
 Smart cities are the future of urban living. Yet they can present various challenges for city planners, most notably in the realm of transportation. To be…
Smart cities are the future of urban living. Yet they can present various challenges for city planners, most notably in the realm of transportation. To be…
Smart cities are the future of urban living. Yet they can present various challenges for city planners, most notably in the realm of transportation. To be successful, various aspects of the city—from environment and infrastructure to business and education—must be functionally integrated.
This can be difficult, as managing traffic flow alone is a complex problem full of challenges such as congestion, emergency response to accidents, and emissions.
To address these challenges, developers are creating AI software with field programmability and flexibility. These software-defined IoT solutions can provide scalable, ready-to-deploy products for real-time environments like traffic management, number plate recognition, smart parking, and accident detection.
Still, building effective AI models is easier said than done. Omitted values, duplicate examples, bad labels, and bad feature values are common problems with training data that can lead to inaccurate models. The results of inaccuracy can be dangerous in the case of self-driving cars, and can also lead to inefficient transportation systems or poor urban planning.
Digital twins of real-time city traffic
End-to-end AI engineering company SmartCow, an NVIDIA Metropolis partner, has created digital twins of traffic scenarios on NVIDIA Omniverse. These digital twins generate synthetic data sets and validate AI model performance.
The team resolved common challenges due to a lack of adequate data for building optimized AI training pipelines by generating synthetic data with NVIDIA Omniverse Replicator.
The foundation for all Omniverse Extensions is Universal Scene Description, known as OpenUSD. USD is a powerful interchange with highly extensible properties on which virtual worlds are built. Digital twins for smart cities rely on highly scalable and interoperable USD features for large, high-fidelity scenes that accurately simulate the real world.
Omniverse Replicator, a core extension of the Omniverse platform, enables developers to programmatically generate annotated synthetic data to bootstrap the training of perception of AI models. Synthetic data is particularly useful when real data sets are limited or hard to obtain.
By using a digital twin, the SmartCow team generated synthetic data that accurately represents real-world traffic scenarios and violations. These synthetic datasets help validate AI models and optimize AI training pipelines.
Building the license plate detection extension
One of the most significant challenges for intelligent traffic management systems is license plate recognition. Developing a model that will work in a variety of countries and municipalities with different rules, regulations, and environments requires diverse and robust training data. To provide adequate and diverse training data for the model, SmartCow developed an extension in Omniverse to generate synthetic data.
Extensions in Omniverse are reusable components or tools that deliver powerful functionalities to augment pipelines and workflows. After building an extension in Omniverse Kit, developers can easily distribute it to customers to use in Omniverse USD Composer, Omniverse USD Presenter, and other apps.
SmartCow’s extension, which is called License Plate Synthetic Generator (LP-SDG), uses an environmental randomizer and a physics randomizer to make synthetic datasets more diverse and realistic.
The environmental randomizer simulates variations in lighting, weather, and other factors in the digital twin environment such as rain, snow, fog, or dust. The physics randomizer simulates scratches, dirt, dents, and discoloration that could affect the ability of the model to recognize the number on the license plate.
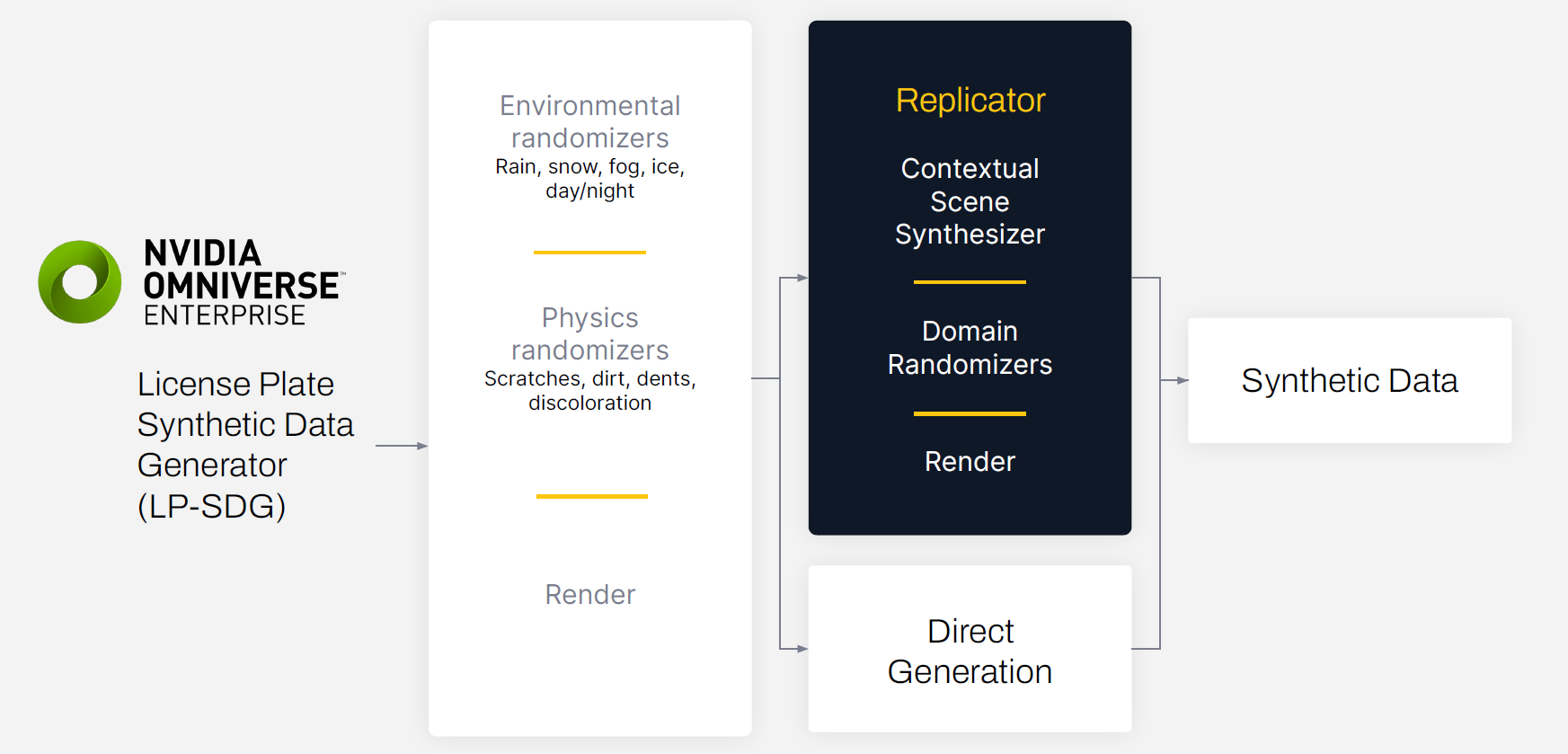
Synthetic data generation with NVIDIA Omniverse Replicator
The data generation process starts with creating a 3D environment in Omniverse. The digital twin in Omniverse can be used for many simulation scenarios, including generating synthetic data. The initial 3D scene was built by SmartCow’s in-house technical artists, ensuring that the digital twin matched reality as best as possible.

Once the scene was generated, domain randomization was used to vary the light sources, textures, camera positions, and materials. This entire process was accomplished programmatically using the built-in Omniverse Replicator APIs.
The generated data was exported with bounding box annotations and additional output variables needed for training.
Model training
The initial model was trained on 3,000 real images. The goal was to understand the baseline model performance and validate aspects such as correct bounding box dimensions and light variation.
Next, the team staged experiments to compare benchmarks on synthetically generated datasets of 3,000 samples, 30,000 samples, and 300,000 samples.

“With the realism obtained through Omniverse, the model trained on synthetic data occasionally outperformed the model trained on real data,” said Natalia Mallia, software engineer at SmartCow. “Using synthetic data actually removes the bias, which is naturally present in the real image training dataset.”
To provide accurate benchmarking and comparisons, the team randomized the data across consistent parameters such as time of day, scratches, and viewing angle when training on the three sizes of synthetically generated data sets. Real-world data was not mixed with synthetic data for training, to preserve comparative accuracy. Each model was validated against a dataset of approximately 1,000 real images.
SmartCow’s team integrated the training data from the Omniverse LP-SDG extension with NVIDIA TAO, a low-code AI model training toolkit that leverages the power of transfer learning for fine-tuning models.
The team used the pretrained license plate detection model available in the NGC catalog and fine-tuned it using TAO and NVIDIA DGX A100 systems.
Model deployment with NVIDIA DeepStream
The AI models were then deployed onto custom edge devices using NVIDIA DeepStream SDK.
They then implemented a continuous learning loop that involved collecting drift data from edge devices, feeding the data back into Omniverse Replicator, and synthesizing retrainable datasets that were passed through automated labeling tools and fed back into TAO for training.
This closed-loop pipeline helped to create accurate and effective AI models for automatically detecting the direction of traffic in each lane and any vehicles that are stalled for an unusual amount of time.
Getting started with synthetic data, digital twins, and AI-enabled smart city traffic management
Digital twin workflows for generating synthetic data sets and validating AI model performance are a significant step towards building more effective AI models for transportation in smart cities. Using synthetic datasets helps overcome the challenge of limited data sets, and provides accurate and effective AI models that can lead to efficient transportation systems and better urban planning.
If you’re looking to implement this solution directly, check out the SmartCow RoadMaster and SmartCow PlateReader solutions.
If you’re a developer interested in building your own synthetic data generation solution, download NVIDIA Omniverse for free and try the Replicator API in Omniverse Code. Join the conversation in the NVIDIA Developer Forums.
Join NVIDIA at SIGGRAPH 2023 to learn about the latest breakthroughs in graphics, OpenUSD, and AI. Save the date for the session, Accelerating Self-Driving Car and Robotics Development with Universal Scene Description.
Get started with NVIDIA Omniverse by downloading the standard license free, or learn how Omniverse Enterprise can connect your team. If you’re a developer, get started with Omniverse resources. Stay up to date on the platform by subscribing to the newsletter, Twitch, and YouTube channels.