
 From taking your order and serving you food in a restaurant to playing poker with you, service robots are becoming increasingly prevalent. Globally, you can…
From taking your order and serving you food in a restaurant to playing poker with you, service robots are becoming increasingly prevalent. Globally, you can…
From taking your order and serving you food in a restaurant to playing poker with you, service robots are becoming increasingly prevalent. Globally, you can find these service robots at hospitals, airports, and retail stores.
According to Gartner, by 2030, 80% of humans will engage with smart robots daily, due to smart robot advancements in intelligence, social interactions, and human augmentation capabilities, up from less than 10% today.
An accurate speech AI or voice AI interface that can quickly understand humans and mimic human speech is critical to a service robot’s ease of use. Developers are integrating automatic speech recognition (ASR) and text-to-speech (TTS) with service robots to enable essential skills, such as understanding and responding to human questions in natural language. These voice-based technologies make up speech AI.
This post explains how ASR and TTS can be used in service robot applications. I provide a walkthrough on how to customize them using speech AI software tools for industry-specific jargon, languages, and dialects, depending on where the robot is deployed.
Why add speech AI to service robot applications?
Service robots are like digital humans in the metaverse except that they operate in the physical world. These service robots can help support warehouse workers, perform dangerous tasks while following human instructions, or even assist in activities that require contactless services. For instance, a service robot in the hospitality industry can greet guests, carry bags, and take orders.
For all these service robots to understand and respond in a human-like way, developers must incorporate highly accurate speech AI that runs in real time.
Examples of speech AI-enabled service robot applications
Today, service robots are used in a wide range of industries.
Restaurants
Online food delivery services are growing in popularity worldwide. To handle the increased customer demand without compromising quality, service robots can assist staff with tasks such as order taking or delivering food to in-person customers.
Hospitals
In hospitals, service robots can support and empower patient care teams by handling patient-related tasks. For example, a speech AI-enabled service robot can empathetically converse with patients to provide company or help improve their mental health state.
Ambient assisted living
In ambient assisted living environments, technology is primarily used to support the independence and safety of elderly or vulnerable adults. Service robots can assist with daily activities, such as transporting food trays from one location to another or using a smart robotic pill dispenser to manage medications in a timely manner. With speech AI skills, service robots can also provide emotional support.
Service robot reference architecture
Service robots help businesses improve quality assurance and boost productivity in several ways:
- Assisting frontline workers with daily repetitive tasks in restaurants or manufacturing environments
- Helping customers find desired items in retail stores
- Supporting physicians and nurses with patient healthcare services in hospitals
In these settings, it’s imperative that robots can accurately process and understand what a user is relaying. This is especially true for situations where danger or serious harm is a possibility, such as a hospital. Service robots that can naturally converse with humans also contribute to a positive overall user experience for an application.
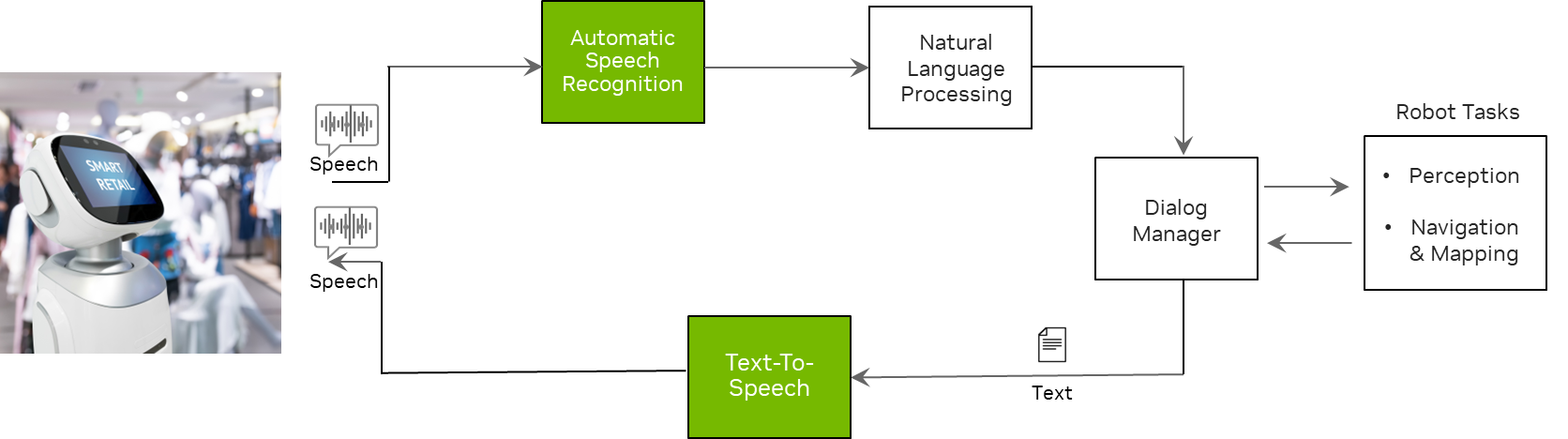
Figure 1 shows that service robots use speech recognition to comprehend what users are saying and TTS to respond to users with a synthetic voice. Other components such as NLP and a dialog manager, are used to help service robots understand context and generate appropriate answers to users’ questions.
Also, the modules under robot tasks such as perception, navigation, and mapping help the robot understand its physical surroundings and move in the right direction.
Voice user interfaces to service robots
Voice user interfaces include two main components: automatic speech recognition and text-to-speech. Automatic speech recognition, also known as speech-to-text, is the process of converting raw speech into text. Text-to-speech, also known as speech synthesis, is the process of converting text into human-like speech.
Developing speech AI pipelines has its own challenges. For example, if a service robot is deployed in restaurants, it should be able to understand words like matcha, cappuccino, and ristretto. It should even transcribe in noisy environments as most people interacting with these applications are in open spaces.
Not only do the robots have to understand what is being said, but they should also be able to say these words correctly. Similarly, each industry has its own terminology that these robots must understand and respond to in real time.
Automatic speech recognition
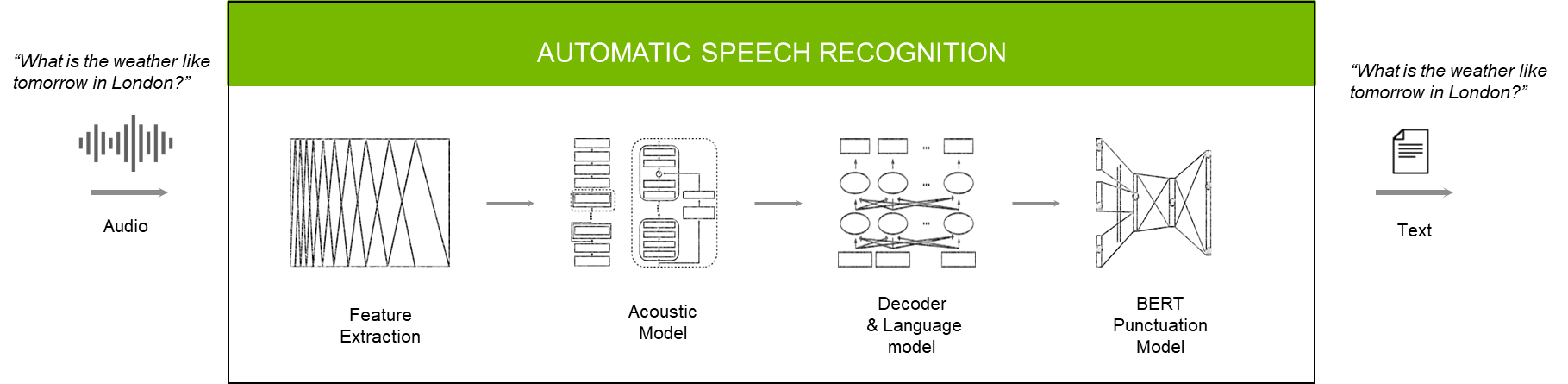
The roles of each model or module in the ASR pipeline are as follows:
- The feature extractor converts raw audio into spectrograms or mel spectrograms.
- The acoustic model takes these spectrograms and generates a matrix that has probabilities of characters or words over each time step.
- The decoder and language model put together these characters/words into a transcript.
- The punctuation and capitalization model applies things like commas, periods, and question marks in the right places for better readability.
Text-to-speech
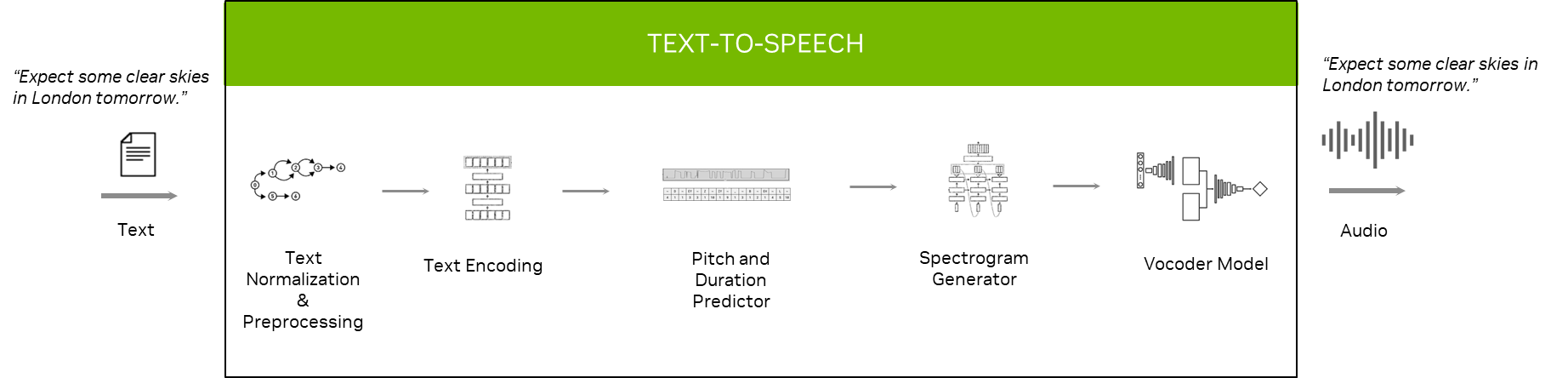
The roles of each model or module in the TTS pipeline are as follows:
- In the text normalization and preprocessing stage, the text is converted into verbalized form. For instance: “at 10:00” -> “at ten o’clock.”
- The text encoding module converts text into an encoded vector.
- The pitch predictor predicts how much highness or lowness you have to give certain words, while the duration predictor predicts how long it takes to pronounce a character or word.
- The spectrogram generator uses an encoded vector and other supporting vectors as input to generate a spectrogram.
- The vocoder model takes spectrograms as input and produces a human-like voice as output.
Speech AI software suite
NVIDIA provides a variety of datasets, tools, and SDKs to help you build end-to-end speech AI pipelines. Customize the pipelines to your industry’s specific vocabulary, language, and dialects and run in milliseconds for natural and engaging interactions.
Datasets
To democratize and diversify speech AI technology, NVIDIA collaborated with Mozilla Common Voice (MCV). MCV is a crowd-sourced project in which volunteers contribute speech data to a public dataset that anyone can use to train voice-enabled technology. You can download various language audio datasets from MCV to develop ASR and TTS models.
NVIDIA also collaborated with Defined.ai, a one-stop shop for training data. You can download audio and speech training data in multiple domains, languages, and accents for use in speech AI models.
Pretrained models
NGC provides several pretrained models trained on a variety of open and proprietary datasets. All models have been optimized and trained on NVIDIA DGX servers for hundreds of thousands of hours.
You can fine-tune these highly accurate, pretrained models on a relevant dataset to improve accuracy even further.
Open-source tools
If you’re looking for open-source tools, NVIDIA offers NeMo, an open-source framework for building and training state-of-the-art AI speech and language models. NeMo is built on top of PyTorch and PyTorch Lightning, making it easy for you to develop and integrate modules that are already familiar.
Speech AI SDK
Use NVIDIA Riva, a free GPU-accelerated speech AI SDK, to build and deploy fully customizable, real-time AI pipelines. Riva offers state-of-the-art, highly accurate, pretrained models through NGC:
- English
- Spanish
- Mandarin
- Hindi
- Russian
- Korean
- German
- French
- Portuguese
Japanese, Arabic, and Italian are coming soon.
With NeMo you can fine-tune these pretrained models on industry-specific jargon, languages, dialects, and accents, and optimized speech AI skills to run in real time.
You can deploy Riva skills in streaming or offline in all clouds, on-premises, at the edge, and on embedded devices.
Running Riva speech AI skills on embedded for robotics applications
In this section, I show you how to run out-of-the-box ASR and TTS skills with Riva on embedded devices. For better accuracy and performance, Riva also enables you to customize or fine-tune models on domain-specific datasets.
You can run Riva speech AI skills in both streaming and offline modes. First, set up and run the Riva server on embedded.
Prerequisites
- Access to NGC.
- Follow all steps to be able to run
ngccommands from a command-line interface (CLI).
- Follow all steps to be able to run
- Access to NVIDIA Jetson Orin, NVIDIA Jetson AGX Xavier, or NVIDIA Jetson NX Xavier.
- NVIDIA JetPack version 5.0.2 on the Jetson platform.
For more information, see the Support Matrix.
Server setup
Download the scripts from NGC by running the following command:
ngc registry resource download-version nvidia/riva/riva_quickstart_arm64:2.7.0
Initialize the Riva server:
bash riva_init.sh
Start the Riva server:
bash riva_start.sh
For more information about the most recent steps, see the Quick Start Guide.
Running C++ ASR client
For embedded, Riva server comes with sample clients that you can seamlessly use to do inference.
Run the following command for streaming ASR:
riva_streaming_asr_client --audio_file=/opt/riva/wav/en-US_sample.wav
For more information about customizing Riva ASR models and pipelines for your industry-specific jargon, languages, dialects, and accents, see the instructions on the Model Overview in the Riva documentation.
Running C++ TTS client
For Riva TTS client on embedded, run the following command to synthesize audio files:
riva_tts_client --voice_name=English-US.Female-1
--text="Hello, this is a speech synthesizer."
--audio_file=/opt/riva/wav/output.wav
For more information about customizing TTS models and pipelines on domain-specific datasets, see Model Overview in the Riva User Guide.
Resource for developing speech AI applications
Speech AI makes it possible for service robots and other interactive applications to comprehend nuanced human language and respond with ease.
It is empowering everything from real people in call centers to service robots in every industry. To understand how speech AI skills were integrated with a robotic dog that can fetch drinks in real life, see Low-code Building Blocks for Speech AI Robotics.
Or, browse speech AI posts to learn about speech AI concepts, speech recognition deployment challenges and tips, or unique ASR applications.
You can also access developer ebooks, such as End-To-End Speech AI pipelines to learn more about models and modules in speech AI pipelines and Building Speech AI Applications to gain insight on how to build and deploy real-time speech AI pipelines for your application.