
Quantum processors are made of superconducting quantum bits (qubits) that — being quantum objects — are highly susceptible to even tiny amounts of environmental noise. This noise can cause errors in quantum computation that need to be addressed to continue advancing quantum computers. Our Sycamore processors are installed in specially designed cryostats, where they are sealed away from stray light and electromagnetic fields and are cooled down to very low temperatures to reduce thermal noise.
However, the world is full of high-energy radiation. In fact, there’s a tiny background of high-energy gamma rays and muons that pass through everything around us all the time. While these particles interact so weakly that they don’t cause any harm in our day-to-day lives, qubits are sensitive enough that even weak particle interactions can cause significant interference.
In “Resolving Catastrophic Error Bursts from Cosmic Rays in Large Arrays of Superconducting Qubits”, published in Nature Physics, we identify the effects of these high-energy particles when they impact the quantum processor. To detect and study individual impact events, we use new techniques in rapid, repetitive measurement to operate our processor like a particle detector. This allows us to characterize the resulting burst of errors as they spread through the chip, helping to better understand this important source of correlated errors.
The Dynamics of a High-Energy Impact
The Sycamore quantum processor is constructed with a very thin layer of superconducting aluminum on a silicon substrate, onto which a pattern is etched to define the qubits. At the center of each qubit is the Josephson junction, a superconducting component that defines the distinct energy levels of the qubit, which are used for computation. In a superconducting metal, electrons bind together into a macroscopic, quantum state, which allows electrons to flow as a current with zero resistance (a supercurrent). In superconducting qubits, information is encoded in different patterns of oscillating supercurrent going back and forth through the Josephson junction.
If enough energy is added to the system, the superconducting state can be broken up to produce quasiparticles. These quasiparticles are a problem, as they can absorb energy from the oscillating supercurrent and jump across the Josephson junction, which changes the qubit state and produces errors. To prevent any energy from being absorbed by the chip and producing quasiparticles, we use extensive shielding for electric and magnetic fields, and powerful cryogenic refrigerators to keep the chip near absolute zero temperature, thus minimizing the thermal energy.
A source of energy that we can’t effectively shield against is high-energy radiation, which includes charged particles and photons that can pass straight through most materials. One source of these particles are tiny amounts of radioactive elements that can be found everywhere, e.g., in building materials, the metal that makes up our cryostats, and even in the air. Another source is cosmic rays, which are extremely energetic particles produced by supernovae and black holes. When cosmic rays impact the upper atmosphere, they create a shower of high-energy particles that can travel all the way down to the surface and through our chip. Between radioactive impurities and cosmic ray showers, we expect a high energy particle to pass through a quantum chip every few seconds.
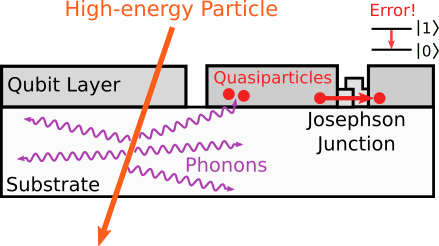 |
| When a high-energy impact event occurs, energy spreads through the chip in the form of phonons. When these arrive at the superconducting qubit layer, they break up the superconducting state and produce quasiparticles, which cause the qubit errors we observe. |
When one of these particles impinges on the chip, it passes straight through and deposits a small amount of its energy along its path through the substrate. Even a small amount of energy from these particles is a very large amount of energy for the qubits. Regardless of where the impact occurs, the energy quickly spreads throughout the entire chip through quantum vibrations called phonons. When these phonons hit the aluminum layer that makes up the qubits, they have more than enough energy to break the superconducting state and produce quasiparticles. So many quasiparticles are produced that the probability of the qubits interacting with one becomes very high. We see this as a sudden and significant increase in errors over the whole chip as those quasiparticles absorb energy from the qubits. Eventually, as phonons escape and the chip cools, these quasiparticles recombine back into the superconducting state, and the qubit error rates slowly return to normal.
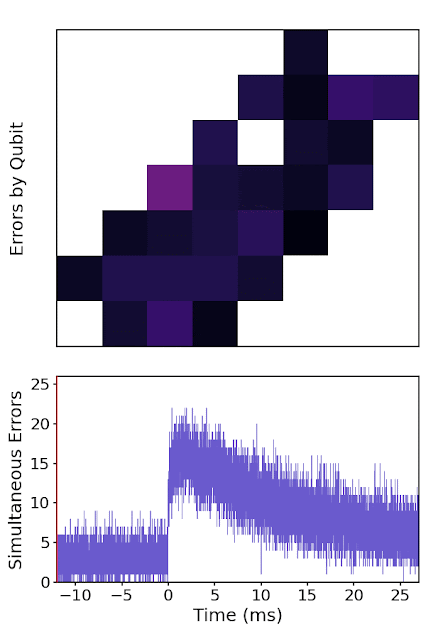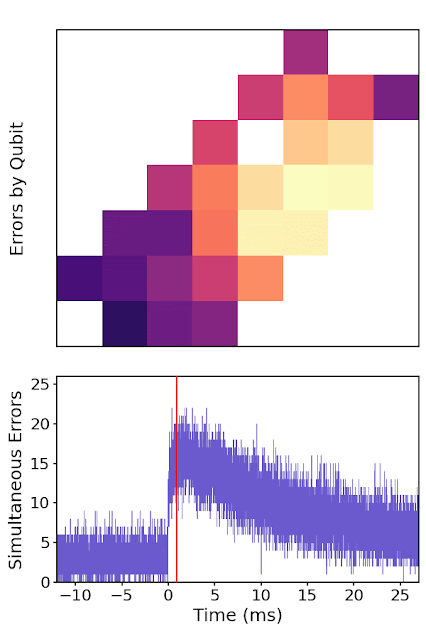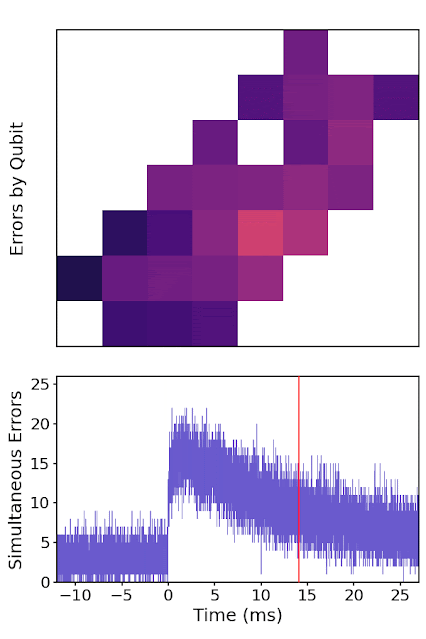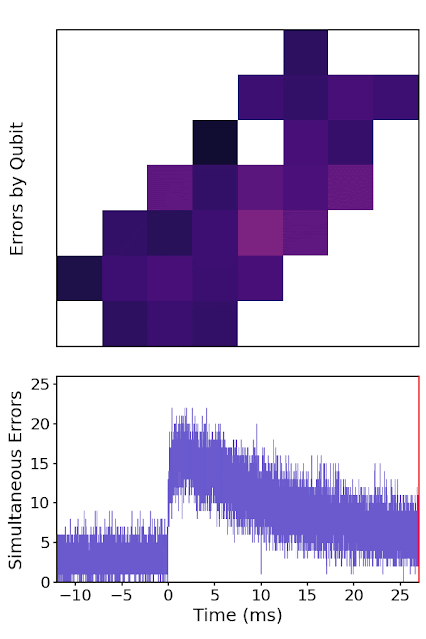 |
| A high-energy particle impact (at time = 0 ms) on a patch of the quantum processor, showing error rates for each qubit over time. The event starts by rapidly spreading error over the whole chip, before saturating and then slowly returning to equilibrium. |
Detecting Particles with a Computer
The Sycamore processor is designed to perform quantum error correction (QEC) to improve the error rates and enable it to execute a variety of quantum algorithms. QEC provides an effective way of identifying and mitigating errors, provided they are sufficiently rare and independent. However, in the case of a high-energy particle going through the chip, all of the qubits will experience high error rates until the event cools off, producing a correlated error burst that QEC won’t be able to correct. In order to successfully perform QEC, we first have to understand what these impact events look like on the processor, which requires operating it like a particle detector.
To do so, we take advantage of recent advances in qubit state preparation and measurement to quickly prepare each qubit in their excited state, similar to flipping a classical bit from 0 to 1. We then wait for a short idle time and measure whether they are still excited. If the qubits are behaving normally, almost all of them will be. Further, the qubits that experience a decay out of their excited state won’t be correlated, meaning the qubits that have errors will be randomly distributed over the chip.
However, during the experiment we occasionally observe large error bursts, where all the qubits on the chip suddenly become more error prone all at once. This correlated error burst is a clear signature of a high-energy impact event. We also see that, while all qubits on the chip are affected by the event, the qubits with the highest error rates are all concentrated in a “hotspot” around the impact site, where slightly more energy is deposited into the qubit layer by the spreading phonons.
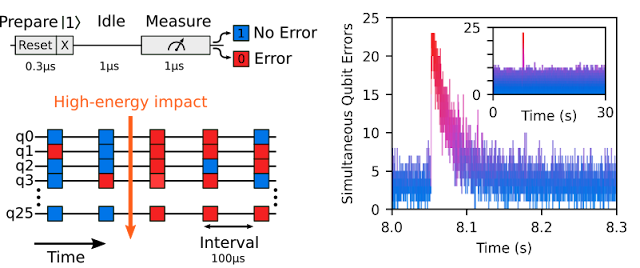 |
| To detect high-energy impacts, we rapidly prepare the qubits in an excited state, wait a little time, and then check if they’ve maintained their state. An impact produces a correlated error burst, where all the qubits show a significantly elevated error rate, as shown around time = 8 seconds above. |
Next Steps
Because these error bursts are severe and quickly cover the whole chip, they are a type of correlated error that QEC is unable to correct. Therefore, it’s very important to find a solution to mitigate these events in future processors that are expected to rely on QEC.
Shielding against these particles is very difficult and typically requires careful engineering and design of the cryostat and many meters of shielding, which becomes more impractical as processors grow in size. Another approach is to modify the chip, allowing it to tolerate impacts without causing widespread correlated errors. This is an approach taken in other complex superconducting devices like detectors for astronomical telescopes, where it’s not possible to use shielding. Examples of such mitigation strategies include adding additional metal layers to the chip to absorb phonons and prevent them from getting to the qubit, adding barriers in the chip to prevent phonons spreading over long distances, and adding traps for quasiparticles in the qubits themselves. By employing these techniques, future processors will be much more robust to these high-energy impact events.
As the error rates of quantum processors continue to decrease, and as we make progress in building a prototype of an error-corrected logical qubit, we’re increasingly pushed to study more exotic sources of error. While QEC is a powerful tool for correcting many kinds of errors, understanding and correcting more difficult sources of correlated errors will become increasingly important. We’re looking forward to future processor designs that can handle high energy impacts and enable the first experimental demonstrations of working quantum error correction.
Acknowledgements
This work wouldn’t have been possible without the contributions of the entire Google Quantum AI Team, especially those who worked to design, fabricate, install and calibrate the Sycamore processors used for this experiment. Special thanks to Rami Barends and Lev Ioffe, who led this project.




 The latest Nsight Systems 2022.1 release introduces several improvements aimed to enhance the profiling experience.
The latest Nsight Systems 2022.1 release introduces several improvements aimed to enhance the profiling experience. 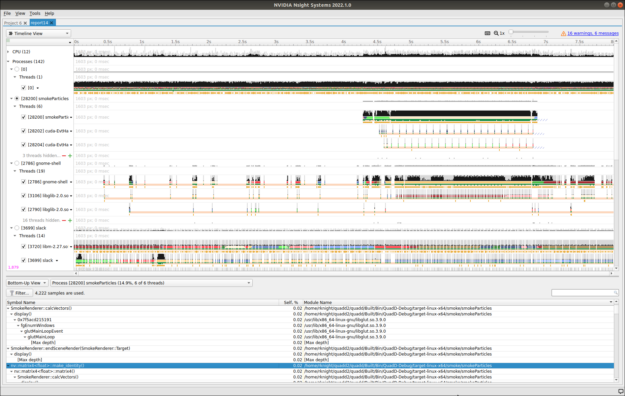
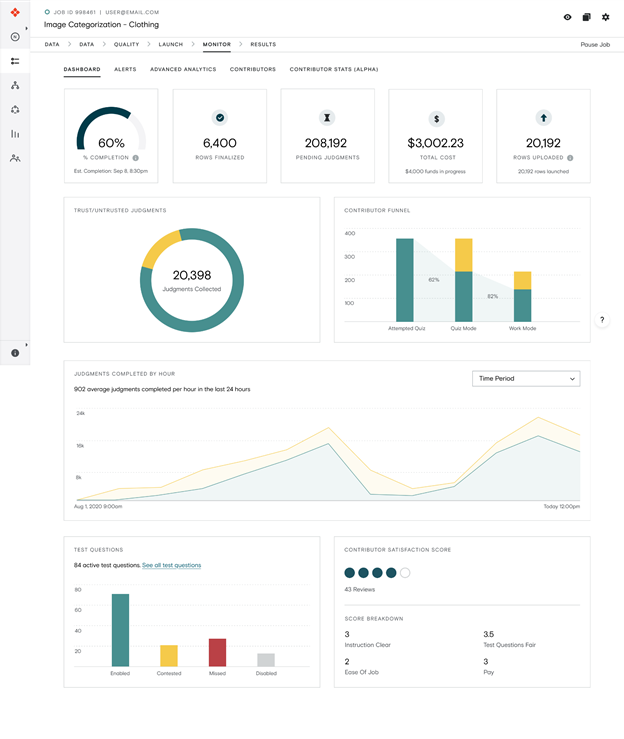
 Generating and labeling data to train AI models is time-consuming. Appen, helps label and annotate your data, which can then be used as inputs in the TAO Toolkit.
Generating and labeling data to train AI models is time-consuming. Appen, helps label and annotate your data, which can then be used as inputs in the TAO Toolkit.
{kind=link}