
 Model developers no longer face a steep learning curve to accelerate model training. By utilizing two open-source software projects, Determined AI’s Deep Learning Training Platform and the RAPIDS accelerated data science toolkit, they can easily achieve up to 10x speedups in data preprocessing and train models at scale. Making GPUs accessible As the field of … Continued
Model developers no longer face a steep learning curve to accelerate model training. By utilizing two open-source software projects, Determined AI’s Deep Learning Training Platform and the RAPIDS accelerated data science toolkit, they can easily achieve up to 10x speedups in data preprocessing and train models at scale. Making GPUs accessible As the field of … Continued
Model developers no longer face a steep learning curve to accelerate model training. By utilizing two open-source software projects, Determined AI’s Deep Learning Training Platform and the RAPIDS accelerated data science toolkit, they can easily achieve up to 10x speedups in data preprocessing and train models at scale.
Making GPUs accessible
As the field of deep learning advances, practitioners are increasingly expected to make a significant investment in GPUs, either on-prem or from the cloud. Hardware is only half the story behind the proliferation of AI, though. NVIDIA’s success in powering data science has as much to do with software as hardware: widespread GPU adoption would be very difficult without convenient software abstractions that make GPUs easy for model developers to use. RAPIDS is a software suite that bridges the gap from CUDA primitives to data-hungry analytics and machine learning use cases.
Similarly, Determined AI’s deep learning training platform frees the model developer from hassles: operational hassles they are guaranteed to hit in a cluster setting, and model development hassles as they move from toy prototype to scale. On the operational side, the platform handles distributed systems concerns like training job orchestration, storage layer integration, centralized logging, and automatic fault tolerance for long-running jobs. On the model development side, machine learning engineers only need to maintain one version of code from the model prototype phase to more advanced tasks like multi-GPU (and multi-node) distributed training and hyperparameter tuning. Further, the platform handles the boilerplate engineering required to track workload dependencies, metrics, and checkpoints.
At their core, both Determined AI and RAPIDS make the GPU accessible to machine learning engineers via intuitive APIs: Determined as the platform for accelerating and tracking deep learning training workflows, and RAPIDS as the suite of libraries speeding up parts of those training workflows.
For the remainder of this post, we’ll examine a model development process in which RAPIDS accelerates training data set construction within a Determined cluster, at which point Determined handles scaled out, fault-tolerant model training and hyperparameter tuning.
The RAPIDS is not alone in offering familiar interfaces atop GPU acceleration. E.g., CuPy is NumPy-compatible, and OpenCV’s GPU module API interface is “kept similar with the CPU interface where possible.” experience will look familiar to ML engineers who are accustomed to tackling data manipulation with pandas or NumPy, and model training with PyTorch or TensorFlow.
Getting started
To use Determined and RAPIDS to accelerate model training, there are a few requirements to meet upfront. On the RAPIDS side, OS and CUDA version requirements are listed here. One is worth calling out explicitly: RAPIDS requires NVIDIA P100 or later generation GPUs, ruling out the NVIDIA K80 in AWS P2 instances.
After satisfying these prerequisites, making RAPIDS available to tasks running on Determined is simple. Because Determined supports custom Docker images for running training workloads, we can create an image that contains the appropriate version of RAPIDS1 installed via conda. This is as simple as specifying the RAPIDS dependency in a Conda environment file:
name: Rapids
channels:
- rapidsai
- nvidia
- conda-forge
dependencies:
- rapids=0.14And updating the base Conda environment in your custom image Dockerfile:
FROM determinedai/environments:cuda-10.0-pytorch-1.4-tf-1.15-gpu-0.7.0 as base COPY environment.yml /tmp/ RUN conda --version && conda env update --name base --file /tmp/environment.yml && conda clean --all --force-pkgs-dirs --yes RUN eval "$(conda shell.bash hook)" && conda activate base
After building and pushing this image to a Docker repository, you can run experiments, notebooks, or shell sessions by configuring the environment image that these tasks should use.
The model
To showcase the potency of integrating RAPIDS and Determined, we picked a tabular learning task that would typically benefit from nontrivial data preprocessing, based on the TabNet architecture and the pytorch-tabnet library implementing it. TabNet brings the power of deep learning to tabular data-driven use cases and offers some nice interpretability properties to boot. One benchmark explored in the TabNet paper is the Rossman store sales prediction task of building a model to predict revenue across thousands of stores based on tabular data describing the stores, promotions, and nearby competitors. Since Rossman dataset access requires signing off on an agreement, we train our model on generated data of a similar schema and scale so that users can more easily run this example. All assets for this experiment are available on GitHub.
Data prep with RAPIDS, training with Determined
With multiple CSVs to ingest and denormalize, the Rossman revenue prediction task is ripe for RAPIDS. The high level flow to develop a revenue prediction model looks like this:
- Read location and historical sales CSVs into cuDF DataFrames residing in GPU memory.
- Join these data sets into a denormalized DataFrame. This GPU-accelerated join is handled by cuDF.
- Construct a PyTorch Dataset from the denormalized DataFrame.
- Train with Determined!
RAPIDS cuDF’s familiar pandas-esque interface makes data ingest and manipulation a breeze:
df_store = cudf.read_csv(STORE_CSV) df_train = cudf.read_csv(TRAIN_CSV).join(df_store, how='left', on='store_id', rsuffix='store') df_valid = cudf.read_csv(VAL_CSV).join(df_store, how='left', on='store_id', rsuffix='store')
We then use CuPy to get from a cuDF DataFrame to a PyTorch Dataset and DataLoader to expose via Determined’s Trial interface.
Given that RAPIDS cuDF is a drop-in replacement for pandas, it’s trivial to toggle between the two libraries and compare performance of their analogous APIs. In this simplified case, cuDF showed a 10x speedup over pandas, requiring only 6 seconds to complete on a single NVIDIA V100 GPU that took a minute on the vCPU.
Another option is to use DLPack as the intermediate format that both cuDF and PyTorch support, either directly, or using NVTabular’s Torch Dataloader which does the same under the covers.
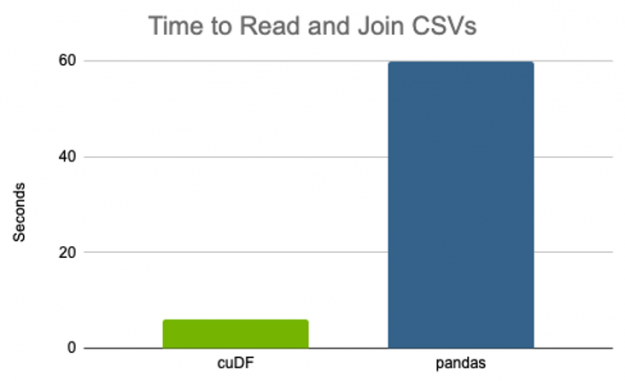
On an absolute scale, this might not seem like a big deal: whether the overall training job takes 20 or 21 minutes doesn’t seem to matter much. However, given the iterative nature of deep learning model tuning, the time and cost savings quickly add up. For a hyperparameter tuning experiment training hundreds or thousands of models, on data larger than the couple of GB, and perhaps with more complex data transformations, savings on the order of GPU-minutes per trained model can translate to savings on the order of GPU-days or weeks at scale, netting your organization hundreds or thousands of dollars in infrastructure cost.
Determined and the broader RAPIDS toolkit
The RAPIDS library suite goes far beyond manipulation of data frames that we leveraged in this example. To name a couple:
- RAPIDS cuML offers GPU-accelerated ML algorithms mirroring sklearn.
- NVTabular, which sits atop RAPIDS, offers high-level abstractions for feature engineering and building recommenders.
If you’re using these libraries, you’ll soon be able to train on a Determined cluster and get the platform’s resource management, experiment tracking, and hyperparameter tuning capabilities. We’ve heard from our users that the need for these tools isn’t limited to deep learning, so we are pushing into the broader ML space and making Determined not only the platform for PyTorch and TensorFlow model development, but for any Python-based model development. Stay tuned, and in the meantime you can learn more about this development from our 2021 roadmap discussion during our most recent community meetup.
Get started
If you’d like to learn more about (and test drive!) RAPIDS and Determined, check out the RAPIDS quick start and Determined’s quick start documentation. We’d love to hear your feedback on the RAPIDS and Determined community Slack channels. Happy training!