Posted by Cat Armato, Program Manager, Google 
This week marks the beginning of the 36th annual Conference on Neural Information Processing Systems (NeurIPS 2022), the biggest machine learning conference of the year, which is being held in New Orleans, LA. NeurIPS 2022 will be held in person with additional options for virtual attendees, and includes invited talks, demonstrations and presentations of some of the latest in machine learning research. This year, NeurIPS is also offering a new track, called Spotlight Papers, which will provide opportunities to highlight papers presented in prestigious journals that would otherwise not have been eligible for submission.
Google is proud to be a Diamond level sponsor of NeurIPS this year and will have a significant presence year with more than 175 accepted papers, additionally contributing to and learning from the broader academic research community through numerous talks, posters, workshops, and tutorials. You can learn more about our work being presented in the list below (Google affiliations highlighted in bold).
Organizing Committee
General Chairs includes: Sanmi Koyejo
Program Chairs include: Alekh Agarwal
Workshop Chairs include: Hanie Sedghi
Tutorial Chairs include: Adji Bousso Dieng, Jessica Schrouff
Affinity Workshop Chair: Adji Bousso Dieng, Jessica Schrouff
Program Committee, Senior Area Chairs include: Corinna Cortes, Claudio Gentile, Mohammad Ghavamzadeh, Amir Globerson, Elad Hazan, Katherine Heller, Satyen Kale, Been Kim, Sanjiv Kumar, Hugo Larochelle, Sergey Levine, Yishay Mansour, Mehryar Mohri, Tara Sainath, Dale Schuurmans, Daniel Tarlow
NeurIPS Foundation Board Secretary: Michael Mozer
NeurIPS Foundation Board Members include: Corinna Cortes, Isabelle Guyon, Sanmi Koyejo, Hugo Larochelle
NeurIPS Foundation Advisory Board include: Peter Bartlett, Zoubin Ghahramani, John C. Platt, Fernando Pereira, Dale Schuurmans
Keynote Speakers
The Data-Centric Era: How ML is Becoming an Experimental Science
Isabelle Guyon
The Forward-Forward Algorithm for Training Deep Neural Networks
Geoffrey Hinton
Outstanding Paper Award
Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily Denton, Seyed Kamyar Seyed Ghasemipour, Burcu Karagol Ayan, S. Sara Mahdavi, Rapha Gontijo Lopes, Tim Salimans, Jonathan Ho, David J Fleet, Mohammad Norouzi
EXPO Day Workshops
Graph Neural Networks in Tensorflow: A Practical Guide
Workshop Organizers include: Bryan Perozzi, Sami Abu-el-Haija
A Hands-On Introduction to Tensorflow and Jax
Workshop Organizers include: Josh Gordon
Affinity Workshops
LatinX in AI (LXAI)
Platinum Sponsor
Networking & Social Chairs include: Andres Muñoz Medina
Program Committee includes: Johan Obando Ceron
Queer in AI
Panelists include: Sara Beery, Talia Ringer
Women in Machine Learning (WiML)
Platinum Sponsor
Workshop Organizers and Mentorship Chairs include: Beliz Gunel
Mentors include: Adam Roberts, Eleni Triantafillou, Zelda Mariet, Clara Hu, Rosanne Liu, Alekh Agarwal, Vinod Prabhakaran, Rose Yu, Katherine Heller
Workshops
New in ML
Workshop Organizers include: Isabelle Guyon
AI for Accelerated Materials Design (AI4Mat)
Workshop Organizers include: Benjamin Sanchez-Lengeling
All Things Attention: Bridging Different Perspectives on Attention
Invited Speakers and Panelists include: Vidhya Navalpakkam
Efficient Natural Language and Speech Processing (ENLSP-II): The Future of Pre-trained Models
Invited Speakers include: Tara Sainath, Anna Huang
Invited Panelists include: Mohammad Norouzi
Program Committee includes: Wenhu Chen
Federated Learning: Recent Advances and New Challenges
Program Committee includes: Kallista Bonawitz, Zachary Charles, Wenshuo Guo, Peter Kairouz, Zhaozhuo Xu, Zheng Xu
Gaussian Processes, Spatiotemporal Modeling, and Decision-Making Systems
Workshop Organizers include: Zi Wang
Invited Speakers include: Jasper Snoek, Carolina Osorio
Advisory Board includes: Zoubin Ghahramani
Has it Trained Yet? A Workshop for Algorithmic Efficiency in Practical Neural Network Training
Workshop Organizers include: Zachary Nado, George Dahl, Naman Agarwal, Aakanksha Chowdhery
Invited Speakers include: Aakanksha Chowdhery, Priya Goyal
Human in the Loop Learning (HiLL)
Workshop Organizers include: Fisher Yu, Vittorio Ferrari
Invited Speakers include: Dorsa Singh, Igor Mordatch, Ding Zhao
INTERPOLATE — First Workshop on Interpolation Regularizers and Beyond
Workshop Organizers include: Yann Dauphin
Invited Speakers include: Chelsea Finn
Panelists include: Chelsea Finn, Dustin Tran
Program Committee includes: Wang Chen, Kimin Lee
LaReL: Language and Reinforcement Learning
Invited Speakers include: Dorsa Singh, Igor Mordatch
Medical Imaging Meets NeurIPS
Program Committee includes: Chenyu You
Memory in Artificial and Real Intelligence (MemARI)
Program Committee includes: Benjamin Eysenbach, Otilia Stretcu
Meta-Learning
Workshop Organizers include: Eleni Triantafillou
Invited Speakers include: Lucas Byer, Chelsea Finn
Program Committee includes: Ishita Dasgupta, Praneet Dutta, Benjamin Eysenbach, Maximilian Igl, Louis Kirsch, Parsa Mahmoudieh, Marc Pickett, Eleni Triantafillou
New Frontiers in Graph Learning (GLFrontiers)
Workshop Organizers include: Hanjun Dai
Offline Reinforcement Learning Workshop: Offline RL as a “Launchpad”
Workshop Organizers include: Rishabh Agarwal, Aviral Kumar, George Tucker
Invited Speakers include: Dorsa Sadigh
Score-Based Methods
Invited Speakers include: Mohammad Norouzi
Invited Panelists include: Jascha Sohl-Dickstein
Synthetic Data for Empowering ML Research
Invited Speakers include: Mehryar Mohri
Invited Panelists include: Katrina Ligett
Program Committee includes: Jinsung Yoon
Table Representation Learning
Workshop Organizers include: Pengcheng Yin
Invited Speakers include: Xinyun Chen, Carsten Binnig
Panelists include: Julian Eisenschlos
Program Committee includes: Wenhu Chen, Xinyun Chen, Beliz Gunel
A Causal View on Dynamical Systems
Program Committee includes: Rose Yu
Algorithmic Fairness Through the Lens of Causality and Privacy
Workshop Organizers include: Awa Dieng
Invited Speakers include: Nicolas Papernot
Roundtable Leads include: David Madras, Negar Rostamzadeh, Nyalleng Moroosi
Program Committee includes: Matt Kusner
Broadening Research Collaborations in ML
Workshop Organizers include: Rosanne Liu, Pablo Samuel Castro, Sunipa Dev
Decentralization and Trustworthy Machine Learning in Web3: Methodologies, Platforms, and Applications
Invited Speakers include: Peter Kairouz
Distribution Shifts (DistShift): Connecting Methods and Applications
Workshop Organizers include: Becca Roelofs, Chelsea Finn, Jacob Eisenstein, Pang Wei Koh
Invited Speakers include: Sarah Beery
Foundation Models for Decision Making
Workshop Organizers include: Sherry Yang, Yilun Du, Igor Mordatch, Shixiang Shane Gu,Ofir Nachum
Invited Speakers include: Dorsa Sadigh, Dale Schuurmans, Machel Reid
Program Committee includes: Bo Dai, Aleksandra Faust, Hiroki Furuta, Kati Goshvadi, Izzeddin Gur, Austin Huang, Kimin Lee, Kuang-Huei Lee, Lisa Lee, Yingjie Miao, Jordi Orbay, Ted Xiao
Gaze Meets ML
Program Committee includes: Peter Mattson, Mehdi Moradi
I Can’t Believe It’s Not Better: Understanding Deep Learning Through Empirical Falsification
Workshop Organizers include: Javier Antorán
Panelists include: Kevin Murphy
Interactive Learning for Natural Language Processing
Invited Speakers include: Anca Dragan
Program Committees include: Julia Kreutzer, Shunyu Yao
Machine Learning and the Physical Sciences
Workshop Organizers include: Adji Bousso Dieng
Invited Speakers include: Ekin Doğuş Çubuk
Machine Learning for Systems
Workshop Organizers include: Martin Maas, Azade Nova, Dan Zhang
Invited Speakers include: Jeff Dean
Program Committee includes: Milad Hashemi, Kevin Swersky
Machine Learning in Structural Biology
Invited Speakers include: David Fleet
MATH-AI: Toward Human-Level Mathematical Reasoning
Workshop Organizers include: Swaroop Mishra, Yuhuai Wu
Invited Speakers include: Talia Ringer
OPT 2022: Optimization for Machine Learning
Workshop Organizers include: Courtney Paquette
Reinforcement Learning for Real Life (RL4RealLife)
Workshop Organizers include: Minmin Chen
Invited Panelists include: Pablo Samuel Castro
Program Committee includes: Victor Carbune, Bo Chang, Yinlam Chow, Konstantina Christakopoulou, Bo Dai, Hanjun Dai, Aleksandra Faust, Joshua Greaves, Chih-wei Hsu, Rahul Kidambi, Srivatsan Krishnan, Iou-Jen Liu, Cong Lu, Jincheng Mei, Chao Qin
Self-Supervised Learning – Theory and Practice
Invited Speakers include: Mathilde Caron
Symmetry and Geometry in Neural Representations (NeurReps)
Invited Speakers include: Noah Shutty
Program Committee includes: Ondrej Biza, Noah Shutty
Temporal Graph Learning Workshop
Invited Speakers include: Mehran Kazemi
Transfer Learning for Natural Language Processing
Workshop Organizers include: Deepak Ramachandran, Sebastian Ruder
Invited Speakers include: Jonas Pfeiffer
Invited Debaters include: Ellie Pavlick
Program Committee includes: Patrick Fernandes, Jonas Pfeiffer, Jiao Sun, Tu Vu, Xinyi Wang, Xin Xu
Cultures of AI and AI for Culture
Workshop Organizers include: Rida Qadri, Fernando Diaz
Deep Reinforcement Learning Workshop
Workshop Organizers include: Karol Hausman, Ted Xiao, Zeyu Zheng
Invited Speakers include: Igor Mordatch
Advisory Board includes: Chelsea Finn
Empowering Communities: A Participatory Approach to AI for Mental Health
Program Committee includes: Diana Mincu, Subhrajit Roy, Martin Seneviratne
HCAI@NeurIPS 2022, Human Centered AI
Keynote Speaker includes: Fernanda Viegas
Learning Meaningful Representations of Life
Workshop Organizers include: Adji Bousso Dieng
Machine Learning for Creativity and Design
Workshop Organizers include: Yingtao Tian
Machine Learning Safety
Workshop Organizers include: Nicholas Carlini
Invited Speakers include: Dorsa Sadigh
Neuro Causal and Symbolic AI (nCSI)
Workshop Organizers include: Thomas Kipf
Robot Learning Workshop: Trustworthy Robotics
Workshop Organizers include: Alex Bewley, Jonathan Tompson
Invited Speakers include: Karol Hausman, Brian Ichter, Been Kim, Leila Takayama, Andy Zeng
Program Committee includes: Vincent Vanhoucke
The Symbiosis of Deep Learning and Differential Equations II
Workshop Organizers include: Winnie Xu
Invited Speakers include: Rose Yu
Tackling Climate Change with Machine Learning
Workshop Organizers include: Emma Strubell
Trustworthy and Socially Responsible Machine Learning
Invited Speakers include: Been Kim, Dorsa Sadigh, Milind Tambe
Vision Transformers: Theory and Applications
Invited Speakers include: Cordelia Schmid, Ming Hsuan Yang
Tutorials
Advances in Bayesian Optimization
Tutorial Organizers include: Virginia Aglietti
Creative Culture and Machine Learning
Tutorial Organizers include: Negar Rostamzadeh
Fair and Socially Responsible ML for Recommendations: Challenges and Perspectives
Invited Panelists include: Fernando Diaz
Lifelong Learning Machines
Invited Panelists include: Christopher Summerfield
The Role of Meta-learning for Few-Shot Learning
Tutorial Organizers include: Eleni Triantafillou
Invited Panelists include: Neil Houlsby, Priyanka Agrawal
Competitions
NeurIPS 2022 Competition Track: Overview & Results
Invited Speakers include: Isabelle Guyon
Causal Insights for Learning Paths in Education
Competition Organizers include: Zichao (Jack) Wang
IGLU: Interactive Grounded Language Understanding in a Collaborative Environment
Competition Organizers include: Negar Arabzadeh
Cross-Domain MetaDL: Any-Way Any-Shot Learning Competition with Novel Datasets from Practical Domains
Competition Organizers include: Isabelle Guyon
Reconnaissance Blind Chess: An Unsolved Challenge for Multi-Agent Decision Making Under Uncertainty
Competition Organizers include: Bo Li
VisDA 2022 Challenge: Sim2Real Domain Adaptation for Industrial Recycling
Competition Organizers include: Dina Bashkirova
Spotlight Papers
CoPur: Certifiably Robust Collaborative Inference via Feature Purification
Jing Liu, Chulin Xie, Oluwasanmi O Koyejo, Bo Li
Machine Learning on Graphs: A Model and Comprehensive Taxonomy
Ines Chami*, Sami Abu-El-Haija, Bryan Perozzi, Christopher Ré, Kevin Murphy
Sparse Winning Tickets are Data-Efficient Image Recognizers
Mukund Varma T, Xuxi Chen, Zhenyu Zhang, Tianlong Chen, Subhashini Venugopalan, Zhangyang Wang
Federated Learning from Pre-trained Models: A Contrastive Learning Approach
Yue Tan, Guodong Long, Jie Ma, Lu Liu, Tianyi Zhou, Jing Jiang
Improving Multi-task Generalization via Regularizing Spurious Correlation
Ziniu Hu*, Zhe Zhao, Xinyang Yi, Tiansheng Yao, Lichan Hong, Yizhou Sun, Ed H. Chi
The Nature of Temporal Difference Errors in Multi-step Distributional Reinforcement Learning
Yunhao Tang, Mark Rowland, Rémi Munos, Bernardo Ávila Pires, Will Dabney, Marc G. Bellemare
Residual Multiplicative Filter Networks for Multiscale Reconstruction
Shayan Shekarforoush, David B. Lindell, David J. Fleet, Marcus A Brubaker
Differentially Private Learning with Margin Guarantees
Raef Bassily, Mehryar Mohri, Ananda Theertha Suresh
Optimal Query Complexities for Dynamic Trace Estimation
David P. Woodruff*, Fred Zhang*, Qiuyi Zhang
Papers
From Gradient Flow on Population Loss to Learning with Stochastic Gradient Descent
Ayush Sekhari, Satyen Kale, Jason D. Lee, Chris De Sa, Karthik Sridharan
On the Global Convergence Rates of Decentralized Softmax Gradient Play in Markov Potential Games
Runyu Zhang, Jincheng Mei, Bo Dai, Dale Schuurmans, Na Li
Matryoshka Representation Learning
Aditya Kusupati, Gantavya Bhatt, Aniket Rege, Matthew Wallingford, Aditya Sinha, Vivek Ramanujan, William Howard-Snyder, Kaifeng Chen, Sham Kakade, Prateek Jain, Ali Farhadi
Efficient Risk-Averse Reinforcement Learning
Ido Greenberg, Yinlam Chow, Mohammad Ghavamzadeh, Shie Mannor
Operator Splitting Value Iteration
Amin Rakhsha, Andrew Wang, Mohammad Ghavamzadeh, Amir-massoud Farahmand
Cluster Randomized Designs for One-Sided Bipartite Experiments
Jennifer Brennan*, Vahab Mirrokni, Jean Pouget-Abadie
A Unified Sequence Interface for Vision Tasks
Ting Chen, Saurabh Saxena, Lala Li, Tsung-Yi Lin*, David J. Fleet, Geoffrey Hinton
Cryptographic Hardness of Learning Halfspaces with Massart Noise
Ilias Diakonikolas, Daniel M. Kane, Pasin Manurangsi, Lisheng Ren
Better Best of Both Worlds Bounds for Bandits with Switching Costs
Idan Amir, Guy Azov, Tomer Koren, Roi Livni
Fast Neural Kernel Embeddings for General Activations
Insu Han, Amir Zandieh, Jaehoon Lee, Roman Novak, Lechao Xiao, Amin Karbasi
Hierarchical Agglomerative Graph Clustering in Poly-Logarithmic Depth
Laxman Dhulipala, David Eisenstat, Jakub Łącki, Vahab Mirronki, Jessica Shi
Improving Zero-Shot Generalization in Offline Reinforcement Learning Using Generalized Similarity Functions
Bogdan Mazoure*, Ilya Kostrikov, Ofir Nachum, Jonathan Tompson
Indicators of Attack Failure: Debugging and Improving Optimization of Adversarial Examples
Maura Pintor, Luca Demetrio, Angelo Sotgiu, Ambra Demontis, Nicholas Carlini, Battista Biggio, Fabio Roli
Learning Energy Networks with Generalized Fenchel-Young Losses
Mathieu Blondel, Felipe Llinares-López, Robert Dadashi, Léonard Hussenot, Matthieu Geist
Learning Robust Dynamics Through Variational Sparse Gating
Arnav Kumar Jain, Shiva Kanth Sujit, Shruti Joshi, Vincent Michalski, Danijar Hafner, Samira Ebrahimi Kahou
Learning to Reason with Neural Networks: Generalization, Unseen Data and Boolean Measures
Arnav Kumar Jain, Shiva Kanth Sujit, Shruti Joshi, Vincent Michalski, Danijar Hafner, Samira Ebrahimi Kahou
So3krates: Equivariant Attention for Interactions on Arbitrary Length-Scales in Molecular Systems
J. Thorben Frank, Oliver T. Unke, Klaus-Robert Müller
Spectral Bias in Practice: The Role of Function Frequency in Generalization
Sara Fridovich-Keil*, Raphael Gontijo-Lopes, Rebecca Roelofs
Delving into Out-of-Distribution Detection with Vision-Language Representations
Yifei Ming, Ziyang Cai, Jiuxiang Gu, Yiyou Sun, Wei Li, Yixuan Li
Path Independent Equilibrium Models Can Better Exploit Test-Time Computation
Cem Anil, Ashwini Pokle, Kaiqu Liang, Johannes Treutlein, Yuhuai Wu, Shaojie Bai, J. Zico Kolter, Roger Grosse
On Optimal Learning Under Targeted Data Poisoning
Steve Hanneke, Amin Karbasi, Mohammad Mahmoody, Idan Mehalel, Shay Moran
Learning With Little Mixing
Ingvar Ziemann, Stephen Tu
Block-Recurrent Transformers
DeLesley Hutchins, Imanol Schlag*, Yuhuai Wu, Ethan Dyer, Behnam Neyshabur
TabNAS: Rejection Sampling for Neural Architecture Search on Tabular Datasets
Chengrun Yang, Gabriel Bender, Hanxiao Liu, Pieter-Jan Kindermans, Madeleine Udell, Yifeng Lu, Quoc Le, Da Huang
Regret Bounds for Multilabel Classification in Sparse Label Regimes
Robert Busa-Fekete, Heejin Choi, Krzysztof Dembczynski, Claudio Gentile, Henry William Reeve, Balazs Szorenyi
Robust Reinforcement Learning Using Offline Data
Kishan Panaganti, Zaiyan Xu, Dileep Kalathil, Mohammad Ghavamzadeh
Contrastive Learning as Goal-Conditioned Reinforcement Learning
Benjamin Eysenbach, Tianjun Zhang, Sergey Levine, Ruslan Salakhutdinov
Beyond Rewards: A Hierarchical Perspective on Offline Multiagent Behavioral Analysis
Shayegan Omidshafiei, Andrei Kapishnikov, Yannick Assogba, Lucas Dixon, Been Kim
Revisiting Neural Scaling Laws in Language and Vision
Ibrahim Alabdulmohsin, Behnam Neyshabur, Xiaohua Zhai
Polynomial Neural Fields for Subband Decomposition and Manipulation
Guandao Yang*, Sagie Benaim, Varun Jampani, Kyle Genova, Jonathan T. Barron, Thomas Funkhouser, Bharath Hariharan, Serge Belongie
First Is Better Than Last for Language Data Influence
Chih-Kuan Yeh, Ankur Taly, Mukund Sundararajan, Frederick Liu, Pradeep Ravikumar
The Privacy Onion Effect: Memorization Is Relative
Nicholas Carlini, Matthew Jagielski, Chiyuan Zhang, Nicolas Papernot, Andreas Terzis, Florian Tramer
Deep Hierarchical Planning from Pixels (see blog post)
Danijar Hafner, Kuang-Huei Lee, Ian Fischer, Pieter Abbeel
Discovered Policy Optimisation
Chris Lu, Jakub Grudzien Kuba, Alistair Letcher, Luke Metz, Christian Schroeder de Witt, Jakob Foerster
Semi-supervised Active Linear Regression
Fnu Devvrit, Nived Rajaraman, Pranjal Awasthi
Pruning’s Effect on Generalization Through the Lens of Training and Regularization
Tian Jin, Daniel M. Roy, Michael Carbin, Jonathan Frankle, Gintare Karolina Dziugaite
Exploring Length Generalization in Large Language Models
Cem Anil*, Yuhuai Wu, Anders Andreassen, Aitor Lewkowycz, Vedant Misra, Vinay Ramasesh, Ambrose Slone, Guy Gur-Ari, Ethan Dyer, Behnam Neyshabur
Fast Stochastic Composite Minimization and an Accelerated Frank-Wolfe Algorithm Under Parallelization
Benjamin Dubois-Taine, Francis Bach, Quentin Berthet, Adrien Taylor
Global Normalization for Streaming Speech Recognition in a Modular Framework
Ehsan Variani, Ke Wu, Michael Riley, David Rybach, Matt Shannon, Cyril Allauzen
Learning Predictions for Algorithms with Predictions
Mikhail Khodak, Maria-Florina Balcan, Ameet Talwalkar, Sergei Vassilvitskii
Multimodal Contrastive Learning with LIMoE: the Language-Image Mixture of Experts (see blog post)
Basil Mustafa, Carlos Riquelme, Joan Puigcerver, Rodolphe Jenatton, Neil Houlsby
Incrementality Bidding via Reinforcement Learning Under Mixed and Delayed Rewards
Ashwinkumar Badanidiyuru, Zhe Feng, Tianxi Li, Haifeng Xu*
Solving Quantitative Reasoning Problems with Language Models (see blog post)
Aitor Lewkowycz, Anders Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay Ramasesh, Ambrose Slone, Cem Anil, Imanol Schlag, Theo Gutman-Solo, Yuhuai Wu, Behnam Neyshabur, Guy Gur-Ari, Vedant Misra
Anonymized Histograms in Intermediate Privacy Models
Badih Ghazi, Pritish Kamath, Ravi Kumar, Pasin Manurangsi
Efficient and Stable Fully Dynamic Facility Location
Sayan Bhattacharya, Nikos Parotsidis, Silvio Lattanzi
Are All Losses Created Equal: A Neural Collapse Perspective
Jinxin Zhou, Chong You, Xiao Li, Kangning Liu, Sheng Liu, Qing Qu, Zhihui Zhu
Universal Rates for Interactive Learning
Steve Hanneke, Amin Karbasi, Shay Moran, Grigoris Velegkas
Nearly Optimal Algorithms for Linear Contextual Bandits with Adversarial Corruptions
Jiafan He, Dongruo Zhou, Tong Zhang, Quanquan Gu
Multiclass Learnability Beyond the PAC Framework: Universal Rates and Partial Concept Classes
Alkis Kalavasis, Grigoris Velegkas, Amin Karbasi
Temporal Latent Bottleneck: Synthesis of Fast and Slow Processing Mechanisms in Sequence Learning
Cenk Baykal, Nishanth Dikkala, Rina Panigrahy, Cyrus Rashtchian, Xin Wang
Pre-trained Language Models for Interactive Decision-Making
Shuang Li, Xavier Puig, Chris Paxton, Yilun Du, Clinton Wang, Linxi Fan, Tao Chen, De-An Huang, Ekin Akyürek, Anima Anandkumar, Jacob Andreas, Igor Mordatch, Antonio Torralba, Yuke Zhu
Polynomial Neural Fields for Subband Decomposition and Manipulation
Guandao Yang*, Sagie Benaim, Varun Jampani, Kyle Genova, Jonathan T. Barron, Thomas Funkhouser, Bharath Hariharan, Serge Belongie
Submodular Maximization in Clean Linear Time
Wenxin Li, Moran Feldman, Ehsan Kazemi, Amin Karbasi
Reinforcement Learning with Logarithmic Regret and Policy Switches
Grigoris Velegkas, Zhuoran Yang, Amin Karbasi
Algorithms with Prediction Portfolios
Michael Dinitz, Sungjin Im, Thomas Lavastida, Benjamin Moseley, Sergei Vassilvitskii
Understanding and Improving Robustness of Vision Transformers Through Patch-Based Negative Augmentation
Yao Qin, Chiyuan Zhang, Ting Chen, Balaji Lakshminarayanan, Alex Beutel, Xuezhi Wang
Best of Both Worlds Model Selection
Aldo Pacchiano, Christoph Dann, Claudio Gentile
Fair Wrapping for Black-Box Predictions
Alexander Soen, Ibrahim Alabdulmohsin, Sanmi Koyejo, Yishay Mansour, Nyalleng Moorosi, Richard Nock, Ke Sun, Lexing Xie
A Reduction to Binary Approach for Debiasing Multiclass Datasets
Ibrahim Alabdulmohsin, Jessica Schrouff, Oluwasanmi Koyejo
Weighted Distillation with Unlabeled Examples
Fotis Iliopoulos, Vasilis Kontonis, Cenk Baykal, Gaurav Menghani, Khoa Trihn,Erik Vee
A Closer Look at Learned Optimization: Stability, Robustness, and Inductive Biases
James Harrison, Luke Metz, Jascha Sohl-Dickstein
Post-hoc Estimators for Learning to Defer to an Expert
Harikrishna Narasimhan, Wittawat Jitkrittum, Aditya Krishna Menon, Ankit Singh Rawat, Sanjiv Kumar
Model-Based RL with Optimistic Posterior Sampling: Structural Conditions and Sample Complexity
Alekh Agarwal, Tong Zhang
On the Statistical Efficiency of Reward-Free Exploration in Non-Linear RL
Jinglin Chen, Aditya Modi, Akshay Krishnamurthy, Nan Jiang, Alekh Agarwal
Towards Learning Universal Hyperparameter Optimizers with Transformers (see blog post)
Yutian Chen, Xingyou Song, Chansoo Lee, Zi Wang, Qiuyi Zhang, David Dohan, Kazuya Kawakami, Greg Kochanski, Arnaud Doucet, Marc’aurelio Ranzato, Sagi Perel, Nando de Freitas
Reproducibility in Optimization: Theoretical Framework and Limits
Kwangjun Ahn*, Prateek Jain, Ziwei Ji, Satyen Kale, Praneeth Netrapalli, Gil I. Shamir
Confident Adaptive Language Modeling
Tal Schuster, Adam Fisch, Jai Gupta, Mostafa Dehghani, Dara Bahri, Vinh Q. Tran, Yi Tay, Donald Metzler
Reinforcement Learning with Neural Radiance Fields
Danny Driess, Ingmar Schubert, Pete Florence, Yunzhu Li, Marc Toussaint
Invariant and Transportable Representations for Anti-Causal Domain Shifts
Yibo Jiang, Victor Veitch
Simple Mechanisms for Welfare Maximization in Rich Advertising Auctions
Gagan Aggarwal, Kshipra Bhawalkar, Aranyak Mehta, Divyarthi Mohan, Alexandros Psomas
STaR: Bootstrapping Reasoning with Reasoning
Eric Zelikman, Yuhuai Wu, Jesse Mu, Noah D. Goodman
Stochastic Online Learning with Feedback Graphs: Finite-Time and Asymptotic Optimality
Teodor V. Marinov, Mehryar Mohri, Julian Zimmert
The Curse of Unrolling: Rate of Differentiating Through Optimization
Damien Scieur, Quentin Bertrand, Gauthier Gidel, Fabian Pedregosa
Visual Prompting via Image Inpainting
Amir Bar, Yossi Gandelsman, Trevor Darrell, Amir Globerson, Alexei A Efros
Multi-Class H-Consistency Bounds
Pranjal Awasthi, Anqi Mao, Mehryar Mohri, Yutao Zhong
Anonymous Bandits for Multi-User Systems
Hossein Esfandiari, Vahab Mirrokni, Jon Schneider
Understanding the Eluder Dimension
Gene Li, Pritish Kamath, Dylan J. Foster, Nathan Srebro
Why So Pessimistic? Estimating Uncertainties for Offline RL Through Ensembles, and Why Their Independence Matters
Seyed Kamyar Seyed Ghasemipour, Shixiang Shane Gu, Ofir Nachum
A Best-of-Both-Worlds Algorithm for Bandits with Delayed Feedback
Saeed Masoudian, Julian Zimmert, Yevgeny Seldin
A Theoretical View on Sparsely Activated Networks
Cenk Baykal, Nishanth Dikkala, Rina Panigrahy, Cyrus Rashtchian, Xin Wang
Chain of Thought Prompting Elicits Reasoning in Large Language Models (see blog post)
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, Denny Zhou
Decoupled Context Processing for Context Augmented Language Modeling
Zonglin Li, Ruiqi Guo, Sanjiv Kumar
Exploring Through Random Curiosity with General Value Functions
Aditya Ramesh, Louis Kirsch, Sjoerd van Steenkiste, Jürgen Schmidhuber
Object Scene Representation Transformer
Mehdi S. M. Sajjadi, Daniel Duckworth, Aravindh Mahendran, Sjoerd van Steenkiste, Filip Pavetić, Mario Lučić, Leonidas J. Guibas, Klaus Greff, Thomas Kipf
Joint Model-Policy Optimization of a Lower Bound for Model-Based RL
Benjamin Eysenbach, Alexander Khazatsky, Sergey Levine, Ruslan Salakhutdinov
A Fourier Approach to Mixture Learning
Mingda Qiao*, Guru Guruganesh, Ankit Singh Rawat, Avinava Dubey, Manzil Zaheer
Why Neural Networks Find Simple Solutions: The Many Regularizers of Geometric Complexity
Benoit Dherin, Michael Munn, Mihaela Rosca, David Barrett
Do Current Multi-task Optimization Methods in Deep Learning Even Help?
Derrick Xin, Behrooz Ghorbani, Ankush Garg, Orhan Firat, Justin Gilmer
Associating Objects and Their Effects in Video Through Coordination Games
Erika Lu, Forrester Cole, Weidi Xie, Tali Dekel, William Freeman, Andrew Zisserman, Michael Rubinstein
Increasing Confidence in Adversarial Robustness Evaluations
Roland S. Zimmermann*, Wieland Brendel, Florian Tramèr, Nicholas Carlini
The Role of Baselines in Policy Gradient Optimization
Jincheng Mei, Wesley Chung, Valentin Thomas, Bo Dai, Csaba Szepesvari, Dale Schuurmans
Scaling Multimodal Pre-training via Cross-Modality Gradient Harmonization
Junru Wu, Yi Liang, Feng Han, Hassan Akbari, Zhangyang Wang, Cong Yu*
S3GC: Scalable Self-Supervised Graph Clustering
Fnu Devvrit*, Aditya Sinha, Inderjit Dhillon, Prateek Jain
Algorithms and Hardness for Learning Linear Thresholds from Label Proportions
Rishi Saket
ALMA: Hierarchical Learning for Composite Multi-Agent Tasks
Shariq Iqbal, Robby Costales, Fei Sha
DC-BENCH: Dataset Condensation Benchmark
Justin Cui, Ruochen Wang, Si Si, Cho-Jui Hsieh
Does GNN Pre-training Help Molecular Representation?
Ruoxi Sun, Hanjun Dai, Adams Yu
Drawing Out of Distribution with Neuro-Symbolic Generative Models
Yichao Liang, Joshua B. Tenenbaum, Tuan Anh Le, N. Siddharth
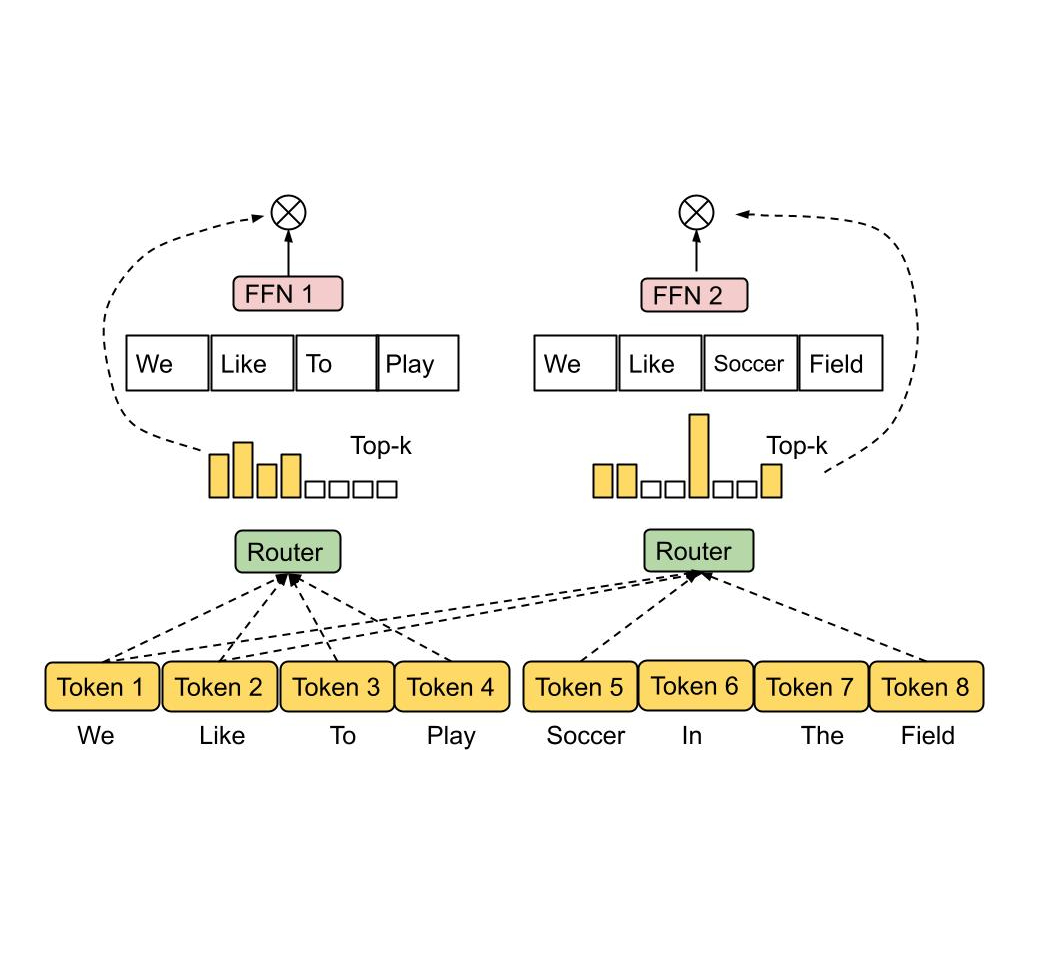
Mixture-of-Experts with Expert Choice Routing (see blog post)
Yanqi Zhou, Tao Lei, Hanxiao Liu, Nan Du, Yanping Huang, Vincent Zhao, Andrew Dai, Zhifeng Chen, Quoc Le, James Laudon
Near-Optimal Regret for Adversarial MDP with Delayed Bandit Feedback
Tiancheng Jin, Tal Lancewicki, Haipeng Luo, Yishay Mansour, Aviv Rosenberg
Precise Learning Curves and Higher-Order Scalings for Dot-Product Kernel Regression
Lechao Xiao, Jeffrey Pennington, Theodor Misiakiewicz, Hong Hu, Yue Lu
Rate-Optimal Online Convex Optimization in Adaptive Linear Control
Asaf Cassel, Alon Cohen, Tomer Koren
Why Neural Networks Find Simple Solutions: The Many Regularizers of Geometric Complexity
Benoit Dherin, Michael Munn, Mihaela Rosca, David G.T. Barrett
Private Isotonic Regression
Badih Ghazi, Pritish Kamath, Ravi Kumar, Pasin Manurangsi
Sketching Based Representations for Robust Image Classification with Provable Guarantees
Nishanth Dikkala, Sankeerth Rao Karingula, Raghu Meka, Jelani Nelson, Rina Panigrahy, Xin Wang
The Role of Baselines in Policy Gradient Optimization
Jincheng Mei, Wesley Chung, Valentin Thomas, Bo Dai, Csaba Szepesvari, Dale Schuurmans
Bringing Image Scene Structure to Video via Frame-Clip Consistency of Object Tokens
Elad Ben Avraham, Roei Herzig, Karttikeya Mangalam, Amir Bar, Anna Rohrbach, Leonid Karlinsky, Trevor Darrell, Amir Globerson
Near-Optimal Private and Scalable k-Clustering
Vincent Cohen-Addad, Alessandro Epasto, Vahab Mirrokni, Shyam Narayanan*, Peilin Zhong
When Does Differentially Private Learning Not Suffer in High Dimensions?
Xuechen Li, Daogao Liu, Tatsunori Hashimoto, Huseyin A Inan, Janardhan Kulkarni, YinTat Lee, Abhradeep Guha Thakurta
End-to-End Learning to Index and Search in Large Output Spaces
Nilesh Gupta, Patrick H. Chen, Hsiang-Fu, Yu, Cho-Jui Hsieh, Inderjit S. Dhillon
A Boosting Approach to Reinforcement Learning
Nataly Brukhim, Elad Hazan, Karan Singh
FedRolex: Model-Heterogeneous Federated Learning with Rolling Sub-Model Extraction
Samiul Alam, Luyang Liu, Ming Yan, Mi Zhang
Non-Convex Online Learning via Algorithmic Equivalence
Udaya Ghai, Zhou Lu, Elad Hazan
Is this the Right Neighborhood? Accurate and Query Efficient Model Agnostic Explanations
Amit Dhurandhar, Karthikeyan Natesan Ramamurthy, Karthikeyan Shanmugam
SAVi++: Towards End-to-End Object-Centric Learning from Real-World Videos
Gamaleldin F. Elsayed, Aravindh Mahendran, Sjoerd van Steenkiste, Klaus Greff, Michael C. Mozer, Thomas Kipf
UViM: A Unified Modeling Approach for Vision with Learned Guiding Codes
Alexander Kolesnikov, André Susano Pinto, Lucas Beyer, Xiaohua Zhai, Jeremiah Harmsen, Neil Houlsby
Implicit Regularization or Implicit Conditioning? Exact Risk Trajectories of SGD in High Dimensions
Courtney Paquette, Elliot Paquette, Ben Adlam, Jeffrey Pennington
Multi-game Decision Transformers (see blog post)
Kuang-Huei Lee, Ofir Nachum, Mengjiao Yang, Lisa Lee, Daniel Freeman, Winnie Xu, Sergio Guadarrama, Ian Fischer, Eric Jang, Henryk Michalewski, Igor Mordatch
Subsidiary Prototype Alignment for Universal Domain Adaptation
Jogendra Nath Kundu, Suvaansh Bhambri, Akshay Ravindra Kulkarni, Hiran Sarkar, Varun Jampani, Venkatesh Babu Radhakrishnan
SAMURAI: Shape And Material from Unconstrained Real-world Arbitrary Image collections
Mark Boss*, Andreas Engelhardt*, Abhishek Kar, Yuanzhen Li, Deqing Sun, Jonathan T. Barron, Hendrik P. A. Lensch, Varun Jampani
Chefs’ Random Tables: Non-Trigonometric Random Features
Valerii Likhosherstov, Krzysztof Marcin Choromanski, Avinava Dubey, Frederick Liu, Tamas Sarlos, Adrian Weller
Lottery Tickets on a Data Diet: Finding Initializations with Sparse Trainable Networks
Mansheej Paul, Brett W Larsen, Surya Ganguli, Jonathan Frankle, Gintare Karolina Dziugaite
DP-PCA: Statistically Optimal and Differentially Private PCA
Xiyang Liu, Weihao Kong, Prateek Jain, Sewoong Oh
Emergent Communication: Generalization and Overfitting in Lewis Games
Mathieu Rita, Corentin Tallec, Paul Michel, Jean-Bastien Grill, Olivier Pietquin, Emmanuel Dupoux, Florian Strub
Handcrafted Backdoors in Deep Neural Networks
Sanghyun Hong, Nicholas Carlini, Alexey Kurakin
I2DFormer: Learning Image to Document Attention for Zero-Shot Image Classification
Muhammad Ferjad Naeem, Yongqin Xian, Luc Van Gool, Federico Tombari
Improved Differential Privacy for SGD via Optimal Private Linear Operators on Adaptive Streams
Sergey Denisov, Brendan McMahan, Keith Rush, Adam Smith, Abhradeep Guha Thakurta
Optimal Scaling for Locally Balanced Proposals in Discrete Spaces
Haoran Sun*, Hanjun Dai, Dale Schuurmans
Near-Optimal Correlation Clustering with Privacy
Vincent Cohen-Addad, Chenglin Fan, Silvio Lattanzi, Slobodan Mitrović, Ashkan Norouzi-Fard, Nikos Parotsidis, Jakub Tarnawski
Thor: Wielding Hammers to Integrate Language Models and Automated Theorem Provers
Albert Q. Jiang, Wenda Li, Szymon Tworkowski, Konrad Czechowski, Tomasz Odrzygóźdź, Piotr Miłoś, Yuhuai Wu, Mateja Jamnik
TPU-KNN: K Nearest Neighbor Search at Peak FLOP/s
Felix Chern, Blake Hechtman, Andy Davis, Ruiqi Guo, David Majnemer, Sanjiv Kumar
When Does Dough Become a Bagel? Analyzing the Remaining Mistakes on ImageNet
Vijay Vasudevan, Benjamin Caine, Raphael Gontijo-Lopes, Sara Fridovich-Keil, Rebecca Roelofs
DASCO: Dual-Generator Adversarial Support Constrained Offline Reinforcement Learning
Quan Vuong, Aviral Kumar, Sergey Levine, Yevgen Chebotar
A Characterization of Semi-Supervised Adversarially Robust PAC Learnability
Idan Attias, Steve Hanneke, Yishay Mansour
Back Razor: Memory-Efficient Transfer Learning by Self-Sparsified Backpropagation
Ziyu Jiang, Xuxi Chen, Xueqin Huang, Xianzhi Du, Denny Zhou, Zhangyang Wang
Subquadratic Kronecker Regression with Applications to Tensor Decomposition
Matthew Fahrbach, Gang Fu, Mehrdad Ghadiri
Zero-Shot Transfer Learning Within a Heterogeneous Graph via Knowledge Transfer Networks
Minji Yoon*, John Palowitch, Dustin Zelle, Ziniu Hu*, Ruslan Salakhutdinov, Bryan Perozzi
Differentially Private Graph Learning via Sensitivity-Bounded Personalized PageRank
Alessandro Epasto, Vahab Mirrokni, Bryan Perozzi, Anton Tsitsulin, Peilin Zhong
Reincarnating Reinforcement Learning: Reusing Prior Computation to Accelerate Progress (see blog post)
Rishabh Agarwal, Max Schwarzer, Pablo Samuel Castro, Aaron Courville, Marc G. Bellemare
Private and Communication-Efficient Algorithms for Entropy Estimation
Gecia Bravo-Hermsdorff, Robert Busa-Fekete, Mohammad Ghavamzadeh, Andres Munoz Medina, Umar Syed
Oracle Inequalities for Model Selection in Offline Reinforcement Learning
Jonathan Lee, George Tucker, Ofir Nachum, Bo Dai, Emma Brunskill
Diagnosing Failures of Fairness Transfer Across Distribution Shift in Real-World Medical Settings
Jessica Schrouff*, Natalie Harris, Oluwasanmi O Koyejo, Ibrahim Alabdulmohsin, Eva Schnider*, Krista Opsahl-Ong, Alexander Brown, Subhrajit Roy, Diana Mincu, Christina Chen, Awa Dieng, Yuan Liu, Vivek Natarajan, Alan Karthikesalingam, Katherine A Heller, Silvia Chiappa, Alexander D’Amour
LASSIE: Learning Articulated Shapes from Sparse Image Ensemble via 3D Part Discovery
Chun-Han Yao, Wei-Chih Hung, Yuanzhen Li, Michael Rubinstein, Ming-Hsuan Yang, Varun Jampani
Patching Open-Vocabulary Models by Interpolating Weights
Gabriel Ilharco, Mitchell Wortsman, Samir Yitzhak Gadre, Shuran Song, Hannaneh Hajishirzi, Simon Kornblith, Ali Farhadi, Ludwig Schmidt
TUSK: Task-Agnostic Unsupervised Keypoints
Yuhe Jin, Weiwei Sun, Jan Hosang, Eduard Trulls, Kwang Moo Yi
Active Learning of Classifiers with Label and Seed Queries
Marco Bressan, Nicolò Cesa-Bianchi, Silvio Lattanzi, Andrea Paudice, Maximilian Thiessen
Autoformalization with Large Language Models
Yuhuai Wu, Albert Q. Jiang, Wenda Li, Markus N. Rabe, Charles Staats, Mateja Jamnik, Christian Szegedy
Benign Underfitting of Stochastic Gradient Descent
Tomer Koren, Roi Livni, Yishay Mansour, Uri Sherman
Chain of Thought Imitation with Procedure Cloning
Mengjiao Yang, Dale Schuurmans, Pieter Abbeel, Ofir Nachum
Efficient and Modular Implicit Differentiation
Mathieu Blondel, Quentin Berthet, Marco Cuturi, Roy Frostig, Stephan Hoyer, Felipe Llinares-López, Fabian Pedregosa, Jean-Philippe Vert
Insights into Pre-training via Simpler Synthetic Tasks
Yuhuai Wu, Felix Li, Percy Liang
Self-Supervised Learning with an Information Maximization Criterion
Serdar Ozsoy, Shadi Hamdan, Sercan Ö. Arik, Deniz Yuret, Alper T. Erdogan
Trimmed Maximum Likelihood Estimation for Robust Generalized Linear Model
Weihao Kong, Rajat Sen, Pranjal Awasthi, Abhimanyu Das
Using Embeddings for Causal Estimation of Peer Influence in Social Networks
Irina Cristali, Victor Veitch
VCT: A Video Compression Transformer
Fabian Mentzer, George Toderici, David Minnen, Sung-Jin Hwang, Sergi Caelles, Mario Lucic, Eirikur Agustsson
Video Diffusion Models
Jonathan Ho, Tim Salimans, Alexey Gritsenko, William Chan, Mohammad Norouzi, David J. Fleet
Large Language Models are Zero-Shot Reasoners
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, Yusuke Iwasawa
Improved Coresets for Euclidean k-Means
Vincent Cohen-Addad, Kasper Green Larsen, David Saulpic, Chris Schwiegelshohn, Omar Ali Sheikh-Omar
On the Adversarial Robustness of Mixture of Experts
Joan Puigcerver, Rodolphe Jenatton, Carlos Riquelme Ruiz, Pranjal Awasthi, Srinadh Bhojanapalli
Stars: Tera-Scale Graph Building for Clustering and Learning
CJ Carey, Jonathan Halcrow, Rajesh Jayaram, Vahab Mirrokni, Warren Schudy, Peilin Zhong
VER: Scaling On-Policy RL Leads to the Emergence of Navigation in Embodied Rearrangement
Erik Wijmans, Irfan Essa, Dhruv Batra
TaSIL: Taylor Series Imitation Learning
Daniel Pfrommer, Thomas TCK Zhang, Stephen Tu, Nikolai Matni
RNNs of RNNs: Recursive Construction of Stable Assemblies of Recurrent Neural Networks
Leo Kozachkov, Michaela M Ennis, Jean-Jacques Slotine
Integral Probability Metrics PAC-Bayes Bounds
Ron Amit, Baruch Epstein, Shay Moran, Ron Meir
D2NeRF: Self-Supervised Decoupling of Dynamic and Static Objects from a Monocular Video
Tianhao Wu, Fangcheng Zhong, Andrea Tagliasacchi, Forrester Cole, Cengiz Oztireli
Posted Pricing and Dynamic Prior-Independent Mechanisms with Value Maximizers
Yuan Deng, Vahab Mirrokni, Hanrui Zhang
Transformer Memory as a Differentiable Search Index
Yi Tay, Vinh Q. Tran, Mostafa Dehghani, Jianmo Ni, Dara Bahri, Harsh Mehta, Zhen Qin, Kai Hui, Zhe Zhao, Jai Gupta, Tal Schuster, William W. Cohen, Donald Metzler
*Work done while at Google. ↩






-buffer.jpg)
























 –>
–>