
 NVIDIA TAO Toolkit provides a low-code AI framework to accelerate vision AI model development suitable for all skill levels, from novice beginners to expert…
NVIDIA TAO Toolkit provides a low-code AI framework to accelerate vision AI model development suitable for all skill levels, from novice beginners to expert…
NVIDIA TAO Toolkit provides a low-code AI framework to accelerate vision AI model development suitable for all skill levels, from novice beginners to expert data scientists. With the TAO Toolkit, developers can use the power and efficiency of transfer learning to achieve state-of-the-art accuracy and production-class throughput in record time with adaptation and optimization.
NVIDIA released TAO Toolkit 5.0, bringing groundbreaking features to enhance any AI model development. The new features include source-open architecture, transformer-based pretrained models, AI-assisted data annotation, and the capability to deploy models on any platform.
Release highlights include:
- Model export in open ONNX format to support deployment on GPUs, CPUs, MCUs, neural accelerators, and more.
- Advanced Vision Transformer training for better accuracy and robustness against image corruption and noise.
- New AI-assisted data annotation, accelerating labeling tasks for segmentation masks.
- Support for new computer vision tasks and pretrained models for optical inspection, such as optical character detection and Siamese Network models.
- Open source availability for customizable solutions, faster development, and integration.
Get started
- Visit the TAO Toolkit getting started page for instructional videos and quick start guides.
- Download TAO Toolkit and pretrained models from NGC.
This post has been revised from its original version to provide accurate information reflecting the TAO Toolkit 5.0 release.
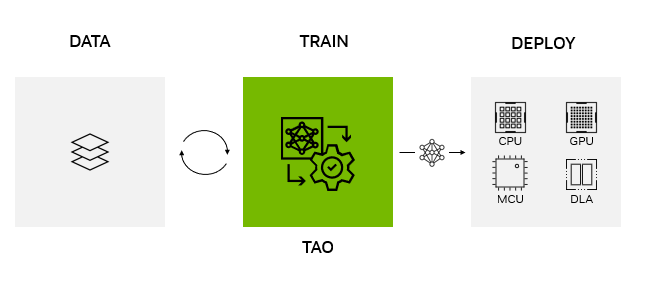
Deploy NVIDIA TAO models on any platform, anywhere
NVIDIA TAO Toolkit 5.0 supports model export in ONNX. This makes it possible to deploy a model trained with NVIDIA TAO Toolkit on any computing platform—GPUs, CPUs, MCUs, DLAs, FPGAs—at the edge or in the cloud. NVIDIA TAO Toolkit simplifies the model training process and optimizes the model for inference throughput, powering AI across hundreds of billions of devices.
Edge Impulse, a platform for building, refining, and deploying machine learning models and algorithms, integrated TAO Toolkit into their edge AI platform. With this integration, Edge Impulse now offers advanced vision AI capabilities and models that complement its current offerings. Developers can use the platform to build production AI with TAO for any edge device. Learn more about the integration in a blog post from Edge Impulse.
STMicroelectronics, a global leader in embedded microcontrollers, integrated NVIDIA TAO Toolkit into its STM32Cube AI developer workflow. This puts the latest AI capabilities into the hands of millions of STMicroelectronics developers. It provides, for the first time, the ability to integrate sophisticated AI into widespread IoT and edge use cases powered by the STM32Cube.
Now, with NVIDIA TAO Toolkit, even the most novice AI developers can optimize and quantize AI models to run on STM32 MCU within the microcontroller’s compute and memory budget. Developers can also bring their own models and fine-tune using TAO Toolkit. More information about this work is captured in the following demo. Learn more about the project on the STMicroelectronics GitHub page.
While TAO Toolkit models can run on any platform, these models achieve the highest throughput on NVIDIA GPUs using TensorRT for inference. On CPUs, these models use ONNX-RT for inference. The script and recipe to replicate these numbers will be provided once the software becomes available.
| NVIDIA Jetson Orin Nano 8 GB | NVIDIA Jetson AGX Orin 64 GB | T4 | A2 | A100 | L4 | H100 | |
| PeopleNet | 112 | 679 | 429 | 242 | 3,264 | 797 | 7,062 |
| DINO – FAN-S | 3.1 | 11.2 | 20.4 | 11.7 | 121 | 44 | 213 |
| SegFormer – MiT | 1.3 | 4.8 | 9.4 | 5.8 | 62.2 | 17.8 | 108 |
| OCRNet | 935 | 3,876 | 3,649 | 2,094 | 28,300 | 8,036 | 55,700 |
| EfficientDet | 61 | 227 | 303 | 184 | 1,521 | 522 | 2,428 |
| 2D Body Pose | 136 | 557 | 593 | 295 | 4,140 | 1,010 | 7,812 |
| 3D Action Recognition | 52 | 212 | 269 | 148 | 1,658 | 529 | 2,708 |
AI-assisted data annotation and management
Data annotation remains an expensive and time-consuming process for all AI projects. This is especially true for CV tasks like segmentation that require generating a segmentation mask at pixel level around the object. Generally, segmentation masks cost 10x more than object detection or classification.
It is faster and less expensive to annotate segmentation masks with new AI-assisted annotation capabilities using TAO Toolkit 5.0. Now you can use the weakly supervised segmentation architecture, Mask Auto Labeler (MAL) to aid in segmentation annotation and in fixing and tightening bounding boxes for object detection. Loose bounding boxes around an object in ground truth data can lead to suboptimal detection results. But, with AI-assisted annotation, you can tighten your bounding boxes over objects, leading to more accurate models.

MAL is a transformer-based, mask auto-labeling framework for instance segmentation using only box annotations. MAL takes box-cropped images as inputs and conditionally generates the mask pseudo-labels. It uses COCO annotation format for both input and output labels.
MAL significantly reduces the gap between auto labeling and human annotation for mask quality. Instance segmentation models trained using the MAL-generated masks can nearly match the performance of the fully supervised counterparts, retaining up to 97.4% performance of fully supervised models.
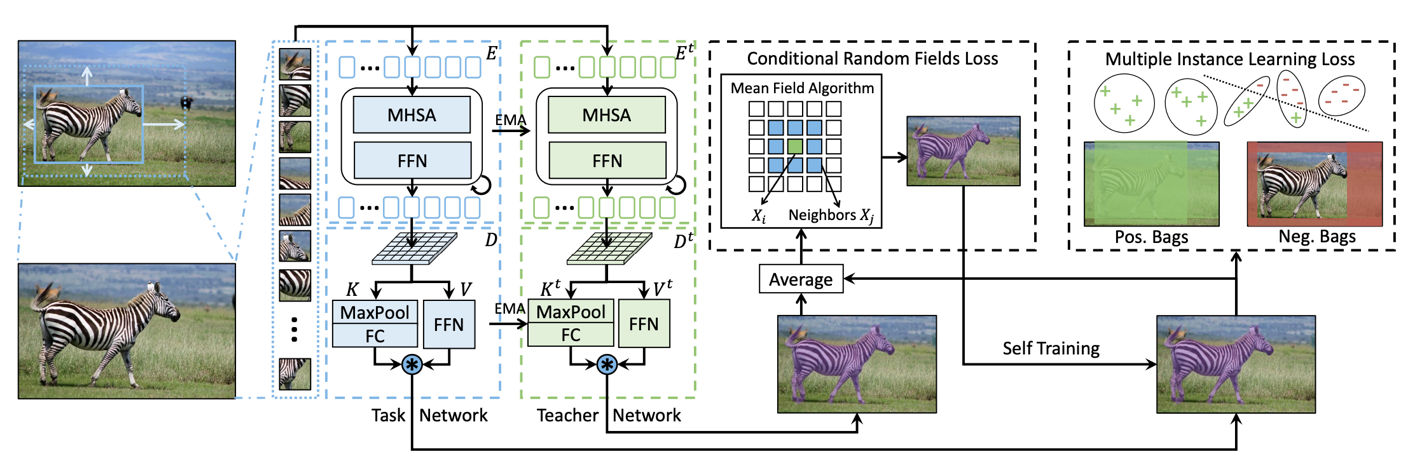
When training the MAL network, a task network and a teacher network (sharing the same transformer structure) work together to achieve class-agnostic self-training. This enables refining the prediction masks with conditional random field (CRF) loss and multi-instance learning (MIL) loss.
TAO Toolkit uses MAL in both the auto-labeling pipeline and data augmentation pipeline. Specifically, users can generate pseudo-masks on the spatially augmented images (sheared or rotated, for example), and refine and tighten the corresponding bounding boxes using the generated masks.
State-of-the-art Vision Transformers
Transformers have become the standard architecture in NLP, largely because of self-attention. They have also gained popularity for a range of vision AI tasks. In general, transformer-based models can outperform traditional CNN-based models due to their robustness, generalizability, and ability to perform parallelized processing of large-scale inputs. All of this increases training efficiency, provides better robustness against image corruption and noise, and generalizes better on unseen objects.
TAO Toolkit 5.0 features several state-of-the-art (SOTA) Vision Transformers for popular CV tasks, as detailed below.
Fully Attentional Network
Fully Attentional Network (FAN) is a transformer-based family of backbones from NVIDIA Research that achieves SOTA in robustness against various corruptions. This family of backbones can easily generalize to new domains and be more robust to noise, blur, and more.
A key design behind the FAN block is the attentional channel processing module that leads to robust representation learning. FAN can be used for image classification tasks as well as downstream tasks such as object detection and segmentation.

The FAN family supports four backbones, as shown in Table 2.
| Model | # of parameters/FLOPs | Accuracy |
| FAN-Tiny | 7 M/3.5 G | 71.7 |
| FAN-Small | 26 M/6.7 | 77.5 |
| FAN-Base | 50 M/11.3 G | 79.1 |
| FAN-Large | 77 M/16.9 G | 81.0 |
Global Context Vision Transformer
Global Context Vision Transformer (GC-ViT) is a novel architecture from NVIDIA Research that achieves very high accuracy and compute efficiency. GC-ViT addresses the lack of inductive bias in Vision Transformers. It achieves better results on ImageNet with a smaller number of parameters through the use of local self-attention.
Local self-attention paired with global context self-attention can effectively and efficiently model both long and short-range spatial interactions. Figure 6 shows the GC-ViT model architecture. For more details, see Global Context Vision Transformers.

As shown in Table 3, the GC-ViT family contains six backbones, ranging from GC-ViT-xxTiny (compute efficient) to GC-ViT-Large (very accurate). GC-ViT-Large models can achieve Top-1 accuracy of 85.6 on the ImageNet-1K dataset for image classification tasks. This architecture can also be used as the backbone for other CV tasks like object detection and semantic and instance segmentation.
| Model | # of parameters/FLOPs | Accuracy |
| GC-ViT-xxTiny | 12 M/2.1 G | 79.6 |
| GC-ViT-xTiny | 20 M/2.6 G | 81.9 |
| GC-ViT-Tiny | 28 M/4.7 G | 83.2 |
| GC-ViT-Small | 51 M/8.5 G | 83.9 |
| GC-ViT-Base | 90 M/14.8 G | 84.4 |
| GC-ViT-Large | 201 M/32.6 G | 85.6 |
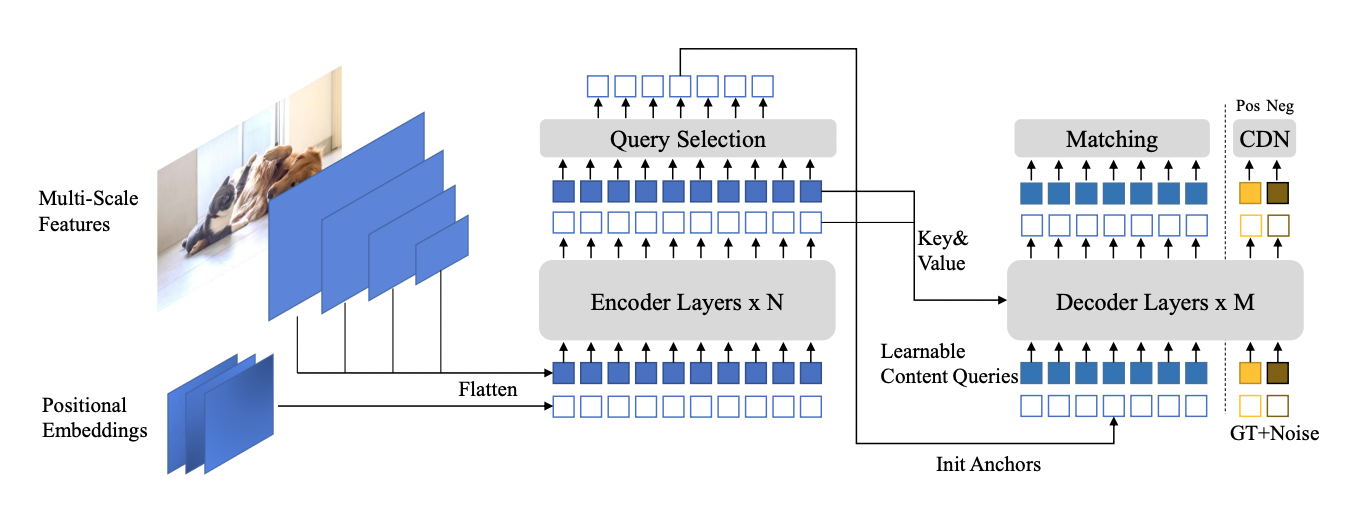
DINO
DINO (detection transformer with improved denoising anchor) is the newest generation of detection transformers (DETR). It achieves a faster training convergence time than its predecessor. Deformable-DETR (D-DETR) requires at least 50 epochs to converge, while DINO can converge in 12 epochs on the COCO dataset. It also achieves higher accuracy when compared with D-DETR.
DINO achieves faster convergence through the use of denoising during training, which helps the bipartite matching process at the proposal generation stage. The training convergence of DETR-like models is slow due to the instability of bipartite matching. Bipartite matching removed the need for handcrafted and compute-heavy NMS operations. However, it often required much more training because incorrect ground truths were matched to the predictions during bipartite matching.
To remedy such a problem, DINO introduced noised positive ground-truth boxes and negative ground-truth boxes to handle “no object” scenarios. As a result, training converges very quickly for DINO. For more information, see DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection.
DINO in TAO Toolkit is flexible and can be combined with various backbones from traditional CNNs, such as ResNets, and transformer-based backbones like FAN and GC-ViT. Table 4 shows the accuracy of the COCO dataset on various versions of DINO with popular YOLOv7. For more details, see YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors.
| Model | Backbone | AP | AP50 | AP75 | APS | APM | APL | Param |
| YOLOv7 | N/A | 51.2 | 69.7 | 55.5 | 35.2 | 56.0 | 66.7 | 36.9M |
| DINO | ResNet50 | 48.8 | 66.9 | 53.4 | 31.8 | 51.8 | 63.4 | 46.7M |
| FAN-Small | 53.1 | 71.6 | 57.8 | 35.2 | 56.4 | 68.9 | 48.3M | |
| GCViT-Tiny | 50.7 | 68.9 | 55.3 | 33.2 | 54.1 | 65.8 | 46.9M |
SegFormer
SegFormer is a lightweight transformer-based semantic segmentation. The decoder is made of lightweight MLP layers. It avoids using positional encoding (mostly used by transformers), which makes the inference efficient at different resolutions.
Adding FAN backbone to SegFormer MLP decoder results in a highly robust and efficient semantic segmentation model. FAN base hybrid + SegFormer was the winning architecture at the Robust Vision Challenge 2022 for semantic segmentation.

| Model | Dataset | Mean IOU (%) | Retention rate (robustness) (%) |
| PSPNet | Cityscapes Validation | 78.8 | 43.8 |
| SegFormer – FAN-S-Hybrid | Cityscapes validation | 81.5 | 81.5 |
See how SegFormer generates robust semantic segmentation while maintaining high efficiency for accelerated autonomous vehicle development in the following video.
CV tasks beyond object detection and segmentation
NVIDIA TAO Toolkit accelerates a wide range of CV tasks beyond traditional object detection and segmentation. The new character detection and recognition models in TAO Toolkit 5.0 enable developers to extract text from images and documents. This automates document conversion and accelerates use cases in industries like insurance and finance.
Detecting anomalies in images is useful when the object being classified varies greatly, such that training with all the variations is impossible. In industrial inspection, for example, a defect can come in any form. Using a simple classifier could result in many missed defects if the defect has not been previously seen by the training data.
For such use cases, comparing the test object directly against a golden reference would result in better accuracy. TAO Toolkit 5.0 features a Siamese neural network in which the model calculates the difference between the object under test and a golden reference to classify if the object is defective.
Automate training using AutoML for hyperparameter optimization
Automated machine learning (autoML) automates the manual task of finding the best models and hyperparameters for the desired KPI on a given dataset. It can algorithmically derive the best model and abstract away much of the complexity of AI model creation and optimization.
AutoML in TAO Toolkit is fully configurable for automatically optimizing the hyperparameters of a model. It caters to both AI experts and nonexperts. For nonexperts, the guided Jupyter Notebook provides a simple, efficient way to create an accurate AI model.
For experts, TAO Toolkit gives you full control of which hyperparameters to tune and which algorithm to use for sweeps. TAO Toolkit currently supports two optimization algorithms: Bayesian and Hyperband optimization. These algorithms can sweep across a range of hyperparameters to find the best combination for a given dataset.
AutoML is supported for a wide range of CV tasks, including several new Vision Transformers such as DINO, D-DETR, SegFormer, and more. Table 6 shows the full list of supported networks (bold items are new to TAO Toolkit 5.0).
| Image classification | Object detection | Segmentation | Other |
| FAN | DINO | SegFormer | LPRNet |
| GC-ViT | D-DETR | UNET | |
| ResNet | YoloV3/V4/V4-Tiny | MaskRCNN | |
| EfficientNet | EfficientDet | ||
| DarkNet | RetinaNet | ||
| MobileNet | FasterRCNN | ||
| DetectNet_v2 | |||
| SSD/DSSD |
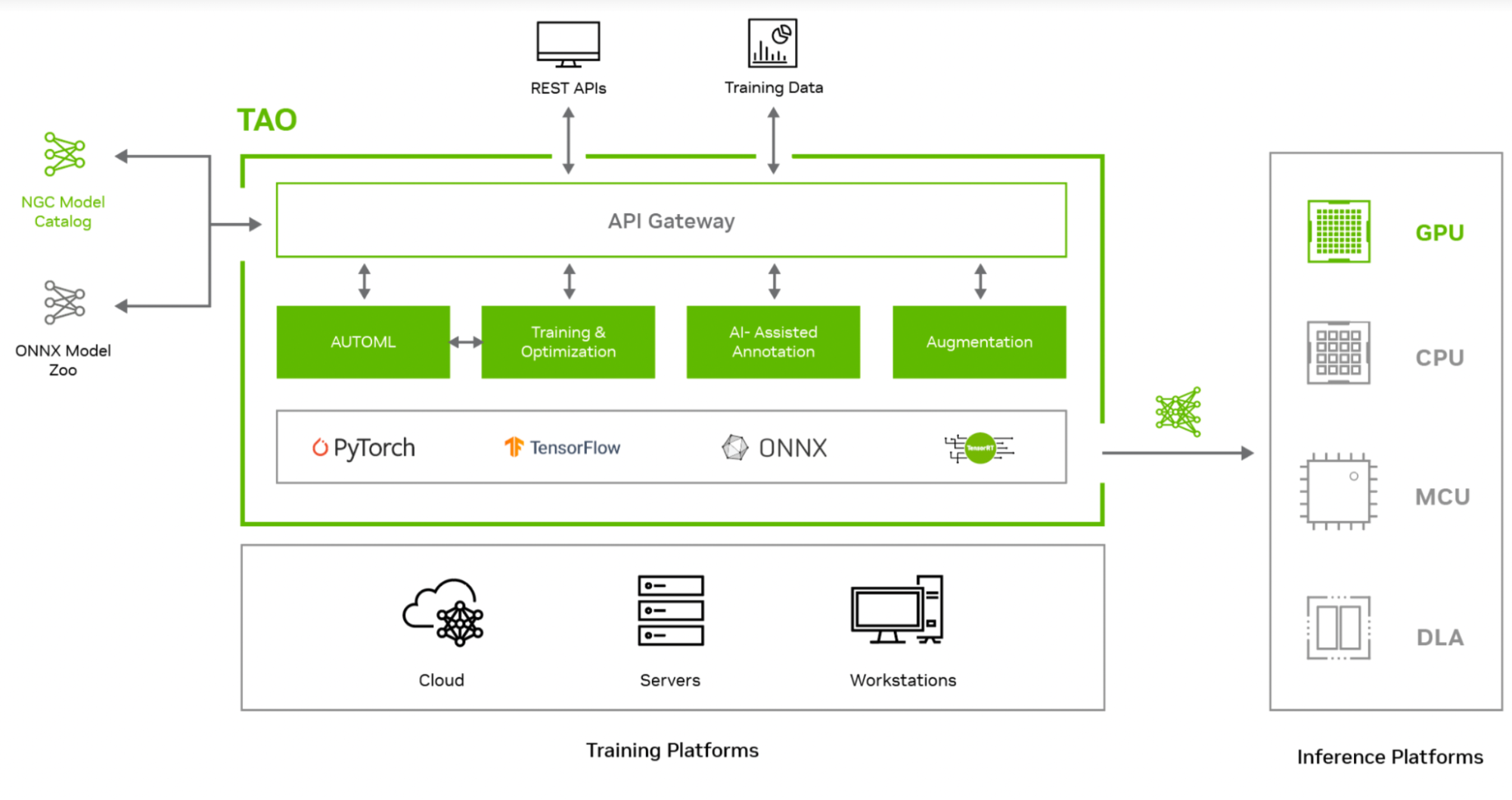
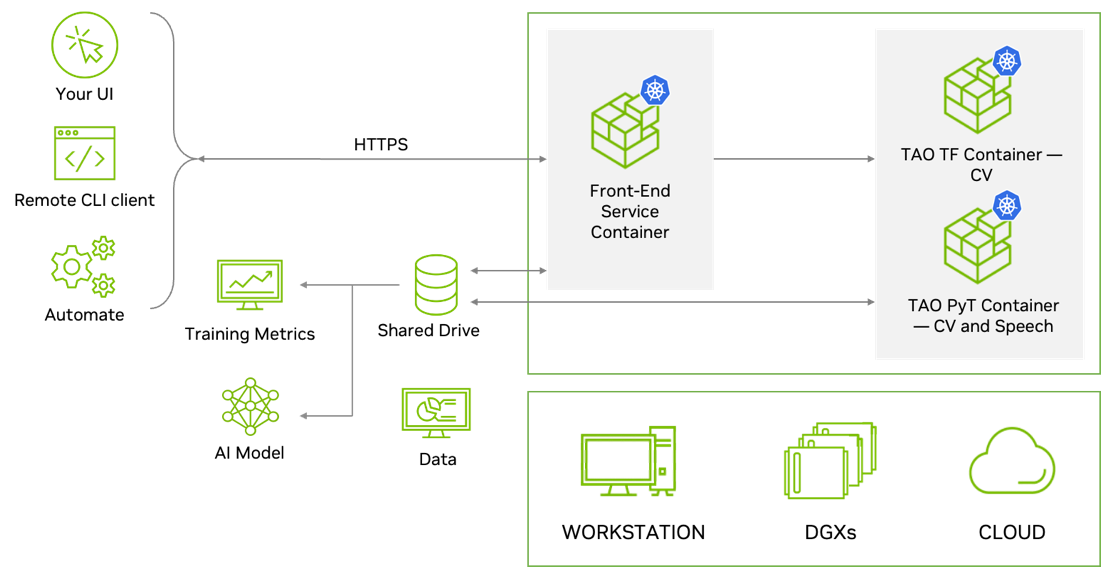
REST APIs for workflow integration
TAO Toolkit is modular and cloud-native, meaning it is available as containers and can be deployed and managed using Kubernetes. TAO Toolkit can be deployed as a self-managed service on any public or private cloud, DGX, or workstation. TAO Toolkit provides well-defined REST APIs, making it easy to integrate into your development workflow. Developers can call the API endpoints for all training and optimization tasks. These API endpoints can be called from any application or user interface, which can trigger training jobs remotely.
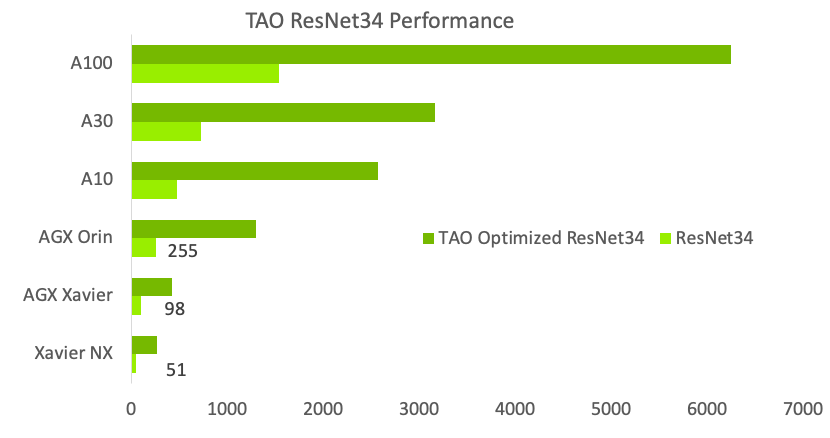
Better inference optimization
To simplify productization and increase inference throughput, TAO Toolkit provides several turnkey performance optimization techniques. These include model pruning, lower precision quantization, and TensorRT optimization, which can combine to deliver a 4x to 8x performance boost, compared to a comparable model from public model zoos.
Open and flexible, with better support
An AI model predicts output based on complex algorithms. This can make it difficult to understand how the system arrived at its decision and challenging to debug, diagnose, and fix errors. Explainable AI (XAI) aims to address these challenges by providing insights into how AI models arrive at their decisions. This helps humans understand the reasoning behind the AI output and makes it easier to diagnose and fix errors. This transparency can help to build trust in AI systems.
To help with transparency and explainability, TAO Toolkit will now be available as source-open. Developers will be able to view feature maps from internal layers, as well as plot activation heat maps to better understand the reasoning behind AI predictions. In addition, having access to the source code will give developers the flexibility to create customized AI, improve debug capability, and increase trust in their models.
NVIDIA TAO Toolkit is enterprise-ready and available through NVIDIA AI Enterprise (NVAIE). NVAIE provides companies with business-critical support, access to NVIDIA AI experts, and priority security fixes. Join NVAIE to get support from AI experts.
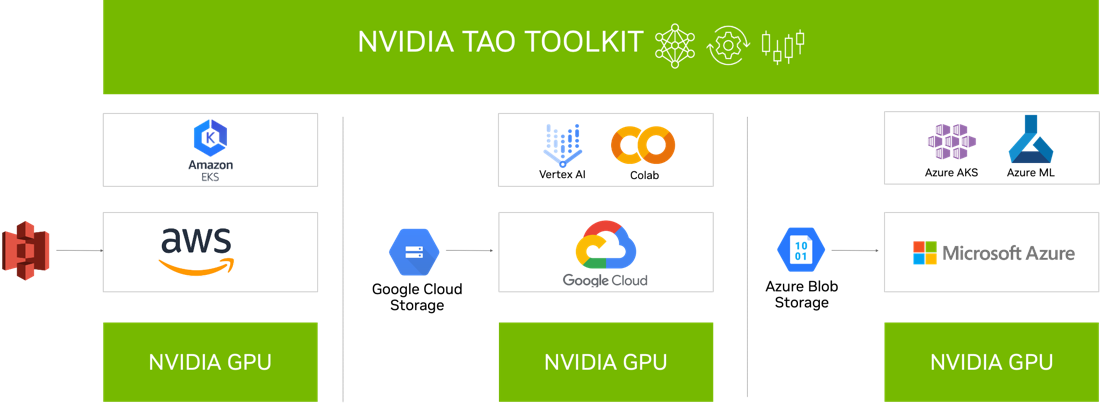
Integration with cloud services
NVIDIA TAO Toolkit 5.0 is integrated into various AI services that you might already use, such as Google Vertex AI, AzureML, Azure Kubernetes service, Google GKE, and Amazon EKS.
Summary
TAO Toolkit offers a platform for any developer, in any service, and on any device to easily transfer-learn their custom models, perform quantization and pruning, manage complex training workflows, and perform AI-assisted annotation with no coding requirements.