NVIDIA Triton Inference Server streamlines and standardizes AI inference by enabling teams to deploy, run, and scale trained ML or DL models from any framework…
NVIDIA Triton Inference Server streamlines and standardizes AI inference by enabling teams to deploy, run, and scale trained ML or DL models from any framework on any GPU- or CPU-based infrastructure. It helps developers deliver high-performance inference across cloud, on-premises, edge, and embedded devices.
The nvOCDR library is integrated into Triton for inference. The nvOCDR library wraps the entire inference pipeline for optical character detection and recognition (OCD/OCR). This library consumes OCDNet and OCRNet models that are trained on TAO Toolkit. For more details, refer to the nvOCDR documentation.
This post is part of a series on using NVIDIA TAO and pretrained models to create and deploy custom AI models to accurately detect and recognize handwritten texts. Part 1 explains the training and fine-tuning of character detection and recognition models using TAO. This part walks you through the steps to deploy the model using NVIDIA Triton. The steps presented can be used with any other OCR tasks.
Build the Triton sample with OCD/OCR models
The following steps show the simple and recommended way to build and use OCD/OCR models in Triton Inference Server with Docker images.
Step 1: Prepare the ONNX models
Once you follow ocdnet.ipynb and ocrnet.ipynb to finish the model training and export, you could get two ONNX models, such as ocdnet.onnx and ocrnet.onnx. (In ocdnet.ipynb, the exported ONNX is named model_best.onnx. In ocrnet.ipynb, the exported ONNX is named best_accuracy.onnx.)
The building process of Triton server and client Docker images can be launched automatically by running related scripts:
$ cd NVIDIA-Optical-Character-Detection-and-Recognition-Solution/triton
# bash setup_triton_server.sh [input image height] [input image width] [OCD input max batchsize] [DEVICE] [ocd onnx path] [ocr onnx path] [ocr character list path]
$ bash setup_triton_server.sh 1024 1024 4 0 ~/onnx_models/ocd.onnx ~/onnx_models/ocr.onnx ~/onnx_models/ocr_character_list
Step 4: Build the Triton client Docker image
Use the following script to build the Triton client Docker image:
$ cd NVIDIA-Optical-Character-Detection-and-Recognition-Solution/triton
$ bash setup_triton_client.sh
Step 5: Run nvOCDR Triton server
After building the Triton server and Triton client docker image, create a container and launch the Triton server:
$ docker run -it --net=host --gpus all --shm-size 8g nvcr.io/nvidian/tao/nvocdr_triton_server:v1.0 bash
Next, modify the config file of nvOCDR lib. nvOCDR lib can support high-resolution input images (4000 x 4000 or larger). If your input images are large, you can change the configure file to /opt/nvocdr/ocdr/triton/models/nvOCDR/spec.json in the Triton server container to support the high resolution images inference.
# to support high resolution images
$ vim /opt/nvocdr/ocdr/triton/models/nvOCDR/spec.json
"is_high_resolution_input": true,
"resize_keep_aspect_ratio": true,
The resize_keep_aspect_ratio will be set to True automatically if you set the is_high_resolution_input to True. If you are going to infer images that have smaller resolution (640 x 640 or 960 x 1280, for example) you can set the is_high_resolution_input to False.
In the container, run the following command to launch the Triton server:
In a separate console, launch the nvOCDR example from the Triton client container:
$ docker run -it --rm -v : --net=host nvcr.io/nvidian/tao/nvocdr_triton_client:v1.0 bash
Launch the inference:
$ python3 client.py -d -bs 1
Figure 1. Predicted output from OCDNet and OCRNet on a sample handwritten image
Conclusion
NVIDIA TAO 5.0 introduced several features and models for Optical Character Detection (OCD) and Optical Character Recognition (OCR). This post walks through the steps to customize and fine-tune the pretrained model to accurately recognize handwritten texts on the IAM dataset. This model achieves 90% accuracy for character detection and about 80% for character recognition. All the steps mentioned in the post can be run from the provided Jupyter notebook, making it easy to create custom AI models with minimal coding.
Next-generation AI pipelines have shown incredible success in generating high-fidelity 3D models, ranging from reconstructions that produce a scene matching…
Next-generation AI pipelines have shown incredible success in generating high-fidelity 3D models, ranging from reconstructions that produce a scene matching given images to generative AI pipelines that produce assets for interactive experiences.
These generated 3D models are often extracted as standard triangle meshes. Mesh representations offer many benefits, including support in existing software packages, advanced hardware acceleration, and supporting physics simulation. However, not all meshes are equal, and these benefits are only realized on a high-quality mesh.
Recent NVIDIA research discovered a new approach called FlexiCubes for generating high-quality meshes in 3D pipelines, improving quality across a range of applications.
FlexiCubes mesh generation
Figure 1. Example mesh reconstructed by FlexiCubes
The common ingredient across AI pipelines from reconstruction to simulation is that meshes are generated from an optimization process. At each step of the process, the representation is updated to match the desired output better.
The new idea of FlexiCubes mesh generation is to introduce additional, flexible parameters that precisely adjust the generated mesh. By updating these parameters during optimization, mesh quality is greatly improved.
Those familiar with mesh-based pipelines might have used marching cubes in the past to extract meshes. FlexiCubes can be used as a drop-in replacement for marching cubes in optimization-based AI pipelines.
Figure 2. FlexiCubes high-quality mesh
FlexiCubes generates high-quality meshes from neural workflows like photogrammetry and generative AI.
Better meshes, better AI
FlexiCubes mesh extraction improves the results of many recent 3D mesh generation pipelines, producing higher-quality meshes that do a better job at representing fine details in complex shapes.
The generated meshes are also well-suited for physics simulation, where mesh quality is especially important to make simulations efficient and robust. The tetrahedral meshes are ready to use in out-of-the-box physics simulations.
Thousands of hackers will tweak, twist and probe the latest generative AI platforms this week in Las Vegas as part of an effort to build more trustworthy and inclusive AI. Read article >
Rise and shine, it’s time to quake up — the GeForce NOW Ultimate KovaaK’s challenge kicks off at the QuakeCon gaming festival today, giving gamers everywhere the chance to play to their ultimate potential with ultra-high 240 frames per second streaming. On top of bragging rights, top scorers can win some sweet prizes — including a 240Hz gaming monitor Read article >
Visual effects studios have long relied on render farms — vast numbers of servers — for computationally intensive, complex special effects, but that landscape is rapidly changing. Read article >
Soccer is considered one of the most popular sports around the world. And with good reason: the action is often intense, and the game combines both physicality…
Soccer is considered one of the most popular sports around the world. And with good reason: the action is often intense, and the game combines both physicality and skill from the players that can be thrilling to watch. So it should come as no surprise that there are folks out there who are working to teach robots the finer points of the game, including how to gather the ball, line up a shot, pass, and score a goal.
The team built their omnidirectional robot with a monocular camera that can autonomously perform the following tasks:
Localization
Soccer ball detection and grabbing
Coordinate calculation
Passing the ball to other team robots
Scoring on an empty goal
The team built the robot with an AI software pipeline running at an average processing speed of 30 FPS, with the hardware consuming only around 10.8 W of power.
The robot has a kicking device on its front and is a four-wheeled omnidirectional robot. Figure 1 shows the geometry of the robot.
Figure 1. The movement capabilities of the omnidirectional robot powered by the NVIDIA Jetson Nano Developer Kit to execute soccer tasks autonomously
“We evaluate our system on three soccer tasks: grabbing a ball, scoring a goal, and passing the ball, achieving 80%, 80%, and 46.7% success rates, respectively,” the team explains in Towards an Autonomous RoboCup Small Size League Robot.
During tournament play, teams will use off-field computers to execute most of the computation, receiving the position of the ball and gathering field geometry information and referee commands. The matches are played between teams of six (division B) and 11 (division A) robots, and the robots receive navigation commands through RF communication with minimal bandwidth. The diameter and height of the robots are limited to 180 millimeters (division B) and 150 millimeters (division A), hence the name Small Size League.
In addition, this challenge requires the robot to detect objects in the field, estimate their position, compute navigation paths, and keep records of past trajectories.
“SSL matches are highly dynamic environments with extremely resource-constrained robots, requiring solutions to consider size, power consumption, accuracy, and processing speed trade-offs. This work presents an architecture that enables these robots to execute basic soccer tasks autonomously, that is, without receiving any external information,” according to Guilherme and his teammates in Towards an Autonomous RoboCup Small Size League Robot.
Project hardware
The team used the following hardware in their project:
A Logitech C922 camera, to provide monocular vision
Inertial sensors, to implement odometry estimation
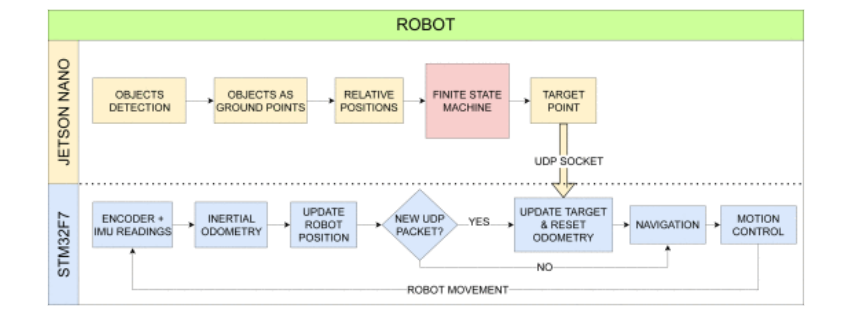
An STM32F767ZI microcontroller unit (MCU), to receive target relative positions and navigation flags from the Nano and execute low-level control and trajectory estimation using inertial odometry
Figure 2. The AI detection pipeline and movement planning of the soccer robot
During the competition’s Vision Blackout Challenge, the winning robot must be able to complete a variety of soccer-based skills, including grabbing a stationary ball, scoring on an empty goal, moving to specific coordinates, and scoring an indirect goal (passing to another robot).
The robot must be able to perform these skills using only embedded sensing and processing. There are no height restrictions for this challenge, so the team added an onboard camera, the Jetson Nano, and a power supply board on top of their typical robot.
Figure 3. The team’s soccer-playing robot modified for the Vision Blackout Challenge (left) and their original robot (right)
In addition, this challenge requires the robot to detect objects in the field, estimate their position, compute navigation paths, and keep records of past trajectories. The SSL soccer matches make use of external cameras and offboard computers for perceiving the environment and sending commands to the robots.
According to the researchers, the SSL Vision architecture “presents limitations such as the camera’s field-of-view, color segmentation, software latency, and communication dropouts, forcing teams to develop solutions for dealing with complex conditions. For example, one common problem during matches is ball occlusion, which occurs when a robot’s projection on the camera image overlaps the ball. Another issue is that the ball and robot position flicks, occasionally not detecting or falsely detecting them.”
In the SSL contests, the robots and balls achieve up to 3.7 m/s and 6.5 m/s velocities, respectively, resulting in a fast-moving game requiring high-throughput solutions. Additionally, the size limitations coupled with using a battery as a power source require solutions to have low-power consumption. Also, precise kicks and passes over long distances are performed during matches, requiring accurate position estimations.
The team also noted the importance of accurate motor control, so the robot can move across the soccer field and keep its measured position accurate. The team needed a way to reduce the rate at which the robot’s internal understanding of its position diverges from its actual physical position. For more details, see Towards an Autonomous RoboCup Small Size League Robot.
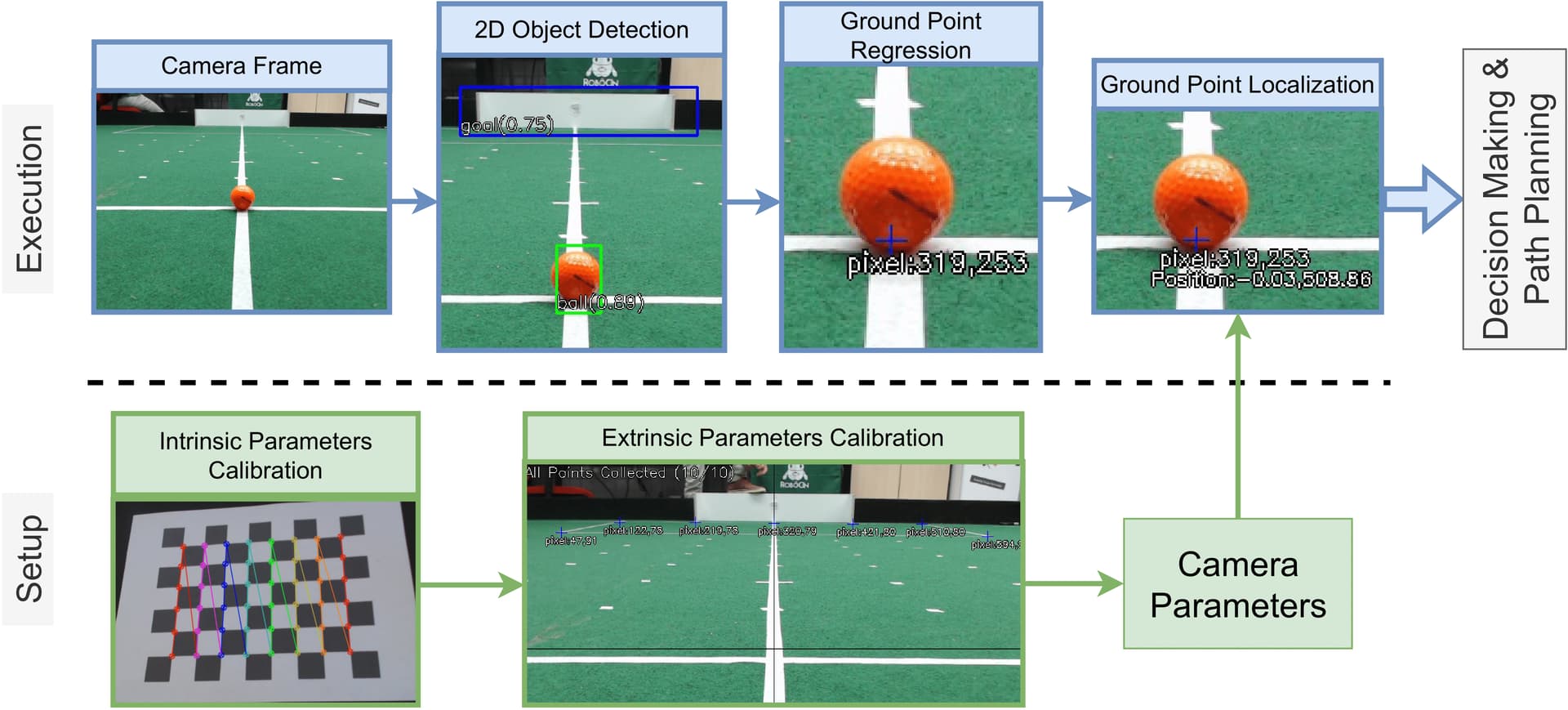
Figure 4. The soccer robot’s camera aids object detection along with field of vision for decision making and path planning
Project software and AI
The team used OpenCV2 and calibration and pose computation techniques to extract the “intrinsic and extrinsic parameters” of the monocular camera (fixed to the robot). They used SSD MobileNet v2 to detect objects’ 2D bounding boxes on camera frames. They also used a program applying linear regression to the bounding box coordinates created by SSD MobileNet that was used to estimate precalibrated camera parameters. This would assign points on the field corresponding to the object’s bottom center (which has an object’s relative position to the camera), and therefore to the robot, too.
Results
The team is pleased with how their robot played in this year’s challenge. Highlights include:
Grabbing a stationary ball: In 12 out of 15 attempts, the robot was able to stop with the ball touching its dribbler, an 80% success rate.
Scoring a goal: A goal was scored in 12 of the 15 runs.
Passing: The robot passed the ball in 7 of the 15 tries, resulting in a 46.7% success rate.
Visit RoboCup 2023 Results to see the full list of results. The team has participated in the RoboCup Small Size League since 2019, winning their first world title in 2022 (Division B). They are currently a three-time Latin American champion. RobôCIn Small Size League Extended Team Description Paper for RoboCup 2023 presents the improvements the team made to their project for the Small Size League (SSL) division B title in RoboCup 2023 in Bordeaux, France in late July, when they took first place.
Figure 5. The robot grabbing a stationary ball(left) and scoring a goal (right)
Future plans
Guilherme shared some insights about challenges their team encountered in competition, and opportunities for improvement for future events. He noted that most of the failures were due to false-positive detections from objects outside the field. “We are working on a solution for detecting the field boundaries and applying a mask to discard those objects,” he said.
The team needs faster object detection solutions. “Even though we are able to execute basic skills so far, 30 FPS is still a low processing speed for the SSL environment. At the main competition, cameras usually operate at 70 FPS,” he said.
The robot’s skills were implemented using only relative positions from detected objects–that is, without the knowledge of the robot’s self-localization on the field. “We believe this information might be useful for optimizing our performance in the soccer tasks, while also allowing us to avoid penalties,” Guilherme noted. For example, the robot should not enter the goalkeeper’s area. “We are working on a self-localization algorithm based on Monte Carlo Localization (MCL) and will share it in the coming months.”
The team plans to add more features to the robot’s system in the future (such as field line detection, localization algorithms, and path planning), and they will be working to optimize each part of the system for those needs.
In addition, the team continues to work on solutions for detecting field boundaries and lines, and estimating the robot’s self-localization. They also plan to replace the Jetson Nano with a Jetson Orin Nano so they can achieve faster processing speeds with their robot. That upgrade should help the team compete more effectively in league play.
To learn more about the team’s original project, visit the Developer Forum and GitHub. Explore Jetson Community Projects for more ideas and inspiration from your fellow robotics developers.
Picture this: You’re browsing through an online store, looking for the perfect pair of running shoes. But with thousands of options available, where do you even…
Picture this: You’re browsing through an online store, looking for the perfect pair of running shoes. But with thousands of options available, where do you even begin? Suddenly, a section catches your eye: “Recommended for You.” Intrigued, you click and, within seconds, a curated list of running shoes tailored to your unique preferences appears. It’s as if the website understands your tastes, needs, and style.
Welcome to the world of recommendation systems, where cutting-edge technology combines data analysis, artificial intelligence (AI), and a touch of magic to transform our digital experiences.
This post dives deep into the fascinating realm of recommendation systems and explores the modeling approach for building a two-stage candidate reranker. I provide pro tips on how to overcome data scarcity in underrepresented languages, along with a technical walkthrough of how to implement these best practices.
Overview of building a two-stage candidate reranker
For each user, a recommender system must predict a few items that this user will be interested in from possibly millions of items. This is a daunting task. A powerful modeling approach is called the two-stage candidate reranker.
Figure 1 shows the two stages. In the first stage, the model identifies hundreds of candidate items that the user may be interested in. In the second stage, the model ranks this list from most likely to least likely. Finally, the model suggests the most likely items to the user.
Figure 1. Flow of a two-stage candidate reranker recommendation system
Stage 1: Candidate generation
There are many ways to generate candidates, including statistical methods and deep learning methods. One statistical technique to generate candidates is building a co-visitation matrix. You iterate through all user historical sessions and maintain a cumulative tally of how often each pair of items coexists within user sessions. As a result, you know the top 100 items that are frequently paired with each item.
Now, given a specific user, you can generate candidate items by iterating through their user history and combining all top 100 lists associated with each item in their history. Many items appear multiple times. The candidates are the most common items in this concatenated list of hundreds of items.
Stage 2: Ranking
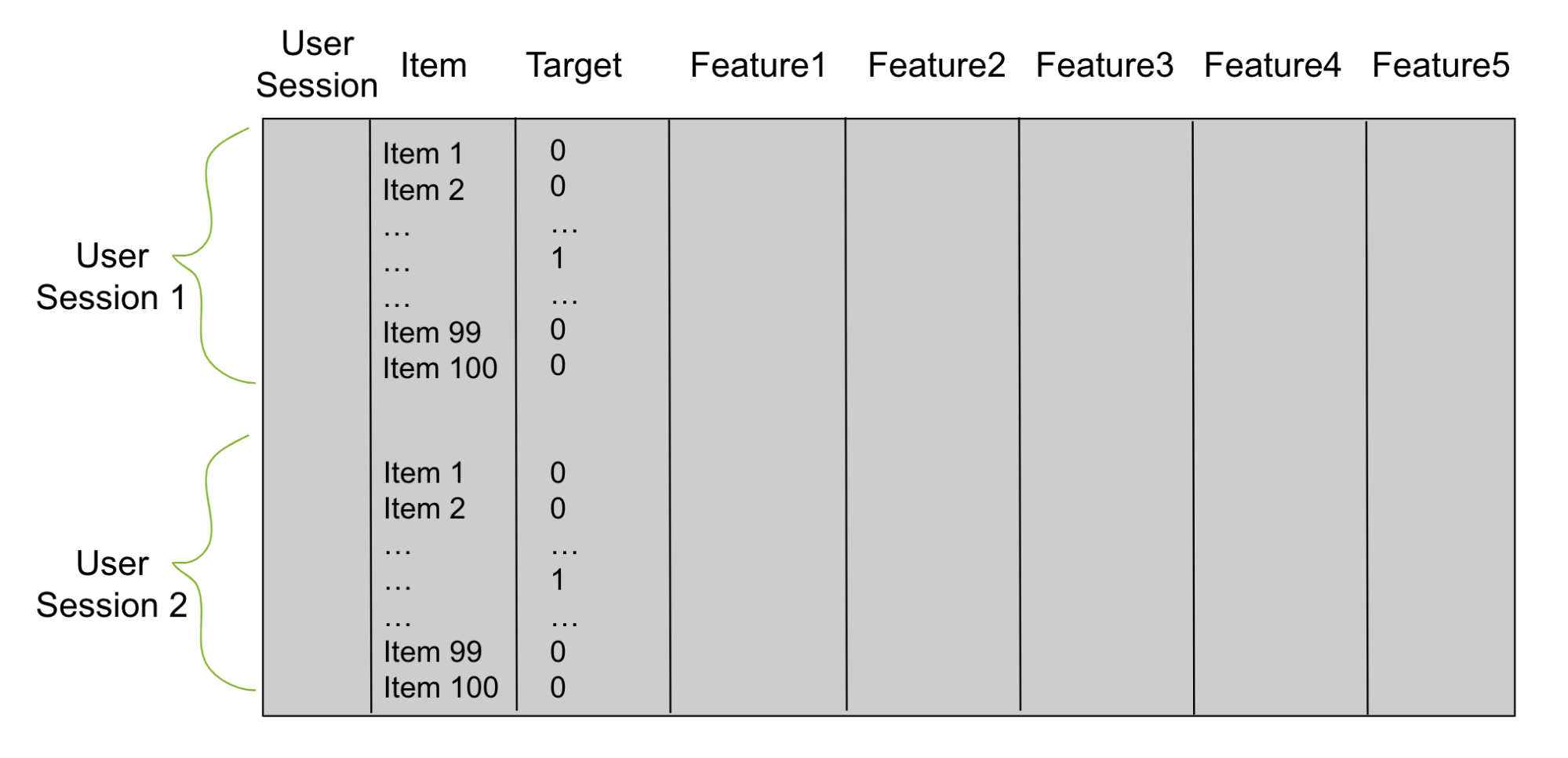
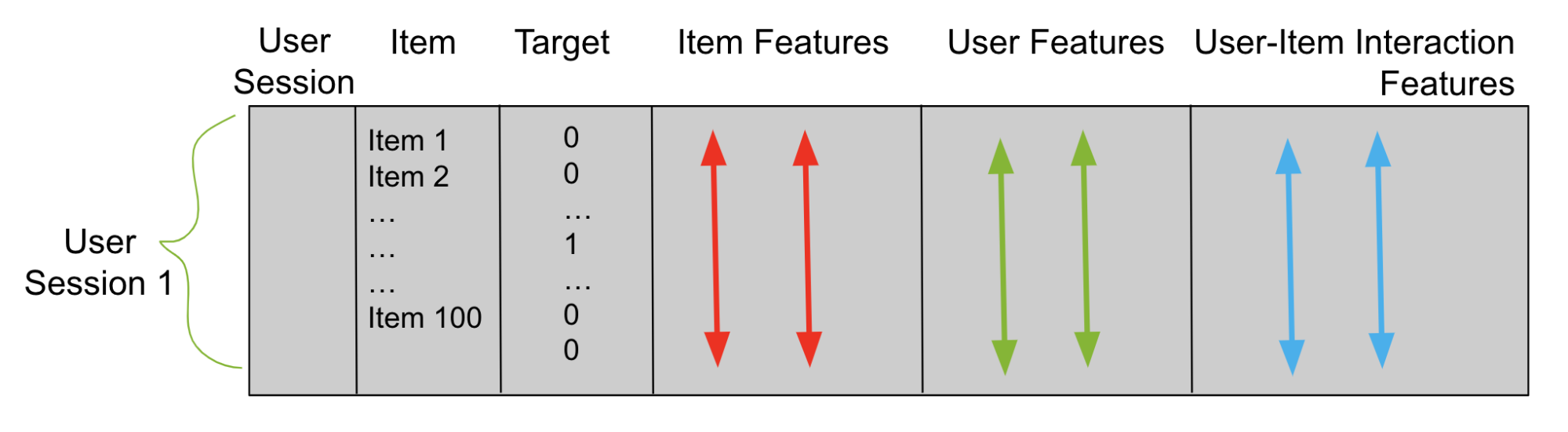
Using candidates from stage 1, build a tabular dataframe (Figure 2), which you use to train a reranker. Imagine that stage 1 produces 100 candidates per user. Then your tabular dataframe has 100 rows for each trained data user. One column is user and another column is candidate item. Add a third column for the target. Each row with a candidate item that is a correct match for that row’s user has a 1 in the target column and 0 otherwise.
Figure 2. Reranker dataframe table
Next, add columns that describe the user sessions and items called feature columns. These feature columns are what the reranker uses to learn patterns and predict the target column. You train your reranker with either a binary classification objective or a pairwise or listwise ranking objective. Afterward, you use this trained model to predict items for unseen test user sessions.
Data scarcity in underrepresented languages
The two-stage candidate reranker approach (and any other approach) requires a large amount of training data to train the machine learning or deep learning model properly. Popular languages typically have lots of existing data, but this is not true for historically underrepresented languages.
Advocating for underserved languages is crucial for several reasons, such as promoting inclusivity, increasing global reach, and improving online user engagement and satisfaction.
To build recommender systems for underrepresented languages, I recommend using transfer learning. By leveraging datasets for common languages, models can recognize existing patterns and apply these learnings to support languages that are not widely spoken. This helps you overcome small dataset challenges and create a more inclusive digital world.
Pro tips for developing multilingual recommendation systems
To overcome data scarcity, use transfer learning to apply information from one language to another for stages 1 and 2. Many items have equivalents in multiple languages. Therefore, user-item interaction behavior in one language can be translated to another language.
Here are the top tips for speeding up the development process for multilingual recommendation engines.
Tips for candidate generation
First, create co-visitation matrices for underrepresented languages by using user histories that exist in both popular languages and underrepresented languages.
Be sure to represent items with pretrained multilingual large language model (LLM) embeddings. Then, use cosine similarity to find candidate items in underrepresented languages.
Initialize NN embeddings with pretrained multilingual LLM embeddings. Then, fine-tune and use cosine similarity between user and item embeddings to find candidate items in the underrepresented languages.
Tips for ranking
You can use item features from popular languages as item features for underrepresented languages in the tabular dataframe for the reranker.
Create user-item interaction features by transferring user-item patterns learned from popular languages to underrepresented languages.
Finally, train an underrepresented language’s reranker using user-item dataframe rows from popular languages.
Tutorial: Multilingual recommender system
To help you test these methods out, I walk you through an optimized process for building a multilingual recommender system.
Candidate generation implementation
The goal of candidate generation is to generate hundreds of item suggestions per user. Two popular techniques are using co-visitation matrices and using representation learning. Using transfer learning with co-visitation matrices is straightforward.
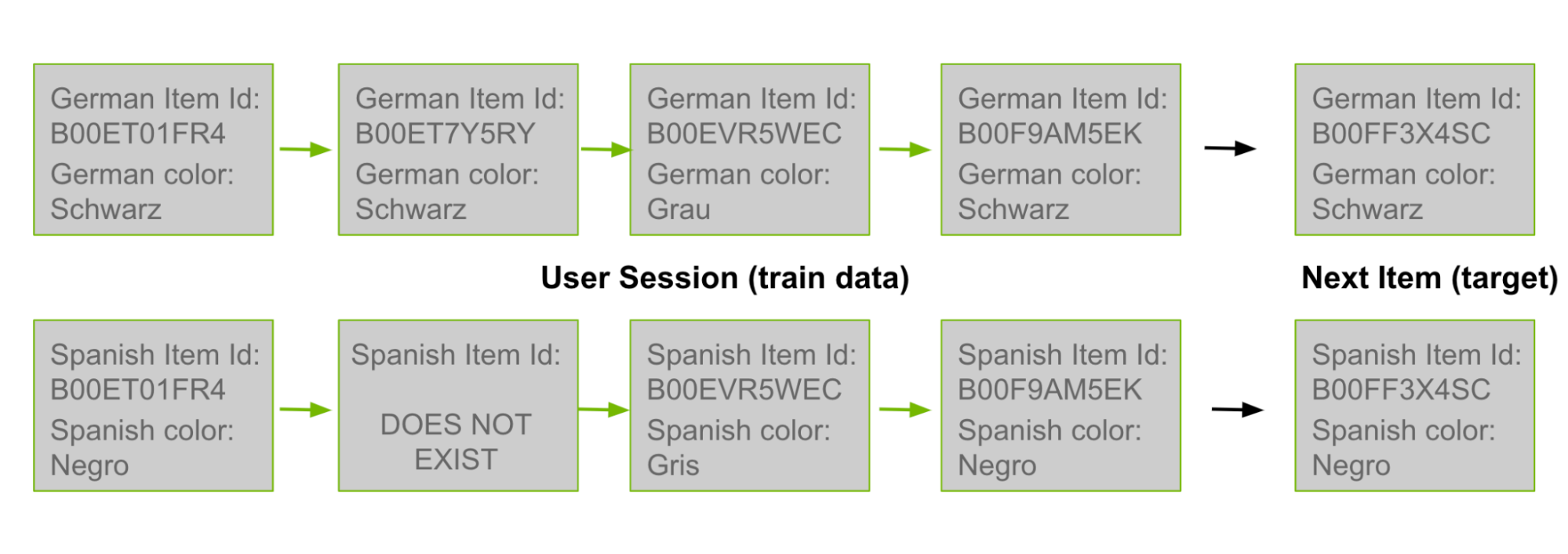
Earlier in this post, I discussed how co-visitation candidate generation is based on counting the coexisting pairs of product IDs within user histories. As many product IDs exist in multiple languages, you can use pairs from a German user’s history as counts in a Spanish co-visitation matrix. In Figure 3, the top German row is from the training data. You then “translate” it to Spanish, shown in the bottom row.
Figure 3. Transfer learning process
The procedure is as follows.
Given a pair of Spanish product IDs, you can iterate through users from the other five languages: English, German, Japanese, Italian, and French.
Whenever you observe the pair of Spanish product IDs in one of these user’s histories, add 1 to the count for this Spanish item pair. Or you can use a different weight, like adding 0.5 to the count.
After you accumulate counts for all Spanish item pairs, continue to generate candidates as before by applying the new co-visitation matrix to each Spanish user’s history to generate candidates for the Spanish user.
The fastest and most efficient way to create co-visitation matrices is to use RAPIDS cuDF. To follow along, see the Candidate ReRank Model using Handcrafted Rules Jupyter notebook with example code.
By merging a dataframe that contains all user histories (that is, a dataframe with columns user and history item) to itself on the key user, you create all historical pairs. Then group by item pairs and aggregate the counts.
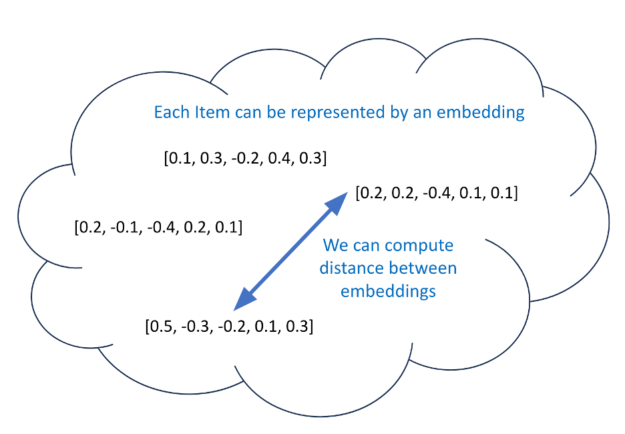
Representation learning, LLMs, and deep learning embeddings are hot and current topics. Besides co-visitation matrices, an alternative to generating candidate items for each user is to create meaningful distance embeddings. If you have meaningful distance embeddings for each item, then you could use a model that predicts an embedding for each user. Next, find the 100 closest (through cosine similarity) embeddings to this predicted embedding and use these as your candidates (Figure 4).
Figure 4. Compute distance between embeddings
The process of training meaningful distance embeddings for items is called representation learning. Embeddings are N dimensional vectors in N dimensional space. During training, embeddings of similar items are modified to be closer together (through some distance metric) while embeddings of dissimilar items are modified to have at least a predefined gap distance (margin) between them.
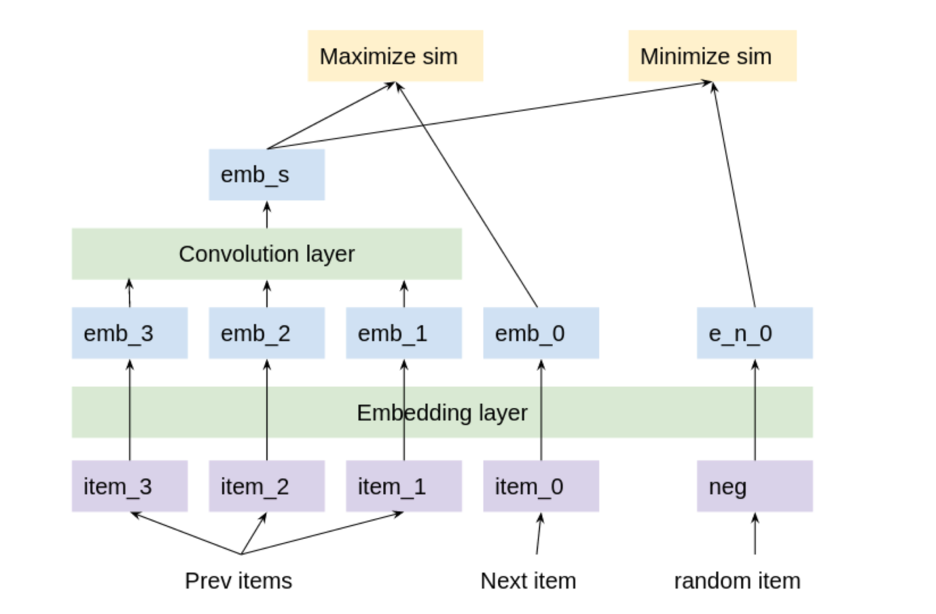
One way to use transfer learning during representation learning is to pre-initialize the embeddings with multilingual sentence embeddings. Each item has a title, whether it’s in English, German, Japan, Spanish, Italian, or French. You can pre-initialize each item with its title embedding from Hugging Face’s model stsb-xlm-r-multilingual, for example. This model has been trained on many different languages and transfers learning from all of them. Afterward, you can fine-tune the embeddings using your training data with the model shown in Figure 5.
Figure 5. Representation learning
Fine-tune your model using all train data user histories. Every three consecutive history items are paired with one positive item target, which is the next consecutive item. Each triplet is paired with 4096 negative item targets, which are randomly chosen items. Backpropagation maximizes cosine similarity between the predicted embedding and positive target. And it minimizes cosine similarity between the predicted embedding and negative target. Afterward, you have meaningful distance embeddings for each item and a predicted embedding for each user.
The goal of stage 2 is to train a reranker that predicts the likelihood of each candidate item being correct among all possible candidate items for each user. To train a model successfully, you need feature columns in addition to a user, item, and target column. There are three types of feature columns:
Item features
User features
User-item interaction features
Figure 6. Reranker dataframe with features
Item features describe items. For example, you can add an item price feature. Then, every row in your reranker dataframe with item A has a corresponding price A in the item price column (Figure 6).
Using transfer learning on item features is easy. To transfer learning from German to Spanish, you can create item features from the German user history data and then merge it to Spanish items.
For example, for each item product ID, count how often it appears in all German user histories. Then every row in your reranker dataframe with Spanish item A has a corresponding German popularity A in the German item popularity column. The reason this works is because many item product IDs exist in both German and Spanish. If a certain Spanish product ID does not exist in German, then you insert NAN in the German item popularity column.
User feature columns and item feature columns are generally created with dataframe groupby commands. Create a property for each user or item and then merge it into your dataframe. The quickest and most efficient method is to use RAPIDS cuDF.
User-item interaction features describe the relationship between a row’s candidate item and that row’s user. These features have a different value for each row. A common way to generate user-item interaction features is to describe the relationship between a user’s last history item and their candidate item.
One way to use transfer learning from popular languages to underrepresented languages is to create meaningful distance embeddings for all items using multilingual information. Then a user-item interaction feature can be the cosine similarity score between a user’s last history item and candidate item based on the embeddings.
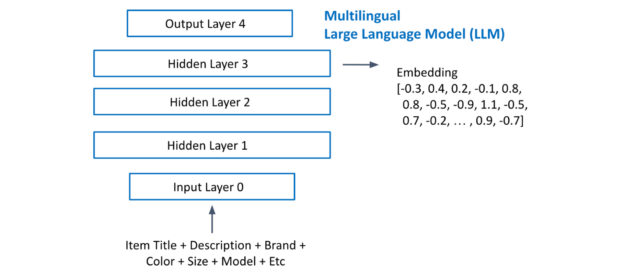
Figure 7 shows extracting item embeddings from a multilingual LLM. You concatenate all the text for each item and input it into your LLM. Extract the last hidden layer activations as your embedding.
Figure 7. Large language model embeddings
A third way to use information from popular languages to improve underrepresented language recommendation is to train your underrepresented GBT reranker using dataframe rows from popular languages. First, you use the same column features for all language dataframes and then you merge all dataframes into one new dataframe. Afterward, your dataframe is large.
The best way to train GBT with millions of rows is to use RAPIDS Dask cuDF XGB, which uses multiple GPUs! For more information, see the KDD cup solution code.
When browsing online, recommendation systems may seem magical but, as you learned throughout this post, the inner workings of a multilingual recommendation engine are deterministic and understandable.
I also introduced the two-stage candidate reranker technique for recommendation systems. This is a powerful technique that helps solve many recommender system needs. Next, I gave you pro tips to help train recommendation systems for underrepresented languages. I shared how RAPIDS and NVIDIA Merlin frameworks can help you build recommender systems.
I hope that you can use some of these ideas in your next recommender system project. By improving online recommender systems for underrepresented languages, we can all make the Internet more inclusive, extend global reach, and improve user engagement and satisfaction.
Large language models (LLMs) are becoming an integral tool for businesses to improve their operations, customer interactions, and decision-making processes….
Enterprises need custom models to tailor the language processing capabilities to their specific use cases and domain knowledge. Custom LLMs enable a business to generate and understand text more efficiently and accurately within a certain industry or organizational context.
Custom models empower enterprises to create personalized solutions that align with their brand voice, optimize workflows, provide more precise insights, and deliver enhanced user experiences, ultimately driving a competitive edge in the market.
This post covers various model customization techniques and when to use them. NVIDIA NeMo supports many of the methods.
NVIDIA NeMo is an end-to-end, cloud-native framework to build, customize, and deploy generative AI models anywhere. It includes training and inferencing frameworks, guardrail toolkits, data curation tools, and pretrained models, offering an easy, cost-effective, and fast way to adopt generative AI.
Selecting an LLM customization technique
You can categorize techniques by the trade-offs between dataset size requirements and the level of training effort during customization compared to the downstream task accuracy requirements.
Figure 1. LLM customization techniques available with NVIDIA NeMo
Figure 1 shows the following popular customization techniques:
Prompt engineering: Manipulates the prompt sent to the LLM but doesn’t alter the parameters of the LLM in any way. It is light in terms of data and compute requirements.
Prompt learning: Uses prompt and completion pairs imparting task-specific knowledge to LLMs through virtual tokens. This process requires more data and compute but provides better accuracy than prompt engineering.
Parameter-efficient fine-tuning (PEFT): Introduces a small number of parameters or layers to existing LLM architecture and is trained with use-case–specific data, providing higher accuracy than prompt engineering and prompt learning, while requiring more training data and compute.
Fine-tuning: Involves updating the pretrained LLM weights unlike the three types of customization techniques outlined earlier that keep these weights frozen. This means fine-tuning also requires the most amount of training data and compute as compared to these other techniques. However, it provides the most accuracy for specific use cases, justifying the cost and complexity.
Prompt engineering involves customization at inference time with show-and-tell examples. An LLM is provided with example prompts and completions, detailed instructions that are prepended to a new prompt to generate the desired completion. The parameters of the model are not changed.
Few-shot prompting: This approach requires prepending a few sample prompts and completion pairs to the prompt, so that the LLM learns how to generate responses for a new unseen prompt. While few-shot prompting requires a relatively smaller amount of data as compared to other customization techniques and does not require fine-tuning, it does add to inference latency.
Chain-of-thought reasoning: Just as humans decompose bigger problems into smaller ones and apply chain of thought to solve problems effectively, chain-of-thought reasoning is a prompt engineering technique that helps LLMs improve their performance on multi-step tasks. It involves breaking a problem down into simpler steps with each of the steps requiring slow and deliberate reasoning. This approach works well for logical, arithmetic, and deductive reasoning tasks.
System prompting: This approach involves adding a system-level prompt in addition to the user prompt to provide specific and detailed instructions to the LLMs to behave as intended. The system prompt can be thought of as input to the LLM to generate its response. The quality and specificity of the system prompt can have a significant impact on the relevance and accuracy of the LLM’s response.
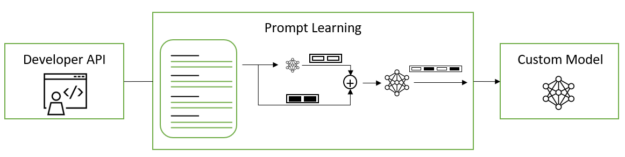
Prompt learning
Prompt learning is an efficient customization method that makes it possible to use pretrained LLMs on many downstream tasks without needing to tune the pretrained model’s full set of parameters. It includes two variations with subtle differences called p-tuning and prompt tuning; both methods are collectively referred to as prompt learning.
Prompt learning enables adding new tasks to LLMs without overwriting or disrupting previous tasks for which the model has already been pretrained. Because the original model parameters are frozen and never altered, prompt learning also avoids catastrophic forgetting issues often encountered when fine-tuning models. Catastrophic forgetting occurs when LLMs learn new behavior during the fine-tuning process at the cost of foundational knowledge gained during LLM pretraining.
Figure 2. Prompt learning applied to LLMs
Instead of selecting discrete text prompts in a manual or automated fashion, prompt tuning and p-tuning use virtual prompt embeddings that you can optimize by gradient descent. These virtual token embeddings exist in contrast to the discrete, hard, or real tokens that do make up the model’s vocabulary. Virtual tokens are purely 1D vectors with dimensionality equal to that of each real token embedding. In training and inference, continuous token embeddings are inserted among discrete token embeddings according to a template provided in the model’s config.
Prompt tuning: For a pretrained LLM, soft prompt embeddings are initialized as a 2D matrix of size total_virtual_tokensXhidden_size. Each task that the model is prompt-tuned to perform has its own associated 2D embedding matrix. Tasks do not share any parameters during training or inference. The NeMo framework prompt tuning implementation is based on The Power of Scale for Parameter-Efficient Prompt Tuning.
P-tuning: An LSTM or MLP model called prompt_encoder is used to predict virtual token embeddings. prompt_encoder parameters are randomly initialized at the start of p-tuning. All base LLM parameters are frozen, and only the prompt_encoder weights are updated at each training step. When p-tuning completes, prompt-tuned virtual tokens from prompt_encoder are automatically moved to prompt_table where all prompt-tuned and p-tuned soft prompts are stored. prompt_encoder is then removed from the model. This enables you to preserve previously p-tuned soft prompts while still maintaining the ability to add new p-tuned or prompt-tuned soft prompts in the future.
prompt_table uses the task name as a key to look up the correct virtual tokens for a specified task. The NeMo framework p-tuning implementation is based on GPT Understands, Too.
Parameter-efficient fine-tuning
Parameter-efficient fine-tuning (PEFT) techniques use clever optimizations to selectively add and update few parameters or layers to the original LLM architecture. Using PEFT, model parameters are trained for specific use cases. Pretrained LLM weights are kept frozen and significantly fewer parameters are updated during PEFT using domain and task-specific datasets. This enables LLMs to reach high accuracy on trained tasks.
There are several popular parameter-efficient alternatives to fine-tuning pretrained language models. Unlike prompt learning, these methods do not insert virtual prompts into the input. Instead, they introduce trainable layers into the transformer architecture for task-specific learning. This helps attain strong performance on downstream tasks while reducing the number of trainable parameters by several orders of magnitude (closer to 10,000x fewer parameters) compared to fine-tuning.
Adapter Learning
Infused Adapter by Inhibiting and Amplifying Inner Activations (IA3)
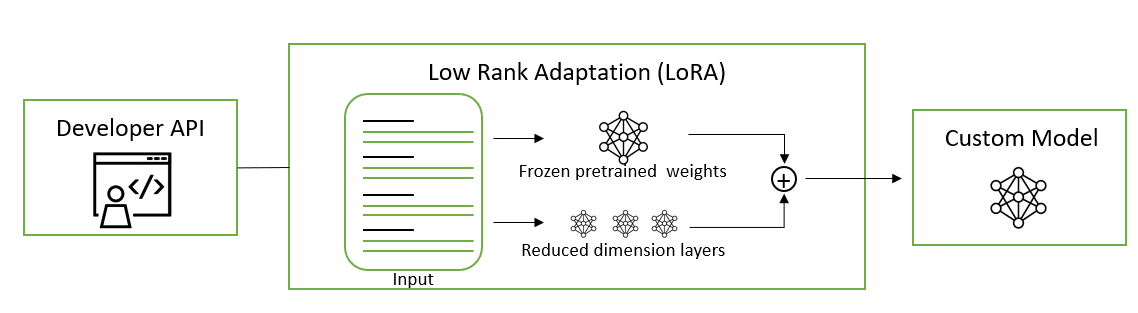
Low-Rank Adaptation (LoRA)
Adapter Learning: Introduces small feed-forward layers in between the layers of the core transformer architecture. Only these layers (adapters) are trained at fine-tuning time for specific downstream tasks. The adapter layer generally uses a down-projection to project the input to a lower-dimensional space followed by a nonlinear activation function, and an up-projection with . A residual connection adds the output of this to the input, leading to a final form:
Adapter modules are usually initialized such that the initial output of the adapter is always zeros to prevent degradation of the original model’s performance due to the addition of such modules. The NeMo framework adapter implementation is based on Parameter-Efficient Transfer Learning for NLP.
IA3: Adds even fewer parameters, compared to adapters, which simply scale the hidden representations in the transformer layer using learned vectors. These scaling parameters can be trained for specific downstream tasks. The learned vectors lk, lv, and lff, respectively rescale the keys and values in attention mechanisms and the inner activations in position-wise feed-forward networks. This technique also makes mixed-task batches possible because each sequence of activations in the batch can be separately and cheaply multiplied by its associated learned task vector. The NeMo framework IA3 implementation is based on Few-Shot Parameter-Efficient Fine-Tuning is Better and Cheaper than In-Context Learning.
Figure 3. LoRA for parameter-efficient fine-tuning
LoRA: Injects trainable low-rank matrices into transformer layers to approximate weight updates. Instead of updating the full pretrained weight matrix W, LoRA updates its low-rank decomposition, reducing the number of trainable parameters 10,000 times and the GPU memory requirements by 3x compared to fine-tuning. This update is applied to the query and value projection weight matrices in the multi-head attention sub-layer. Applying updates to low-rank decomposition instead of the entire matrix has been shown to be on par or better in model quality than fine-tuning, enabling higher training throughput and with no additional inference latency.
When data and compute resources have no hard constraints, customization techniques such as supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF) are great alternative approaches to PEFT and prompt engineering. Fine-tuning can help achieve the best accuracy on a range of use cases as compared to other customization approaches.
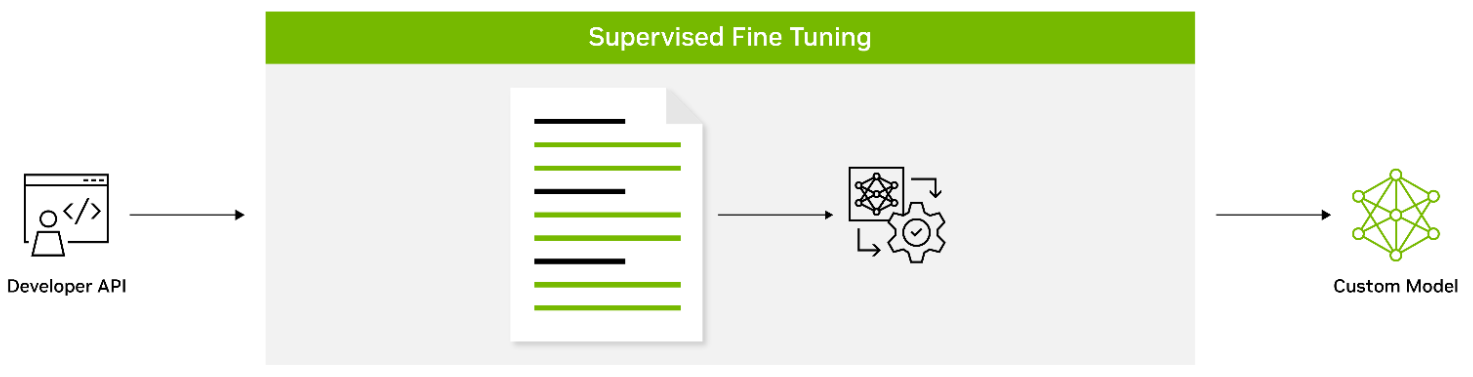
Supervised fine-tuning: SFT is the process of fine-tuning all the model’s parameters on labeled data of inputs and outputs that teaches the model domain-specific terms and how to follow user-specified instructions. It is typically done after model pretraining. Using pretrained models enables many benefits that include the use of state-of-the-art models without having to train from scratch, reduced computation costs, and reduced data collection needs as compared to the pretraining stage. A form of SFT is referred to as instruction tuning because it involves fine-tuning language models on a collection of datasets described through instructions.
Figure 4. Supervised fine-tuning with labeled instructions following data
SFT with instructions leverages the intuition that NLP tasks can be described through natural language instructions, such as “Summarize the following article into three sentences.” or “Write an email in Spanish about an upcoming school festival.” This method successfully combines the strengths of fine-tuning and prompting paradigms to improve LLM zero-shot performance at inference time.
The instruction tuning process involves performing fine-tuning on the pretrained model on a mixture of several NLP datasets expressed through natural language instructions that are blended in varying proportions. At inference time, the fine-tuned model is evaluated on unseen tasks and this process is known to substantially improve zero-shot performance on unseen tasks. SFT is also an important intermediary step in the process of improving LLM capabilities using reinforcement learning, which we describe next.
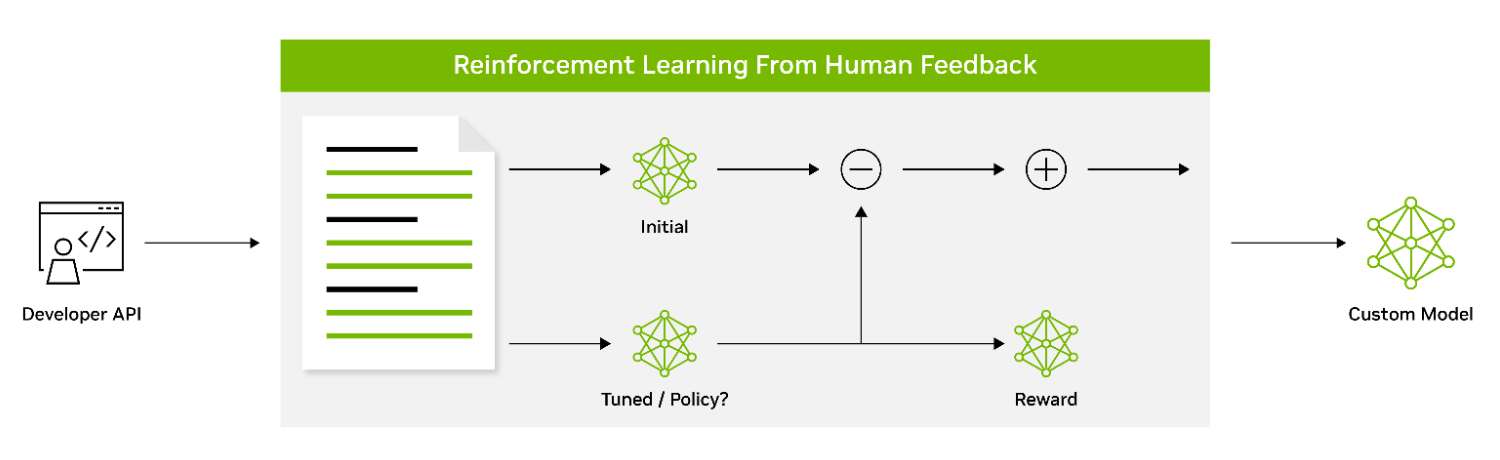
Reinforcement learning with human feedback: Reinforcement learning with human feedback (RLHF) is a customization technique that enables LLMs to achieve better alignment with human values and preferences. It uses reinforcement learning to enable the model to adapt its behavior based on the feedback it receives. It involves a three-stage fine-tuning process that uses human preference as the loss function. The SFT model fine-tuned with instructions as described in the earlier section is considered the first stage in the RLHF technique.
Figure 5. Aligning LLM behavior with human preferences using reinforcement learning
The SFT model is trained as a reward model (RM) in stage 2 of RLHF. A dataset consisting of prompts with multiple responses ranked by humans is used to train the RM to predict human preference.
After the RM is trained, stage 3 of RLHF focuses on fine-tuning the initial policy model against the RM using reinforcement learning with a proximal policy optimization (PPO) algorithm. These three stages of RLHF performed iteratively enable LLMs to generate outputs that are more aligned with human preferences and can follow instructions more effectively.
While RLHF results in powerful LLMs, the downside is that this method can be misused and exploited to generate undesirable or harmful content. The NeMo method uses the PPO value network as a critic model to guide the LLMs away from generating harmful content. There are other approaches being actively explored in the research community to steer the LLMs towards appropriate behavior and reduce toxic generation or hallucinations where LLMs make up facts.
Customize your LLMs
This post covered various model customization techniques and when to use them. Many of those methods are supported by NVIDIA NeMo.
NeMo provides an accelerated workflow for training with 3D parallelism techniques. It offers a choice of several customization techniques and is optimized for at-scale inference of large-scale models for language and image applications, with multi-GPU and multi-node configurations.
Download the NeMo framework today and customize pretrained LLMs on your preferred on-premises and cloud platforms.

 NVIDIA Triton Inference Server streamlines and standardizes AI inference by enabling teams to deploy, run, and scale trained ML or DL models from any framework…
NVIDIA Triton Inference Server streamlines and standardizes AI inference by enabling teams to deploy, run, and scale trained ML or DL models from any framework…
 Explore the latest streaming analytics features and advancements with this new release.
Explore the latest streaming analytics features and advancements with this new release. Next-generation AI pipelines have shown incredible success in generating high-fidelity 3D models, ranging from reconstructions that produce a scene matching…
Next-generation AI pipelines have shown incredible success in generating high-fidelity 3D models, ranging from reconstructions that produce a scene matching…


 Soccer is considered one of the most popular sports around the world. And with good reason: the action is often intense, and the game combines both physicality…
Soccer is considered one of the most popular sports around the world. And with good reason: the action is often intense, and the game combines both physicality…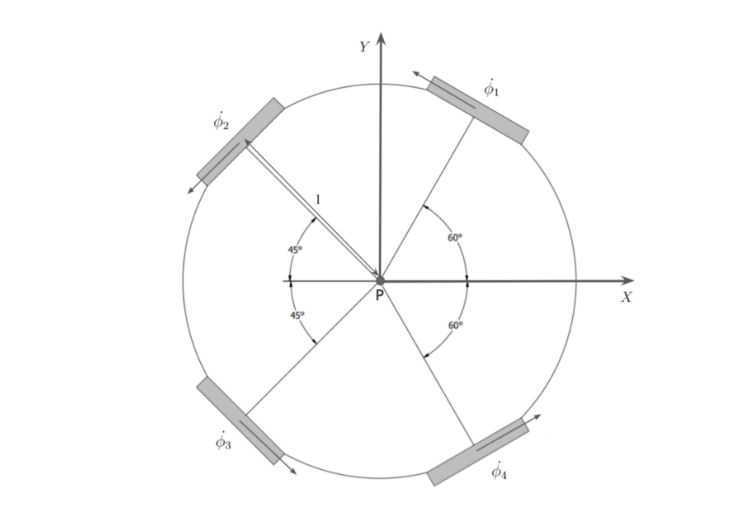



 Picture this: You’re browsing through an online store, looking for the perfect pair of running shoes. But with thousands of options available, where do you even…
Picture this: You’re browsing through an online store, looking for the perfect pair of running shoes. But with thousands of options available, where do you even…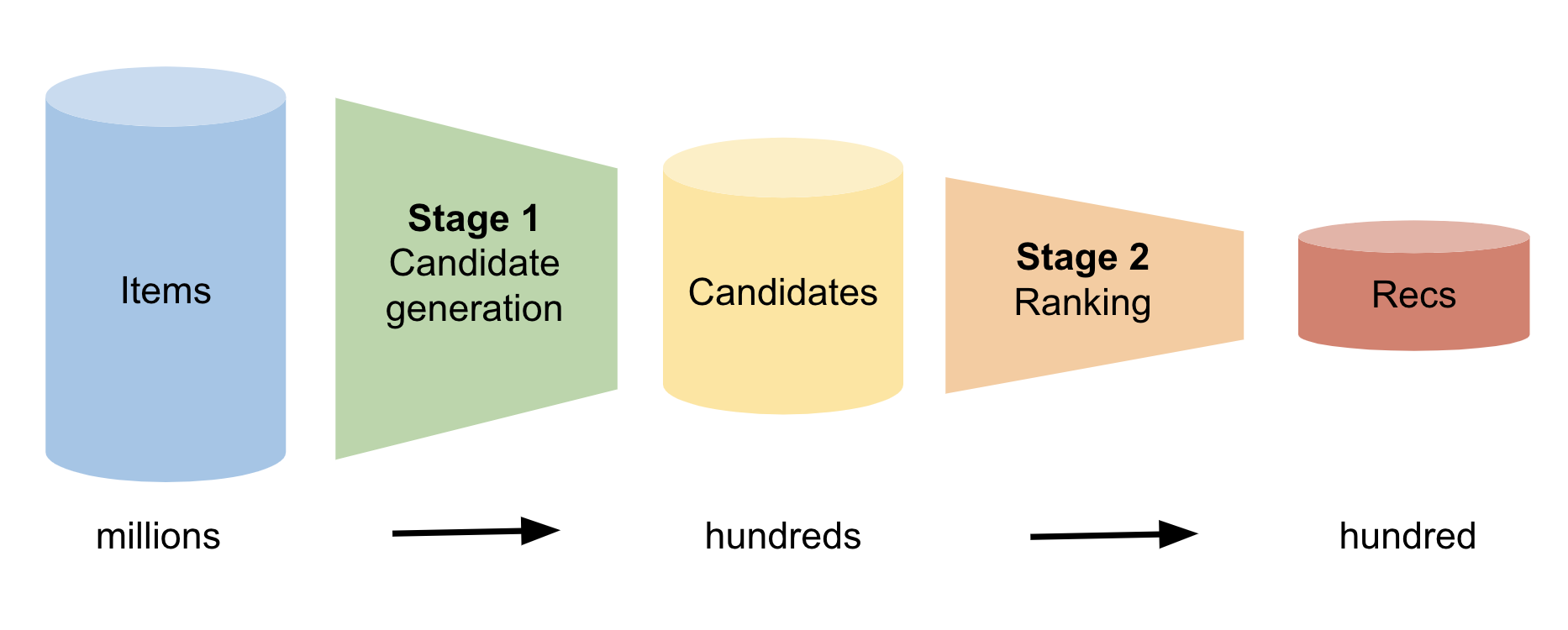
 Large language models (LLMs) are becoming an integral tool for businesses to improve their operations, customer interactions, and decision-making processes….
Large language models (LLMs) are becoming an integral tool for businesses to improve their operations, customer interactions, and decision-making processes….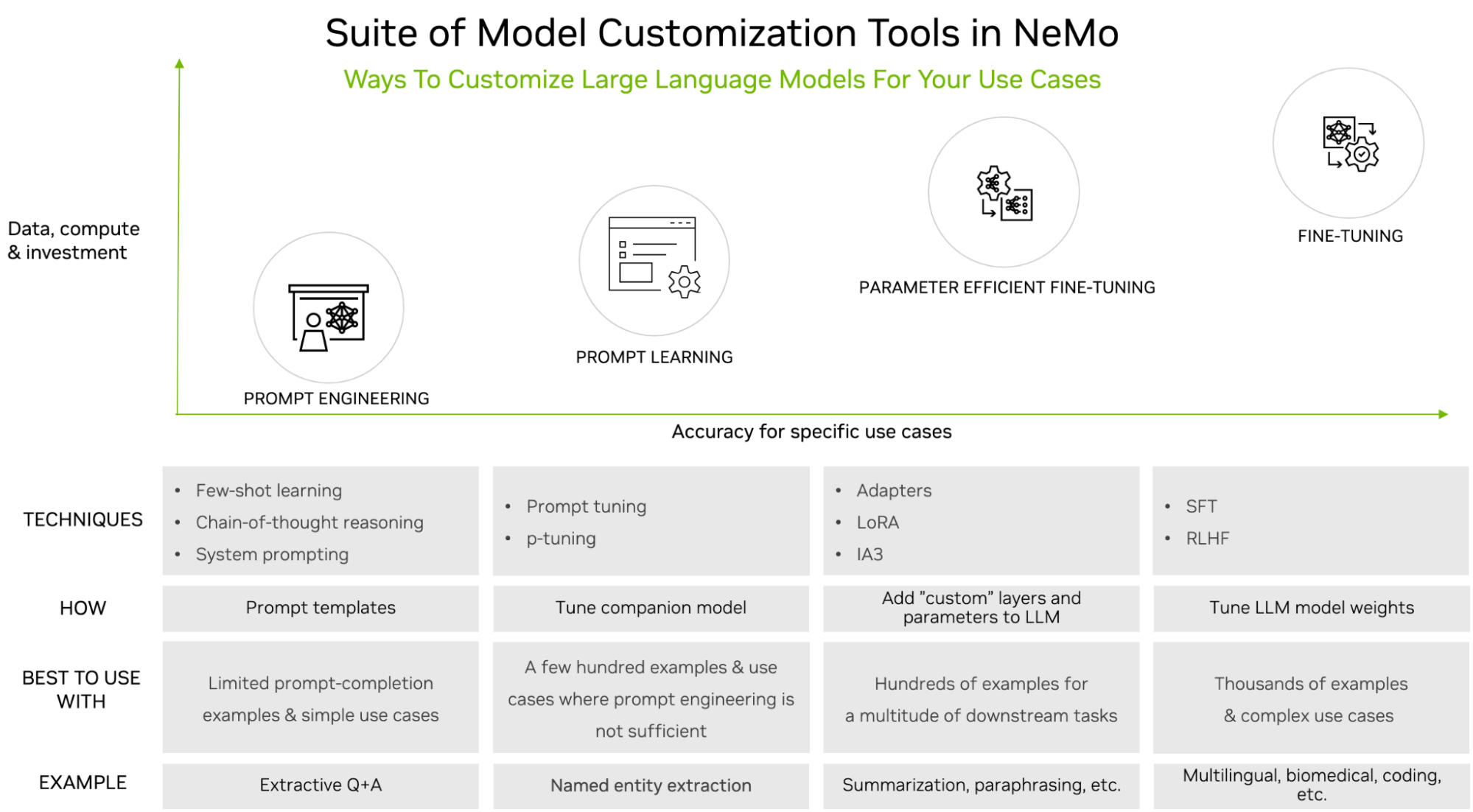
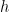 to a lower-dimensional space followed by a nonlinear activation function, and an up-projection with
to a lower-dimensional space followed by a nonlinear activation function, and an up-projection with  . A residual connection adds the output of this to the input, leading to a final form:
. A residual connection adds the output of this to the input, leading to a final form: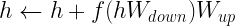
 NVIDIA Modulus is now part of the NVIDIA AI Enterprise suite, supporting PyTorch 2.0, CUDA 12, and new samples.
NVIDIA Modulus is now part of the NVIDIA AI Enterprise suite, supporting PyTorch 2.0, CUDA 12, and new samples.