
 Speech is one of the primary means to communicate with an AI-powered application. From virtual assistants to digital avatars, voice-based interfaces are…
Speech is one of the primary means to communicate with an AI-powered application. From virtual assistants to digital avatars, voice-based interfaces are…
Speech is one of the primary means to communicate with an AI-powered application. From virtual assistants to digital avatars, voice-based interfaces are changing how we typically interact with smart devices.
Deep learning techniques for speech recognition and speech synthesis are helping improve the user experience—think human-like responses and natural-sounding tones.
If you plan to build and deploy a speech AI-enabled application, this post provides an overview of how automatic speech recognition (ASR) and text-to-speech (TTS) technologies have evolved due to deep learning. I also mention some popular, state-of-the-art ASR and TTS architectures used in today’s modern applications.
Demystifying speech AI
Every day, hundreds of billions of audio minutes are generated, whether you are conversing with digital humans in the metaverse or actual humans in contact centers. Speech AI can assist in automating all these audio minutes.
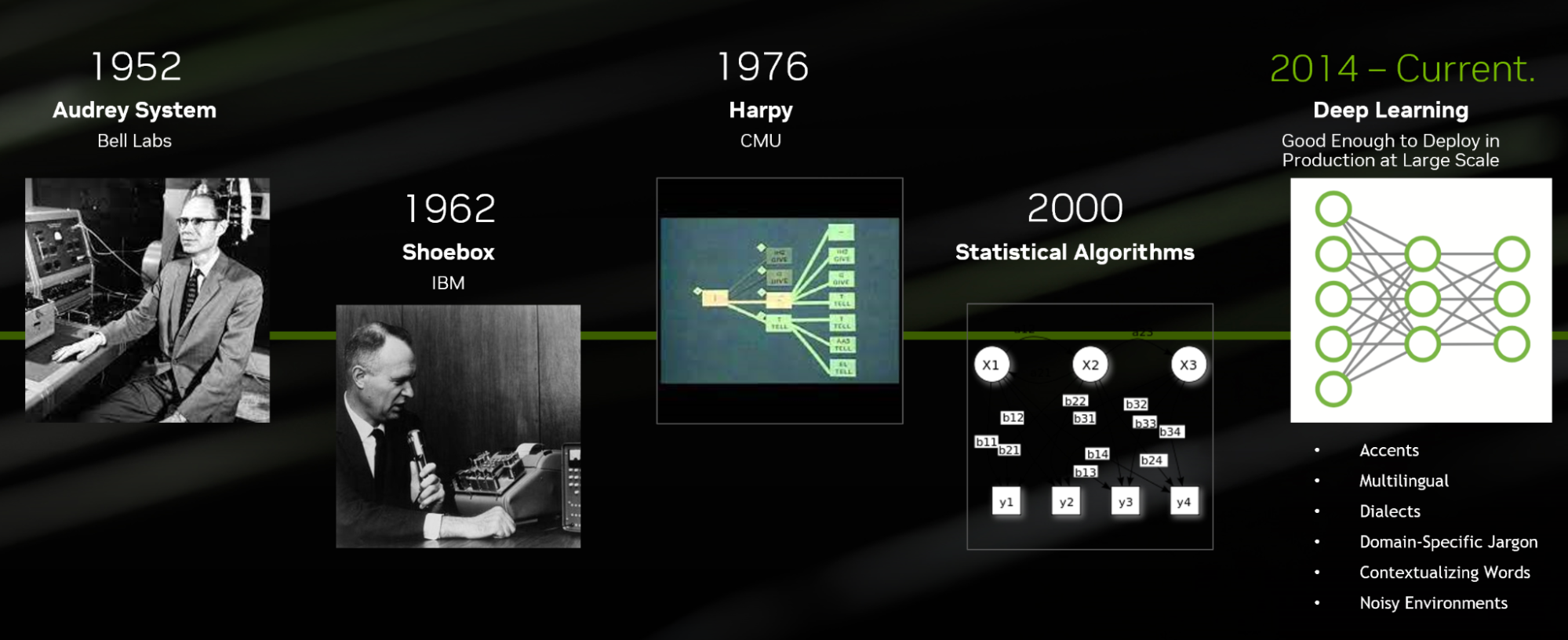
Speech AI includes technologies like ASR, TTS, and related tasks. Interestingly, these technologies are not new and have existed for the last five decades.
Speech recognition evolution
Today, ASR algorithms developed using deep learning techniques can be customized for domain-specific jargon, languages, accents, and dialects, as well as transcribing in noisy environments.
This level of technique differs significantly from the first ASR system, Audrey, which was invented by Bell Labs in 1952. At the time, Audrey could only transcribe numbers and was not developed using deep learning techniques.
ASR pipeline
A standard ASR deep learning pipeline consists of a feature extractor, acoustic model, decoder and language model, and BERT punctuation and capitalization model.
Text-to-speech evolution
TTS, or speech synthesis, systems that are developed using deep learning techniques sound like real humans and can run in real time to have natural and meaningful discussions. On the other hand, traditional systems like Voder, DECtalk commercial, and concatenative TTS sound robotic and are difficult to run in real time.
Deep learning TTS algorithms are flexible enough so that you can adjust the speed, pitch, and duration at the inference time to generate more expressive TTS voices.
TTS pipeline
A basic TTS pipeline includes the following components: text normalization, text encoding, pitch/duration predictor, spectrogram generator, and vocoder model.
You can learn more about how ASR and TTS have changed over the past few years and about each of the models and modules in ASR and TTS pipelines in the on-demand video, Speech AI Demystified.
Popular ASR and TTS architectures used today
Several state-of-the-art neural network architectures have been created. Some of the most popular ones in use today for ASR are CTC and transducer-based architecture models. For example, you can apply these architecture techniques to models such as CitriNet and Conformer.
For TTS, different types of architectures exist:
- Autoregressive or non-autoregressive
- Deterministic or generative
- Explicit control or non-explicit control
Each of these TTS architectures offer varying capabilities. For example, deterministic models can predict the outcome exactly and don’t include randomness. Generative models include the data distribution itself and can capture different variations of the synthetic voice. To build an end-to-end text-to-speech pipeline, you must combine one architecture from each category.
You can get the latest architecture best practices to build an ASR and TTS pipeline for your voice-enabled application in the on-demand video, Speech AI Demystified.
NVIDIA Speech AI SDK
You can develop deep learning-based ASR and TTS algorithms by leveraging a GPU-accelerated speech AI SDK. NVIDIA Riva helps you build and deploy customizable AI pipelines that deliver world-class accuracy in all clouds, on-premises, at the edge, and on embedded devices.
Riva has state-of-the-art pretrained models on NGC that are trained on multiple open and proprietary datasets. You can use low-coding tools to customize these models to fit your industry and use case with optimized speech AI skills that can run in real time, without sacrificing accuracy.
Build your first speech AI application
Are you looking to add an interactive voice experience to applications? The following free ebooks will guide your journey:
- Get a comprehensive overview of the growing speech AI landscape with Introduction to Speech AI.
- Learn how to achieve natural-sounding speech by adding TTS skills to your application with End-to-End Speech AI Pipelines.
- Understand how your organization can deploy speech AI with Building Speech AI Applications.
If you prefer step-by-step instruction, check out a self-paced online course to get started with highly accurate custom ASR for speech AI.