
 NVIDIA Math Libraries are available to boost your application’s performance, from GPU-accelerated implementations of BLAS to random number generation.
NVIDIA Math Libraries are available to boost your application’s performance, from GPU-accelerated implementations of BLAS to random number generation.
There are three main ways to accelerate GPU applications: compiler directives, programming languages, and preprogrammed libraries. Compiler directives such as OpenACC aIlow you to smoothly port your code to the GPU for acceleration with a directive-based programming model. While it is simple to use, it may not provide optimal performance in certain scenarios.
Programming languages such as CUDA C and C++ give you greater flexibility when accelerating your applications, but it is also the user’s responsibility to write code that takes advantage of new hardware features to achieve optimal performance on the latest hardware. This is where preprogrammed libraries fill in the gap.
In addition to enhancing code reusability, the NVIDIA Math Libraries are optimized to make best use of GPU hardware for the greatest performance gain. If you’re looking for a straightforward way to speed up your application, continue reading to learn about using libraries to improve your application’s performance.
The NVIDIA math libraries, available as part of the CUDA Toolkit and the high-performance computing (HPC) software development kit (SDK), offer high-quality implementations of functions encountered in a wide range of compute-intensive applications. These applications include the domains of machine learning, deep learning, molecular dynamics, computational fluid dynamics (CFD), computational chemistry, medical imaging, and seismic exploration.
These libraries are designed to replace the common CPU libraries such as OpenBLAS, LAPACK, and Intel MKL, as well as accelerate applications on NVIDIA GPUs with minimal code changes. To show the process, we created an example of the double precision general matrix multiplication (DGEMM) functionality to compare the performance of cuBLAS with OpenBLAS.
The code example below demonstrates the use of the OpenBLAS DGEMM call.
// Init Data
…
// Execute GEMM
cblas_dgemm(CblasColMajor, CblasNoTrans, CblasTrans, m, n, k, alpha, A.data(), lda, B.data(), ldb, beta, C.data(), ldc);
Code example 2 below shows the cuBLAS dgemm call.
// Init Data
…
// Data movement to GPU
…
// Execute GEMM
cublasDgemm(cublasH, CUBLAS_OP_N, CUBLAS_OP_T, m, n, k, &alpha, d_A, lda, d_B, ldb, &beta, d_C, ldc));
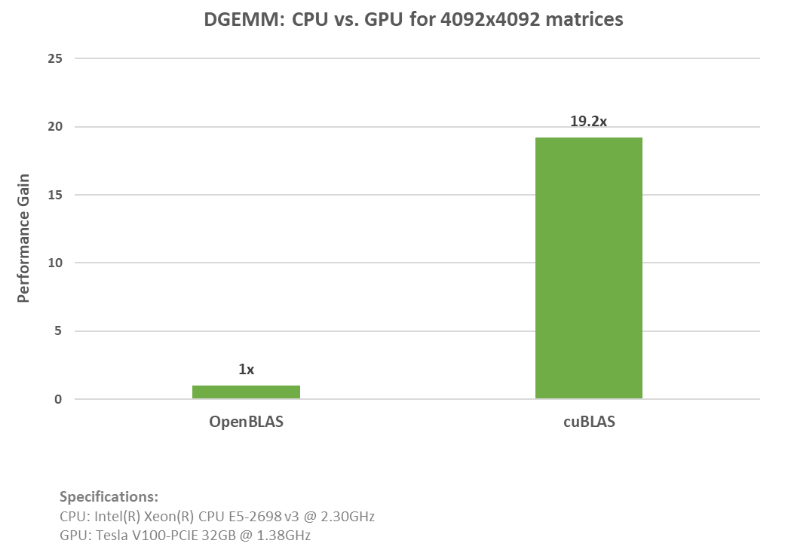
As shown in the example above, you can simply add and replace the OpenBLAS CPU code with the cuBLAS API functions. See the full code for both the cuBLAS and OpenBLAS examples. This cuBLAS example was run on an NVIDIA(R) V100 Tensor Core GPU with a nearly 20x speed-up. The graph below displays the speedup and specs when running these examples.
Fun fact: These libraries are invoked in the higher-level Python APIs such as cuPy, cuDNN and RAPIDS, so if you have experience with those, then you have already been using these NVIDIA Math Libraries.
The remainder of this post covers all of the math libraries available. For the latest updates and information, watch Recent Developments in NVIDIA Math Libraries.
Delivering better performance compared to CPU-only alternatives
There are many NVIDIA Math Libraries to take advantage of, from GPU-accelerated implementations of BLAS to random number generation. Take a look below at an overview of the NVIDIA Math Libraries and learn how to get started to easily boost your application’s performance.
Speed up Basic Linear Algebra Subprograms with cuBLAS
General Matrix Multiplication (GEMM) is one of the most popular Basic Linear Algebra Subprograms (BLAS) deployed in AI and scientific computing. GEMMs also form the foundational blocks for deep learning frameworks. To learn more about the use of GEMMs in deep learning frameworks, see Why GEMM Is at the Heart of Deep Learning.
The cuBLAS Library is an implementation of BLAS which leverages GPU capabilities to achieve great speed-ups. It comprises routines for performing vector and matrix operations such as dot products (Level 1), vector addition (Level 2), and matrix multiplication (Level 3).
Additionally, if you would like to parallelize your matrix-matrix multiplies, cuBLAS supports the versatile batched GEMMs which finds use in tensor computations, machine learning, and LAPACK. For more details about improving efficiency in machine learning and tensor contractions, see Tensor Contractions with Extended BLAS Kernels on CPU and GPU.
cuBLASXt
If the problem size is too big to fit on the GPU, or your application needs single-node, multi-GPU support, cuBLASXt is a great option. cuBLASXt allows for hybrid CPU-GPU computation and supports BLAS Level 3 operations that perform matrix-to-matrix operations such as herk which performs the Hermitian rank update.
cuBLASLt
cuBLASLt is a lightweight library that covers GEMM. cuBLASLt uses fused kernels to speed up applications by “combining” two or more kernels into a single kernel which allows for reuse of data and reduced data movement. cuBLASLt also allows users to set the post-processing options for the epilogue (apply Bias and then ReLU transform or apply bias gradient to an input matrix).
cuBLASMg: CUDA Math Library Early Access Program
For large-scale problems, check out cuBLASMg for state-of-the-art multi-GPU, multi-node matrix-matrix multiplication support. It is currently a part of the CUDA Math Library Early Access Program. Apply for access.
Process sparse matrices with cuSPARSE
Sparse-matrix, dense-matrix multiplication (SpMM) is fundamental to many complex algorithms in machine learning, deep learning, CFD, and seismic exploration, as well as economic, graph, and data analytics. Efficiently processing sparse matrices is critical to many scientific simulations.
The growing size of neural networks and the associated increase in cost and resources incurred has led to the need for sparsification. Sparsity has gained popularity in the context of both deep learning training and inference to optimize the use of resources. For more insight into this school of thought and the need for a library such as cuSPARSE, see The Future of Sparsity in Deep Neural Networks.
cuSPARSE provides a set of basic linear algebra subprograms used for handling sparse matrices which can be used to build GPU-accelerated solvers. There are four categories of the library routines:
- Level 1 operates between a sparse vector and dense vector, such as the dot product between two vectors.
- Level 2 operates between a sparse matrix and a dense vector, such as a matrix-vector product.
- Level 3 operates between a sparse matrix and a set of dense vectors, such as a matrix-matrix product).
- Level 4 allows conversion between different matrix formats and compression of compressed sparse row (CSR) matrices.
cuSPARSELt
For a lightweight version of the cuSPARSE library with compute capabilities to perform sparse matrix-dense matrix multiplication along with helper functions for pruning and compression of matrices, try cuSPARSELt. For a better understanding of the cuSPARSELt library, see Exploiting NVIDIA Ampere Structured Sparsity with cuSPARSELt.
Accelerate tensor applications with cuTENSOR
The cuTENSOR library is a tensor linear algebra library implementation. Tensors are core to machine learning applications and are an essential mathematical tool used to derive the governing equations for applied problems. cuTENSOR provides routines for direct tensor contractions, tensor reductions, and element-wise tensor operations. cuTENSOR is used to improve performance in deep learning training and inference, computer vision, quantum chemistry, and computational physics applications.
cuTENSORMg
If you still want cuTENSOR features, but with support for large tensors that can be distributed across multi-GPUs in a single node such as with the DGX A100, cuTENSORMg is the library of choice. It provides broad mixed-precision support, and its main computational routines include direct tensor contractions, tensor reductions, and element-wise tensor operations.
GPU-accelerated LAPACK features with cuSOLVER
The cuSOLVER library is a high-level package useful for linear algebra functions based on the cuBLAS and cuSPARSE libraries. cuSOLVER provides LAPACK-like features, such as matrix factorization, triangular solve routines for dense matrices, a sparse least-squares solver, and an eigenvalue solver.
There are three separate components of cuSOLVER:
- cuSolverDN is used for dense matrix factorization.
- cuSolverSP provides a set of sparse routines based on sparse QR factorization.
- cuSolverRF is a sparse re-factorization package, useful for solving sequences of matrices with a shared sparsity pattern.
cuSOLVERMg
For GPU-accelerated ScaLAPACK features, a symmetric eigensolver, 1-D column block cyclic layout support, and single-node, multi-GPU support for cuSOLVER features, consider cuSOLVERMg.
cuSOLVERMp
Multi-node, multi-GPU support is needed for solving large systems of linear equations. Known for its lower-upper factorization and Cholesky factorization features, cuSOLVERMp is a great solution.
Large-scale generation of random numbers with cuRAND
The cuRAND library focuses on the generation of random numbers through pseudo-random or quasi-random number generators on either the host (CPU) API or a device (GPU) API. The host API can generate random numbers purely on the host and store them in host memory, or they can be generated on the device where the calls to the library happen on the host, but the random number generation occurs on the device and is stored to global memory.
The device API defines functions for setting up random number generator states and generating sequences of random numbers which can be immediately used by user kernels without having to read and write to global memory. Several physics-based problems have shown the need for large-scale random number generation.
Monte Carlo simulation is one such use case for random number generators on the GPU. The Development of GPU-Based Parallel PRNG for Monte Carlo Applications in CUDA Fortran highlights the application of cuRAND in large-scale generation of random numbers.
Calculate fast Fourier transforms with cuFFT
cuFFT, the CUDA Fast Fourier Transform (FFT) library provides a simple interface for computing FFTs on an NVIDIA GPU. The FFT is a divide-and-conquer algorithm for efficiently computing discrete Fourier transforms of complex or real-valued data sets. It is one of the most widely used numerical algorithms in computational physics and general signal processing.
cuFFT can be used for a wide range of applications, including medical imaging and fluid dynamics. Parallel Computing for Quantitative Blood Flow Imaging in Photoacoustic Microscopy illustrates the use of cuFFT in physics-based applications. Users with existing FFTW applications should use cuFFTW to easily port code to NVIDIA GPUs with minimal effort. The cuFFTW library provides the FFTW3 API to facilitate porting of existing FFTW applications.
cuFFTXt
To distribute FFT calculations across GPUs in a single node, check out cuFFTXt. This library includes functions to help users manipulate data on multiple GPUs and keep track of data ordering, which allows data to be processed in the most efficient way possible.
cuFFTMp
Not only is there multi-GPU support within a single system, cuFFTMp provides support for multi-GPUs across multiple nodes. This library can be used with any MPI application since it is independent of the quality of MPI implementation. It uses NVSHMEM which is a communication library based on OpenSHMEM standards that was designed for NVIDIA GPUs.
cuFFTDx
To improve performance by avoiding unnecessary trips to global memory and allowing fusion of FFT kernels with other operations, check out cuFFT device extensions (cuFFTDx) . Part of the Math Libraries Device Extensions, it allows applications to compute FFTs inside user kernels.
Optimize standard mathematical functions with CUDA Math API
The CUDA Math API is a collection of standard mathematical functions optimized for every NVIDIA GPU architecture. All of the CUDA libraries rely on the CUDA Math Library. CUDA Math API supports all C99 standard float and double math functions, float, double, and all rounding modes, and different functions such as trigonometry and exponential functions ( cospi, sincos) and additional inverse error functions (erfinv, erfcinv).
Customize code using C++ templates with CUTLASS
Matrix multiplications are the foundation of many scientific computations. These multiplications are particularly important in efficient implementation of deep learning algorithms. Similar to cuBLAS, CUDA Templates for Linear Algebra Subroutines (CUTLASS) comprises a set of linear algebra routines to carry out efficient computation and scaling.
It incorporates strategies for hierarchical decomposition and data movement similar to those used to implement cuBLAS and cuDNN. However, unlike cuBLAS, CUTLASS is increasingly modularized and reconfigurable. It decomposes the moving parts of GEMM into fundamental components or blocks available as C++ template classes, thereby giving you flexibility to customize your algorithms.
The software is pipelined to hide latency and maximize data reuse. Access shared memory without conflict to maximize your data throughput, eliminate memory footprints, and design your application exactly the way you want. To learn more about using CUTLASS to improve the performance of your application, see CUTLASS: Fast Linear Algebra in CUDA C++.
Compute differential equations with AmgX
AmgX provides a GPU-accelerated AMG (algebraic multi-grid) library and is supported on a single GPU or multi-GPUs on distributed nodes. It allows users to create complex nested solvers, smoothers, and preconditioners. This library implements classical and aggregation-based algebraic multigrid methods with different smoothers such as block-Jacobi, Gauss-Seidel, and dense LU.
This library also contains preconditioned Krylov subspace iterative methods such as PCG and BICGStab. AmgX provides up to 10x acceleration to the computationally intense linear solver portion of simulations and is well-suited for implicit unstructured methods.
AmgX was specifically developed for CFD applications and can be used in domains such as energy, physics, and nuclear safety. A real-life example of the AmgX library is in solving the Poisson Equation for small-scale to large-scale computing problems.
The flying snake simulation example shows the reduction in time and cost incurred when using the AmgX wrapper on GPUs to accelerate CFD codes. There is a 21x speed-up with 3 million mesh points on one K20 GPU when compared to one 12-core CPU node.
Get started with NVIDIA Math Libraries
- cuBLAS, cuRAND, cuFFT, cuSPARSE, cuSOLVER, and the CUDA Math Library are included in both the NVIDIA HPC SDK and the CUDA Toolkit
- The Math Library Device Extensions (cuFFTDx) are available in MathDx 20.22
- cuTENSOR, cuSPARSELt, and MathDx can be found on DevZone
- AmgX and CUTLASS are available on GitHub
- cuBLASMg is currently a part of the CUDA Math Library Early Access Program
We continue working to improve the NVIDIA Math Libraries. If you have questions or a new feature request, contact Product Manager Matthew Nicely.
Acknowledgements
We would like to thank Matthew Nicely for his guidance and active feedback. A special thank you to Anita Weemaes for all her feedback and her continued support throughout.