
 The telecom sector is transforming how communication happens. Striving to provide reliable, uninterrupted service, businesses are tackling the challenge of…
The telecom sector is transforming how communication happens. Striving to provide reliable, uninterrupted service, businesses are tackling the challenge of…
The telecom sector is transforming how communication happens. Striving to provide reliable, uninterrupted service, businesses are tackling the challenge of delivering an optimal customer experience.
This optimal customer experience is something many long-time customers of large telecom service providers do not have. Take Jack, for example. His call was on hold for 10 minutes, which made him late for work. Jill, the third agent he spoke with, read the brief note provided by the previous agent but had trouble understanding it. So, she asked Jack a few questions to clarify. With no co-workers available, Jill consulted multiple policy documents to address Jack’s concerns. Several resources later, Jill located the necessary information, but sadly, Jack had already ended the call.
Long wait times, complex service requests, and a lack of personalization are some of the common issues faced by customers, leading to dissatisfaction and churn. To overcome these challenges, the telecom sector is turning to AI—specifically conversational AI, a technology that leverages speech, translation, and natural language processing (NLP) to facilitate human-like interactions.
This post explores why conversational AI systems are essential and why it is important to have a high level of transcription accuracy for optimal performance in downstream tasks. We explain the NVIDIA Riva speech recognition customization techniques Quantiphi has used to improve transcription accuracy.
Accuracy in conversational AI systems
In telco contact centers, highly accurate conversational AI systems are essential for several reasons. Conversational AI systems can help agents extract valuable information from call interactions and make informed decisions, leading to improved service quality and customer experience.
One key component in a conversational AI system is automatic speech recognition (ASR), also known as speech recognition or speech-to-text. Downstream tasks in telco contact centers heavily rely on accurate transcription provided by ASR systems. These tasks encompass a wide range of applications such as:
- Customer insights
- Sentiment analysis
- Call classification
- Call transcription
Quick and accurate responses are vital for efficient and effective customer service. That means reducing the overall latency of individual components, including ASR, is very important. By reducing the time required to complete a task, contact center agents can provide prompt solutions, leading to enhanced customer satisfaction and loyalty.
Moreover, accurate transcription that includes punctuation enhances readability. Clear and well-punctuated transcriptions help agents better understand customer queries, facilitating clear communication and problem solving. This, in turn, improves the overall efficiency and effectiveness of customer interactions.
NVIDIA Riva automatic speech recognition pipeline
Speech-to-text receives an audio stream as input, transcribes it, and produces the transcribed text as output (Figure 1). First, the audio stream goes to an audio feature extractor and preprocessor, which filter out noise and capture audio spectral features in a spectrogram or mel spectrogram. Then, an acoustic model, together with a language model, transcribes the speech into text. Punctuation is added to the transcribed text to improve readability.
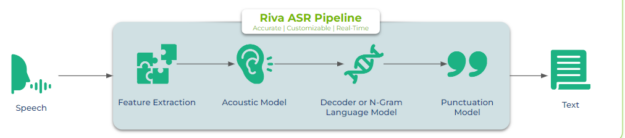
Performance evaluation metrics for ASR systems
The performance of an ASR system can be measured using three metrics:
- Accuracy is fundamental, as it directly affects the quality and reliability of the transcriptions. By measuring accuracy through metrics like word error rate (WER), the system can be evaluated in terms of how well it transcribes spoken words. A low WER is vital in contact centers, as it ensures that customer queries and interactions are precisely captured, enabling agents to provide accurate and appropriate responses.
- Latency is the time taken to generate a transcript of a segment of audio. To maintain an engaging experience, the caption should be delivered at a latency of no more than a few hundred milliseconds. A transcription system must deliver captions with minimal delay. Low latency ensures a seamless and engaging customer experience, enhancing overall efficiency and customer satisfaction.
- Cost to develop and run a transcription service on sufficient compute infrastructure is another important measure. Although AI-based transcription is inexpensive compared to human interpreters, cost must be weighed along with other factors.
In a contact center setting, a transcription system must excel in accuracy to provide reliable transcriptions, offer low latency for prompt customer interactions, and consider cost factors to ensure a cost-effective and feasible solution for the organization. By optimizing all three metrics, the transcription system can effectively support contact center operations and enhance delivery of customer service.
Methods to improve ASR accuracy
As shown in Figure 2, there are several techniques that can be used to achieve the best possible transcription accuracy for a specific domain, the easiest of which is word boosting. ASR word boosting involves passing to the model a list of important, possibly out-of-vocabulary, domain-specific words as additional input. This enables the ASR module to recognize such words during inference.
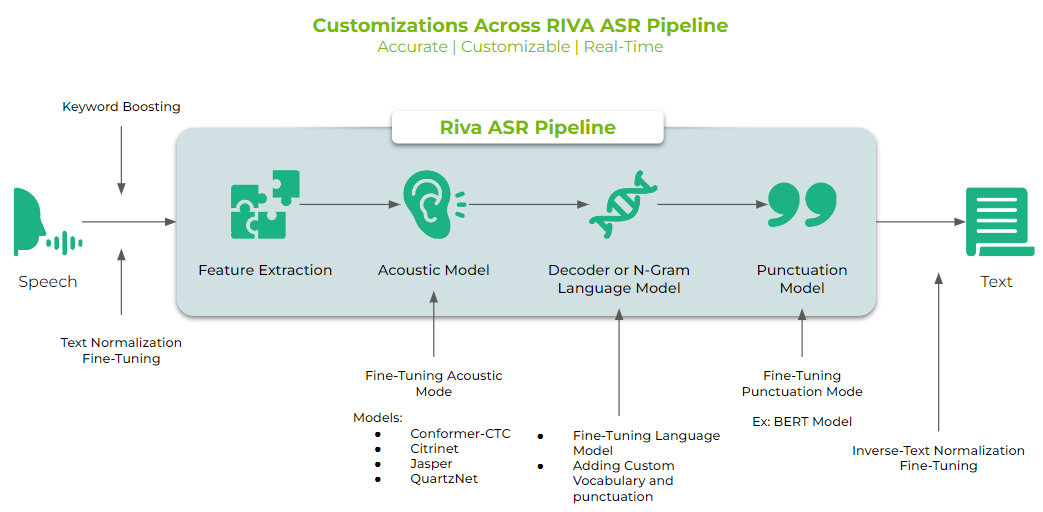
In most cases, certain nouns (such as the names of companies or services) are either not in the vocabulary, or are frequently mistranscribed by the ASR model. These nouns were added to the list of words to be boosted. This strategy enabled us to easily improve recognition of specific words at request time.
In addition, the Quantiphi team:
- Retrained the language model on our own custom dataset to adapt the ASR engine to our domain-specific terms and phrases.
- Fine-tuned the acoustic model to adapt the ASR engine to specific accents and noisy environments.
Customized speech-assisted conversational AI systems
One of the most significant challenges faced by customer contact centers in the telecom industry is the long time it takes to resolve complex queries. Agents typically need to consult with multiple stakeholders and internal policy documents to respond to complex queries.
Conversational AI systems provide relevant documentation, insights, and recommendations, thereby enabling contact center agents to expedite the resolution of customer queries.
The Quantiphi solution architecture for customized speech-assisted conversational AI pipeline involves the following:
- Speech recognition pipeline: Creates transcriptions by capturing spoken language and converting it into text
- Intent slot model: Identifies user intent
- Semantic search pipeline: Retrieves answers for the agent query through the dialog manager
Quantiphi built a semantic search engine and a question-answering solution (Figure 3). It retrieves the most relevant documents for a given query and generates a concise answer for telco contact center agents.
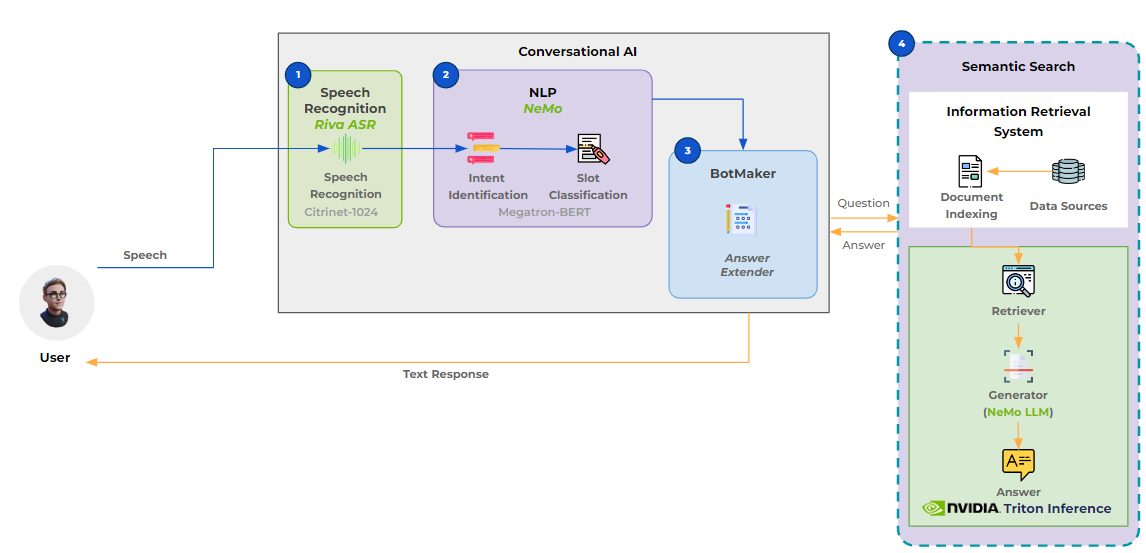
ASR, in conjunction with question-answering (QnA) systems, is also used in virtual agents and avatar-based chatbots. The accuracy of ASR transcripts has a significant impact on the accuracy of agent assist, virtual agents, and avatar-based chatbots, since they are input to responses generated by a retrieval augmented generation (RAG) pipeline. Even a slight discrepancy in the way the query is transcribed can cause the generative model to provide incorrect responses.
The Quantiphi team tried off-the-shelf ASR models, which sometimes failed to correctly transcribe proper nouns. The quality of the ASR transcription is of paramount importance when it is used in conjunction with question – answering pipelines, as shown in the following example:
Query: What is 5G?
ASR transcript: What is five g.
Generator response: Five grand is the amount of money you can earn if you work in a factory for a month.
Correct response: 5G is the next generation of wireless technology. It will be faster, more reliable, and more secure than 4G LTE.
To overcome such issues, we have used word-boosting, inverse text normalization, custom vocabulary, training language models, and fine-tuning acoustic models.
Word boosting
Words (or acronyms) such as mMTC and MEC were often transcribed incorrectly. We have addressed this with the help of word boosting. Consider the following example:
Before word boosting
Multi axis edge computing, also known as MEG is a type of network architecture that provides cloud computing capabilities and an It service environment at the edge of the network.
Mtc Fis a service area that offers low bandwidth connectivity with deep coverage.
After word boosting
Multi access edge computing also known as MEC is a type of network architecture that provides cloud computing capabilities and an IT service environment at the edge of the network.
mMTC is a service area that offers low bandwidth connectivity with deep coverage.
The before and after show how responses change, even if there is a slight difference in the way an n-gram is represented. Through inverse text normalization, the ASR model transcribes words such as ‘five g’ as ‘5G’, thus improving the QnA pipeline’s performance in the process.
Adding customized vocabulary to ASR
Most use cases typically have certain domain-specific words and jargon associated with them. To include these words in the ASR output, we added them to the vocabulary file and rebuilt the ASR model. For more details, see the tutorial How to Customize Riva ASR Vocabulary and Pronunciation with Lexicon Mapping.
Training n-gram language models
The contexts present in QnA tasks typically form a good source of text corpus to train an n-gram language model. A customized language model results in ASR outputs that are more receptive to sequences of words that commonly appear in the domain. We used an NVIDIA NeMo script to train a KenLM model and integrated it with the ASR model at build time.
Fine-tuning acoustic models
To further improve ASR performance, we fine-tuned an ASR acoustic model with 10-100 hours of small chunks (5-15 seconds) of audio data, with their corresponding ground-truth text. This helped the acoustic model to pick up regional accents. We used the Riva Jupyter notebook and NeMo for this fine-tuning. We further converted this checkpoint to Riva format using the nemo2riva tool and built it using the riva-build command.
Key takeaways
Question-answering and insights extraction make up conversational solutions that empower telecom customer service agents to provide personalized and efficient support. This improves customer satisfaction and reduces agent churn. To achieve highly accurate QnA and insights extraction solutions, it is necessary to provide high-accuracy transcriptions as an input to the rest of the pipeline.
Quantiphi achieved the highest possible accuracy by customizing speech recognition models with NVIDIA Riva ASR word boosting, inverse text normalization, custom vocabulary, training language models and fine-tuning acoustic models. This was not possible with off-the-shelf solutions.
What does that mean for Jack and Jill? Equipped with telco-customized speech-assisted conversational AI applications, Jill can quickly scan through the AI-generated summary of Jack’s previous conversations. Just as Jack finishes asking a question, her screen is already populated with the most relevant document to resolve Jack’s query. She swiftly conveys the information to Jack. He decides to answer the survey with positive feedback and still arrives at work on time.
Get in touch with experts at Quantiphi to embark on a comprehensive exploration of how conversational AI can profoundly augment your organization’s customer experience. If you are interested in diving deeper into the technical aspects of constructing agent assist solutions, join us for the webinar, Empower Telco Contact Center Agents with Multi-Language Speech-AI-Customized Agent Assists.