
 This article presents an effective systematic method to approach reading research papers to be used as a resource for Machine Learning practitioners.
This article presents an effective systematic method to approach reading research papers to be used as a resource for Machine Learning practitioners.
Is it necessary for data scientists or machine-learning experts to read research papers?
The short answer is yes. And don’t worry if you lack a formal academic background or have only obtained an undergraduate degree in the field of machine learning.
Reading academic research papers may be intimidating for individuals without an extensive educational background. However, a lack of academic reading experience should not prevent Data scientists from taking advantage of a valuable source of information and knowledge for machine learning and AI development.
This article provides a hands-on tutorial for data scientists of any skill level to read research papers published in academic journals such as NeurIPS, JMLR, ICML, and so on.
Before diving wholeheartedly into how to read research papers, the first phases of learning how to read research papers cover selecting relevant topics and research papers.
Step 1: Identify a topic
The domain of machine learning and data science is home to a plethora of subject areas that may be studied. But this does not necessarily imply that tackling each topic within machine learning is the best option.
Although generalization for entry-level practitioners is advised, I’m guessing that when it comes to long-term machine learning, career prospects, practitioners, and industry interest often shifts to specialization.
Identifying a niche topic to work on may be difficult, but good. Still, a rule of thumb is to select an ML field in which you are either interested in obtaining a professional position or already have experience.
Deep Learning is one of my interests, and I’m a Computer Vision Engineer that uses deep learning models in apps to solve computer vision problems professionally. As a result, I’m interested in topics like pose estimation, action classification, and gesture identification.
Based on roles, the following are examples of ML/DS occupations and related themes to consider.
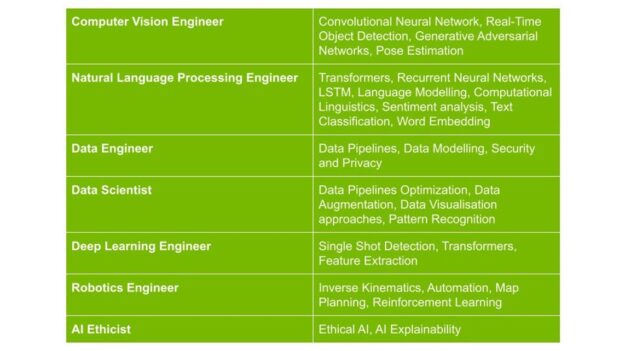
For this article, I’ll select the topic Pose Estimation to explore and choose associated research papers to study.
Step 2: Finding research papers
One of the most excellent tools to use while looking at machine learning-related research papers, datasets, code, and other related materials is PapersWithCode.
We use the search engine on the PapersWithCode website to get relevant research papers and content for our chosen topic, “Pose Estimation.” The following image shows you how it’s done.
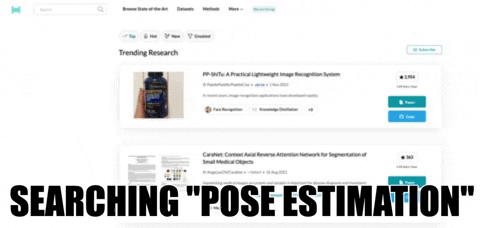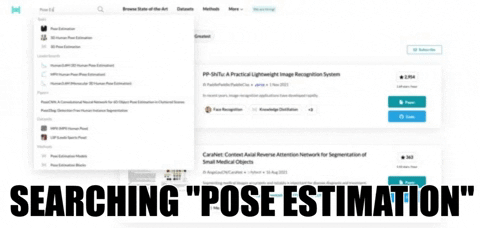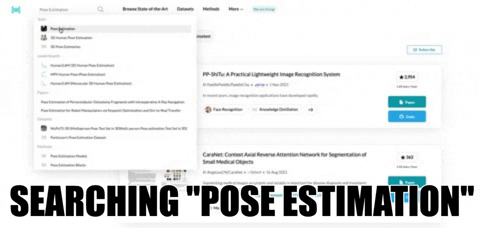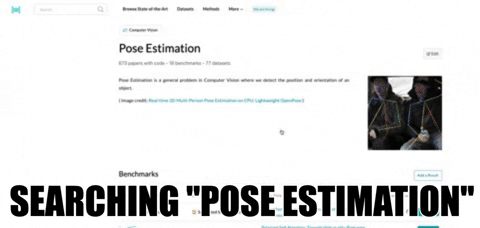
The search results page contains a short explanation of the searched topic, followed by a table of associated datasets, models, papers, and code. Without going into too much detail, the area of interest for this use case is the “Greatest papers with code”. This section contains the relevant papers related to the task or topic. For the purpose of this article, I’ll select the DensePose: Dense Human Pose Estimation In The Wild.
Step 3: First pass (gaining context and understanding)

At this point, we’ve selected a research paper to study and are prepared to extract any valuable learnings and findings from its content.
It’s only natural that your first impulse is to start writing notes and reading the document from beginning to end, perhaps taking some rest in between. However, having a context for the content of a study paper is a more practical way to read it. The title, abstract, and conclusion are three key parts of any research paper to gain an understanding.
The goal of the first pass of your chosen paper is to achieve the following:
- Assure that the paper is relevant.
- Obtain a sense of the paper’s context by learning about its contents, methods, and findings.
- Recognize the author’s goals, methodology, and accomplishments.
Title
The title is the first point of information sharing between the authors and the reader. Therefore, research papers titles are direct and composed in a manner that leaves no ambiguity.
The research paper title is the most telling aspect since it indicates the study’s relevance to your work. The importance of the title is to give a brief perception of the paper’s content.
In this situation, the title is “DensePose: Dense Human Pose Estimation in the Wild.” This gives a broad overview of the work and implies that it will look at how to provide pose estimations in environments with high levels of activity and realistic situations properly.
Abstract
The abstract portion gives a summarized version of the paper. It’s a short section that contains 300-500 words and tells you what the paper is about in a nutshell. The abstract is a brief text that provides an overview of the article’s content, researchers’ objectives, methods, and techniques.
When reading an abstract of a machine-learning research paper, you’ll typically come across mentions of datasets, methods, algorithms, and other terms. Keywords relevant to the article’s content provide context. It may be helpful to take notes and keep track of all keywords at this point.
For the paper: “DensePose: Dense Human Pose Estimation In The Wild“, I identified in the abstract the following keywords: pose estimation, COCO dataset, CNN, region-based models, real-time.
Conclusion
It’s not uncommon to experience fatigue when reading the paper from top to bottom at your first initial pass, especially for Data Scientists and practitioners with no prior advanced academic experience. Although extracting information from the later sections of a paper might seem tedious after a long study session, the conclusion sections are often short. Hence reading the conclusion section in the first pass is recommended.
The conclusion section is a brief compendium of the work’s author or authors and/or contributions and accomplishments and promises for future developments and limitations.
Before reading the main content of a research paper, read the conclusion section to see if the researcher’s contributions, problem domain, and outcomes match your needs.
Following this particular brief first pass step enables a sufficient understanding and overview of the research paper’s scope and objectives, as well as a context for its content. You’ll be able to get more detailed information out of its content by going through it again with laser attention.
Step 4: Second pass (content familiarization)
Content familiarization is a process that’s relevant to the initial steps. The systematic approach to reading the research paper presented in this article. The familiarity process is a step that involves the introduction section and figures within the research paper.
As previously mentioned, the urge to plunge straight into the core of the research paper is not required because knowledge acclimatization provides an easier and more comprehensive examination of the study in later passes.
Introduction
Introductory sections of research papers are written to provide an overview of the objective of the research efforts. This objective mentions and explains problem domains, research scope, prior research efforts, and methodologies.
It’s normal to find parallels to past research work in this area, using similar or distinct methods. Other papers’ citations provide the scope and breadth of the problem domain, which broadens the exploratory zone for the reader. Perhaps incorporating the procedure outlined in Step 3 is sufficient at this point.
Another aspect of the benefit provided by the introduction section is the presentation of requisite knowledge required to approach and understand the content of the research paper.
Graph, diagrams, figures
Illustrative materials within the research paper ensure that readers can comprehend factors that support problem definition or explanations of methods presented. Commonly, tables are used within research papers to provide information on the quantitative performances of novel techniques in comparison to similar approaches.
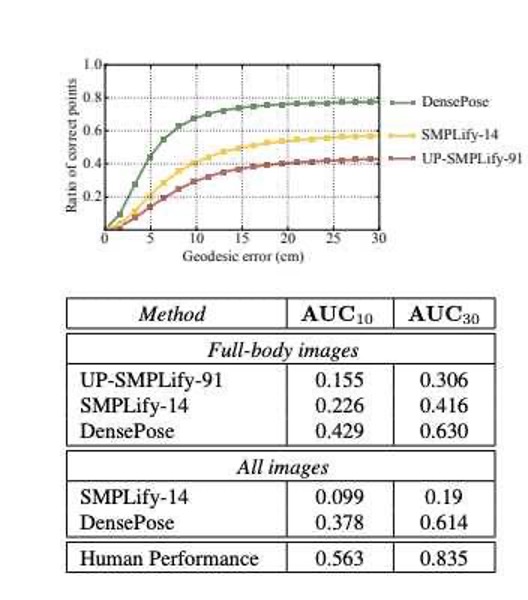
Generally, the visual representation of data and performance enables the development of an intuitive understanding of the paper’s context. In the Dense Pose paper mentioned earlier, illustrations are used to depict the performance of the author’s approach to pose estimation and create. An overall understanding of the steps involved in generating and annotating data samples.
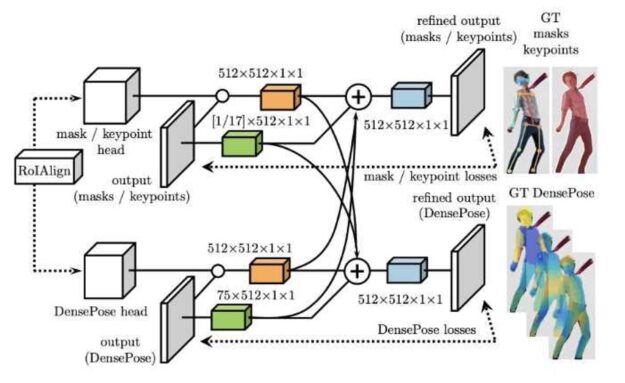
In the realm of deep learning, it’s common to find topological illustrations depicting the structure of artificial neural networks. Again this adds to the creation of intuitive understanding for any reader. Through illustrations and figures, readers may interpret the information themselves and gain a fuller perspective of it without having any preconceived notions about what outcomes should be.
Step 5: Third pass (deep reading)
The third pass of the paper is similar to the second, though it covers a greater portion of the text. The most important thing about this pass is that you avoid any complex arithmetic or technique formulations that may be difficult for you. During this pass, you can also skip over any words and definitions that you don’t understand or aren’t familiar with. These unfamiliar terms, algorithms, or techniques should be noted to return to later.

During this pass, your primary objective is to gain a broad understanding of what’s covered in the paper. Approach the paper, starting again from the abstract to the conclusion, but be sure to take intermediary breaks in between sections. Moreover, it’s recommended to have a notepad, where all key insights and takeaways are noted, alongside the unfamiliar terms and concepts.
The Pomodoro Technique is an effective method of managing time allocated to deep reading or study. Explained simply, the Pomodoro Technique involves the segmentation of the day into blocks of work, followed by short breaks.
What works for me is the 50/15 split, that is, 50 minutes studying and 15 minutes allocated to breaks. I tend to execute this split twice consecutively before taking a more extended break of 30 minutes. If you are unfamiliar with this time management technique, adopt a relatively easy division such as 25/5 and adjust the time split according to your focus and time capacity.
Step 6: Forth pass (final pass)
The final pass is typically one that involves an exertion of your mental and learning abilities, as it involves going through the unfamiliar terms, terminologies, concepts, and algorithms noted in the previous pass. This pass focuses on using external material to understand the recorded unfamiliar aspects of the paper.
In-depth studies of unfamiliar subjects have no specified time length, and at times efforts span into the days and weeks. The critical factor to a successful final pass is locating the appropriate sources for further exploration.
Unfortunately, there isn’t one source on the Internet that provides the wealth of information you require. Still, there are multiple sources that, when used in unison and appropriately, fill knowledge gaps. Below are a few of these resources.
- The Machine Learning Subreddit
- The Deep Learning Subreddit
- PapersWithCode
- Top conferences such as NIPS, ICML, ICLR
- Research Gate
- Machine Learning Apple
The Reference sections of research papers mention techniques and algorithms. Consequently, the current paper either draws inspiration from or builds upon, which is why the reference section is a useful source to use in your deep reading sessions.
Step 7: Summary (optional)
In almost a decade of academic and professional undertakings of technology-associated subjects and roles, the most effective method of ensuring any new information learned is retained in my long-term memory through the recapitulation of explored topics. By rewriting new information in my own words, either written or typed, I’m able to reinforce the presented ideas in an understandable and memorable manner.

To take it one step further, it’s possible to publicize learning efforts and notes through the utilization of blogging platforms and social media. An attempt to explain the freshly explored concept to a broad audience, assuming a reader isn’t accustomed to the topic or subject, requires understanding topics in intrinsic details.
Conclusion
Undoubtedly, reading research papers for novice Data Scientists and ML practitioners can be daunting and challenging; even seasoned practitioners find it difficult to digest the content of research papers in a single pass successfully.
The nature of the Data Science profession is very practical and involved. Meaning, there’s a requirement for its practitioners to employ an academic mindset, more so as the Data Science domain is closely associated with AI, which is still a developing field.
To summarize, here are all of the steps you should follow to read a research paper:
- Identify A Topic.
- Finding associated Research Papers
- Read title, abstract, and conclusion to gain a vague understanding of the research effort aims and achievements.
- Familiarize yourself with the content by diving deeper into the introduction; including the exploration of figures and graphs presented in the paper.
- Use a deep reading session to digest the main content of the paper as you go through the paper from top to bottom.
- Explore unfamiliar terms, terminologies, concepts, and methods using external resources.
- Summarize in your own words essential takeaways, definitions, and algorithms.
Thanks for reading!