
 AI-based applications demand entirely new tools and procedures to deploy and manage at the edge. Learn about the distinctive challenges associated with edge AI application deployment.
AI-based applications demand entirely new tools and procedures to deploy and manage at the edge. Learn about the distinctive challenges associated with edge AI application deployment.
Sign up for Edge AI News to stay up to date with the latest trends, customers use cases, and technical walkthroughs.
Nearly all enterprises today develop or adopt application software that codifies the processing of information such as invoices, human resource profiles, or product specifications. An entire industry has risen to deploy and execute these enterprise applications both in centralized data centers or clouds, as well as in edge locations such as stores, factories, and home appliances.
Recently, the nature of enterprise software has changed as developers now incorporate AI into their applications. According to Gartner, by 2027, machine learning in the form of deep learning will be included in over 65% of edge use cases, up from less than 10% in 2021*. With AI, you don’t need to codify the output for every possible input. Rather, AI models learn patterns from training data and then apply those patterns to new inputs.
Naturally, the processes required to manage AI-based applications differ from the management that has evolved for purely deterministic, code-based applications. This is true particularly for AI-based applications at the edge, where computing resources and network bandwidth are scarce, and where easy access to the devices poses security risks.
AI-based applications benefit from new tools and procedures to securely deploy, manage, and scale at the edge.
Differences between traditional enterprise software and AI applications at the edge
There are four fundamental differences between the way that traditional enterprise software and AI applications at the edge are designed and managed:
- Containerization
- Data strategy
- Updates
- Security
Containerization
Virtualization has been the primary deployment and management tool adopted by enterprises to deploy traditional applications in data centers around the world. For traditional applications and environments, virtualization provides structure, management, and security for these workloads to run on hypervisors.
While virtualization is still used in almost every data center, we are seeing widespread adoption of container technology for AI applications, especially at the edge. In a recent report on The State of Cloud Native Development, the Cloud Native Computing Foundation highlighted that “…developers working on edge computing have the highest usage for both containers and Kubernetes.” with 76% of edge AI applications using containers and 63% using Kubernetes.
Why are so many developers using containers for AI workloads at the edge?
- Performance
- Scalability
- Resiliency
- Portability
Performance
Containers virtualize a host operating system’s kernel, whereas in traditional virtualization, a hypervisor virtualizes physical hardware and creates guest operating systems in every instance. This allows containers to run with full bare-metal performance compared to near bare-metal performance. This is critical for many edge AI applications, especially those with safety-related use cases where response times are measured in sub-milliseconds.
Containers can also run multiple applications on the same system, providing consolidation without virtualization’s performance overhead.
Scalability
An edge AI “data center” may be distributed across hundreds of locations. Cloud-based management platforms give administrators the tools to centrally manage environments that can scale across hundreds and thousands of locations. Scaling by leveraging the network and intelligent software, as opposed to personnel traveling to every edge location, leads to reduced cost, higher efficiency, and resiliency.
Resiliency
AI applications usually provide resilience through scaling. Multiple clones of the same application run behind a load balancer, and service continues when a clone fails.
Even when an edge environment has a single node, container policies can ensure that the application automatically restarts for minimal downtime.
Portability
After an application is containerized, it can be deployed on any infrastructure whether on bare-metal, virtual machines, or various public clouds. They can also be scaled up or down as needed. With containers, applications can be run just as easily on a server at the edge as it can in any cloud.
Virtual machines and containers differ in several ways but are two methods of deploying multiple isolated services on a single platform. Many vendors supply solutions that work for both environments such as Red Hat OpenShift and VMware Tanzu.
Edge environments see both virtualization and containerization, but as more edge AI workloads are put into production, expect to see a move towards bare metal and containers.
Data strategy
The next difference is about the role of data in the lifecycle of traditional edge applications and edge AI applications.
Traditional edge applications commonly ingest small streams of structured data such as point-of-purchase sale transactions, patient medical records, or instructions. After being processed, the application sends back similar streams of structured information, such as payment authorizations, analytical results, or record searches. When it’s consumed, the data is no longer useful to the application.
Unlike traditional applications, AI applications have a lifecycle that spans beyond analysis and inference and includes re-training and ongoing updates. AI applications stream data from a sensor, often a camera, and make inferences on that data. A portion of the data is collected at the edge location and shared back to a centralized data center or cloud so that it can be used for retraining the application.
Due to this reliance on data to improve the application, a strong data strategy is critical.
The cost to transmit data from the edge to the data center or cloud is impacted by data size, network bandwidth, and how frequently the application needs to be updated. Here are some of the different data strategies that people employ with AI applications at the edge:
- Collect false inferences
- Collect all data
- Collect interesting data
Collect false inferences
At the very least, an organization should collect all incorrect inferences. When an AI makes an incorrect inference, the data needs to be identified, relabeled, and used for retraining to improve model accuracy.
However, if only false inferences are used for retraining, models will likely experience a phenomenon called model drift.
Collect all data
Organizations that opt to send all of their data to a central repository are often in situations where bandwidth and latency are not limiting factors. These organizations use the data to re-train or adjust and build new models. Or they might use it for batch data processing to glean different insights.
The benefit of collecting all data are the enormous pools of data to leverage. The downside is that it is incredibly costly. Often, it’s not even feasible to move that much data.
Collect interesting data
This is the sweet spot for data collection as it balances the need for valuable data with the cost of transmitting and storing that data.
Interesting data can encompass any data that an organization anticipates to be valuable to their current or future models or data analytics projects. For example, with self driving cars, most of the data collected from the same streets with similar weather would not drastically change the training of a model. However, if it was snowing, that data would be useful to send back to a central repository as it could improve the model for driving during extreme weather.
Updates
The functional content of traditional edge software is delivered through code. Developers write and compile sequences of instructions that execute on edge devices. Any management and orchestration platform must accommodate updates to the software to fix defects, add functionality, and remediate vulnerabilities.
Development teams most commonly release new code each month, quarter, or year, but not every new release is immediately pushed to edge systems. Instead, IT teams tend to wait for a critical mass of updates and do a more substantial update only when necessary.
In contrast, edge AI applications follow a different software lifecycle that centers on the training and retraining of the AI model. Every model update has the potential to improve accuracy and precision or increase or adjust functionality. The more frequently a model is updated, the more accurate it becomes, providing additional value to the organization.
For example, if an inspection AI application goes from 75% to 80% accuracy, that organization would see fewer defects missed, leading to improved product quality. Additionally, fewer false positives result in less wasted product.
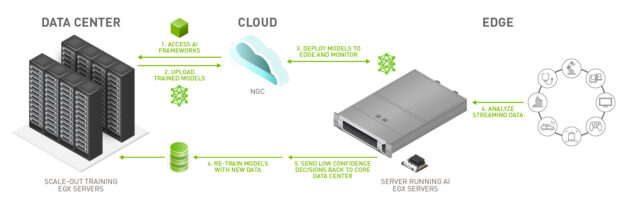
In Figure 1, steps 5 and 6 detail the retraining process, which is critical for updating models.
Frequent model updates should be anticipated by organizations that are deploying an edge AI solution. By building retraining processes from the start through cloud-native deployment practices such as containers and implementing strong data strategies, organizations can develop sustainable edge AI solutions.
Security
Edge computing represents a dramatic shift in the security paradigm for many IT teams. In the castle-and-moat network security model, nobody outside of the network is able to access data on the inside but everyone inside the network can. In contrast, edge environments are inherently unsafe because almost everyone has physical access.
Edge AI applications exacerbate this issue, as they are built using highly valuable corporate intellectual property, which is the lifeline of a business. It represents the competitive advantage that allows for a business’s differentiation and is core to its function.
While security is important for all applications, it is important to increase security at the edge when working with AI applications. For more information, see Edge Computing: Considerations for Security Architects.
- Physical security
- Data privacy
- Corporate intellectual property
- Access controls
Physical security
Because edge devices are located outside of a physical data center, edge computing sites must be designed with the assumption that malicious actors can get physical access to a machine. To combat this, technologies such as physical tamper detection and secure boot can be put in place as additional security checks.
Data privacy
Edge AI applications often store real-world data such as voice and imagery that convey highly private information about people’s lives and identities. Edge AI developers carry the burden of protecting such private data troves to preserve their users’ trust and to comply with regulations.
Corporate intellectual property
Inference engines incorporate the learning of massive, proprietary data and the expertise and work of machine learning teams. Losing control of these inference engines to a competitor could greatly impair a company’s competitiveness in the market.
Access controls
Due to the distributed nature of these environments, it is almost guaranteed that someone will need to access them remotely. Just-in-time (JIT) access is a policy used to ensure that a person is granted the least amount of privilege needed to complete a task for a limited amount of time.
Designing edge AI environments
As enterprises shift from deploying traditional enterprise applications to AI applications at the edge, maintaining the same infrastructure that supported traditional applications is not a scalable solution.
For a successful edge AI application, updating your organization’s deployment methodology, data strategy, update cadence, and security policies is incredibly important.
NVIDIA offers software to help organizations develop, deploy, and manage their AI applications wherever they are located.
For example, to help organizations manage and deploy multiple AI workloads across distributed locations we created NVIDIA Fleet Command, a managed platform for container orchestration that streamlines the provisioning and deployment of systems and AI applications at the edge.
To help organizations get started quickly, we created NVIDIA LaunchPad, a free program that provides immediate, short-term access to the necessary hardware and software stacks to experience end-to-end solution workflows such as building and deploying an AI application.
Want to get experience deploying and managing an edge AI application? Register for a free LaunchPad experience today!