

|
I am training a model using tf.Keras. The code is the following.
class CustomCallback(tf.keras.callbacks.Callback): def __init__(self, val_dataset, **kwargs): self.val_dataset = val_dataset super().__init__(**kwargs) def on_train_batch_end(self, batch, logs=None): if batch%1000 == 0: val = self.model.evaluate(self.val_dataset, return_dict=True) print("*** Val accuracy: %.2f ***" % (val['sparse_categorical_accuracy'])) super().on_train_batch_end(batch, logs) ## DATASET ## # Create a dictionary describing the features. image_feature_description = { 'train/label' : tf.io.FixedLenFeature((), tf.int64), 'train/image' : tf.io.FixedLenFeature((), tf.string) } def _parse_image_function(example_proto): # Parse the input tf.train.Example proto using the dictionary above. parsed_features = tf.io.parse_single_example(example_proto, image_feature_description) image = tf.image.decode_jpeg(parsed_features['train/image']) image = tf.image.resize(image, [224,224]) # augmentation image = tf.image.random_flip_left_right(image) image = tf.image.random_brightness(image, 0.2) image = tf.image.random_jpeg_quality(image, 50, 95) image = image/255.0 label = tf.cast(parsed_features['train/label'], tf.int32) return image, label def load_dataset(filenames, labeled=True): ignore_order = tf.data.Options() ignore_order.experimental_deterministic = False # disable order, increase speed dataset = tf.data.TFRecordDataset(filenames) # automatically interleaves reads from multiple files dataset = dataset.with_options(ignore_order) # uses data as soon as it streams in, rather than in its original order dataset = dataset.map(partial(_parse_image_function), num_parallel_calls=AUTOTUNE) return dataset def get_datasets(filenames, labeled=True, BATCH=64): dataset = load_dataset(filenames, labeled=labeled) train_dataset = dataset.skip(2000) val_dataset = dataset.take(2000) train_dataset = train_dataset.shuffle(4096) train_dataset = train_dataset.prefetch(buffer_size=AUTOTUNE) train_dataset = train_dataset.batch(BATCH) val_dataset = val_dataset.batch(BATCH) return train_dataset, val_dataset train_dataset, val_dataset = get_datasets('data/train_224.tfrecords', BATCH=64) ## CALLBACKS ## log_path = './logs/' + datetime.datetime.now().strftime("%Y%m%d-%H%M%S") checkpoint_path = './checkpoints/' + datetime.datetime.now().strftime("%Y%m%d-%H%M%S") tb_callback = tf.keras.callbacks.TensorBoard( log_path, update_freq=100, profile_batch=0) model_checkpoint_callback = tf.keras.callbacks.ModelCheckpoint( filepath=checkpoint_path+'/weights.{epoch:02d}-{accuracy:.2f}.hdf5', save_weights_only=False, save_freq=200) custom_callback = CustomCallback(val_dataset=val_dataset) ## MODEL ## lr_schedule = tf.keras.optimizers.schedules.ExponentialDecay( 0.005, decay_steps=300, decay_rate=0.98, staircase=True ) model = tf.keras.applications.MobileNetV2( include_top=True, weights=None, classes=2, alpha=0.25) model.compile( optimizer=tf.keras.optimizers.RMSprop(learning_rate=lr_schedule), loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False), metrics=['accuracy', 'sparse_categorical_accuracy']) model.fit(train_dataset, epochs=NUM_EPOCHS, shuffle=True, validation_data=val_dataset, validation_steps=None, callbacks=[model_checkpoint_callback, tb_callback, custom_callback]) model.save('model.hdf5')
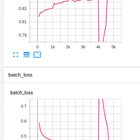
At the end of each epoch I can see a spike in the batch accuracy and loss, as you can see in the figure below. After the spike, the metrics gradually return to previous values and keep improving. What could be the reason for this strange behaviour? submitted by /u/fralbalbero |
Categories
Large spikes after each epoch using tf.Keras API
{kind=link}