
 Imagine driving along a road and an obstacle suddenly appears in your path. How quickly can you react to it? How does your reaction speed change with the time…
Imagine driving along a road and an obstacle suddenly appears in your path. How quickly can you react to it? How does your reaction speed change with the time…
Imagine driving along a road and an obstacle suddenly appears in your path. How quickly can you react to it? How does your reaction speed change with the time of day, the color of the obstacle, and where it appears in your field of view?
The ability to react quickly to visual events is valuable to everyday life. It is also a fundamental skill in fast-paced video games. A recent collaboration between researchers from NVIDIA, NYU, and Princeton—winner of a SIGGRAPH 2022 Technical Paper Award—explores the relationship between image features and the time it takes for an observer to react.
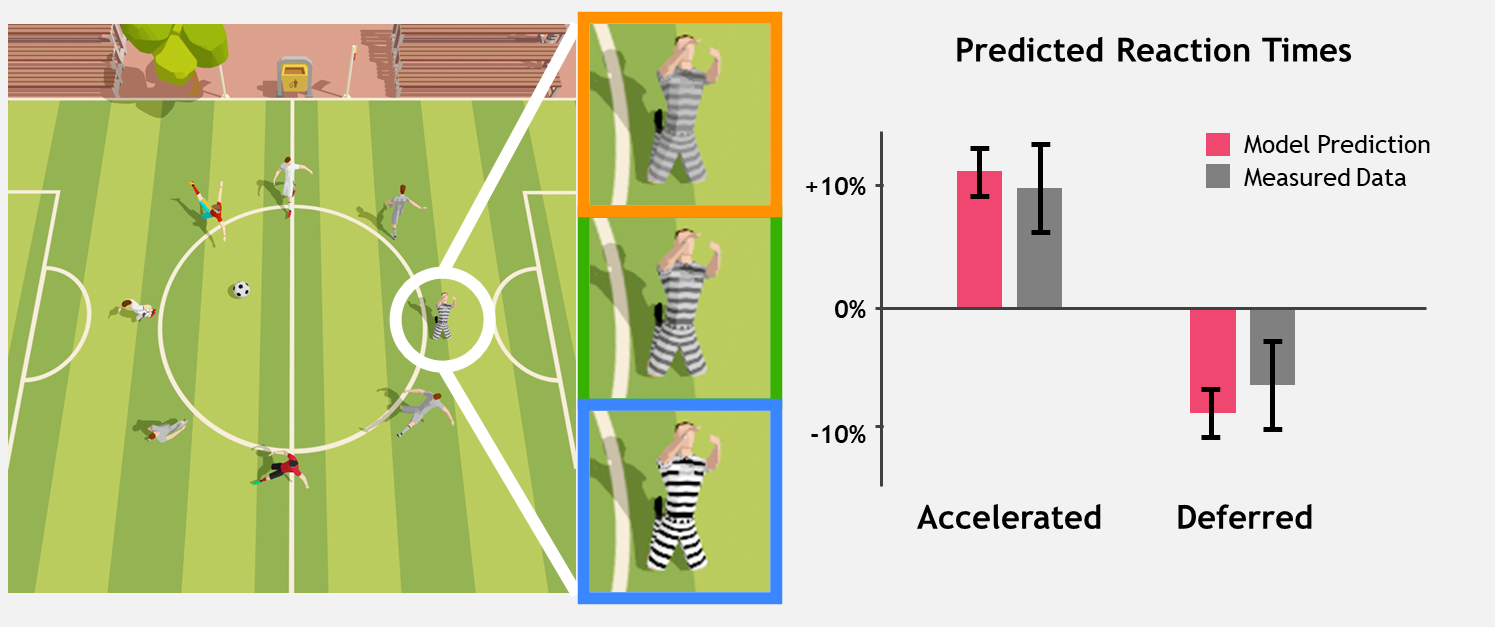
Reaction speed and visual events
With so many recent advances in display technology, human reaction times have become a primary bottleneck in the graphics pipeline. Response times for communicating with remote servers, rendering and displaying images, and collecting and processing mouse or keyboard input are all typically tens of milliseconds or less.
By contrast, the pipeline for human perception is much slower, and can range from 100 to 500 milliseconds depending on the complexity of the visual input. This research aims to simplify and optimize images to reduce our reaction time as much as possible.
Visual contrast and spatial frequency are well-known features that influence low-level vision. Further, human vision is not uniform over the entire field of view. The amount of contrast needed to boost reaction time varies depending on eccentricity, or visual angle (where an object is located relative to center gaze) and spatial frequency (whether an object is a solid color or a complex pattern, for example). Reaction time is a combination of many neural processes, and the proposed model includes all of these factors.
Reaction time measurements are based on the onset latency of voluntary rapid eye movements called saccades. The “reaction time clock” starts ticking as soon as the target appears on the screen. Once the target is identified, a saccade is initiated towards it.
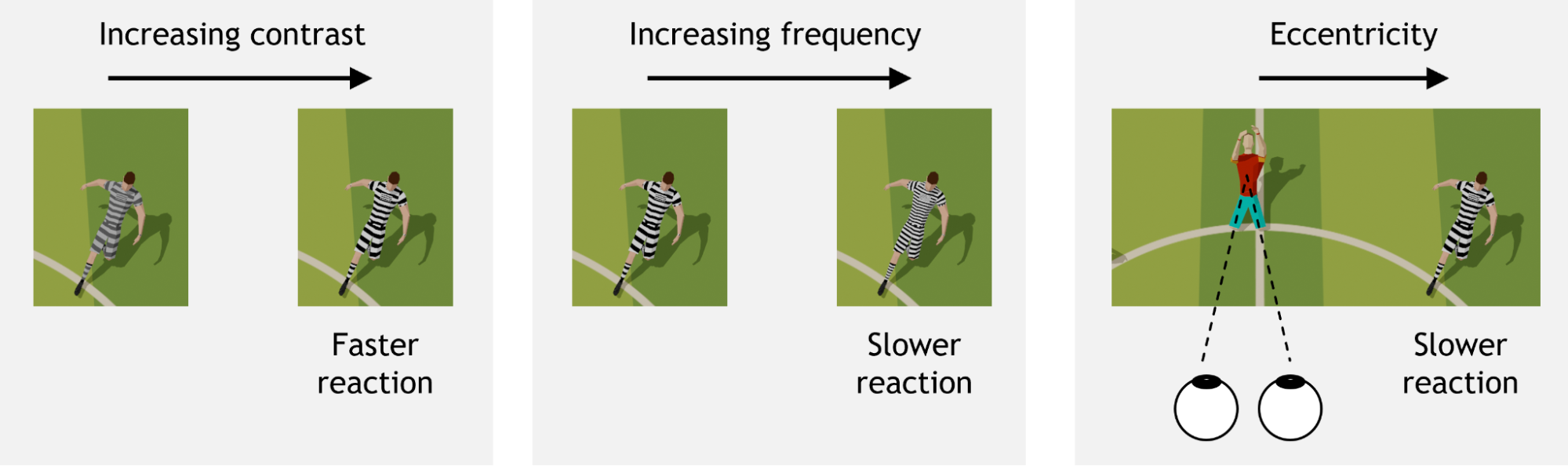
Modeling saccadic reaction
To build a perceptually accurate model for reaction time prediction, researchers conducted a series of experiments with human observers, collecting over 11,000 reaction times for varying image features.
Inspired by how the human brain perceives information and makes decisions, the researchers designed a model for reaction time prediction, accounting for contrast, frequency, and eccentricity, as well as the inherent randomness in human reaction speed.
In this model, a measure of “decision confidence” is accumulated over time, and once enough confidence has been accumulated, a saccade is made. The rate at which confidence accumulates over time is inconsistent, as shown in the video below.
Hence, instead of predicting a single reaction time with full certainty, the model provides a likelihood of exhibiting various reaction times. The average rate of confidence accumulation is influenced by image features and results in a change in the likelihood of reaction times, as shown in the video below.
Two validation experiments confirm that this model can be applied to images that might be seen, including video games and natural photographs.
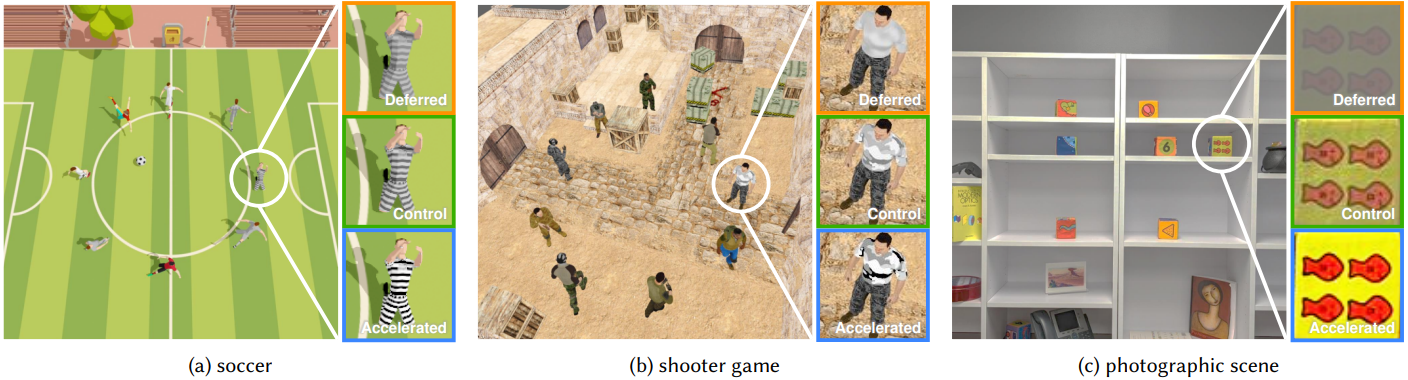
Using reaction time prediction to optimize human performance
Applications for this saccadic reaction time model include, for example, a smart drive-assist system estimating whether a driver can safely react to pedestrians and other vehicles, and turn on appropriate assistance features. Similarly, e-sports game designers can use this model to understand the fairness of their game’s visual design, avoiding bias in competitive outcomes.
Ambitious gamers can also use this model to fine-tune their setup for maximum performance–by choosing an optimal skin for the target 3D object, for example.
In future work, the research team plans to explore how other image features like color and temporal effects influence human reaction time, and how to train humans to increase the speed at which they react to on-screen or real-world events.
For more details, read the paper, Image Features Influence Reaction Time: A Learned Probabilistic Perceptual Model for Saccade Latency. You can also visit the gaze-timing project on GitHub.
The paper’s authors, Budmonde Duinkharjav, Praneeth Chakravarthula, Rachel Brown, Anjul Patney, and Qi Sun will present this work at SIGGRAPH 2022 on August 11 in Vancouver, British Columbia.