
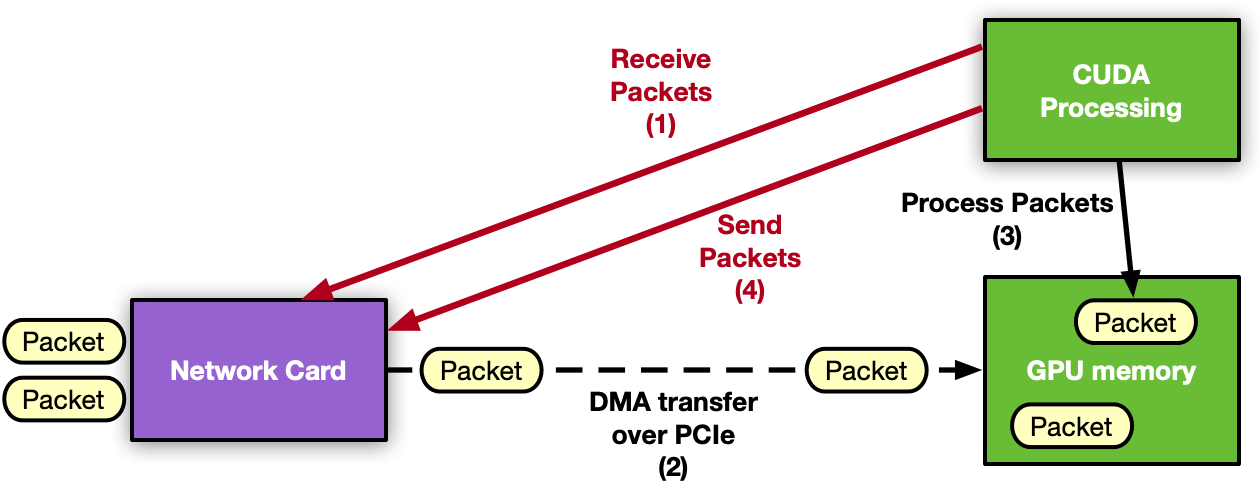
 Real-time processing of network traffic can be leveraged by the high degree of parallelism GPUs offer. Optimizing packet acquisition or transmission in these…
Real-time processing of network traffic can be leveraged by the high degree of parallelism GPUs offer. Optimizing packet acquisition or transmission in these…
Real-time processing of network traffic can be leveraged by the high degree of parallelism GPUs offer. Optimizing packet acquisition or transmission in these types of applications avoids bottlenecks and enables the overall execution to keep up with high-speed networks. In this context, DOCA GPUNetIO promotes the GPU as an independent component that can exercise network and compute tasks without the intervention of the CPU.
This post provides a list of GPU packet processing applications focusing on different and unrelated contexts where NVIDIA DOCA GPUNetIO has been integrated to lower latency and maximize performance.
NVIDIA DOCA GPUNetIO API
NVIDIA DOCA GPUNetIO is one of the new libraries released with the NVIDIA DOCA software framework. The DOCA GPUNetIO library enables direct communication between the NIC and the GPU through one or more CUDA kernels. This removes the CPU from the critical path.
Using the CUDA device functions in the DOCA GPUNetIO library, a CUDA kernel can send and receive packets directly from and to the GPU without the need of CPU cores or memory. Key features of this library include:
- GPUDirect Async Kernel-Initiated Network (GDAKIN): Communications over Ethernet; GPU (CUDA kernel) can directly interact with the network card to send or receive packets in GPU memory (GPUDirect RDMA) without the intervention of the CPU.
- GPU memory exposure: Combine within a single function the basic CUDA memory allocation feature with the GDRCopy library to expose a GPU memory buffer to the direct access (read or write) from the CPU without using CUDA API.
- Accurate Send Scheduling: From the GPU, it’s possible to schedule the transmission of a burst of packets in the future, associate a timestamp to it, and provide this information to the network card, which will in turn take care of sending packets at the right time.
- Semaphores: Useful message passing object to share information and synchronize across different CUDA kernels or between a CUDA kernel and a CPU thread.
For a deep dive into the principles and benefits of DOCA GPUNetIO, see Inline GPU Packet Processing with NVIDIA DOCA GPUNetIO. For more details about DOCA GPUNetIO API, refer to the DOCA GPUNetIO SDK Programming Guide.
Along with the library, the following NVIDIA DOCA application and NVIDIA DOCA sample show how to use functions and features offered by the library.
- NVIDIA DOCA application: A GPU packet processing application that can detect, manage, filter, and analyze UDP, TCP, and ICMP traffic. The application also implements an HTTP over TCP server. With a simple HTTP client (curl or wget, for example), it’s possible to establish a TCP three-way handshake connection and ask for simple HTML pages through HTTP GET requests to the GPU.
- NVIDIA DOCA sample: GPU send-only example that shows how to use the Accurate Send Scheduling feature (system configuration, functions to use).
DOCA GPUNetIO in real-world applications
DOCA GPUNetIO has been used to empower the NVIDIA Aerial SDK to send and receive using the GPU, getting rid of the CPU. For more details, see Inline GPU Packet Processing with NVIDIA DOCA GPUNetIO. The sections below provide new examples that successfully use DOCA GPUNetIO to leverage the GPU packet acquisition with the GDAKIN technique.
NVIDIA Morpheus AI
NVIDIA Morpheus is a performance-oriented, application framework that enables cybersecurity developers to create fully optimized AI pipelines for filtering, processing, and classifying large volumes of real-time data. The framework abstracts GPU and CPU parallelism and concurrency through an accessible programming model consisting of Python and C++ APIs.
Leveraging this framework, developers can quickly construct arbitrary data pipelines composed of stages that acquire, mutate, or publish data for a downstream consumer. You can apply Morpheus in different contexts including malware detection, phishing/spear phishing detection, ransomware detection, and many others. Its flexibility and high performance are ideal for real-time network traffic analysis.
For the network monitoring use case, the NVIDIA Morpheus team recently integrated the DOCA framework to implement a high-speed, low-latency GPU packet acquisition source stage to feed real-time packets to an AI-pipeline responsible for analyzing packets’ contents. For more details, visit Morpheus on GitHub.
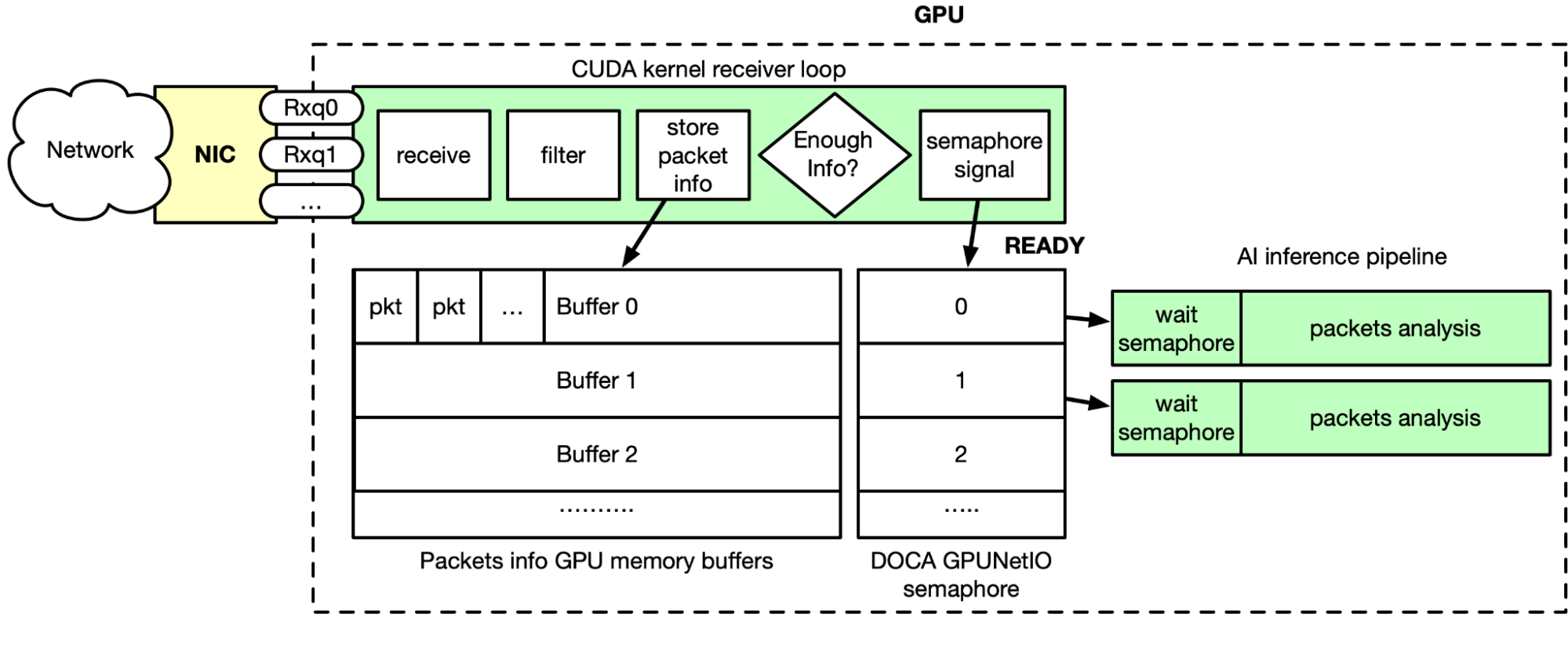
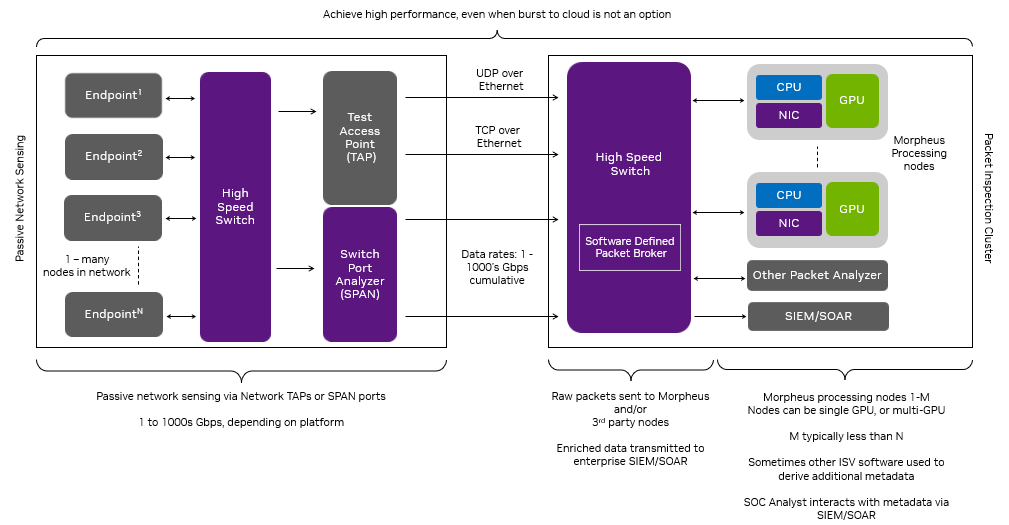
As shown in Figure 2, GPU packet acquisition happens in real time. Through DOCA Flow, flow steering rules are applied to the Ethernet receive queues, meaning queues can only receive specific types of packets (TCP, for example). Morpheus launches a CUDA kernel, which performs the following steps in a loop:
- Receive packets using DOCA GPUNetIO receive function
- Filter and analyze in parallel packets in GPU memory
- Copy relevant packets info in a list of GPU memory buffers
- The related DOCA GPUNetIO semaphore item is set to READY when a buffer has accumulated enough packets of information
- The CUDA kernel in front of the AI pipeline is polling the semaphore item
- When the item is READY, AI is unblocked as packet information is ready in the buffer
The GTC session Defensive Cyber Operations (DCO) on Edge Networks presents a concrete example in which this architecture is leveraged to deploy a high-performance, AI-enabled SPAN/Network TAP solution. This solution was motivated by the daunting data rates in information technology (IT) and operational technology (OT) networks, heterogeneity of Layer 7 application data, and edge computing size, weight, and power (SWaP) constraints.
In the case of edge computing, many organizations are unable to “burst to cloud” when the compute demand increases, especially on disconnected edge networks. This scenario requires designing an architecture for I/O and compute challenges that deliver performance across the SWaP spectrum.
This DCO example addresses these constraints through the lens of a common cybersecurity problem, identifying leaked data (leaked passwords, secret keys, and PII, for example) in unencrypted TCP traffic, and represents an extension of the Morpheus SID demo. Identifying and remediating these vulnerabilities reduces the attack surface and increases the security posture of organizations.
In this example, the DCO solution receives packets into a heterogeneous Morpheus pipeline (GPU and concurrent CPU stages written in a mix of Python and C++) that applies a transformer model to detect leaked sensitive data in Layer 7 application data. It integrates outputs with the ELK stack, including an intuitive visualization for Security Operations Center (SOC) analysts to exploit (Figures 3 and 4).
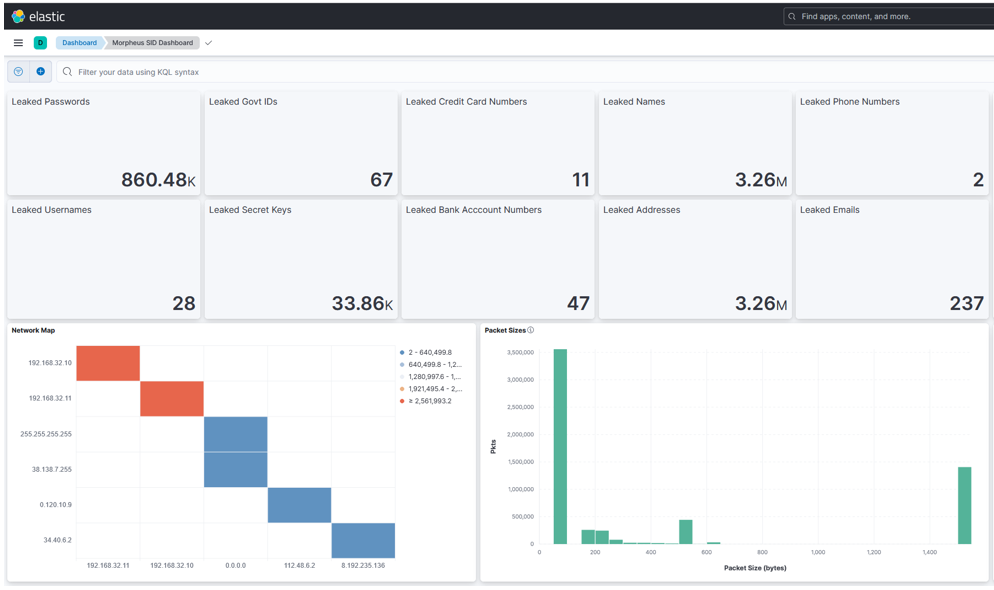
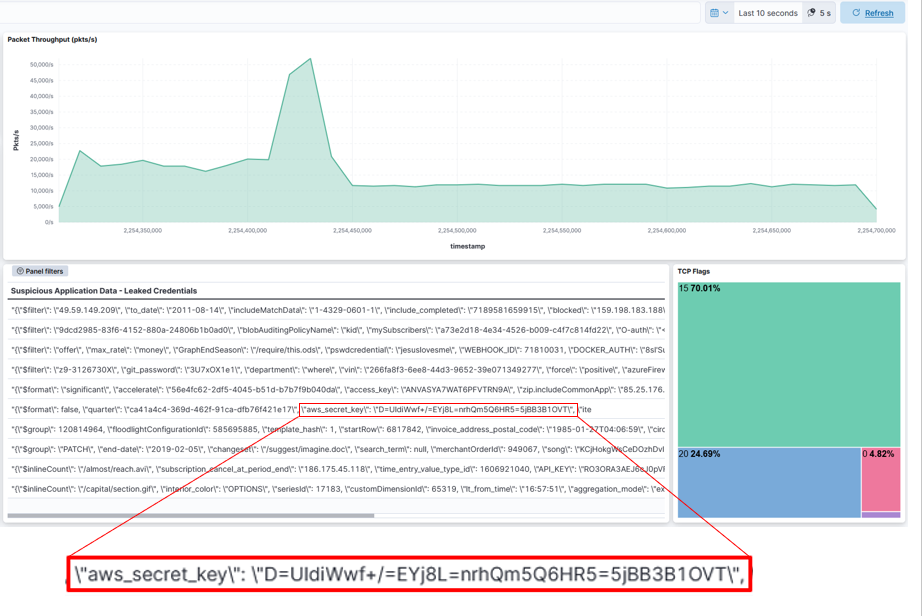
The experimental setup included cloud-native UDP multicast and REST applications running on VMs with a 100 Gbps NVIDIA BlueField-2 DPU. These applications communicated through a SWaP-efficient NVIDIA Spectrum SN2100 Ethernet switch. Packet generators injected sensitive data into packets transmitted by these applications. Network packets were aggregated and mirrored off a SPAN port on the NVIDIA Spectrum SN2100 and sent to an NVIDIA A30X converged accelerator powering the Morpheus packet inspection pipeline achieving impressive throughput results.
- This pipeline includes several components from I/O, packet filtering, packet processing, and indexing in a third-party SIEM platform (Elasticsearch). Focusing only on the I/O aspects, DOCA GPUNetIO enables Morpheus to receive packets into GPU memory at up to 100 Gbps with a single receive queue, removing a critical bottleneck in cyber packet processing applications.
- Leveraging stage level concurrency, the pipeline demonstrated a 60% boost in Elasticsearch indexing throughput.
- Running the end-to-end data pipeline on the NVIDIA A30X converged accelerator generated enriched packets at ~50% capacity of the elasticsearch indexer. Using twice as many A30Xs would fully saturate the indexer, providing a convenient scaling heuristic.
While this use case demonstrates a specific application of Morpheus, it represents the foundational components for cyber packet processing applications. Morpheus plus DOCA GPUNetIO together provide the performance and extensibility for a huge number of latency-sensitive and compute-intensive packet processing applications.
Line-rate radar signal processing
This section walks through an example in which the radar detection application ingests downconverted I/Q samples from a simulated range-only radar system at line rate of 100 Gbps, performing all required signal processing needed to convert the received I/Q RF samples into object detections in real time.
Remote sensing applications such as radar, lidar, and optical platforms rely on signal processing algorithms to turn the raw data collected from the environment they are measuring into actionable information. These algorithms are often highly parallelizable and require a high computational load, making them ideal for GPU-based processing.
Additionally, input sensors generate enormous quantities of raw data, meaning the ingress/egress capability of the processing solution must be able to handle very high bandwidths at low latencies.
Further complicating the problem, many edge-based sensor systems have strict SWaP constraints, restricting the number and power of available CPU cores that might be used in other high-throughput networking approaches, such as DPDK-based GPUDirect RDMA.
DOCA GPUNetIO enables the GPU to directly handle the networking load as well as the signal processing required to make a real-time sensor streaming application successful.
Commonly used signal processing algorithms were used in the radar detection application. The flowchart in Figure 6 shows a graphical representation of the signal processing pipeline being used to convert the I/Q samples into detections.

MTI filtering is a common technique used to eliminate stationary background clutter, such as the ground or buildings, from the reflected RF waveform in radar systems. The approach used here is known as the Three-Pulse Canceler, which is simply a convolution of the I/Q data in the pulse dimension with the filter coefficients ‘[+1, -2, +1].’
Pulse Compression maximizes the signal-to-noise ratio (SNR) of the received waveform with respect to the presence of targets. It is performed by computing the cross-correlation of the received RF data with the transmitted waveform.
Constant False Alarm Rate (CFAR) detectors compute an empirical estimate of the noise, localized to each range bin of the filtered data. The power of each bin is then compared to the noise and declared a detection if it is statistically likely given the noise estimate and distribution.
A 3D buffer of size (# Waveforms) x (# Channels) x (# Samples) is used to hold the organized RF data being received (note that applying the MTI filter upon packet receipt reduces the size of the pulse dimension to 1). No ordering is assumed to the UDP data streaming in, except that it is streamed roughly in order of the packets’ ascending waveform ID. Around 500 complex samples are transmitted per-packet, and the samples’ location in the 3D buffer is dependent on the waveform ID, channel ID, and sample index.
This application runs two CUDA kernels and one CPU core persistently. The first CUDA kernel is responsible for using the DOCA GPUNetIO API to read packets from the NIC onto the GPU. The second CUDA kernel places packet data into the correct memory location based on metadata in the packets header and applies the MTI filter, and the CPU core is responsible for launching the CUDA kernels that handle Pulse Compression and CFAR. The FFTs were performed using the cuFFT library.
Figure 7 shows a graphical representation of the application.
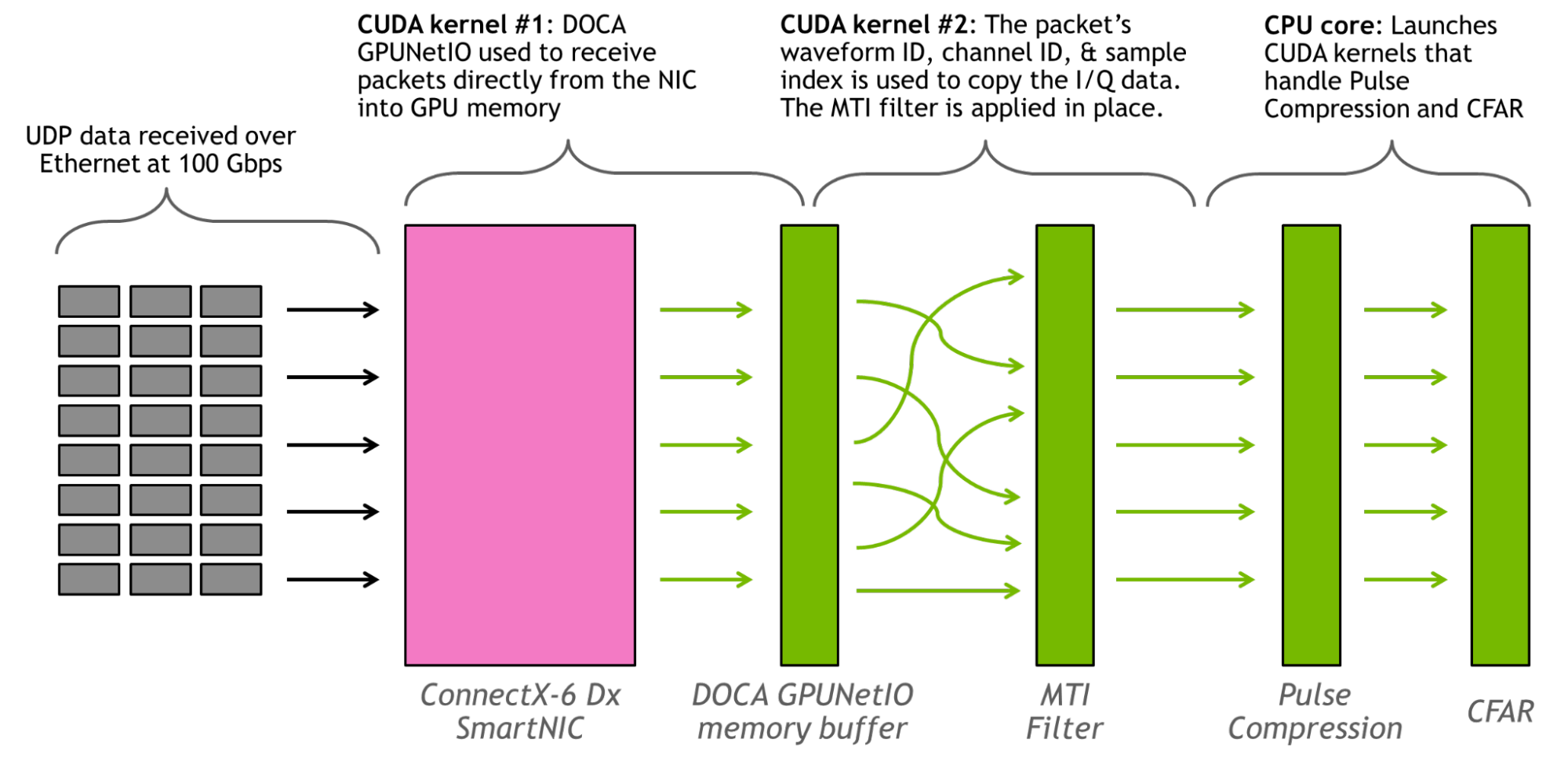
The throughput of the radar detection pipeline is >100 Gbps. Running at the line rate of 100 Gbps for 1 million 16-channel waveforms, no packets were dropped and the signal processing never fell behind the throughput of the data stream. The latency, measured from when the last data packet for an independent waveform ID was received, was on the order of 3 milliseconds. An NVIDIA ConnectX-6 Dx SmartNIC and an NVIDIA A100 80 GB GPU were used. Data was sent through UDP packets over Ethernet.
Future work will evaluate the performance of this architecture when running exclusively on a BlueField DPU with an integrated GPU.
Real-time DSP services over GPU
Analog signals are everywhere, both artificial (Wi-Fi radio, for example) and natural (solar radiation and earthquakes, for example). To capture analog data digitally, sound waves must be converted using a D-A converter, controlled by parameters such as sample rate and sample bit depth. Digital audio and video can be processed with FFT, allowing sound designers to use tools such as an equalizer (EQ) to alter general characteristics of the signal.
This example explains how NVIDIA products and SDK were used to perform real-time audio DSP with GPU over the network. To do so, the team built a client that parses a WAV file, frames data into multiple Ethernet packets, and sends them over the network to a server application. This application is responsible for receiving packets, applying FFT, manipulating the audio signal, and finally sending back the modified data.
The client’s responsibility is recognizing which portion should be sent to the “server” for the signal processing chain and how to treat the processed samples when they are received back from the server. This approach supports multiple DSP algorithms, such as overlap-add, and various sample window selections.
The server application uses DOCA GPUNetIO to receive packets in GPU memory from a CUDA kernel. When a subset of packets has been received, the CUDA kernel in parallel applies the FFT through the cuFFTDx library to each packet’s payload. In parallel, to each packet, a different CUDA thread applies a frequency filter reducing the amplitude of low or high frequencies. Basically, it applies a low-pass or high-pass filter.
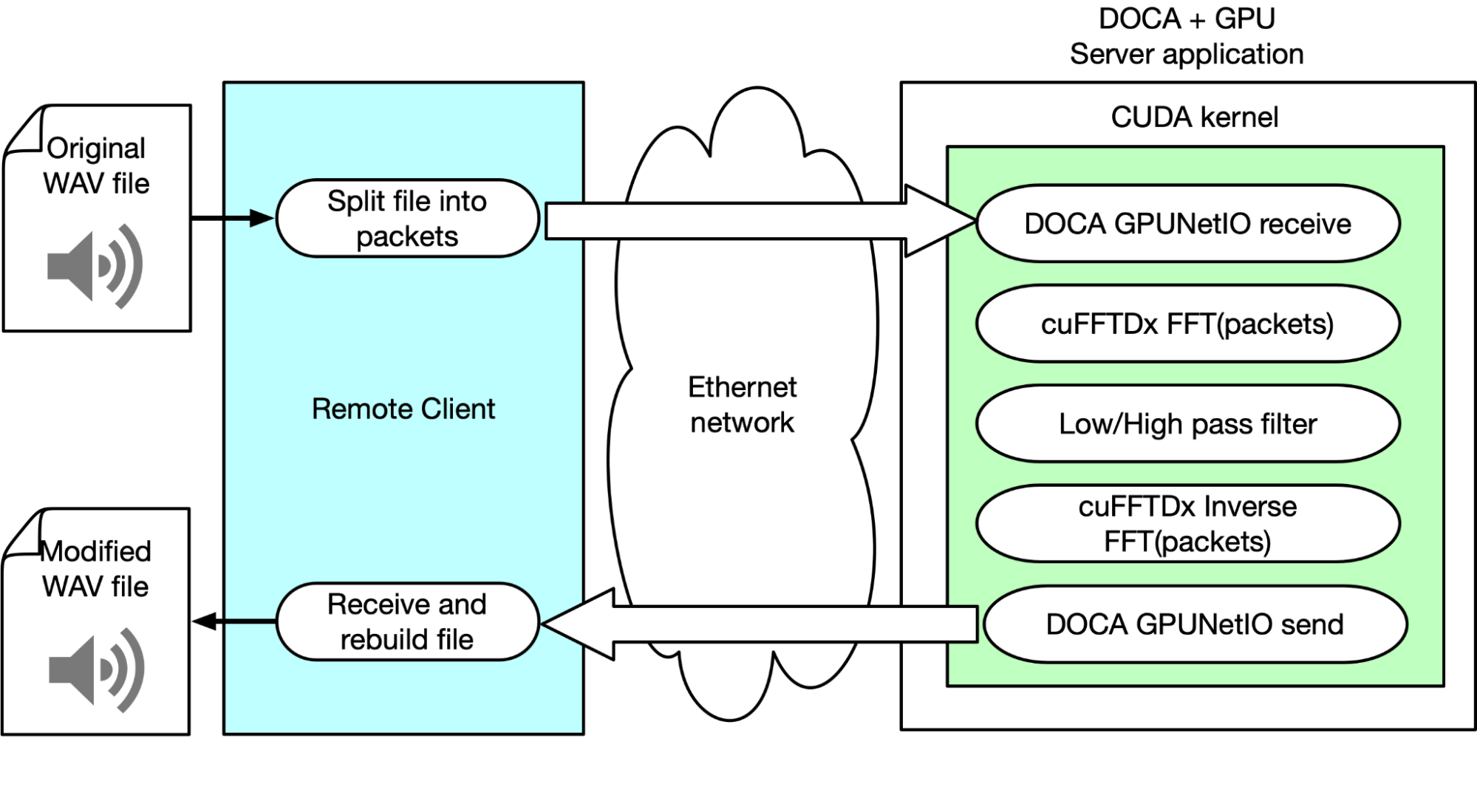
An inverse FFT is applied to each packet. Through DOCA GPUNetIO, the CUDA kernel sends back to the client the modified packets. The client reorders packets and rebuilds them to recreate an audible and reproducible WAV audio file with sound effects applied.
Using the client, the team could tweak parameters to optimize performance and the quality of the audio output. It is possible to separate the flows and multiplex streams into their processing chains, thus offloading many complex computations into the GPU. This is just scratching the potential of this solution, which could open new market opportunities for cloud DSP service providers.
Summary
DOCA GPUNetIO library promotes a generic GPU-centric approach for both packets’ acquisition and transmission in network applications exercising real-time traffic analysis. This post demonstrates how this library can be adopted in a wide range of applications from different contexts, providing huge improvements for latency, throughput, and system resource utilization.
To learn more about GPU packet processing and GPUNetIO, see the following resources: