
 NVIDIA and Snowflake announced a new partnership bringing accelerated computing to the Data Cloud with the new Snowpark Container Services (private preview), a…
NVIDIA and Snowflake announced a new partnership bringing accelerated computing to the Data Cloud with the new Snowpark Container Services (private preview), a…
NVIDIA and Snowflake announced a new partnership bringing accelerated computing to the Data Cloud with the new Snowpark Container Services (private preview), a runtime for developers to manage and deploy containerized workloads. By integrating the capabilities of GPUs and AI into the Snowflake platform, customers can enhance ML performance and efficiently fine-tune LLMs. They achieve this by leveraging the NVIDIA AI Enterprise software suite on the secure and governed Snowflake platform. With this collaboration, customers can develop cost-effective AI-powered applications using their valuable data.
About NVIDIA AI Enterprise
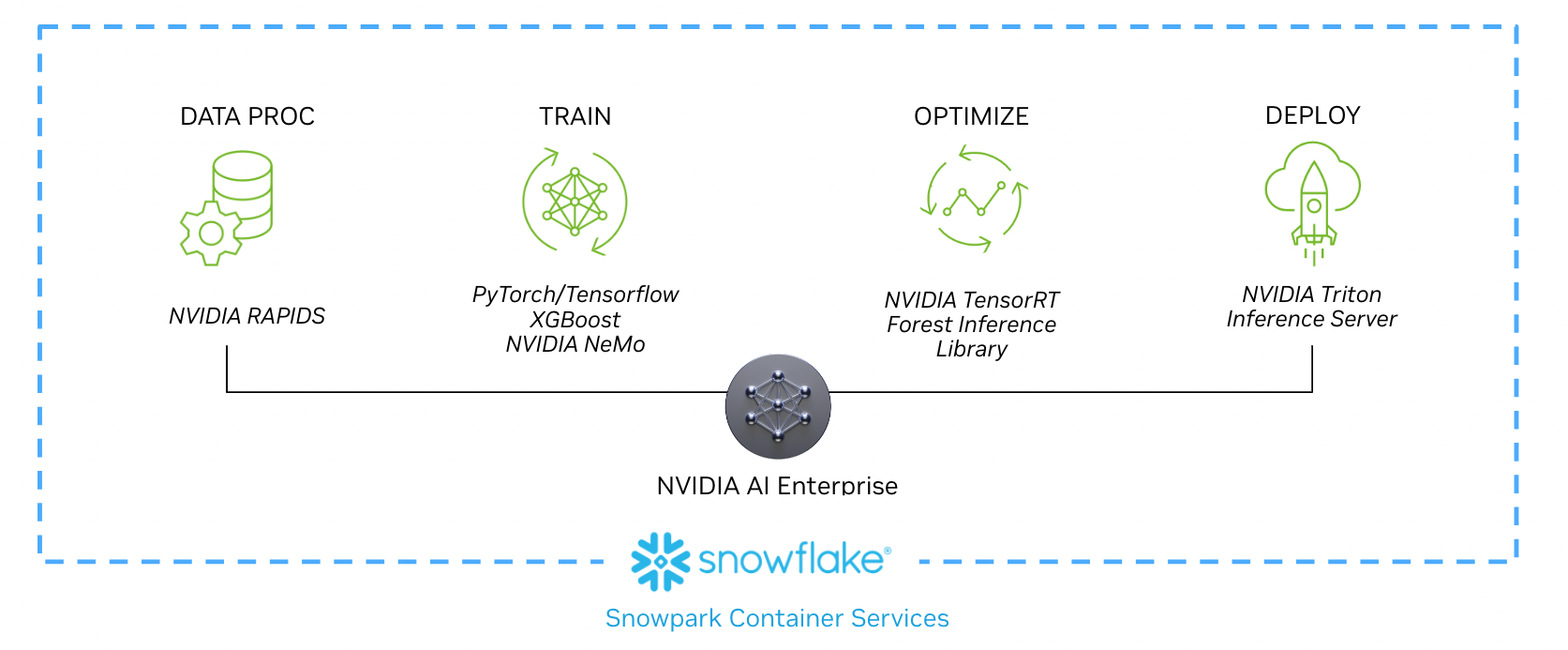
As AI initiatives progress, the need for a trusted, scalable support model for enterprises becomes vital to making sure AI projects stay on track. To support building AI applications, NVIDIA AI Enterprise includes the software to streamline the end-to-end AI pipeline, from data prep, to model training, to simulation, and deploying at scale.
NVIDIA AI Enterprise is the software layer of the NVIDIA AI platform and includes:
- Optimizations to run on accelerated infrastructure for performance, productivity, and cost savings.
- Enterprise-grade support, security, and API stability.
- AI workflows and pretrained models to speed time to production.
- Certifications to deploy everywhere—cloud, data center, and edge.
Enable AI workflows directly on Snowflake Data Cloud
Data is the fuel for generative AI—and the data fueling enterprise AI use cases lives in Snowflake. With the NVIDIA AI platform now available on Snowpark Container Services, customers can put their data to work without sacrificing security, performance, or ease of use.
Using the NVIDIA AI Enterprise accelerated infrastructure and computing libraries through Snowpark Container Services, developers and data scientists can build accelerated AI workflows with ease.
With Snowpark, enterprises securely deploy and process their Python code used for AI and ML. Developers can also expand accelerated ML workloads and run sophisticated AI models such as LLMs where their data is already stored. This reduces potential security risks and latency when moving large amounts of data.
The following workflow shows how a data scientist can implement each stage, from data processing to real-time inferencing, as part of the new partnership. The technologies outlined in this workflow and example use case, including NVIDIA RAPIDS, NVIDIA Merlin, NVIDIA TensorRT, and NVIDIA Triton are all included with NVIDIA AI Enterprise and available on Snowpark Container Services.
Example use case: training a recommender model
Session-based recommender systems are becoming increasingly important in content-rich applications aiming to provide more relevant next-item predictions. Training these models starts by loading data and conducting initial SQL and DataFrame preprocessing using the Snowpark Python library.
Customers can use NVIDIA RAPIDS, Merlin, and other AI frameworks in a Jupyter Notebook running in Snowpark Container Services to augment data processing and train models.
NVTabular, part of Merlin, is an accelerated feature engineering library designed to generate key features needed in recommender systems model training. After the data is prepared using NVTabular, additional accelerated computing libraries in Merlin begin training the AI workflow.
The task of training a model on very large datasets can be time-consuming. During training, the dataset is often copied in and out of memory in chunks while compute cores process it. Training a model using a GPU provides higher throughput and faster model training because they include high-bandwidth memory and make use of an increased number of compute cores for parallel processing.
Operating on Snowpark Container Services results in a 20X speedup during the training of a predictive model with accelerated compute. This boosts the productivity of data scientists during model creation and reduces the overall TCO by doing more, in less time.
After training, the model is tested for accuracy with sample test data. The workflow then optimizes and retrains the model as needed. Finally, it publishes the newly trained model to a registry such as the Snowpark Model Registry (private preview).
After training, NVIDIA AI Enterprise provides TensorRT, optimizing for accelerated computing. At the final stage in the workflow, the model deploys and begins performing inference tasks. Running inside a Triton Inference server, it consumes data in real time and provides insights.
Request access to get started
Snowflake customers can request access to the technical preview of the Snowpark Container Services from their account team. Customers are also eligible for a free NVIDIA AI Enterprise 90-day evaluation license to make sure they have access to the full stack of NVIDIA AI software.
Learn more about NVIDIA AI Enterprise.
Learn more about Snowpark Container Services.