
 LEGO lovers scratching their heads reading assembly instructions could soon have help with complicated builds thanks to a new study from Stanford University,…
LEGO lovers scratching their heads reading assembly instructions could soon have help with complicated builds thanks to a new study from Stanford University,…
LEGO lovers scratching their heads reading assembly instructions could soon have help with complicated builds thanks to a new study from Stanford University, MIT, and Autodesk. The researchers designed a deep learning framework that translates 2D manuals into steps a machine can understand to build 3D LEGO kits. The work could advance research focused on creating machines that aid people while assembling objects.
“LEGO manuals provide a self-contained environment that exemplifies a core human skill: learning to complete tasks under guidance. Leveraging recent advances in visual scene parsing and program synthesis, we aimed to build machines with similar skills, starting with LEGO and eventually aiming for real-world scenarios,” said study senior author Jiajun Wu, an assistant professor in Computer Science at Stanford University.
According to the researchers, translating 2D manuals with AI presents two main challenges. First, AI must learn and understand the correspondence between a 3D shape during each assembly step based on the 2D manual images. This includes accounting for the orientation and alignment of the pieces.
It must also be capable of sorting through the bricks and inferring their 3D poses within semi-assembled models. As part of the LEGO build process, small pieces are combined to create larger parts, such as the head, neck, and body of a guitar. When combined, these larger parts create a complete project. This increases the difficulty as machines must parse out all the LEGO bricks, even those that may not be visible such as LEGO studs and antistuds.
The team worked to create a model that can translate 2D manuals into machine-executable plans to build a defined object. While there are two current approaches for performing this task—search-based and learning-based—both present limitations.
The search-based method seeks out possible 3D poses of pieces and manual images, looking for the correct pose. The method is compute intensive and slow, but precise.
Learning-based models rely on neural networks to predict a component’s 3D pose. They are fast, but not as accurate, especially when using unseen 3D shapes.
To solve this limitation, the researchers developed the Manual-to-Executable-Plan Network (MEPNet), which according to the study, uses deep learning and computer vision to integrate “neural 2D keypoint detection modules and 2D-3D projection algorithms.”
Working off a sequence of predictions, at each step, the model reads the manual, locates the pieces to add, and deduces the 3D positioning. After the model predicts the pose for each piece and step, it can parse the manual from scratch creating a building plan a robot could follow to build the LEGO object.
“For each step, the inputs consist of 1) a set of primitive bricks and parts that have been built in previous steps represented in 3D; and 2) a target 2D image showing how components should be connected. The expected output is the (relative) poses of all components involved in this step,” the researchers write in the study.
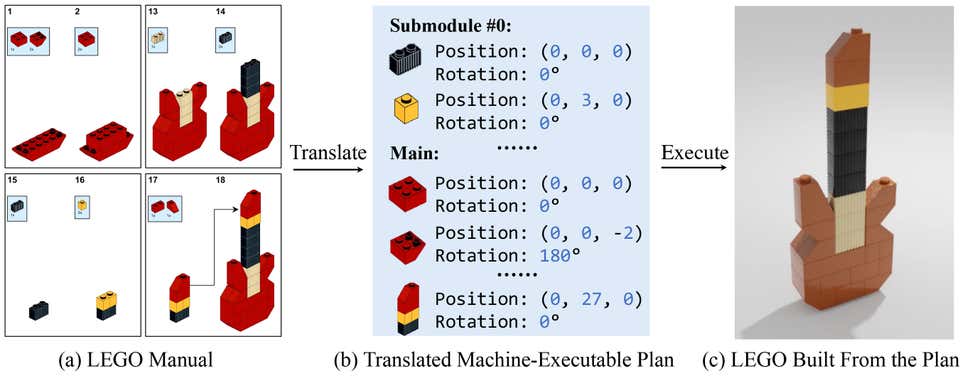
They created the first synthetic training data from a LEGO kit containing 72 types of bricks and employed an image rendering from LPub3D, an open-source application for “creating LEGO style digital building instructions.”
In total, the researchers generated 8,000 training manuals, using 10 sets for validation, and 20 sets for testing. There are around 200 individual steps in each data set accounting for about 200,000 individual steps in training.
“We train MEPNet with full supervision on a synthetically generated dataset where we have the ground truth keypoint, mask, and rotation information,” they write in the study. The MEPNet model was trained for 5 days on four NVIDIA TITAN RTX GPUs powered by NVIDIA Turing architecture.
They also tested the model on a Minecraft house dataset, which has a similar build style to LEGO.
Comparing MEPNet to existing models, the researchers found it outperformed the others in real-world LEGO sets, synthetically generated manuals, and the Minecraft example.
MEPNet was more accurate in pose estimations and better at identifying builds even with unseen pieces. The researchers also found that the model is able to apply learnings from synthetically generated manuals to real-world LEGO manuals.
While producing a robot capable of executing the plans is also needed, the researchers envision this work as a starting point.
“Our long-term goal is to build machines that can assist humans in constructing and assembling complex objects. We are thinking about extending our approach to other assembly domains, such as IKEA furniture,” said lead author Ruocheng Wang, an incoming Ph.D. student in Computer Science at Stanford University.
The lego_release code is available on GitHub.
Read the study Translating a Visual LEGO Manual to a Machine-Executable Plan.
View the research project page.