accurate simulation platform). HRSGs use heat exhaust from gas turbines to create steam used to drive steam turbines, which improves plant efficiency and output while reducing operational costs.
The company developed a new workflow that feeds temperature, pressure, and velocity data to Modulus and simulates steam and water flow in real-time using Omniverse. By accurately predicting corrosion with a digital twin, Siemens Energy estimates that utilities could save $1.7 billion annually by automating equipment inspections and cutting downtime by 10% per year.
Figure 1. Industrial digital twin of the Siemens Energy heat recovery steam generator
Siemens Gamesa
Power is also generated in offshore platforms, such as wind farms, where higher wind speeds drive turbines and generate more electricity per capacity installed than onshore sites. Traditional methods to simulate turbulent wind flow, wake effects, and other scenarios are computationally intensive and costly.
Siemens Gamesa, a leader in renewable energy, built a digital twin to model their offshore wind farms, which generate over 100 gigawatts of energy each year. Using the NVIDIA digital twin platform for scientific computing, the company was able to simulate wake effects up to 4,000x faster with high accuracy and fidelity. Faster computational fluid dynamics simulations shorten the time to design an ideal wind farm, which leads to increased electricity output and lower operating costs.
Gigastack
Energy companies are exploring processes to sustainably power industrial plants, replacing fossil fuels with “green hydrogen”. A new industry consortium is developing Gigastack, the world’s first industrial-scale green hydrogen project, to accelerate the country’s net-zero emissions goals and create a framework for successful operations around the world.
The project, now in the second of three phases, aims to use renewable electricity produced by offshore wind to split water into oxygen and renewable hydrogen, to fuel the Phillips 66 Humber Refinery in the United Kingdom. Worley, the project’s lead engineering firm, leveraged Aspen Technology’s Optiplant software to remotely collaborate on a physically accurate 3D conceptual layout of the Humber Refinery with designers and engineers around the world. The digital twin layers multiple dimensions to automate plant processes, such as scheduling, cost estimation, emissions, maintenance, and worker safety.
Modernizing legacy grid infrastructure
After it’s generated, electricity must move through transmission and distribution lines to reach end customers, whether they’re residential, commercial, or industrial. A significant portion of the energy is lost in this process, which reduces the available energy supply. In addition, extreme weather events, such as snowstorms, wildfires, and floods, threaten the reliability of the grid.
In the event of widespread power outages due to large storms or other causes, utilities route trucks to service downed lines in the field to restore power quickly and efficiently. However, routing vehicles is an exponentially complex problem.
NVIDIA cuOpt helps utilities dynamically reoptimize truck rolls as new challenges arise or power grid assets go offline. The route optimization software suite uses GPU-accelerated logistics solvers relying on heuristics and optimizations to deliver dynamic rerouting simulations and subsecond solver-response time.
Electric Power Research Institute
Accelerated computing enables utilities to optimize power flow, predict grid anomalies, prevent unplanned blackouts, and automate maintenance. Electric Power Research Institute (EPRI), an independent, nonprofit energy research and development organization, is building a grid simulator with NVIDIA to schedule outages of power systems and minimize downtime.
Using AI and HPC, utilities can model the electric grid as a connected graph with transformers and substations as nodes and transmission lines as edges. These models are trained on historical data to simulate specific grid outages, and address challenges to accommodate variable renewable energy, distributed energy resources, and shifting flow patterns.
Figure 2. An accelerated grid simulator to efficiently model power flow and minimize grid disruptions
This method of contingency planning extends beyond N-1 (single asset failure) to multipoint failures that enhance resiliency at the regional–, micro–, and nano-grid levels. The tool simulates AC power flow (ACPF) as steady-state branch currents and node voltages of a transmission grid circuit, given input profiles for loads and generators.
As clean energy resources expand, the grid simulator can guide operators to redispatch or reconfigure network topology by solving millions of simultaneous ACPF problems in seconds.
HEAVY.AI
With utilities’ limited visibility into their infrastructure, vegetation near grids poses a wildfire threat to neighboring communities and wildlife habitats. Managing vegetation requires real-time data analysis to proactively monitor transmission lines and transformers.
HEAVY.AI, an advanced data analytics company, analyzes terabytes of geospatial data from satellite, LIDAR, weather, and vegetation health. A strike tree model enables risk-based vegetation management, while a web-based dashboard provides insights for predictive maintenance and wildfire mitigation.
IronYun
At electric substations, safety and security are critical to automation and maintenance of reliable grid operations. Startups such as IronYun are using computer vision to monitor security access or equipment health. Using existing IP cameras and intelligent video analytics, the company’s platform can help ensure protocols for worker health and safety are followed and prevent onsite breaches.
Unlocking edge intelligence with smart grid technology
At the edge of the grid, energy reaches its final destination in homes, office buildings, factories, stores, and more.
Utilidata
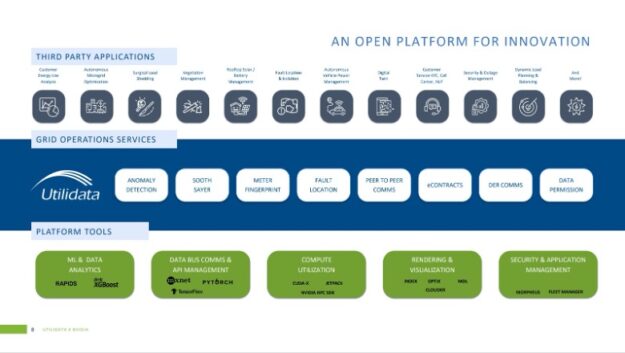
Utilidata is working with NVIDIA to develop a smart grid chip that can be embedded in smart meters. The chip can enhance grid resiliency, integrate distributed energy resources (DERs) among solar, storage, and EVs, and accelerate the transition to a decarbonized grid. The chip is designed to be a platform for innovation, with a set of core grid operations services developed by Utilidata that will enable applications developed by third parties.
Figure 3 shows the platform tools and Utilidata’s core services for advanced metering infrastructure, which come embedded on the smart grid chip, and examples of applications that could be developed.
Figure 3. Utilidata open platform to accelerate grid edge services
Noteworthy AI
Utilities can also automate and simplify the inspection of distribution poles, power lines, and other pole-mounted equipment. Using computer vision and smart camera systems, Noteworthy AI can detect cracks, corrosion, breakages, high-risk vegetation, and other potential issues through inference at the grid edge. The camera system, built on the NVIDIA Jetson edge AI platform, is mounted to utility trucks and collects 60-megabyte images of grid infrastructure during field servicing. Running multiple AI models at the edge on Jetson, with only a subset of images sent to the cloud for analysis, reduces the cost of compute for Noteworthy AI.
Bullfrog Energy Ecosystem
Smart homes are also automating tasks using smart devices connected to the Internet of Things (IoT). Anuranet launched the Bullfrog Energy Ecosystem, which includes an NVIDIA Jetson-powered smart meter, smart breaker, and home control hub. The platform uses computer vision and conversational AI to drive personalized interactions with homeowners.
For consumers, monthly electricity bills can be lowered through visibility into energy consumption and carbon footprint.
For utilities, this connectivity at the edge enables real-time energy pricing.
Anuranet’s platform automates controls for neighborhood-level microgrids, bringing together individual smart homes into energy-efficient communities.
Accelerating the energy transition
Utilities are at the forefront of the clean energy transition, but must modernize transmission and distribution grid infrastructure to manage renewable energy resources at scale. Accelerated computing can power this digital transformation and create software-defined smart grids that deliver reliable energy and accelerate sustainability initiatives.
In general, the information on internet about tensorflow object detection api tells we only need to divide the dataset into train and test. But I find other information about machine learning that also talks about a validation dataset. Is the validation dataset important in object detection and in this framework?
Today, we want to call attention to a highly useful package in the torch ecosystem: torchopt. It extends torch by providing a set of popular optimization algorithms not available in the base library. As this post will show, it is also fun to use!
Today, we want to call attention to a highly useful package in the torch ecosystem: torchopt. It extends torch by providing a set of popular optimization algorithms not available in the base library. As this post will show, it is also fun to use!
Imagine we have a neural network, or any network that can be trained iteratively with epochs and consider the two training cases below;
We have x amount of data and we train until we reach 0.1 loss. Let us say this took 100 epochs.
We have greatly increased the size of our data to 100x and we have trained for a greatly reduced number of epochs (let us say 1 epoch) to reach 0.1 loss.
In terms of testing performance and realtime predictions, will there be any significant difference between these two cases even though the loss (let us assume the validation and training accuracies are the same as well.) is the same?
I am feeling the contradiction between training for large epochs with small data and training with small data for lower epochs.
As far as I am concerned, I could not get a transformer network to converge to acceptable metrics without data augmentation, while training for a low number of epochs. I have tried training it for thousands of epochs with limited data, no luck.
In order to keep the argument easily arguable, I assumed every other thing I did not change between two cases did not actually change. Quite obviously increasing the data size to 100x will not result in 0.1 loss with 1 epochs, models do not work linearly like that.
Posted by Jiahui Yu, Senior Research Scientist, and Jing Yu Koh, Research Software Engineer, Google Research
In recent years, natural language processing models have dramaticallyimproved their ability to learn general-purpose representations, which has resulted in significant performance gains for a wide range of natural language generation and natural language understanding tasks. In large part, this has been accomplished through pre-training language models on extensive unlabeled text corpora.
This pre-training formulation does not make assumptions about input signal modality, which can be language, vision, or audio, among others. Several recent papers have exploited this formulation to dramatically improve image generation results through pre-quantizing images into discrete integer codes (represented as natural numbers), and modeling themautoregressively (i.e., predicting sequences one token at a time). In these approaches, a convolutional neural network (CNN) is trained to encode an image into discrete tokens, each corresponding to a small patch of the image. A second stage CNN or Transformer is then trained to model the distribution of encoded latent variables. The second stage can also be applied to autoregressively generate an image after the training. But while such models have achieved strong performance for image generation, few studies have evaluated the learned representation for downstream discriminative tasks (such as image classification).
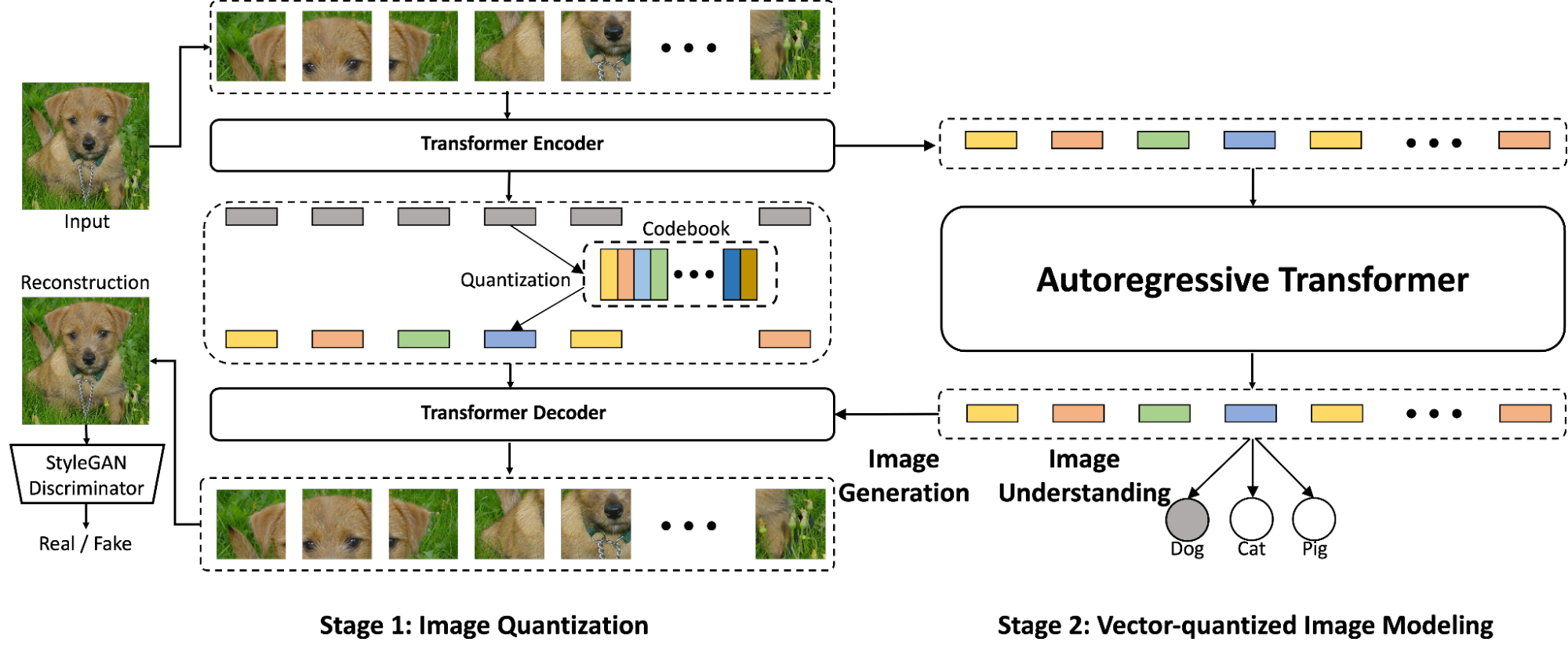
In “Vector-Quantized Image Modeling with Improved VQGAN”, we propose a two-stage model that reconceives traditional image quantization techniques to yield improved performance on image generation and image understanding tasks. In the first stage, an image quantization model, called VQGAN, encodes an image into lower-dimensional discrete latent codes. Then a Transformer model is trained to model the quantized latent codes of an image. This approach, which we call Vector-quantized Image Modeling (VIM), can be used for both image generation and unsupervised image representation learning. We describe multiple improvements to the image quantizer and show that training a stronger image quantizer is a key component for improving both image generation and image understanding.
Vector-Quantized Image Modeling with ViT-VQGAN One recent, commonly used model that quantizes images into integer tokens is the Vector-quantized Variational AutoEncoder (VQVAE), a CNN-based auto-encoder whose latent space is a matrix of discrete learnable variables, trained end-to-end. VQGAN is an improved version of this that introduces an adversarial loss to promote high quality reconstruction. VQGAN uses transformer-like elements in the form of non-local attention blocks, which allows it to capture distant interactions using fewer layers.
In our work, we propose taking this approach one step further by replacing both the CNN encoder and decoder with ViT. In addition, we introduce a linear projection from the output of the encoder to a low-dimensional latent variable space for lookup of the integer tokens. Specifically, we reduced the encoder output from a 768-dimension vector to a 32- or 8-dimension vector per code, which we found encourages the decoder to better utilize the token outputs, improving model capacity and efficiency.
Overview of the proposed ViT-VQGAN (left) and VIM (right), which, when working together, is capable of both image generation and image understanding. In the first stage, ViT-VQGAN converts images into discrete integers, which the autoregressive Transformer (Stage 2) then learns to model. Finally, the Stage 1 decoder is applied to these tokens to enable generation of high quality images from scratch.
With our trained ViT-VQGAN, images are encoded into discrete tokens represented by integers, each of which encompasses an 8×8 patch of the input image. Using these tokens, we train a decoder-only Transformer to predict a sequence of image tokens autoregressively. This two-stage model, VIM, is able to perform unconditioned image generation by simply sampling token-by-token from the output softmax distribution of the Transformer model.
VIM is also capable of performing class-conditioned generation, such as synthesizing a specific image of a given class (e.g., a dog or a cat). We extend the unconditional generation to class-conditioned generation by prepending a class-ID token before the image tokens during both training and sampling.
Uncurated set of dog samples from class-conditioned image generation trained on ImageNet. Conditioned classes: Irish terrier, Norfolk terrier, Norwich terrier, Yorkshire terrier, wire-haired fox terrier, Lakeland terrier.
To test the image understanding capabilities of VIM, we also fine-tune a linear projection layer to perform ImageNet classification, a standard benchmark for measuring image understanding abilities. Similar to ImageGPT, we take a layer output at a specific block, average over the sequence of token features (frozen) and insert a softmax layer (learnable) projecting averaged features to class logits. This allows us to capture intermediate features that provide more information useful for representation learning.
Experimental Results We train all ViT-VQGAN models with a training batch size of 256 distributed across 128 CloudTPUv4 cores. All models are trained with an input image resolution of 256×256. On top of the pre-learned ViT-VQGAN image quantizer, we train Transformer models for unconditional and class-conditioned image synthesis and compare with previous work.
We measure the performance of our proposed methods for class-conditioned image synthesis and unsupervised representation learning on the widely used ImageNet benchmark. In the table below we demonstrate the class-conditioned image synthesis performance measured by the Fréchet Inception Distance (FID). Compared to prior work, VIM improves the FID to 3.07 (lower is better), a relative improvement of 58.6% over the VQGAN model (FID 7.35). VIM also improves the capacity for image understanding, as indicated by the Inception Score (IS), which goes from 188.6 to 227.4, a 20.6% improvement relative to VQGAN.
Fréchet Inception Distance (FID) comparison between different models for class-conditional image synthesis and Inception Score (IS) for image understanding, both on ImageNet with resolution 256×256. The acceptance rate shows results filtered by a ResNet-101 classification model, similar to the process in VQGAN.
After training a generative model, we test the learned image representations by fine-tuning a linear layer to perform ImageNet classification, a standard benchmark for measuring image understanding abilities. Our model outperforms previous generative models on the image understanding task, improving classification accuracy through linear probing (i.e., training a single linear classification layer, while keeping the rest of the model frozen) from 60.3% (iGPT-L) to 73.2%. These results showcase VIM’s strong generation results as well as image representation learning abilities.
Conclusion We propose Vector-quantized Image Modeling (VIM), which pretrains a Transformer to predict image tokens autoregressively, where discrete image tokens are produced from improved ViT-VQGAN image quantizers. With our proposed improvements on image quantization, we demonstrate superior results on both image generation and understanding. We hope our results can inspire future work towards more unified approaches for image generation and understanding.
Acknowledgements We would like to thank Xin Li, Han Zhang, Ruoming Pang, James Qin, Alexander Ku, Yuanzhong Xu, Jason Baldridge, Yonghui Wu for the preparation of the VIM paper. We thank Wei Han, Yuan Cao, Jiquan Ngiam, Vijay Vasudevan, Zhifeng Chen and Claire Cui for helpful discussions and feedback, and others on the Google Research and Brain Team for support throughout this project.
Let say I have an object detector from TF object detection API. Not much of customization can be done to the detector itself, but I want to add a branch on the detected images with LSTM to generate a description. Is there a way to do it in a single architecture? Or the only way is to train the detector and then train seperately the LSTM on detected images (2 stage)?

 Edge AI and high-performance computing are modernizing the electric grid, from power generation to transmission and distribution to the grid-edge.
Edge AI and high-performance computing are modernizing the electric grid, from power generation to transmission and distribution to the grid-edge.