
 NVIDIA is partnering with IronYun to leverage the capabilities of edge AI to help make the world a smarter, safer, more efficient place.
NVIDIA is partnering with IronYun to leverage the capabilities of edge AI to help make the world a smarter, safer, more efficient place.
Nearly every organization is enticed by the ability to use cameras to understand their businesses better. Approximately 1 billion video cameras—the ultimate Internet of Things (IoT) sensors—are being used to help people around the world live better and safer.
But, there is a clear barrier to success. Putting the valuable data collected by these cameras to use requires significant human effort. The time-consuming process of manually reviewing massive amounts of footage is arduous and costly. Moreover, after the review is complete, much of the footage is either thrown out or stowed away in the cloud and never used again.
This leads to vast amounts of valuable data never being used to its full potential.
Luckily, thanks to advancements in AI and edge computing, organizations can now layer AI analytics directly onto their existing camera infrastructures to expand the value of video footage captured. By adding intelligence to the equation, organizations can transform physical environments into safer, smarter spaces with AI-powered video analytics systems.
Edge AI in action
This change is already helping companies in many industries improve customer experiences, enhance safety, drive accountability, and deliver operational efficiency. The possibilities for expanding these smart spaces and reaping even greater benefits are vast.
In the retail space, an AI-powered smart store can elevate the consumer shopping experience by using heat maps to improve customer traffic flow, accurately forecast product demand, and optimize supply chain logistics. Ultimately, these smart stores could completely transform retail as we know it and use cameras to create “just walk out” shopping experiences, with no cash registers required.
At electrical substations, intelligent video analytics is streamlining asset inspection and ensuring site safety and security. AI-powered analysis of real-time video streaming provides continuous monitoring of substation perimeters. This can be used to prevent unauthorized access, ensure technicians and engineers follow health and safety protocols, and detect dangerous environmental conditions like smoke and fire.
Creating a smart space
At the forefront of this smart space revolution is the AI vision company and NVIDIA Metropolis partner IronYun. The IronYun AI platform, Vaidio, is helping retailers, banks, NFL stadiums, factories, and more fuel their existing cameras with the power of AI.
NVIDIA and IronYun are working to leverage the capabilities of edge AI and help make the world a smarter, safer, more efficient place.
A smart space is more than simply a physical location equipped with cameras. To be truly smart, these spaces must take collected data to generate critical insights that create superior experiences.
According to IronYun, most organizations today use cameras to improve safety in their operations. The IronYun Vaidio platform extends beyond basic security applications and supports dozens of advanced AI-powered video analytics capabilities specific to each customer. From video search to heat map creation and detection for PPE, IronYun is helping organizations across all industries take their business to the next level with AI through a single platform.
How does this look in the real world? An NFL stadium that hosts 65,000 fans at every game uses Vaidio in interesting ways. The customer first approached IronYun in hopes of improving safety and security operations at the stadium. Once they saw Vaidio analytics in action, they realized they could leverage the same advanced platform to monitor and alert security of smoke, fire, falls, and fights, as well as detect crowd patterns.
IronYun CEO, Paul Sun says, “The tedious task of combing through hours of video footage can take days or weeks to complete. Using Vaidio’s AI video analytics, that same forensic video search can be done in seconds.”
Powering smart spaces across the world
Edge AI is the technology that is making smart spaces possible for organizations to mobilize data being produced at the edge.
The edge is simply a location, named for the way AI computation is done near or at the edge of a network rather than centrally in a cloud computing facility or private data center. Without the low latency and speed provided by the edge, many security and data gathering applications would not be effective or possible.
Sun says, “When you are talking about use cases to ensure safety like weapons detection or smoke and fire detection, instantaneous processing at the edge can accelerate alert and response times, especially relative to camera-based alternatives.”
Building the future
With the powerful capabilities of NVIDIA Metropolis, NVIDIA Fleet Command, and NVIDIA Certified-Systems IronYun applies AI analytics to help make the world safer and smarter,
The NVIDIA Metropolis platform offers IronYun the development tools and services to reduce the time and cost of developing their vision AI deployments. This is a key factor in their ability to bring multiple new and accurate AI-powered video analytics to the Vaidio platform every year.
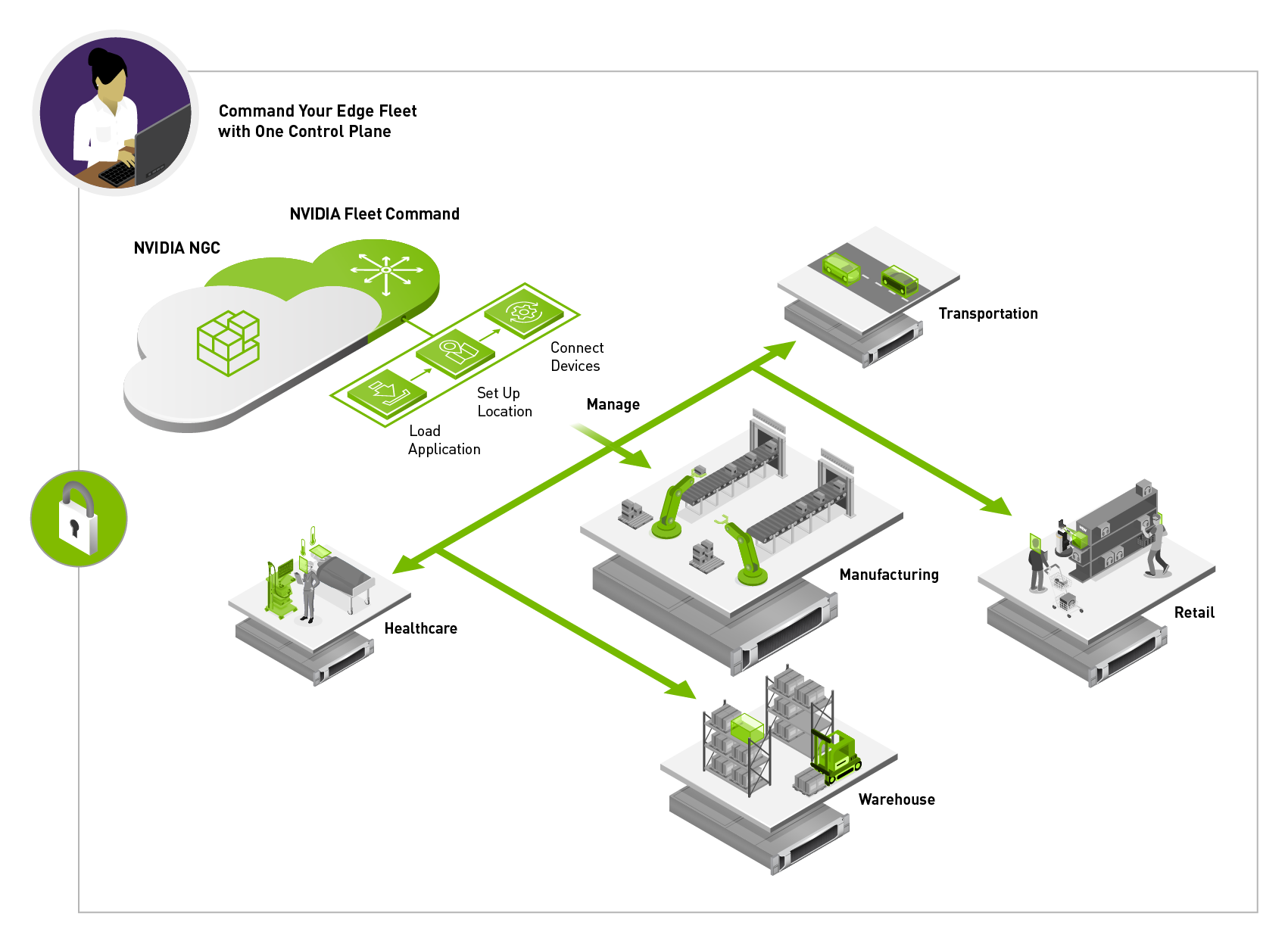
NVIDIA Fleet Command is also an essential component of the Vaidio platform, equipping IT administrators with secure, remote access to all of their systems.
Fleet Command eliminates the need for IT teams to be on call 24/7 when a system experiences a bug or issue. Instead, they can troubleshoot and manage emergencies from the comfort of their office.
The Fleet Command dashboard sits in the cloud and provides administrators a control plane to deploy applications, alerts and analytics. It also provides provisioning and monitoring capabilities, user management control, and other features needed for day-to-day management of the lifecycle of an AI application.
The dashboard also has a private registry where organizations can securely store their own custom application or a partner application, such as IronYun’s Vaidio platform for deployment at any location.
“With NVIDIA Fleet Command, we are able to scale our vision applications from one or two cameras in a POC, to thousands of cameras in a production deployment. By simplifying the management of edge environments, and improving video analytics accuracy at scale, our customer environments indeed become safer and smarter,” says Sun.
Explore the countless possibilities this new generation of AI applications is powering, from operational efficiency to safety for city streets, airports, factory floors, and more.
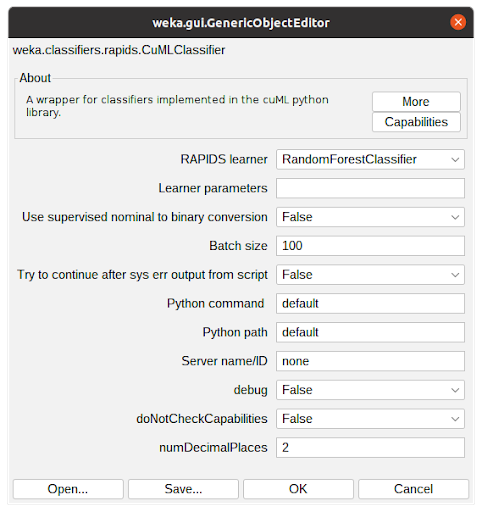
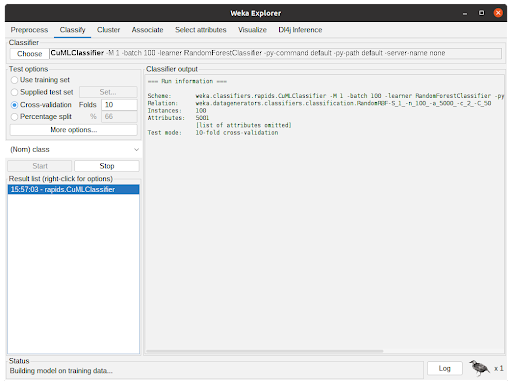
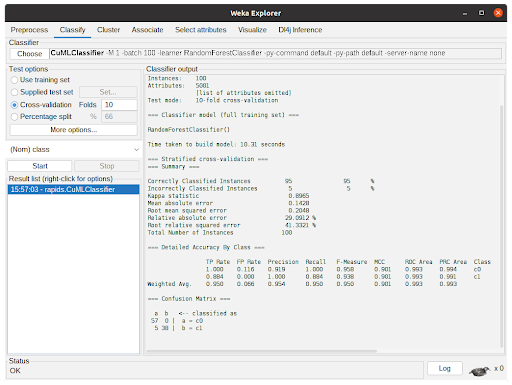
 Accelerated WEKA integrates the WEKA workbench with Python and Java libraries that support GPU to speedup the training and prediction time of machine learning models.
Accelerated WEKA integrates the WEKA workbench with Python and Java libraries that support GPU to speedup the training and prediction time of machine learning models.
 Create a compact desktop cluster with four NVIDIA Jetson Xavier NX modules to accelerate training and inference of AI and deep learning workflows.
Create a compact desktop cluster with four NVIDIA Jetson Xavier NX modules to accelerate training and inference of AI and deep learning workflows.

") Leading security, storage, and networking vendors are joining the DOCA and DPU community.
Leading security, storage, and networking vendors are joining the DOCA and DPU community.