Today, NVIDIA announced the Jetson Orin Nano series of system-on-modules (SoMs). They deliver up to 80X the AI performance of NVIDIA Jetson Nano and set the new…
Today, NVIDIA announced the Jetson Orin Nano series of system-on-modules (SoMs). They deliver up to 80X the AI performance of NVIDIA Jetson Nano and set the new…
Today, NVIDIA announced the Jetson Orin Nano series of system-on-modules (SoMs). They deliver up to 80X the AI performance of NVIDIA Jetson Nano and set the new standard for entry-level edge AI and robotics applications.
For the first time, the Jetson family now includes NVIDIA Orin-based modules that span from the entry-level Jetson Orin Nano to the highest-performance Jetson AGX Orin. This gives customers the flexibility to scale their applications easily.
Jump-start your Jetson Orin Nano development today with full software emulation support provided by the Jetson AGX Orin Developer Kit.
The need for increased real-time processing capability continues to grow for everyday use cases across industries. Entry-level AI applications like smart cameras, handheld devices, service robots, intelligent drones, smart meters, and more all face similar challenges.
These applications require more low-latency processing on-device for the data flowing from their multimodal sensor pipelines while keeping within the constraints of a power-efficient, cost-optimized small form factor.
Jetson Orin Nano series
Jetson Orin Nano series production modules will be available in January starting at $199. The modules deliver up to 40 TOPS of AI performance in the smallest Jetson form-factor, with power options as little as 5W and up to 15W. The series comes with two different versions: Jetson Orin Nano 4GB and Jetson Orin Nano 8GB.

*NVIDIA Orin Architecture from Jetson Orin Nano 8GB, Jetson Orin Nano 4GB has 2 TPCs and 4 SMs.
As shown in Figure 1, Jetson Orin Nano showcases the NVIDIA Orin architecture with an NVIDIA Ampere Architecture GPU. It has up to eight streaming multiprocessors (SMs) composed of 1024 CUDA cores and up to 32 Tensor Cores for AI processing.
The NVIDIA Ampere Architecture third-generation Tensor Cores deliver better performance per watt than the previous generation and bring more performance with support for sparsity. With sparsity, you can take advantage of the fine-grained structured sparsity in deep learning networks to double the throughput for Tensor Core operations.
To accelerate all parts of your application pipeline, Jetson Orin Nano also includes a 6-core Arm Cortex-A78AE CPU, video decode engine, ISP, video image compositor, audio processing engine, and video input block.
Within its small, 70x45mm 260-pin SODIMM footprint, the Jetson Orin Nano modules include various high-speed interfaces:
- Up to seven lanes of PCIe Gen3
- Three high-speed 10-Gbps USB 3.2 Gen2 ports
- Eight lanes of MIPI CSI-2 camera ports
- Various sensor I/O
To reduce your engineering effort, we’ve made the Jetson Orin Nano and Jetson Orin NX modules completely pin– and form-factor–compatible. Table 1 shows the differences between the Jetson Orin Nano 4GB and the Jetson Orin Nano 8GB.
| Jetson Orin Nano 4GB | Jetson Orin Nano 8GB | |
| AI Performance | 20 Sparse TOPs | 10 Dense TOPs | 40 Sparse TOPs | 20 Dense TOPs |
| GPU | 512-core NVIDIA Ampere Architecture GPU with 16 Tensor Cores | 1024-core NVIDIA Ampere Architecture GPU with 32 Tensor Cores |
| GPU Max Frequency | 625 MHz | |
| CPU | 6-core Arm Cortex-A78AE v8.2 64-bit CPU 1.5 MB L2 + 4 MB L3 | |
| CPU Max Frequency | 1.5 GHz | |
| Memory | 4GB 64-bit LPDDR5 34 GB/s | 8GB 128-bit LPDDR5 68 GB/s |
| Storage | – (Supports external NVMe) |
|
| Video Encode | 1080p30 supported by 1-2 CPU cores | |
| Video Decode | 1x 4K60 (H.265) | 2x 4K30 (H.265) | 5x 1080p60 (H.265) | 11x 1080p30 (H.265) | |
| Camera | Up to 4 cameras (8 through virtual channels*) 8 lanes MIPI CSI-2 D-PHY 2.1 (up to 20 Gbps) | |
| PCIe | 1 x4 + 3 x1 (PCIe Gen3, Root Port, & Endpoint) | |
| USB | 3x USB 3.2 Gen2 (10 Gbps) 3x USB 2.0 | |
| Networking | 1x GbE | |
| Display | 1x 4K30 multimode DisplayPort 1.2 (+MST)/e DisplayPort 1.4/HDMI 1.4* | |
| Other I/O | 3x UART, 2x SPI, 2x I2S, 4x I2C, 1x CAN, DMIC and DSPK, PWM, GPIOs | |
| Power | 5W – 10W | 7W – 15W |
| Mechanical | 69.6 mm x 45 mm 260-pin SO-DIMM connector | |
| Price | $199† | $299† |
* For more information about additional compatibility to DisplayPort 1.4a and HDMI 2.1 and virtual channels, see the Jetson Orin Nano series data sheet.
† 1KU Volume
For more information about supported features, see the Software Features section of the latest NVIDIA Jetson Linux Developer Guide.
Start your development today using the Jetson AGX Orin Developer Kit and emulation
The Jetson AGX Orin Developer Kit and all the Jetson Orin modules share one SoC architecture, enabling the developer kit to emulate any of the modules and make it easy for you to start developing your next product today.
You don’t have to wait for the Jetson Orin Nano hardware to be available before starting to port their applications to the new NVIDIA Orin architecture and latest NVIDIA JetPack. With the new overlay released today, you can emulate the Jetson Orin Nano modules with the developer kit, just as with the other Jetson Orin modules. With the developer kit configured to emulate Jetson Orin Nano 8GB or Jetson Orin Nano 4GB, you can develop and run your full application pipeline.

Performance benchmarks with Jetson Orin Nano
With Jetson AGX Orin, NVIDIA is leading the inference performance category of MLPerf. Jetson Orin modules provide a giant leap forward for your next-generation applications, and now the same NVIDIA Orin architecture is made accessible for entry-level AI devices.
We used emulation mode with NVIDIA JetPack 5.0.2 to run computer vision benchmarks with Jetson Orin Nano, and the results showcase how it sets the new standard. Testing included some of our dense INT8 and FP16 pretrained models from NGC, and a standard ResNet-50 model. We also ran the same models for comparison on Jetson Nano, TX2 NX, and Xavier NX.
Here is the full list of benchmarks:
- NVIDIA PeopleNet v2.3 for pruned people detection, and NVIDIA PeopleNet v2.5 for the highest accuracy people detection
- NVIDIA ActionRecognitionNet 2D and 3D models
- NVIDIA LPRNet for license plate recognition
- NVIDIA DashCamNet, BodyPoseNet for multiperson human pose estimation
- ResNet-50 (224×224) Model
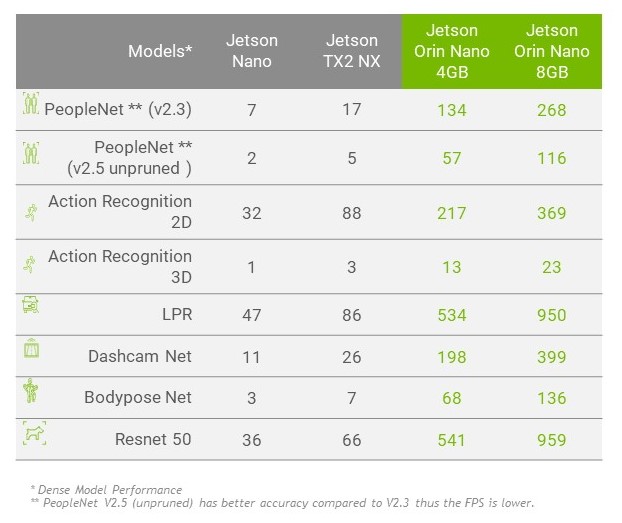
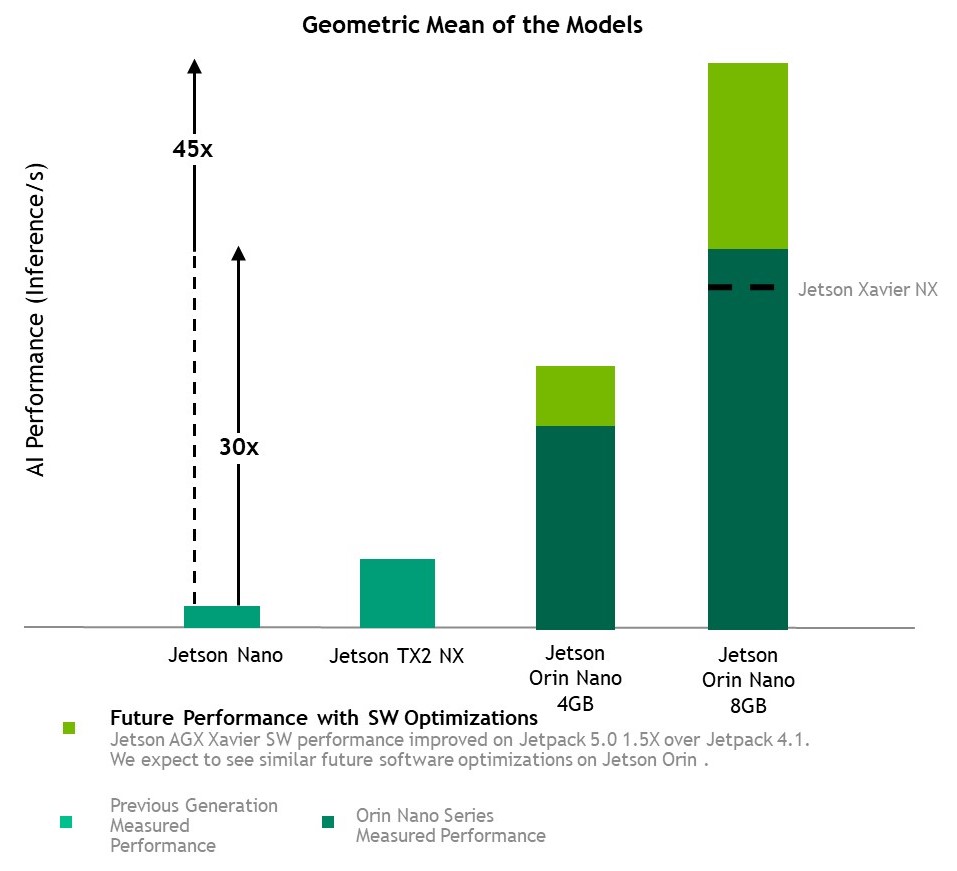
Taking the geomean of these benchmarks, Jetson Orin Nano 8GB shows a 30x performance increase compared to Jetson Nano. With future software improvements, we expect this to approach a 45x performance increase. Other Jetson devices have increased performance 1.5x since their first supporting software release, and we expect the same with Jetson Orin Nano.
Jetson runs the NVIDIA AI software stack, and use-case-specific application frameworks are available, including NVIDIA Isaac for robotics, NVIDIA DeepStream for vision AI, and NVIDIA Riva for conversational AI. You can save significant time with the NVIDIA Omniverse Replicator for synthetic data generation (SDG), and with the NVIDIA TAO Toolkit for fine-tuning pretrained AI models from the NGC catalog.
Jetson compatibility with the overall NVIDIA AI accelerated computing platform makes for ease of development and seamless migration. For more information about the NVIDIA software technologies that we bring in Jetson Orin, join us for an upcoming webinar about NVIDIA JetPack 5.0.2.
Strengthen entry-level robots with NVIDIA Isaac ROS
The Jetson Orin platform is designed to solve the toughest robotics challenges and brings accelerated computing to over 700,000 ROS developers. Combined with the powerful hardware capabilities of Jetson Orin Nano, enhancements in the latest NVIDIA Isaac software for ROS deliver excellent performance and productivity in the hands of roboticists.
The new Isaac ROS DP release optimizes ROS2 node-processing pipelines that can be executed on the Jetson Orin platform and provides new DNN-based GEMS designed to increase throughput. The Jetson Orin Nano can take advantage of those highly optimized ROS2 packages for tasks such as localization, real-time 3D reconstruction, and depth estimation, which can be used for obstacle avoidance.
Unlike the original Jetson Nano, which can only process simple applications, the Jetson Orin Nano can run more complex applications. With a continuing commitment to improving NVIDIA Isaac ROS, you’ll see increased accuracy and throughput on the Jetson Orin Platform over time.
For roboticists developing the next generation of service robots, intelligent drones, and more, the Jetson Orin Nano is the ideal solution with up to 40 TOPS for modern AI inference pipelines in a power-efficient and small form factor.
Get started developing for all six Jetson Orin modules by placing an order for the Jetson AGX Orin Developer Kit and installing the latest NVIDIA JetPack.
For more information about the overlay for emulating Jetson Orin Nano modules, see Jetson Linux and read the NVIDIA Jetson Orin Nano documentation available at the Jetson download center. For more information and support, see the NVIDIA Embedded Developer page and the Jetson forums.
 Supercomputers are used to model and simulate the most complex processes in scientific computing, often for insight into new discoveries that otherwise would be…
Supercomputers are used to model and simulate the most complex processes in scientific computing, often for insight into new discoveries that otherwise would be…
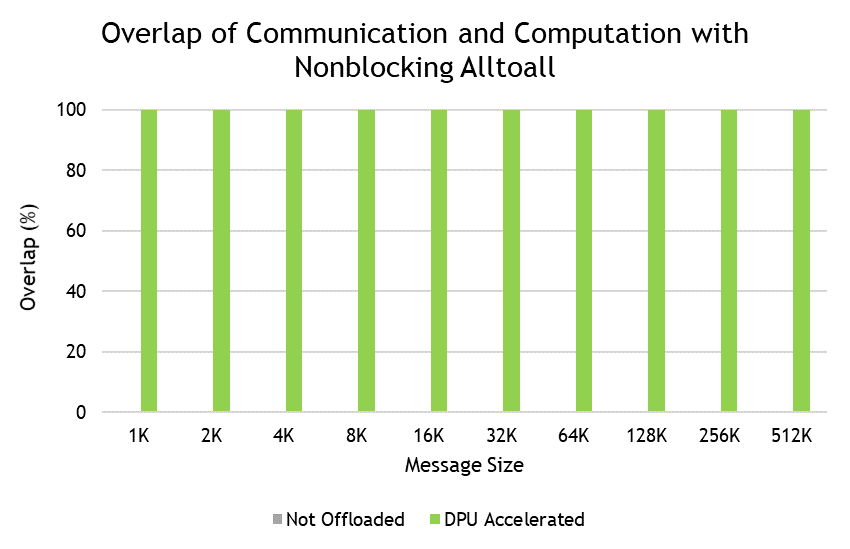
 Announced at GTC, technical artists, software developers, and ML engineers can now build custom, physically accurate, synthetic data generation pipelines in the…
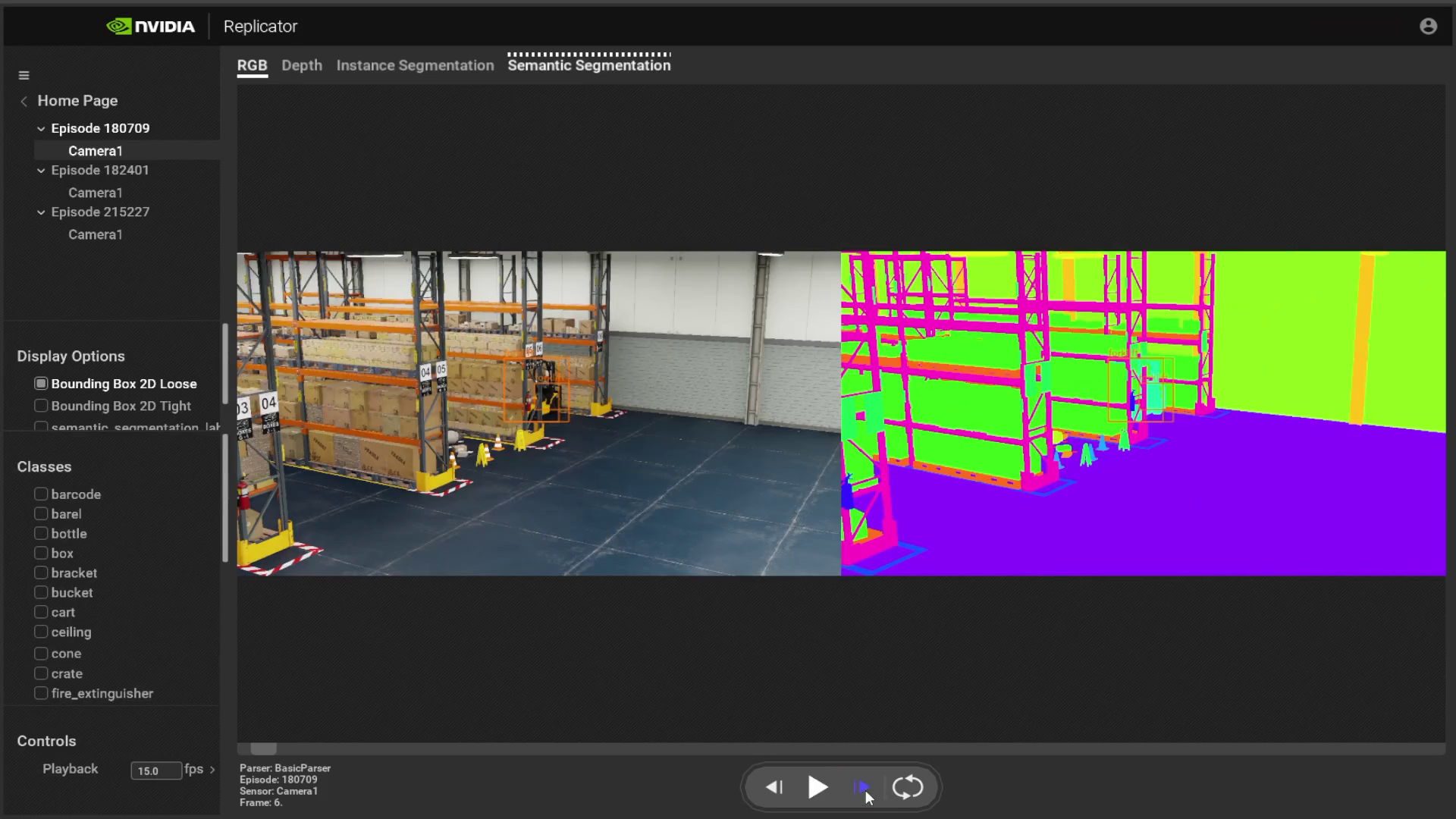
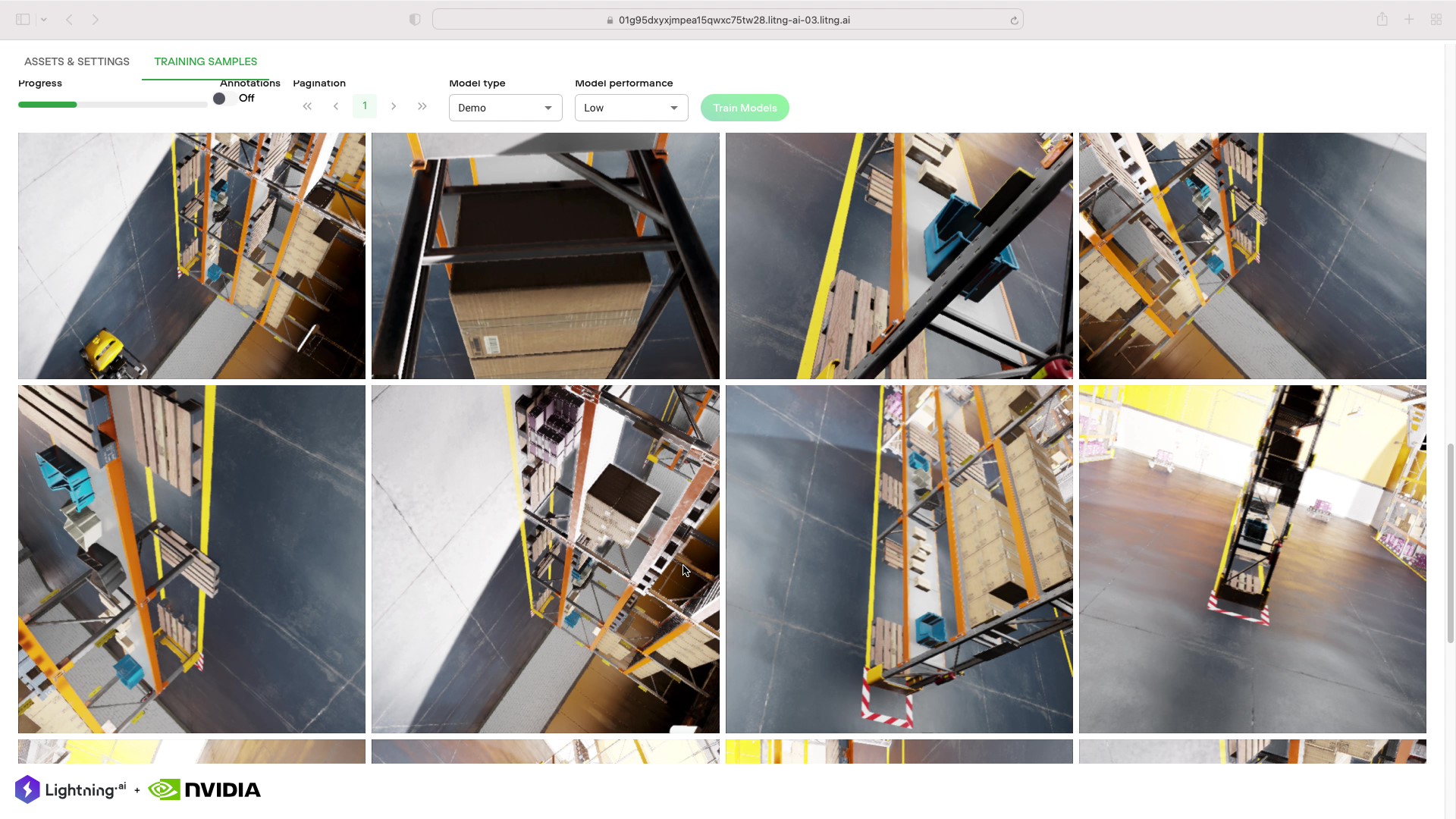
Announced at GTC, technical artists, software developers, and ML engineers can now build custom, physically accurate, synthetic data generation pipelines in the…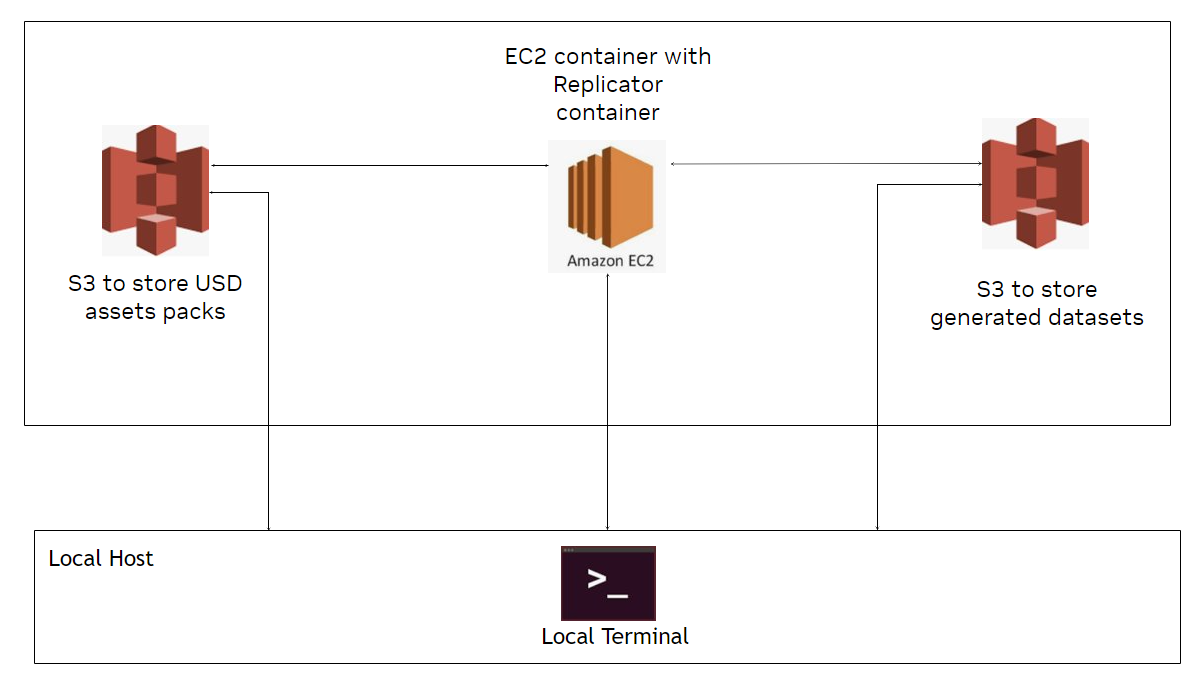
 Recent advances in large language models (LLMs) have fueled state-of-the-art performance for NLP applications such as virtual scribes in healthcare, interactive…
Recent advances in large language models (LLMs) have fueled state-of-the-art performance for NLP applications such as virtual scribes in healthcare, interactive… Developers, creators, and enterprises around the world are using NVIDIA Omniverse to build virtual worlds and push the boundaries of the metaverse. Based on…
Developers, creators, and enterprises around the world are using NVIDIA Omniverse to build virtual worlds and push the boundaries of the metaverse. Based on…