Large language models (LLMs), such as GPT, have emerged as revolutionary tools in natural language processing (NLP) due to their ability to understand and…
Large language models (LLMs), such as GPT, have emerged as revolutionary tools in natural language processing (NLP) due to their ability to understand and…
Large language models (LLMs), such as GPT, have emerged as revolutionary tools in natural language processing (NLP) due to their ability to understand and generate human-like text. These models are trained on vast amounts of diverse data, enabling them to learn patterns, language structures, and contextual relationships. They serve as foundational models that can be customized to a wide range of downstream tasks, making them highly versatile.
Downstream tasks, such as classification, can include the analysis and categorization of text based on predefined criteria, aiding in tasks like sentiment analysis or spam detection. In closed question-answering (QA), they can provide precise answers based on the given context. In generation tasks, they can produce human-like text, such as story writing or poem composition. Even when it comes to brainstorming, LLMs can generate creative and coherent ideas by leveraging their vast knowledge base.
The adaptability and versatility of LLMs make them invaluable tools for a wide range of applications, empowering businesses, researchers, and individuals to accomplish various tasks with remarkable efficiency and accuracy.
This post shows you how LLMs can be adapted to downstream tasks using distributed datasets and federated learning to preserve privacy and enhance model performance.
Adaptation of LLMs to downstream tasks
Parameter-efficient fine-tuning of LLMs using task-specific modules has gained prominence. This approach involves keeping the pretrained LLM layers fixed while adapting a smaller set of additional parameters to the specific task at hand. Various techniques have been developed to facilitate this process, including prompt tuning, p-tuning, adapters, LoRA, and others.
For example, p-tuning involves freezing the LLM and learning to predict virtual token embeddings that are combined with the original input text, as shown in Figure 1. The task-specific virtual token embeddings are predicted by a prompt encoder network, which, along with the input word embeddings, are fed into the LLM to enhance performance on the downstream task at inference time. It is parameter efficient as only the prompt encoder parameters must be trained on the input text and labels, while the foundational LLM parameters can stay fixed.
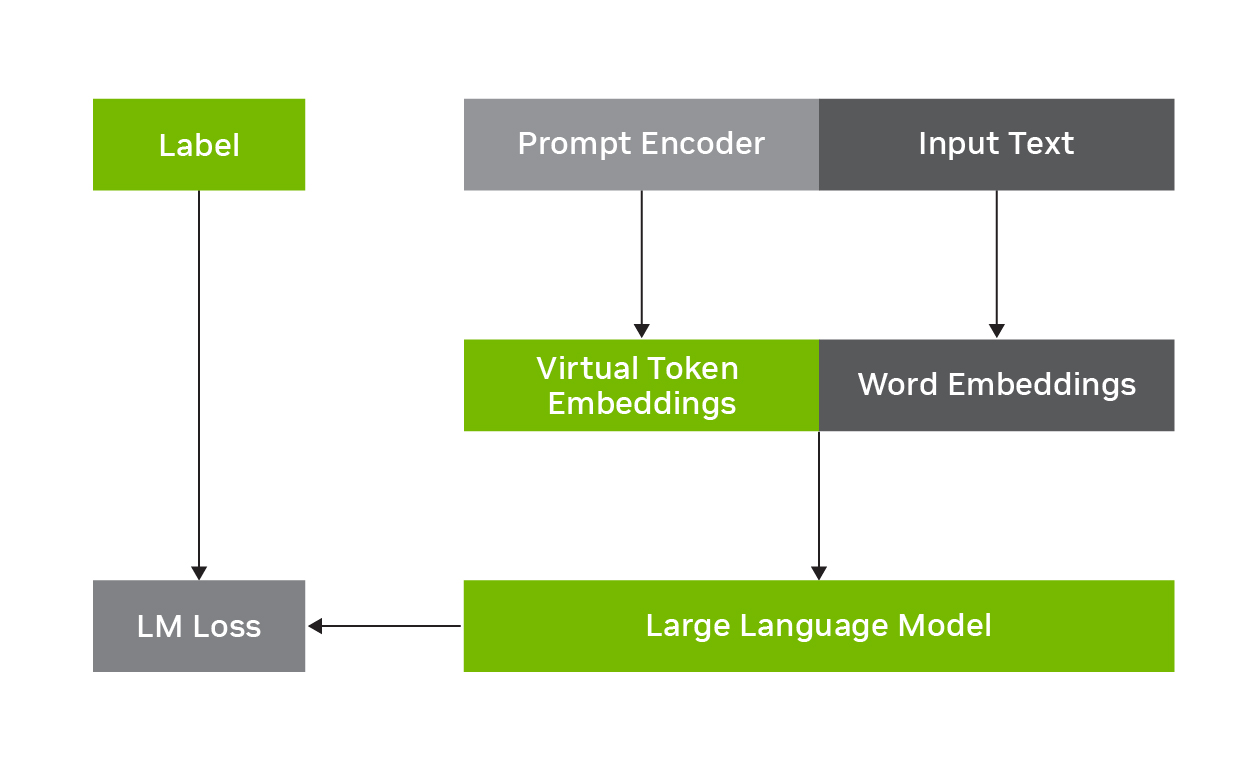
Federated learning
Using private data for training AI models poses significant challenges due to regulatory constraints and complex bureaucratic processes. Privacy regulations and data protection laws often prohibit sharing sensitive information, limiting the feasibility of traditional data-sharing approaches. Moreover, data annotation, a crucial aspect of model training, incurs substantial costs and demands significant time and effort.
Recognizing data as a valuable asset, federated learning (FL) has emerged as a technology to address these concerns. FL bypasses the conventional model training process by sharing models instead of raw data. Participating clients train models using their respective private datasets locally, and the updated model parameters are aggregated. This preserves the privacy of the underlying data while collectively benefiting from the knowledge gained during the training process.
No direct data exchange is needed, which mitigates the compliance risks associated with data privacy regulations and distributes the burdensome data annotation cost among collaborators in the federation.
Figure 2 shows federated p-tuning with global model and three clients. The LLM parameters stay fixed while prompt encoder parameters are trained on the local data. After local training, the new parameters are aggregated on the server to update the global model for the next round of federated learning.
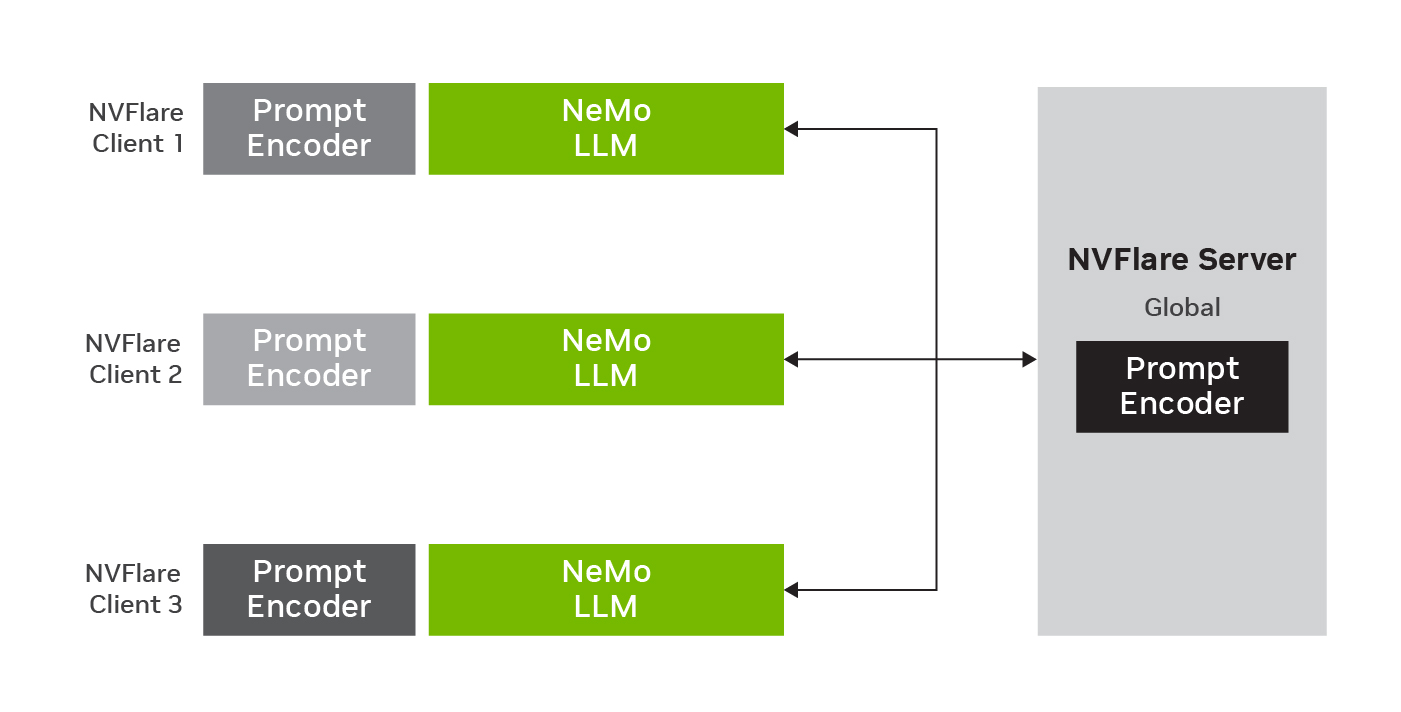
Federating the adaptation of LLMs to downstream tasks
FL enables this adaptation of LLMs to downstream tasks by leveraging decentralized data sources. By training LLMs collaboratively across multiple participants without sharing raw data, the accuracy, robustness, and generalizability of LLMs can be enhanced by leveraging collective knowledge and exposing models to a wider range of linguistic patterns (Figure 2). Additionally, FL offers various options for model adaptation and inference, including global models trained on aggregated data and personalized models tailored to individual clients.
Federated p-tuning for sentiment analysis
This section provides an example of federated adaptation of an LLM from NVIDIA NeMo framework for a downstream task with NVIDIA Flare using p-tuning. Both NeMo and NVIDIA Flare are open-source toolkits developed by NVIDIA. This fine-tuning process is efficient, as only a few dozen million parameters need to be exchanged, significantly reducing the communication burden.
In this sentiment analysis task, the NeMo Megatron-GPT model with 20 billion parameters can be efficiently fine-tuned using p-tuning. It uses the Financial PhraseBank dataset, which. contains the sentiments for financial news headlines from a retail investor’s perspective. For more details, see Good Debt or Bad Debt: Detecting Semantic Orientations in Economic Texts.
The example inputs and model predictions are shown in Figure 3. In total, this data contains 1,800 pairs of headlines and corresponding sentiment labels. In p-tuning, only 50 million parameters of a trainable prompt encoder network are updated (0.25% of the full 20B parameters). For FL experiments, the data is split into three sets, which correspond to 600 headlines and sentiment pairs for each site. The clients use the same validation set to enable a direct comparison.

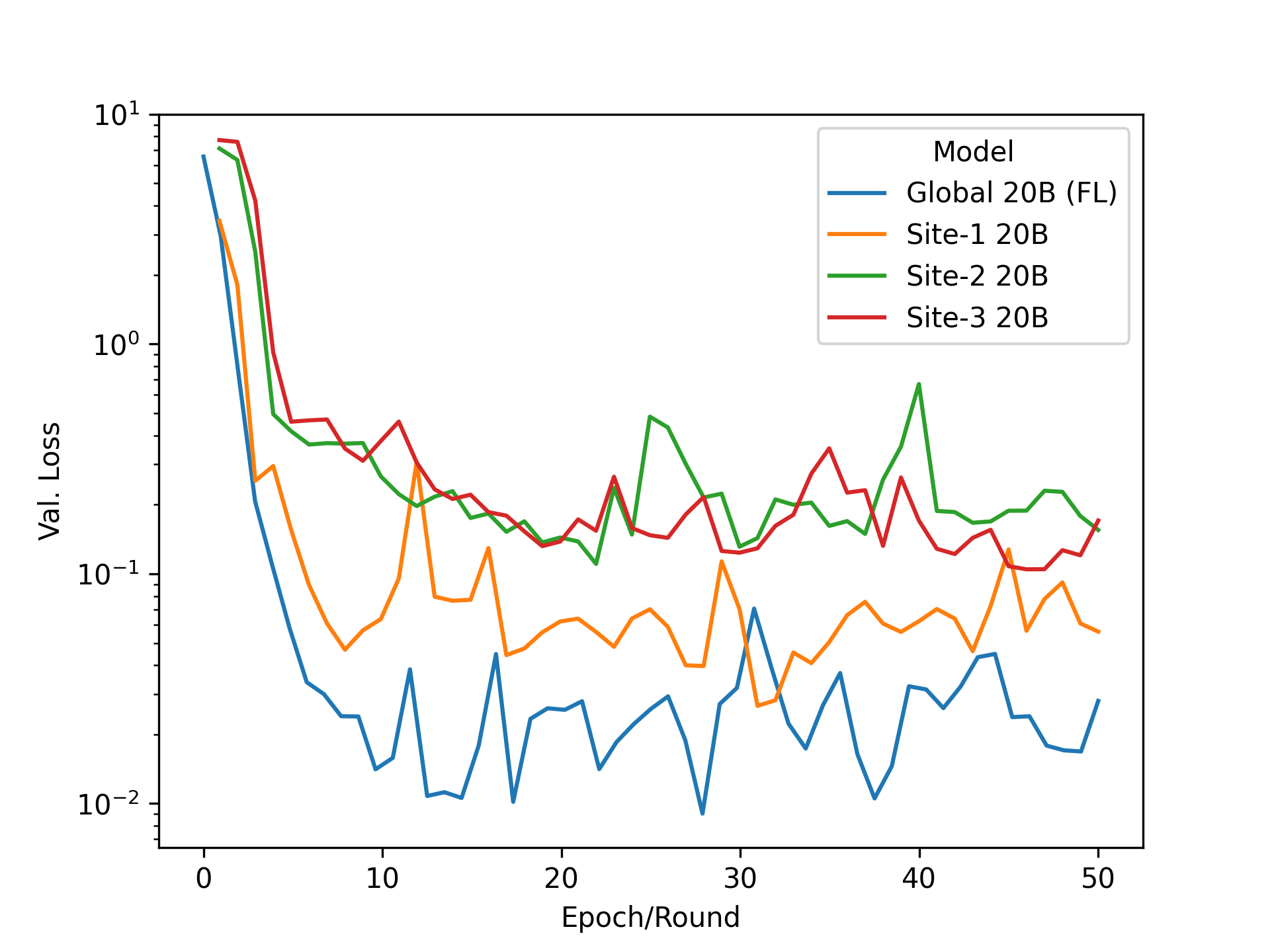
Figure 4a compares training the model in the centralized fashion compared to the federated model for 50 epochs (or FL rounds). In both settings, the adapted model performs comparably on the downstream task, achieving a similar low loss on the validation set. Figure 4b compares each client training on their local dataset only compared to the model p-tuned using FL. One can see a clear advantage for the global model using federated p-tuning by effectively making use of the larger training sets available in the collaboration and achieving a lower loss than clients training on their data alone.
Conclusion
Overall, this post highlights the potential of federated p-tuning in adapting LLMs to downstream tasks, emphasizing the benefits of FL in enabling collaborative learning for preserving privacy and enhancing model performance. Some key takeaways are:
- Large language models such as GPT have revolutionized NLP, offering versatility for various downstream tasks such as classification, question-answering, generation, and brainstorming.
- Federated learning addresses challenges related to private data by sharing model parameters instead of raw data, ensuring privacy and reducing compliance risks.
- Fine-tuning LLMs with task-specific modules, such as prompt-tuning or p-tuning, enables efficient adaptation to specific tasks.
- FL facilitates collaborative training and inference, leading to improved model performance.
For more information, see the NVIDIA Flare documentation and NVIDIA NeMo framework page. To replicate the experiments explained here and other LLM tasks, explore the Examples of NeMo-NVFlare Integration. The federated p-tuning approach presented here can be further combined with additional privacy-preserving solutions offered by NVIDIA Flare, such as homomorphic encryption and differential privacy. To learn more, see NVIDIA FLARE: Federated Learning from Simulation to Real-World.
 If you are a DirectX 12 (DX12) game developer, you may have noticed that GPU times displayed in real time in your game HUD may change over time for a given…
If you are a DirectX 12 (DX12) game developer, you may have noticed that GPU times displayed in real time in your game HUD may change over time for a given….jpg)
 Robotics simulation enables virtual training and programming that can use physics-based digital representations of environments, robots, machines, objects, and…
Robotics simulation enables virtual training and programming that can use physics-based digital representations of environments, robots, machines, objects, and…


 Organizations are increasingly adopting hybrid and multi-cloud strategies to access the latest compute resources, consistently support worldwide customers, and…
Organizations are increasingly adopting hybrid and multi-cloud strategies to access the latest compute resources, consistently support worldwide customers, and…









 The latest release of NVIDIA CUDA Toolkit 12.2 introduces a range of essential new features, modifications to the programming model, and enhanced support for…
The latest release of NVIDIA CUDA Toolkit 12.2 introduces a range of essential new features, modifications to the programming model, and enhanced support for…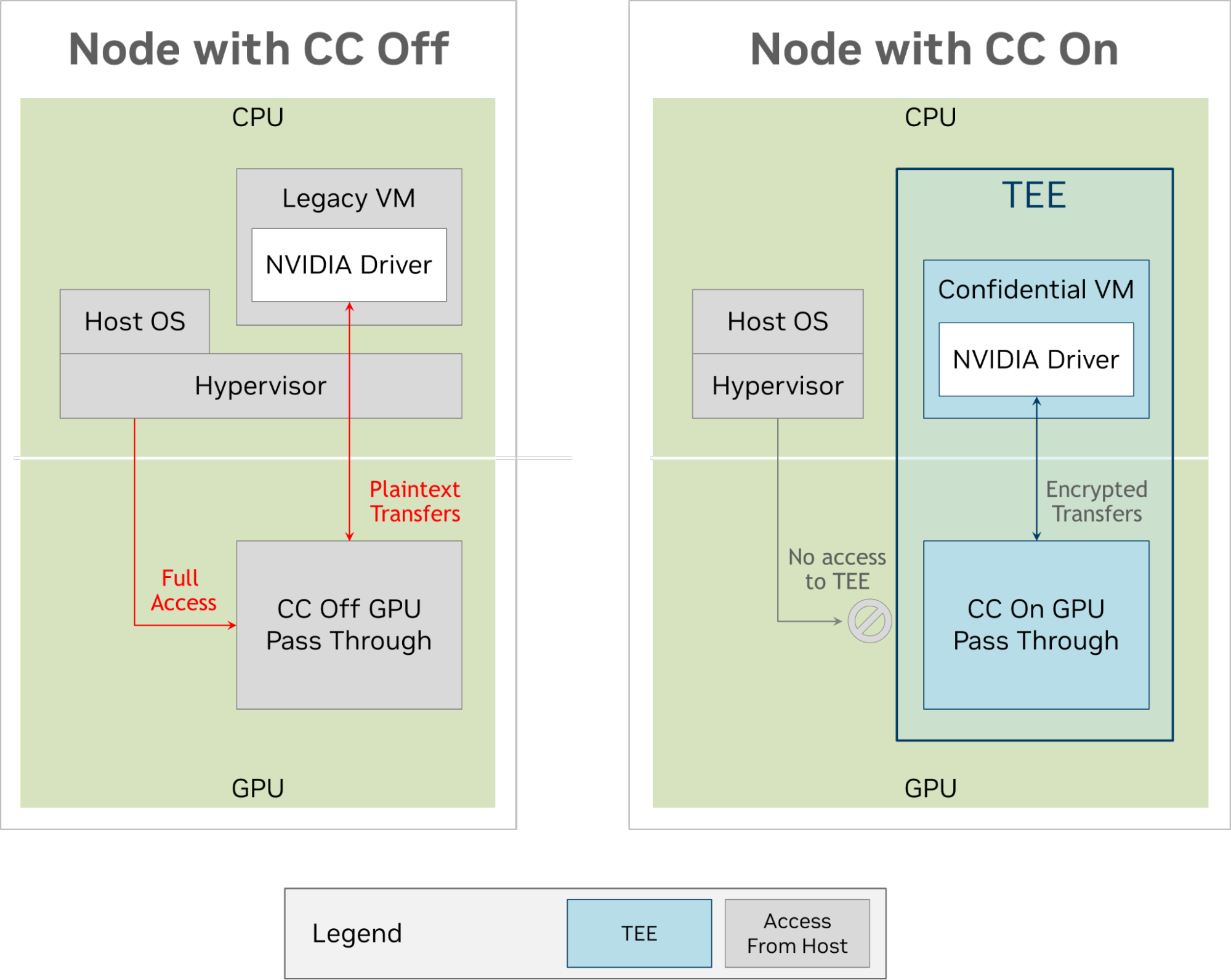
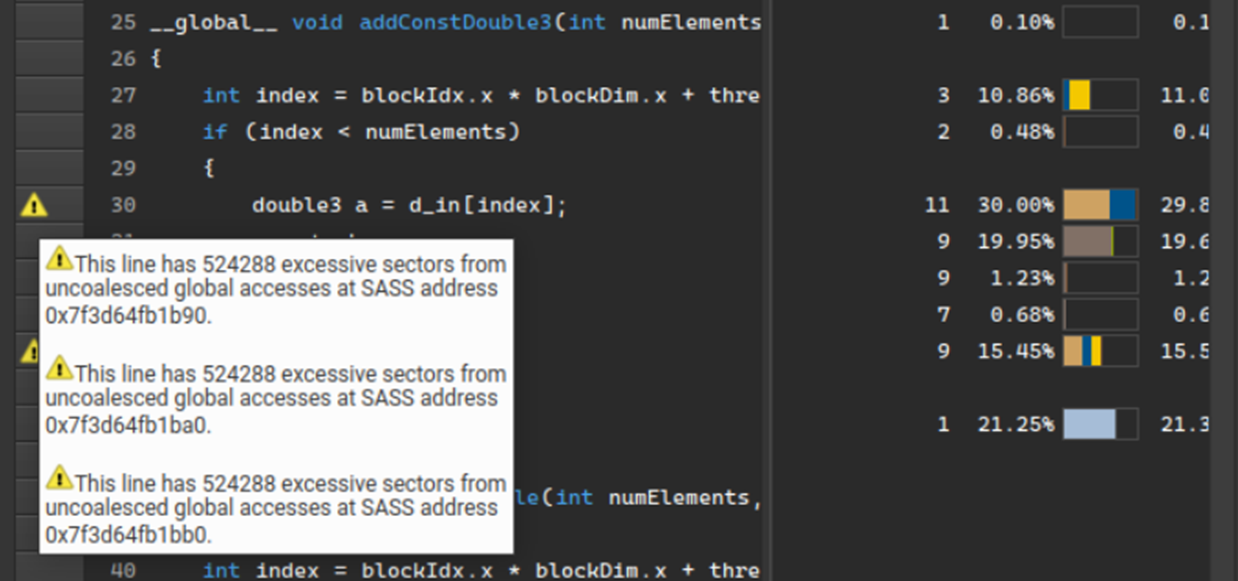
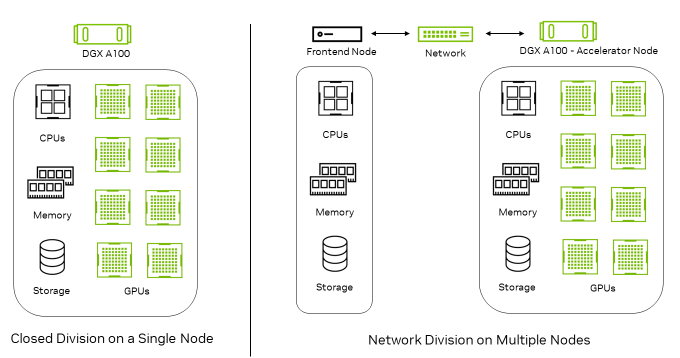
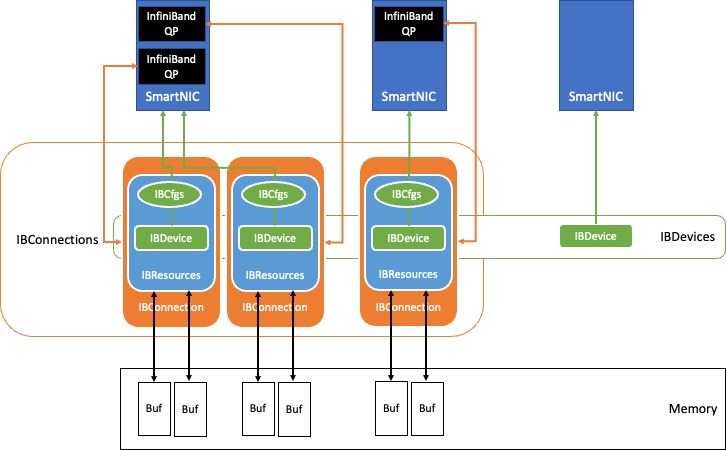
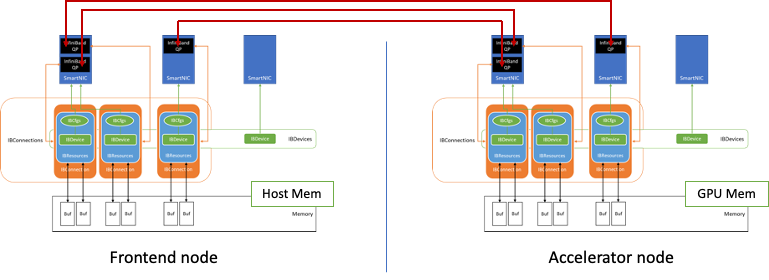
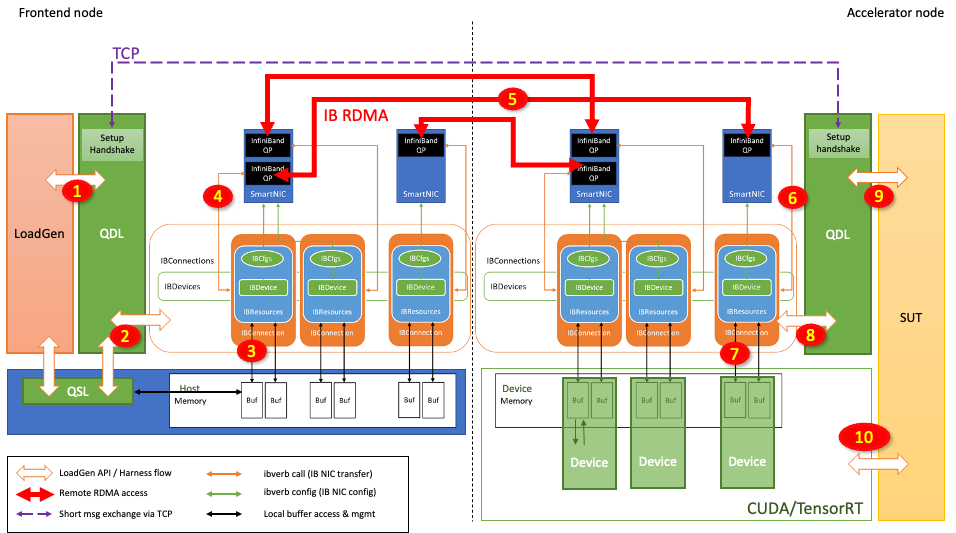
 In MLPerf Inference v3.0, NVIDIA made its first submissions to the newly introduced Network division, which is now part of the MLPerf Inference Datacenter…
In MLPerf Inference v3.0, NVIDIA made its first submissions to the newly introduced Network division, which is now part of the MLPerf Inference Datacenter…