Alien invasions. Gritty dystopian megacities. Battlefields swarming with superheroes. As one of Hollywood’s top concept artists, Drew Leung can visualize any world you can think of, except one where AI takes his job. He would know. He’s spent the past few months trying to make it happen, testing every AI tool he could. “If your Read article >
NVIDIA and Oracle are teaming to make the power of AI accessible to enterprises across industries. These include healthcare, financial services, automotive and a broad range of natural language processing use cases driven by large language models, such as chatbots, personal assistants, document summarization and article completion. Join NVIDIA and Oracle experts at Oracle CloudWorld, Read article >
High-end PC gaming arrives on more devices this GFN Thursday. GeForce NOW RTX 3080 members can now stream their favorite PC games at up to 1600p and 120 frames per second in a Chrome browser. No downloads, no installs, just victory. Even better, NVIDIA has worked with Google to support the newest Chromebooks, which are Read article >
NVIDIA is excited to introduce a new feature available in the next generation of GPUs called Shader Execution Reordering (SER). SER is a performance…
NVIDIA is excited to introduce a new feature available in the next generation of GPUs called Shader Execution Reordering (SER). SER is a performance optimization that unlocks the potential for better ray and memory coherency in ray tracing shaders, and thus increased shading efficiency.
Background and overview
Shading divergence is a long-standing problem in ray tracing. With increasingly complex renderer implementations, more workloads are becoming limited by shader execution rather than the tracing of rays. One way to mitigate this problem is to reduce the divergence affecting the GPU when executing shader code.
SER helps to alleviate two types of divergence: execution divergence and data divergence. Execution divergence occurs when different threads execute different shaders or branches within a shader. Data divergence occurs when different threads access memory resources in patterns that are hard to cache.
SER mitigates divergence by reordering threads, on the fly, across the GPU so that they can continue execution with increased coherence. It also enables the decoupling of ray intersection and shading.
HLSL extension headers, which can be found in the latest NVIDIA API
Link against nvapi64.lib, included in the packages containing the headers above
A recent version of DXC / dxcompiler.dll that supports templates (optional). If you’re compiling shaders from Visual Studio, make sure that your project is configured to use this version of the compiler executable.
First, initialize / deinitialize NVAPI using the following call:
NvAPI_Initialize();
NvAPI_Unload();
Next, verify that the SER API is supported, using the following call:
bool supported = false;
NvAPI_D3D12_IsNvShaderExtnOpCodeSupported(pDevice, NV_EXTN_OP_HIT_OBJECT_REORDER_THREAD, &supported);
if (!supported)
{
/* Don't use SER */
}
Host side integration
Before ray tracing state object creation, set up a fake UAV slot and register it:
#define NV_SHADER_EXTN_SLOT 999999 // pick an arbitrary unused slot
#define NV_SHADER_EXTN_REGISTER_SPACE 999999 // pick an arbitrary unused space
NvAPI_D3D12_SetNvShaderExtnSlotSpace(pDevice, NV_SHADER_EXTN_SLOT,
NV_SHADER_EXTN_REGISTER_SPACE);
If you need a thread-local variant, use the related function: NvAPI_D3D12_SetNvShaderExtnSlotSpaceLocalThread.
Next, add the fake UAV slot to the global root signature used to compile ray tracing pipelines. You do not need to allocate and / or bind a resource for this. Below is an example of augmenting D3D12 sample code with a fake UAV slot, denoted in bold. The root signature creation in your application will likely look quite different.
// Global Root Signature
// This is a root signature that is shared across all raytracing shaders invoked during a
// DispatchRays() call.
{
// Performance TIP: Order from most frequent to least frequent.
CD3DX12_DESCRIPTOR_RANGE ranges[5];
ranges[0].Init(D3D12_DESCRIPTOR_RANGE_TYPE_UAV, 1, 0); // output texture
ranges[1].Init(D3D12_DESCRIPTOR_RANGE_TYPE_SRV, 2, 0, 1); // static index buffers
ranges[2].Init(D3D12_DESCRIPTOR_RANGE_TYPE_SRV, 2, 0, 2); // static vertex buffers
ranges[3].Init(D3D12_DESCRIPTOR_RANGE_TYPE_SRV, 1, 0, 3); // static vertex buffers
// fake UAV for shader execution reordering
ranges[4].Init(
D3D12_DESCRIPTOR_RANGE_TYPE_UAV, 1, NV_SHADER_EXTN_SLOT, NV_SHADER_EXTN_REGISTER_SPACE);
CD3DX12_ROOT_PARAMETER rootParameters[GlobalRootSignatureParams::Count];
rootParameters[GlobalRootSignatureParams::OutputViewSlot].InitAsDescriptorTable(1, &ranges[0]);
rootParameters[GlobalRootSignatureParams::AccelerationStructureSlot].InitAsShaderResourceView(0);
rootParameters[GlobalRootSignatureParams::SceneConstantSlot].InitAsConstantBufferView(0);
rootParameters[GlobalRootSignatureParams::VertexBuffersSlot].InitAsDescriptorTable(3, &ranges[1]);
rootParameters[GlobalRootSignatureParams::SerUavSlot].InitAsDescriptorTable(1, &ranges[4]);
CD3DX12_ROOT_SIGNATURE_DESC globalRootSignatureDesc(ARRAYSIZE(rootParameters), rootParameters);
SerializeAndCreateRaytracingRootSignature(
globalRootSignatureDesc, &m_raytracingGlobalRootSignature);
}
Use of API in shader code
In shader code, define the fake UAV slot and register again, using the same values:
#define NV_SHADER_EXTN_SLOT u999999 // matches slot number in NvAPI_D3D12_SetNvShaderExtnSlotSpace
#define NV_SHADER_EXTN_REGISTER_SPACE space999999 // matches space number in NvAPI_D3D12_SetNvShaderExtnSlotSpace
#include "SER/nvHLSLExtns.h"
Now the SER API may be used in ray generation shaders:
1) ensure that templates are enabled in DXC by specifying the command line argument -HV 2021
or
2) use the macro version of the API that does not require templates. The macro version can be enabled by #defining NV_HITOBJECT_USE_MACRO_API before #including nvHLSLExtns.h. This is intended for use in legacy codebases which have difficulty switching to HLSL 2021. The recommended path is using templates if the codebase can support it.
Integration of Unreal Engine 5 NvRTX
Unreal Engine developers can take advantage of SER within the NVIDIA branch of Unreal Engine (NvRTX). The following section explains how SER provides performance gains in ray tracing operations and provides optimization tips for specific use cases.
The NVIDIA Unreal Engine 5 NvRTX 5.0.3 release will feature SER integration to support optimization of many of its ray tracing paths. With SER, NvRTX developers will see additional frame rate optimization on 40 series cards with up to 40% increased speeds in ray tracing operations and zero impact on quality or content authoring. This improves efficiency of complex ray tracing calculations and will provide greater gains in scenes that take full advantage of what ray tracing has to offer.
Benefits of SER in Unreal Engine 5
SER in Unreal Engine 5 (UE5) enables better offline path tracing, arguably the most complex tracing operation in UE5. Likewise, hardware ray traced reflections and translucency, which have complex interactions with materials and lighting, will also see benefits.
SER also improves Lumen performance when hardware ray tracing is enabled. In some cases, the changes required to do this, independent of initial system complexity, are trivial. In other cases, it has added substantial complexity. Three different examples are explored in more detail below.
Simple case: Path tracing
Path tracing presents a highly divergent workflow, making it a great candidate for applying SER.
Figure 1. Grandma’s Kitchen by Richard Cowgill, path traced in Unreal Engine 5. Path tracing is 40% faster with SER for this view.
Applying SER allows the path tracer to reduce divergence in its material evaluation, instead of just on the number of bounces. This offers a 20-50% gain in performance with the code change provided below:
#if !PATH_TRACER_USE_REORDERING
// Trace the ray, including evaluation of hit data
TraceRay(
TLAS,
RayFlags,
RAY_TRACING_MASK_ALL,
RAY_TRACING_SHADER_SLOT_MATERIAL,
RAY_TRACING_NUM_SHADER_SLOTS,
MissShaderIndex,
PathState.Ray,
PackedPayload);
#else
{
NvHitObject Hit;
// Trace ray to produce hit object
NvTraceRayHitObject(
TLAS,
RayFlags,
RAY_TRACING_MASK_ALL,
RAY_TRACING_SHADER_SLOT_MATERIAL,
RAY_TRACING_NUM_SHADER_SLOTS,
MissShaderIndex,
PathState.Ray,
PackedPayload, Hit);
// Reorder threads to have coherent hit evaluation
NvReorderThread(Hit);
// Evaluate hit data in the now coherent environment
NvInvokeHitObject(TLAS, Hit, PackedPayload);
}
#endif
This improvement can be accomplished by replacing the DXR TraceRay function with an equivalent set of NvTraceRayHitObject, NvReorderThread, and NvInvokeHitObject. A key aspect is that the optimization is only applied selectively. The change only applies to the TraceTransparentRay function within the UE5 path tracing code, as this is the source of most material evaluation divergence. Other rays are performing cheaper operations and are less important to reorder, so they may not be worth the extra cost of attempting to reorder.
This example is the tip of the iceberg when it comes to the potential of the path tracer code. More careful analysis will almost certainly allow additional gains, including possibly eliminating the need to use multiple passes to compact longer rays.
Unusual case: Work compaction in Lumen global illumination
Typically, one thinks of reordering to handle the execution divergence experienced by hit shading. While the ray tracing passes used in Lumen global illumination do not run a divergent hit shader, they still benefit from the mechanisms provided by SER.
For large scenes, like the UE5 City Sample, traces are broken into the near and far field, which are run as separate tracing passes with compaction in between. The multiple passes and compaction can be replaced by a single NVReorderThread call. This avoids the idle bubbles on the GPU required to compact the results of near-field tracing, and then launch far-field rays.
Removing the extra overhead of storing, compacting, and relaunching work is often worth a 20% savings. The shader changes can be more intensive due to assumptions in the original code (functions using macros to permute behaviors rather than arguments). However, the logical changes amounted to adding two reorder calls with a single Boolean expression for whether a trace had hit or missed.
Complex case: Lumen reflections
Lumen is a system contained in UE5 which implements global illumination and reflections. It has a high degree of complexity, and a thorough discussion of it is well beyond the scope of this blog post. The description below is heavily distilled and focuses on one specific configuration: Lumen reflections with hardware ray tracing (HWRT) hit lighting enabled. Note that Lumen is also able to leverage software ray tracing by way of signed distance fields, which will not be discussed here.
To render reflections, the Lumen HWRT hit lighting path uses multiple passes:
Near field tracing – extract material ID
Compact rays
Far field tracing (optional) – extract material ID
Compact rays
Append far field rays (optional)
Sort rays by material
Re-trace with hit lighting
In addition, the following important details about how Lumen works help explain the differences in approach between SER and non-SER.
Near field and far field in lumen correspond with different sections of the TLAS for objects close to the camera, and objects far away from the camera respectively. Both near field and far field are contained in the same TLAS.
Two different ray tracing pipelines are used in the passes above. Near and far field both use a simplified (fast) tracing path, while hit lighting has full material support. This is the reason for the separate re-tracing path with hit lighting.
For further technical details on these passes, see Lumen Technical Details. With SER enabled, the passes can be combined because separate compaction and sorting phases are no longer necessary. The pass roughly becomes trace near field, if not a hit trace far field, if either hit then uses the hit object to evaluate the material and perform lighting. This is possible due to the decoupling of tracing and shading.
The relevant sections of the shader are provided below:
NvHitObject SERHitObject;
// Near field
NvTraceRayHitObject(..., SERHitObject);
NvReorderThread(SERHitObject);
Result.bIsHit = SERHitObject.IsHit();
// Far field
if (!Result.bIsHit)
{
// Transform ray into far field space of TLAS
...
NvTraceRayHitObject(..., SERHitObject);
NvReorderThread(SERHitObject);
Result.bIsHit = SERHitObject.IsHit();
}
// Compute result
if (Result.bIsHit)
{
NvInvokeHitObject(Context.TLAS, SERHitObject, Payload);
Result.Radiance = CalculateRayTracedLighting();
}
// Handle miss
This is one example of the availability of SER creating a higher-level implication on the rendering architecture, rather than just replacing TraceRay with the respective NVAPI equivalent. The implementation described above resulted in a 20-30% speed increase in Lumen reflections on the GPU, measured when profiling a typical workload in UE5 City Sample.
Conclusion
Shading divergence can pose performance problems when considering both data and execution. The Shader Execution Reordering API gives developers a powerful tool to mitigate these penalties, with relatively little effort required to get started. The optimizations discussed above represent only the initial stages of introducing the possibilities provided by SER to a large codebase, such as Unreal Engine 5. We look forward to seeing SER realize more of its potential as its use evolves.
The age of electric vehicles has arrived and, with it, an entirely new standard for premium SUVs. Polestar, the performance EV brand spun out from Volvo Cars, launched its third model today in Copenhagen. With the Polestar 3, the automaker has taken SUV design back to the drawing board, building a vehicle as innovative as Read article >
Join us for the second episode of our webinar series, Level Up with NVIDIA. You learn how to use the latest NVIDIA RTX technology in Unreal Engine 5, followed…
Join us for the second episode of our webinar series, Level Up with NVIDIA. You learn how to use the latest NVIDIA RTX technology in Unreal Engine 5, followed by a live Q&A session where you can ask NVIDIA experts about your game integrations.
A transformer model is a neural network that learns context and thus meaning by tracking relationships in sequential data like the words in this sentence.
A transformer model is a neural network that learns context and thus meaning by tracking relationships in sequential data like the words in this sentence.
Imagine that you’re working on a machine learning (ML) project and you’ve found your champion model. What happens next? For many, the project ends there,…
Imagine that you’re working on a machine learning (ML) project and you’ve found your champion model. What happens next? For many, the project ends there, with their models sitting isolated in a Jupyter notebook. Others will take the initiative to convert their notebooks to scripts for somewhat production-grade code.
Both of these end points restrict a project’s accessibility, requiring knowledge of source code hosting sites like GitHub and Bitbucket. A better solution is to convert your project into a prototype with a frontend that can be deployed on internal servers.
While a prototype may not be production standard, it’s an effective technique companies use to provide stakeholders with insight into a proposed solution. This then allows the company to collect feedback and develop better iterations in the future.
To develop a prototype, you will need:
A frontend for user interaction
A backend that can process requests
Both requirements can take a significant amount of time to build, however. In this tutorial, you will learn how to rapidly build your own machine learning web application using Streamlit for your frontend and FastAPI for your microservice, simplifying the process. Learn more about microservices in Building a Machine Learning Microservice with FastAPI.
Streamlit, an open-source app framework, aims to simplify the process of building web applications for machine learning and data science. It has been gaining a significant amount of traction in the applied ML community in recent years. Founded in 2018, Streamlit was born out of the frustrations of ex-Google engineers faced with the challenges experienced by practitioners when deploying machine learning models and dashboards.
Using the Streamlit framework, data scientists and machine learning practitioners can build their own predictive analytics web applications in a few hours. There is no need to depend on front-end engineers or knowledge of HTML, CSS, or Javascript since it’s all done in Python.
FastAPI has also had a rapid rise to prominence among Python developers. It’s a modern web framework, also initially released in 2018, that was designed to compensate in almost all areas in which Flask falls flat. One of the great things about switching to FastAPI is the learning curve is not so steep, especially if you already know Flask. With FastAPI you can expect thorough documentation, short development times, simple testing, and easy deployment. This makes it possible to develop RESTful APIs in Python.
By combining the power of the two frameworks, it’s possible to develop an exciting machine learning application you could share with your friends, colleagues, and stakeholders in less than a day.
Build a full-stack machine learning application
The following steps guide you through building a simple classification model using FastAPI and Streamlit. This model evaluates whether a car is acceptable based on the following six input features:
After you have done all of the data analysis, trained your champion model, and packaged the machine learning model, the next step is to create two dedicated services: 1) the FastAPI backend and 2) the Streamlit frontend. These two services can then be deployed in two Docker containers and orchestrated using Docker Compose.
Each service requires its own Dockerfile to assemble the Docker images. A Docker Compose YAML file is also required to define and share both container applications. The following steps work through the development of each service.
The user interface
In the car_evaluation_streamlit package, create a simple user-interface in the app.py file using Streamlit. The code below includes:
A title for the UI
A short description of the project
Six interactive elements the user will use to input information about a car
Class values returned by the API
A submit button that, when clicked, will send all data collected from the user to the machine learning API service as a post request and then display the response from the model
import requests
import streamlit as st
# Define the title
st.title("Car evaluation web application")
st.write(
"The model evaluates a cars acceptability based on the inputs below.
Pass the appropriate details about your car using the questions below to discover if your car is acceptable."
)
# Input 1
buying = st.radio(
"What are your thoughts on the car's buying price?",
("vhigh", "high", "med", "low")
)
# Input 2
maint = st.radio(
"What are your thoughts on the price of maintenance for the car?",
("vhigh", "high", "med", "low")
)
# Input 3
doors = st.select_slider(
"How many doors does the car have?",
options=["2", "3", "4", "5more"]
)
# Input 4
persons = st.select_slider(
"How many passengers can the car carry?",
options=["2", "4", "more"]
)
# Input 5
lug_boot = st.select_slider(
"What is the size of the luggage boot?",
options=["small", "med", "big"]
)
# Input 6
safety = st.select_slider(
"What estimated level of safety does the car provide?",
options=["low", "med", "high"]
)
# Class values to be returned by the model
class_values = {
0: "unacceptable",
1: "acceptable",
2: "good",
3: "very good"
}
# When 'Submit' is selected
if st.button("Submit"):
# Inputs to ML model
inputs = {
"inputs": [
{
"buying": buying,
"maint": maint,
"doors": doors,
"persons": persons,
"lug_boot": lug_boot,
"safety": safety
}
]
}
# Posting inputs to ML API
response = requests.post(f"http://host.docker.internal:8001/api/v1/predict/", json=inputs, verify=False)
json_response = response.json()
prediction = class_values[json_response.get("predictions")[0]]
st.subheader(f"This car is **{prediction}!**")
The only framework required for this service is Streamlit. In the requirements.txt file, note the version of Streamlit to install when creating the Docker image.
streamlit>=1.12.0,
Now, add the Dockerfile to create the docker image for this service:
FROM python:3.9.4
WORKDIR /opt/car_evaluation_streamlit
ADD ./car_evaluation_streamlit /opt/car_evaluation_streamlit
RUN pip install --upgrade pip
RUN pip install -r /opt/car_evaluation_streamlit/requirements.txt
EXPOSE 8501
CMD ["streamlit", "run", "app.py"]
Each command creates a layer and each layer is an image.
The REST API
REpresentational State Transfer Application Programming Interfaces (REST APIs) is a software architecture that enables two applications to communicate with one another. In technical terms, a REST API transfers the state of a requested resource to the client. In this scenario, the requested resource will be a prediction from the machine learning model.
The API built with FastAPI can be found in the car_evaluation_api package. Locate the app/main.py file, which is used to run the application. For more information about how the API was developed, see Building a Machine Learning microservice with FastAPI.
from typing import Any
from fastapi import APIRouter, FastAPI, Request
from fastapi.middleware.cors import CORSMiddleware
from fastapi.responses import HTMLResponse
from loguru import logger
from app.api import api_router
from app.config import settings, setup_app_logging
# setup logging as early as possible
setup_app_logging(config=settings)
app = FastAPI(
title=settings.PROJECT_NAME, openapi_url=f"{settings.API_V1_STR}/openapi.json"
)
root_router = APIRouter()
@root_router.get("/")
def index(request: Request) -> Any:
"""Basic HTML response."""
body = (
""
""
"
"
""
""
)
return HTMLResponse(content=body)
app.include_router(api_router, prefix=settings.API_V1_STR)
app.include_router(root_router)
# Set all CORS enabled origins
if settings.BACKEND_CORS_ORIGINS:
app.add_middleware(
CORSMiddleware,
allow_origins=[str(origin) for origin in settings.BACKEND_CORS_ORIGINS],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
if __name__ == "__main__":
# Use this for debugging purposes only
logger.warning("Running in development mode. Do not run like this in production.")
import uvicorn
uvicorn.run(app, host="localhost", port=8001, log_level="debug")
The code above defines the server, which includes three endpoints:
"/": An endpoint used to define a body that returns an HTML response
"/health": An endpoint to return the health response schema of the model
"/predict": An endpoint used to serve predictions from the trained model
You may only see the "/" endpoint in the code above: this is because the "/health" and "/predict" endpoints were imported from the API module and added to the application router. Next, save the dependencies for the API service in the requirements.txt file:
Note: An extra index was added to pip to install the packaged model from Gemfury.
Next, add the Dockerfile to the car_evalutation_api package.
FROM python:3.9.4
# Create the user that will run the app
RUN adduser --disabled-password --gecos '' ml-api-user
WORKDIR /opt/car_evaluation_api
ARG PIP_EXTRA_INDEX_URL
# Install requirements, including from Gemfury
ADD ./car_evaluation_api /opt/car_evaluation_api
RUN pip install --upgrade pip
RUN pip install -r /opt/car_evaluation_api/requirements.txt
RUN chmod +x /opt/car_evaluation_api/run.sh
RUN chown -R ml-api-user:ml-api-user ./
USER ml-api-user
EXPOSE 8001
CMD ["bash", "./run.sh"]
Both services have been created, as well as the instructions to build the containers for each service.
The next step is to wire the containers together so you can start using your machine learning application. Before proceeding, make sure you have Docker and Docker Compose installed. Reference the Docker Compose installation guide if necessary.
Wire the Docker containers
To wire the containers together, locate the docker-compose.yml file in the packages/ directory.
The contents of the Docker Compose file are provided below:
This file defines the version of Docker Compose to use, defines the two services to be wired together, the ports to expose, and the paths to their respective Dockerfiles. Note that the car_evaluation_streamlit service informs Docker Compose that it depends on the car_evaluation_api service.
To test the application, navigate to the project root from your command prompt (the location of the docker-compose.yml file). Then run the following command to build the images and spin up both containers:
docker-compose up -d --build
It may take a minute or two to build the images. Once the Docker images are built, you can navigate to http://localhost:8501 to use the application.
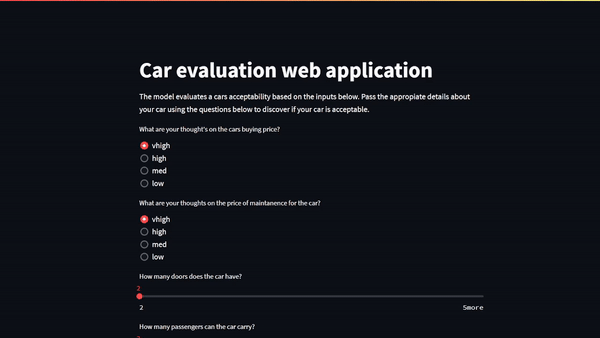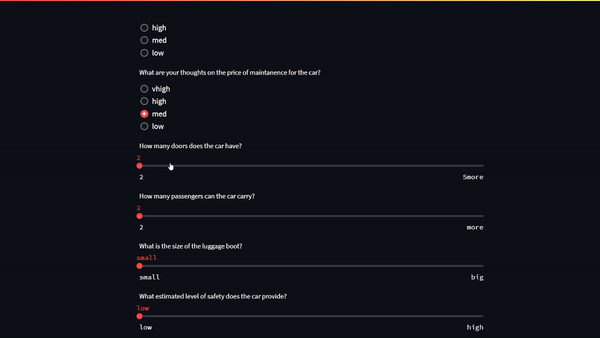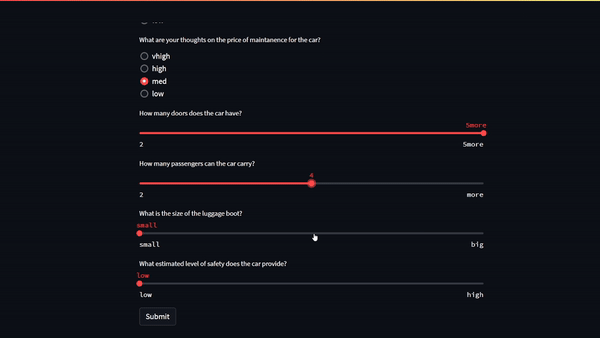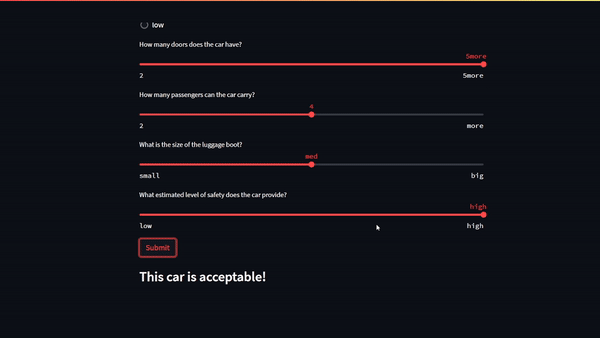
Figure 1. Machine learning web application demonstrating a prediction after inputs were sent from the Streamlit user interface
Figure 1 shows the six model inputs outlined at the beginning of this post:
The car buying price (low, medium, high, very high)
The car’s maintenance costs (low, medium, high, very high)
The number of doors the car has (2, 3, 4, 5+)
The number of passengers the car can carry (2, 4, more)
The size of the luggage boot (small, medium, big).
The expected safety of the car (low, medium, high)
Summary
Congratulations—you have just created your own full-stack machine learning web application. The next steps may involve deploying the application on the web using services such as Heroku Cloud, Google App Engine, or Amazon EC2.
Streamlit enables developers to rapidly build aesthetically pleasing user interfaces for data science and machine learning. A working knowledge of Python is all that is required to get started with Streamlit. FastAPI is a modern web framework designed to compensate in most areas where Flask falls flat. You can use Streamlit and FastAPI backend together to build a full-stack web application with Docker and Docker Compose.
Everyone wants green computing. Mobile users demand maximum performance and battery life. Businesses and governments increasingly require systems that are powerful yet environmentally friendly. And cloud services must respond to global demands without making the grid stutter. For these reasons and more, green computing has evolved rapidly over the past three decades, and it’s here Read article >
This week ‘In the NVIDIA Studio’ creators can now pick up the GeForce RTX 4090 GPU, available from top add-in card providers including ASUS, Colorful, Gainward, Galaxy, GIGABYTE, INNO3D, MSI, Palit, PNY and ZOTAC, as well as from system integrators and builders worldwide.

 NVIDIA is excited to introduce a new feature available in the next generation of GPUs called Shader Execution Reordering (SER). SER is a performance…
NVIDIA is excited to introduce a new feature available in the next generation of GPUs called Shader Execution Reordering (SER). SER is a performance…

 Join us for the second episode of our webinar series, Level Up with NVIDIA. You learn how to use the latest NVIDIA RTX technology in Unreal Engine 5, followed…
Join us for the second episode of our webinar series, Level Up with NVIDIA. You learn how to use the latest NVIDIA RTX technology in Unreal Engine 5, followed… Imagine that you’re working on a machine learning (ML) project and you’ve found your champion model. What happens next? For many, the project ends there,…
Imagine that you’re working on a machine learning (ML) project and you’ve found your champion model. What happens next? For many, the project ends there,…