

There have recently been tremendous advances in language models, partly because they can perform tasks with strong performance via in-context learning (ICL), a process whereby models are prompted with a few examples of input-label pairs before performing the task on an unseen evaluation example. In general, models’ success at in-context learning is enabled by:
- Their use of semantic prior knowledge from pre-training to predict labels while following the format of in-context examples (e.g., seeing examples of movie reviews with “positive sentiment” and “negative sentiment” as labels and performing sentiment analysis using prior knowledge).
- Learning the input-label mappings in context from the presented examples (e.g., finding a pattern that positive reviews should be mapped to one label, and negative reviews should be mapped to a different label).
In “Larger language models do in-context learning differently”, we aim to learn about how these two factors (semantic priors and input-label mappings) interact with each other in ICL settings, especially with respect to the scale of the language model that’s used. We investigate two settings to study these two factors — ICL with flipped labels (flipped-label ICL) and ICL with semantically-unrelated labels (SUL-ICL). In flipped-label ICL, labels of in-context examples are flipped so that semantic priors and input-label mappings disagree with each other. In SUL-ICL, labels of in-context examples are replaced with words that are semantically unrelated to the task presented in-context. We found that overriding prior knowledge is an emergent ability of model scale, as is the ability to learn in-context with semantically-unrelated labels. We also found that instruction tuning strengthens the use of prior knowledge more than it increases the capacity to learn input-label mappings.
 |
| An overview of flipped-label ICL and semantically-unrelated label ICL (SUL-ICL), compared with regular ICL, for a sentiment analysis task. Flipped-label ICL uses flipped labels, forcing the model to override semantic priors in order to follow the in-context examples. SUL-ICL uses labels that are not semantically related to the task, which means that models must learn input-label mappings in order to perform the task because they can no longer rely on the semantics of natural language labels. |
Experiment design
For a diverse dataset mixture, we experiment on seven natural language processing (NLP) tasks that have been widely used: sentiment analysis, subjective/objective classification, question classification, duplicated-question recognition, entailment recognition, financial sentiment analysis, and hate speech detection. We test five language model families, PaLM, Flan-PaLM, GPT-3, InstructGPT, and Codex.
Flipped labels
In this experiment, labels of in-context examples are flipped, meaning that prior knowledge and input-label mappings disagree (e.g., sentences containing positive sentiment labeled as “negative sentiment”), thereby allowing us to study whether models can override their priors. In this setting, models that are able to override prior knowledge and learn input-label mappings in-context should experience a decrease in performance (since ground-truth evaluation labels are not flipped).
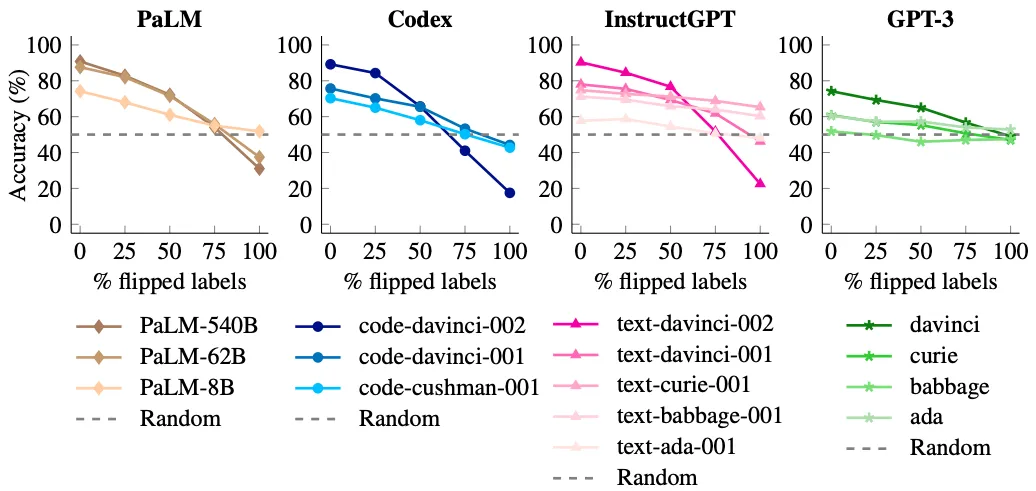 |
| The ability to override semantic priors when presented with flipped in-context example labels emerges with model scale. Smaller models cannot flip predictions to follow flipped labels (performance only decreases slightly), while larger models can do so (performance decreases to well below 50%). |
We found that when no labels are flipped, larger models have better performance than smaller models (as expected). But when we flip more and more labels, the performance of small models stays relatively flat, but large models experience large performance drops to well-below random guessing (e.g., 90% → 22.5% for code-davinci-002).
These results indicate that large models can override prior knowledge from pre-training when contradicting input-label mappings are presented in-context. Small models can’t do this, making this ability an emergent phenomena of model scale.
Semantically-unrelated labels
In this experiment, we replace labels with semantically-irrelevant ones (e.g., for sentiment analysis, we use “foo/bar” instead of “negative/positive”), which means that the model can only perform ICL by learning from input-label mappings. If a model mostly relies on prior knowledge for ICL, then its performance should decrease after this change since it will no longer be able to use semantic meanings of labels to make predictions. A model that can learn input–label mappings in-context, on the other hand, would be able to learn these semantically-unrelated mappings and should not experience a major drop in performance.
 |
| Small models rely more on semantic priors than large models do, as indicated by the greater decrease in performance for small models than for large models when using semantically-unrelated labels (i.e., targets) instead of natural language labels. For each plot, models are shown in order of increasing model size (e.g., for GPT-3 models, a is smaller than b, which is smaller than c). |
Indeed, we see that using semantically-unrelated labels results in a greater performance drop for small models. This suggests that smaller models primarily rely on their semantic priors for ICL rather than learning from the presented input-label mappings. Large models, on the other hand, have the ability to learn input-label mappings in-context when the semantic nature of labels is removed.
We also find that including more in-context examples (i.e., exemplars) results in a greater performance improvement for large models than it does for small models, indicating that large models are better at learning from in-context examples than small models are.
 |
| In the SUL-ICL setup, larger models benefit more from additional examples than smaller models do. |
Instruction tuning
Instruction tuning is a popular technique for improving model performance, which involves tuning models on various NLP tasks that are phrased as instructions (e.g., “Question: What is the sentiment of the following sentence, ‘This movie is great.’ Answer: Positive”). Since the process uses natural language labels, however, an open question is whether it improves the ability to learn input-label mappings or whether it strengthens the ability to recognize and apply semantic prior knowledge. Both of these would lead to an improvement in performance on standard ICL tasks, so it’s unclear which of these occur.
We study this question by running the same two setups as before, only this time we focus on comparing standard language models (specifically, PaLM) with their instruction-tuned variants (Flan-PaLM).
First, we find that Flan-PaLM is better than PaLM when we use semantically-unrelated labels. This effect is very prominent in small models, as Flan-PaLM-8B outperforms PaLM-8B by 9.6% and almost catches up to PaLM-62B. This trend suggests that instruction tuning strengthens the ability to learn input-label mappings, which isn’t particularly surprising.
 |
| Instruction-tuned language models are better at learning input–label mappings than pre-training–only language models are. |
More interestingly, we saw that Flan-PaLM is actually worse than PaLM at following flipped labels, meaning that the instruction tuned models were unable to override their prior knowledge (Flan-PaLM models don’t reach below random guessing with 100% flipped labels, but PaLM models without instruction tuning can reach 31% accuracy in the same setting). These results indicate that instruction tuning must increase the extent to which models rely on semantic priors when they’re available.
 |
| Instruction-tuned models are worse than pre-training–only models at learning to override semantic priors when presented with flipped labels in-context. |
Combined with the previous result, we conclude that although instruction tuning improves the ability to learn input-label mappings, it strengthens the usage of semantic prior knowledge more.
Conclusion
We examined the extent to which language models learn in-context by utilizing prior knowledge learned during pre-training versus input-label mappings presented in-context.
We first showed that large language models can learn to override prior knowledge when presented with enough flipped labels, and that this ability emerges with model scale. We then found that successfully doing ICL using semantically-unrelated labels is another emergent ability of model scale. Finally, we analyzed instruction-tuned language models and saw that instruction tuning improves the capacity to learn input-label mappings but also strengthens the use of semantic prior knowledge even more.
Future work
These results underscore how the ICL behavior of language models can change depending on their scale, and that larger language models have an emergent ability to map inputs to many types of labels, a form of reasoning in which input-label mappings can potentially be learned for arbitrary symbols. Future research could help provide insights on why these phenomena occur with respect to model scale.
Acknowledgements
This work was conducted by Jerry Wei, Jason Wei, Yi Tay, Dustin Tran, Albert Webson, Yifeng Lu, Xinyun Chen, Hanxiao Liu, Da Huang, Denny Zhou, and Tengyu Ma. We would like to thank Sewon Min and our fellow collaborators at Google Research for their advice and helpful discussions.