
 NVIDIA delivered leading results for MLPerf Inference 2.0, including 5x more performance for NVIDIA Jetson AGX Orin, an SoC platform built for edge devices and robotics.
NVIDIA delivered leading results for MLPerf Inference 2.0, including 5x more performance for NVIDIA Jetson AGX Orin, an SoC platform built for edge devices and robotics.
Models like Megatron 530B are expanding the range of problems AI can address. However, as models continue to grow complexity, they pose a twofold challenge for AI compute platforms:
- These models must be trained in a reasonable amount of time.
- They must be able to do inference work in real time.
What’s needed is a versatile AI platform that can deliver the needed performance on a wide variety of models for both training and inference.
To evaluate that performance, MLPerf is the only industry-standard AI benchmark that tests data center and edge platforms across a half-dozen applications, measuring throughput, latency, and energy efficiency.
In MLPerf Inference 2.0, NVIDIA delivered leading results across all workloads and scenarios with both data center GPUs and the newest entrant, the NVIDIA Jetson AGX Orin SoC platform built for edge devices and robotics.
Beyond the hardware, it takes great software and optimization work to get the most out of these platforms. The results of MLPerf Inference 2.0 demonstrate how to get the kind of performance needed to tackle today’s increasingly large and complex AI models.
Here’s a look at the performance seen on MLPerf Inference 2.0, as well as some of those optimizations and how they got built.
Do the numbers
Figure 1 shows the latest entrant, NVIDIA Jetson AGX Orin.
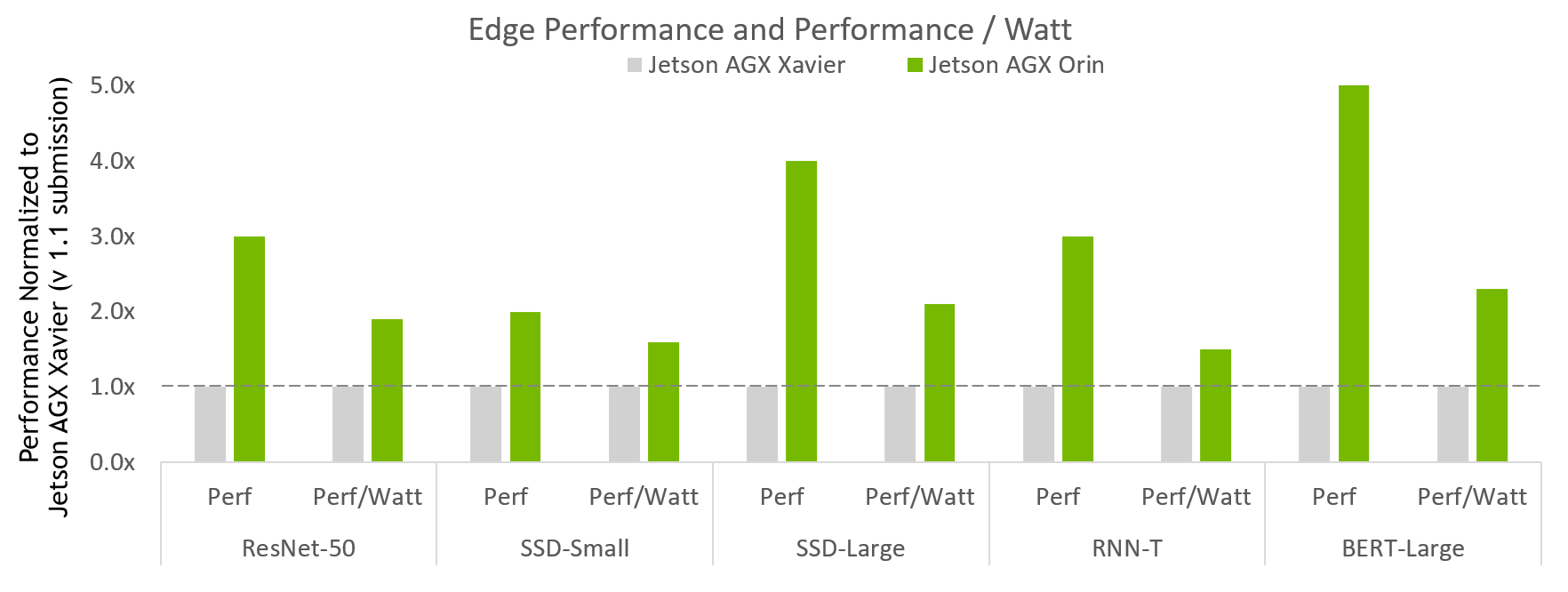
MLPerf v2.0 Inference Edge Closed and Edge Closed Power; Performance/Watt from MLPerf results for respective submissions for Data Center and Edge, Offline Throughput, and Power. NVIDIA Xavier AGX Xavier: 1.1-110 and 1.1-111 | Jetson AGX Orin: 2.0-140 and 2.0-141. MLPerf name and logo are trademarks. Source: http://www.mlcommons.org/en.
Figure 1 shows that Jetson AGX Orin delivers up to 5x more performance compared to previous generation. It brings on average about 3.4x more performance across the full breadth of usages tested. In addition, Jetson AGX Orin delivers up to 2.3x more energy efficiency.
Jetson Orin AGX is an SoC that brings up to 275 TOPS of AI compute for multiple concurrent AI inference pipelines, plus high-speed interface support for multiple sensors. The NVIDIA Jetson AGX Orin Developer Kit enables you to create advanced robotics and edge AI applications for manufacturing, logistics, retail, service, agriculture, smart city, healthcare, and life sciences.
In the Data Center category, NVIDIA continues to deliver across-the-board AI inference performance leadership across all usages.
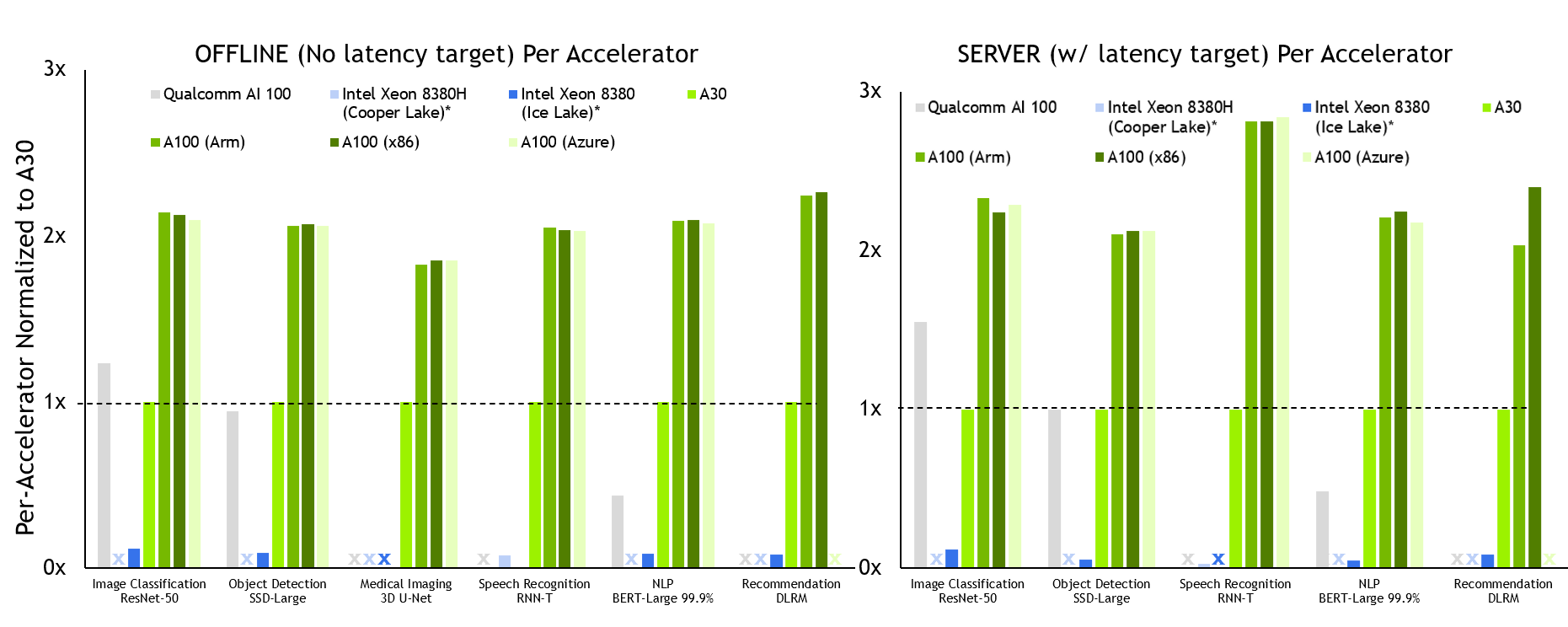
MLPerf v2.0 Inference Closed; Per-accelerator performance derived from the best MLPerf results for respective submissions using reported accelerator count in Data Center Offline and Server. Qualcomm AI 100: 2.0-130, Intel Xeon 8380 from MLPerf v.1.1 submission: 1.1-023 and 1.1-024, Intel Xeon 8380H 1.1-026, NVIDIA A30: 2.0-090, NVIDIA A100 (Arm): 2.0-077, NVIDIA A100 (x86): 2.0-094. MLPerf name and logo are trademarks. Source: http://www.mlcommons.org/en.
NVIDIA A100 delivers the best per-accelerator performance across all tests in both the Offline and Server scenarios.
We submitted the A100 in the following configurations:
- A100 SXM paired with x86 CPUs (AMD Epyc 7742)
- A100 PCIe paired with x86 CPUs (AMD Epyc 7742)
- A100 SXM paired with an Arm CPU (NVIDIA Ampere Architecture Altra Q80-30)
Microsoft Azure also submitted using its A100 instance, which we also show in this data.
All configurations deliver about the same inference performance, which is a testament to the readiness of our Arm software stack, as well as the overall performance of A100 on-premises and in the cloud.
A100 also delivers up to 105x more performance than a CPU-only submission (RNN-T, Server scenario). A30 also delivered leadership-level performance on all but one workload. Like the A100, it ran every Data Center category test.
Key optimizations
Delivering great inference performance requires a full stack approach, where great hardware is combined with optimized and versatile software. NVIDIA TensorRT and NVIDIA Triton Inference Server both play pivotal roles in delivering great inference performance across the diverse set of workloads.
Jetson AGX Orin optimizations
The NVIDIA Orin new NVIDIA Ampere Architecture iGPU is supported by NVIDIA TensorRT 8.4. It is the most important component of the SoC for MLPerf performance. The extensive TensorRT library of optimized GPU kernels was extended to support the new architecture. The TensorRT builder picks up these kernels automatically.
Furthermore, the plug-ins used in MLPerf networks have all been ported to NVIDIA Orin and added to TensorRT 8.4, including the res2 plug-in (resnet50) and qkv to context plug-in (BERT). Unlike systems with discrete GPU accelerators, inputs are not copied from host memory to device memory, because the SoC DRAM is shared by the CPU and iGPU.
In addition to the iGPU, NVIDIA uses two deep learning accelerators (DLAs) for maximum system performance on CV networks (resnet50, ssd-mobilenet, ssd-resnet34) in the offline scenario.
NVIDIA Orin incorporates a new generation of DLA HW. To take advantage of these hardware improvements, the DLA compiler added the following NVIDIA Orin features, which are available automatically when you upgrade to a future release of TensorRT, without modifying any application source code.
- SRAM chaining: Keeps intermediate tensors in local SRAM to avoid reads from/writes to DRAM, which reduces latency as well as platform DRAM usage. It also reduces interference with GPU inference.
- Convolution + pooling fusion: INT8 convolution + bias + scale + ReLU can be fused with a subsequent pooling node.
- Convolution + element-wise fusion: INT8 convolution + element-wise sum can be fused with a subsequent ReLU node.
The batch size of the two DLA accelerators were finely tuned to obtain the right balance of GPU+DLA aggregated performance. The tuning balanced the need to minimize scheduling conflicts for DLA engine’s GPU fallback kernels while reducing overall potential starvation out of the SoC’s shared DRAM bandwidth.
3D-UNet medical imaging
While most of the workloads were largely unchanged from MLPerf Inference v1.1, the 3D-UNet medical imaging workload was enhanced with the KITS19 data set. This new data set of kidney tumor images has much larger images of varying sizes and requires a lot more processing per sample.
The KiTS19 data set introduces new challenges in achieving performant, energy-efficient inference. More specifically:
- Input tensors used in KiTS19 vary in shape from 128x192x320 to 320x448x448; the biggest input tensor is 8.17x larger than the smallest input tensor.
- Tensors larger than 2 GB are needed during inference.
- There is a sliding window on the specific region of interest (ROI) shape (128x128x128), with a large overlap factor (50%).
To address this, we developed a sliding window method to process these images:
- Slice each input tensor into ROI shape, abiding by the overlap factor.
- Use a loop to process all the sliding window slices for a given input tensor.
- Weight and normalize the inference result of each sliding window.
- Get the final segmentation output by the ArgMax of the aggregated results of sliding window inferences.
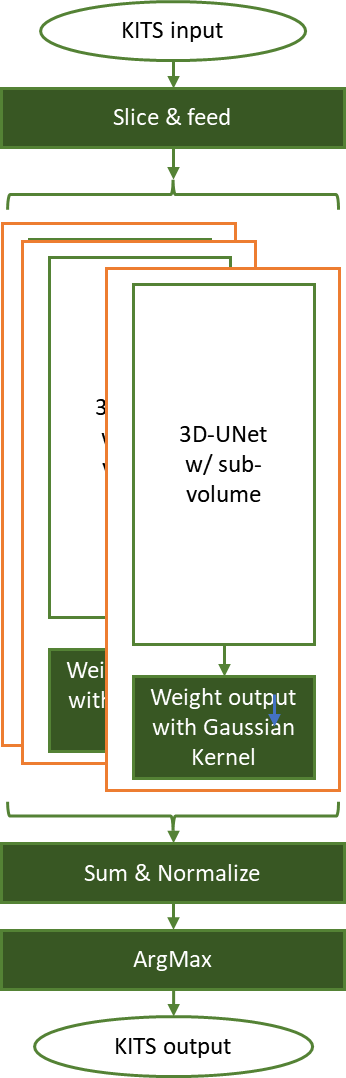
In Figure 3, each input tensor is sliced to the ROI-shape (128x128x128) with overlap-factor (50%) and fed into the pretrained network. Each sliding window output is then optimally weighted for capturing features with a Gaussian kernel of normalized sigma = 0.125.
The inference results are aggregated according to original input tensor shape and normalized, for those weighting factors. An ArgMax operation then carves the segmentation information, marking the background, normal kidney cells, and tumors.
This implementation compares the segmentation against the ground truth and calculates a DICE score to determine benchmarking accuracy. You can also check the outcome visually (Figure 4).
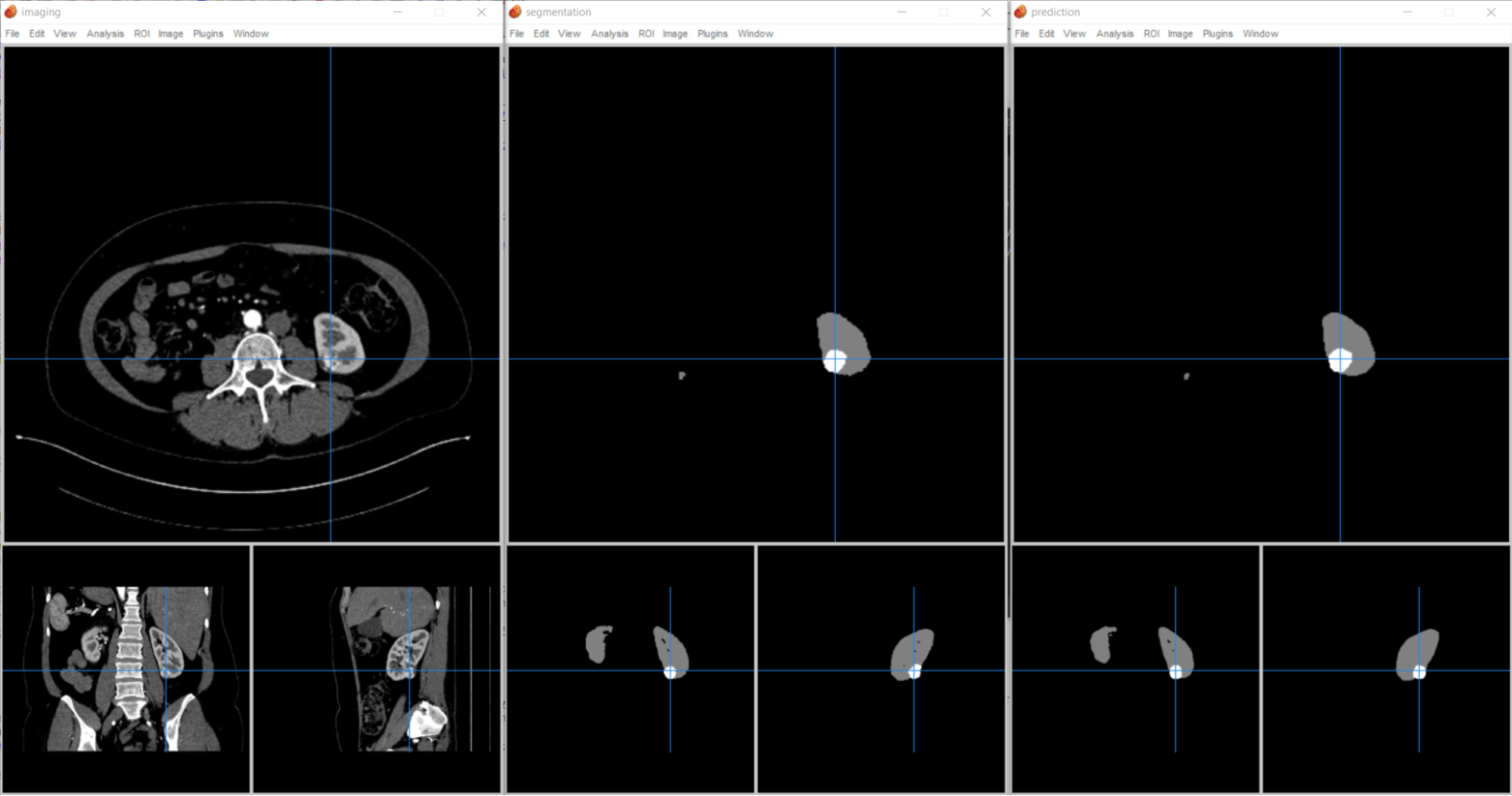
We’ve supported INT8 precision in our data center GPUs for over 5 years, and this precision brings significant speedups on many models with near-zero loss in accuracy compared to FP16 and FP32 precision levels.
For 3D-UNet, we used INT8 by calibrating the images from the calibration set using the TensorRT IInt8MinMaxCalibrator. This implementation achieves 100% accuracy in the FP32 reference model, thus enabling both high and low accuracy modes of the benchmark.
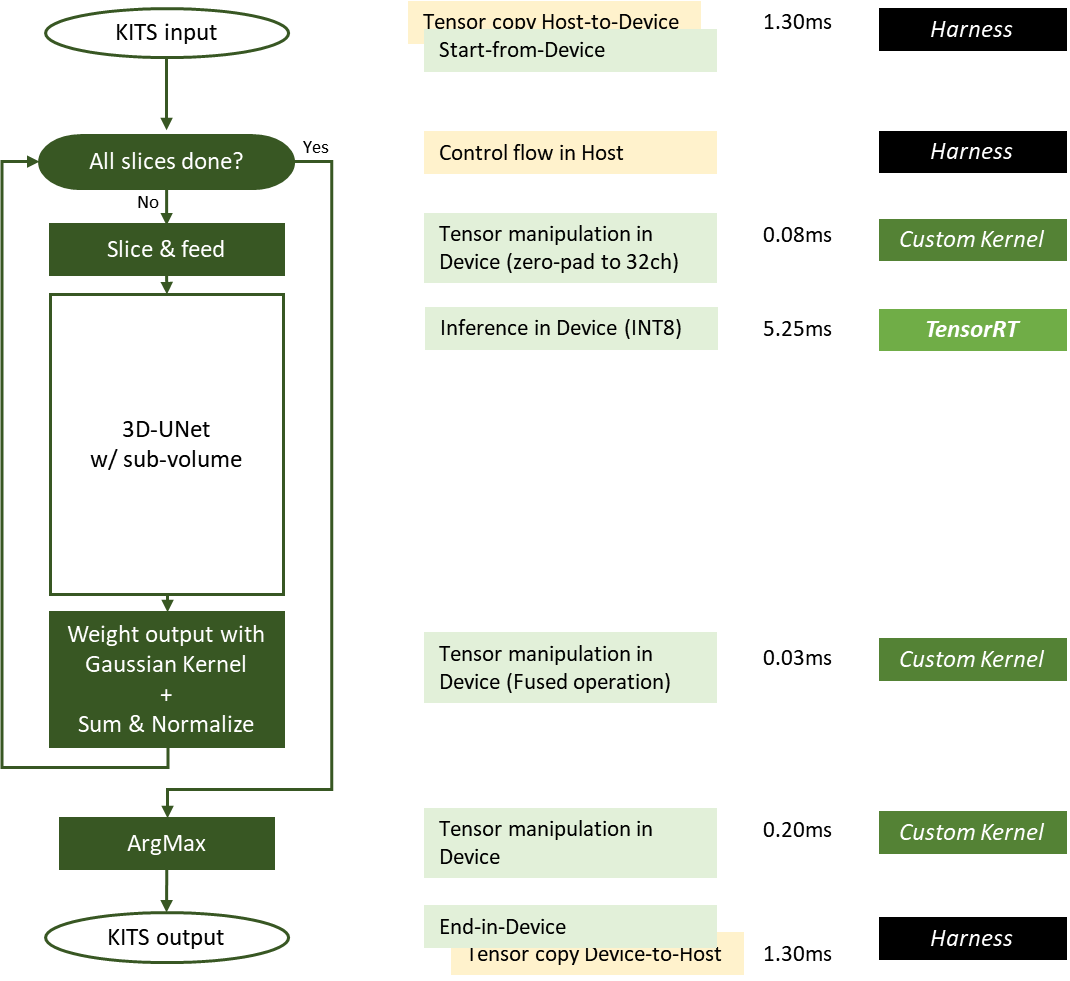
In Figure 5, green boxes are executed on the device (GPU) and yellow boxes are executed on the host (CPU). Some operations required for sliding window inference are optimized as fused operations.
Exploiting the GPUDirect RDMA and storage, host-to-device, or device-to-host data movement can be minimized or eliminated. The latency of each work is measured from the DGX-A100 system for one input sample whose size is close to the average input size. The latency for the slicing kernel and ArgMax kernel varies proportionally to the input image size.
Here are some of the specific optimizations implemented:
- The Gaussian kernel patches used for weighting are now precalculated and stored on disk and are loaded into GPU memory before the timed portion of the benchmark starts.
- Weighting and normalizing are optimized as a fused operation, using 27 precomputed patches required for the sliding window of 50% overlap on the 3D input tensor.
- Custom CUDA kernels handling the slicing, weighting, and ArgMax are written so that all these operations are done in the GPU, eliminating the need of H2D/D2H data transfer.
- Input tensor in INT8 LINEAR memory layout enables a minimal amount of data in H2D transfer as KiTS19 input set is a single channel.
TensorRT requires INT8 input in the NC/32DHW32 format. We use a custom CUDA kernel that performs slicing to zero-pad and reformat the INT8 LINEAR input tensor slice to INT8 NC/32DHW32 format in a contiguous memory region in GPU global memory.
Zero-padding and reformatting the tensor within the GPU is much faster than otherwise expensive H2D transfer of 32x more data. This optimization improves overall performance significantly and frees up the precious system resource.
The TensorRT engine is built for running inference on each of the sliding window slices. Because 3D-UNet is dense, we found that increasing batch size proportionally increases the runtime of the engine.
NVIDIA Triton optimizations
The NVIDIA submission continues to show the versatility of Triton Inference Server. This round, the Triton Inference Server also supports running NVIDIA Triton on AWS Inferentia. NVIDIA Triton uses the Python backend to run Inferentia-optimized PyTorch and TensorFlow models.
Using NVIDIA Triton and torch-neuron, the NVIDIA submissions achieved 85% to 100% of the native inference performance on Inferentia.
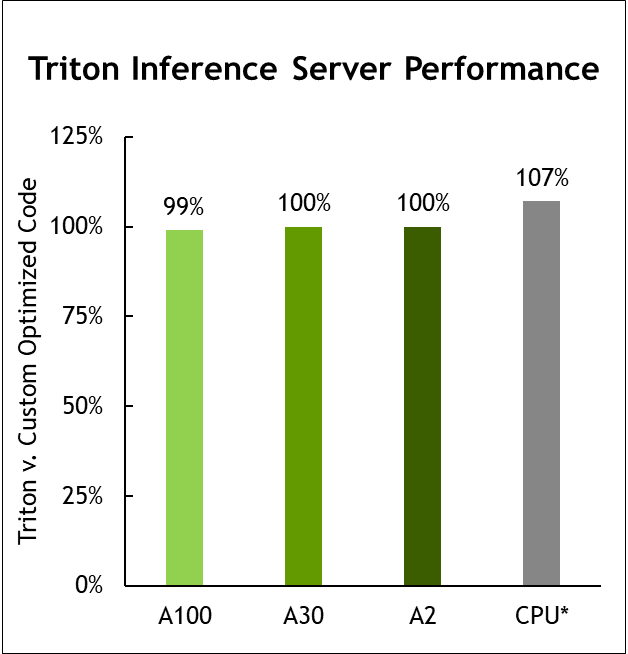
MLPerf v1.1 Inference Closed; Per-accelerator performance derived from the best MLPerf results for respective submissions using reported accelerator count in Data Center Offline. Geomean of all submitted workloads shown. CPU comparison based on Intel submission data from MLPerf Inference 1.1 to compare configurations with same CPU, submissions 1.0-16, 1.0-17, 1.0-19. NVIDIA Triton on CPU: 2.0-100 and 2.0-101. A2: 2.0-060 and 2.0-061. A30: 2.0-091 and 2.0-092. A100: 2.0-094 and 2.0-096. MLPerf name and logo are trademarks. Source: http://www.mlcommons.org/en.
NVIDIA Triton now supports the AWS Inferentia inference processor and delivers nearly equal performance to running on the AWS Neuron SDK alone.
It takes a platform
NVIDIA inference leadership comes from building the most performant AI accelerators, both for training and inference. But great hardware is just the beginning.
NVIDIA TensorRT and Triton Inference Server software play pivotal roles in delivering our great inference performance across this diverse set of workloads. They are available at NGC, the NVIDIA hub, along with other GPU-optimized software for deep learning, machine learning, and HPC.
The NGC containerized software makes it much easier to get accelerated platforms up and running so you can focus on building real applications, and speeding time-to-value. NGC is freely available through the marketplace of your preferred cloud provider.
For more information, see Inference Technical Overview. This paper covers the trends in AI inference, challenges around deploying AI applications, and details of inference development tools and application frameworks.