Hi, anyone have working example of regression with text and numerical features? I’m struggling to get good result with multiple type of input like this
submitted by /u/AccurateAd8373
[visit reddit] [comments]
 DataBloom
DataBloomHi, anyone have working example of regression with text and numerical features? I’m struggling to get good result with multiple type of input like this
submitted by /u/AccurateAd8373
[visit reddit] [comments]
 The early access version of the NVIDIA DOCA SDK was announced earlier this year at GTC. DOCA marks our focus on finding new ways to accelerate computing. The emergence of the DPU paradigm as the evolution of SmartNICs is finally here. We enable developers and application architects to squeeze more value out of general-purpose CPUs … Continued
The early access version of the NVIDIA DOCA SDK was announced earlier this year at GTC. DOCA marks our focus on finding new ways to accelerate computing. The emergence of the DPU paradigm as the evolution of SmartNICs is finally here. We enable developers and application architects to squeeze more value out of general-purpose CPUs … Continued
The early access version of the NVIDIA DOCA SDK was announced earlier this year at GTC. DOCA marks our focus on finding new ways to accelerate computing. The emergence of the DPU paradigm as the evolution of SmartNICs is finally here. We enable developers and application architects to squeeze more value out of general-purpose CPUs by accelerating, offloading, and isolating the data center infrastructure to the DPU.
One of the most important ways to think about DOCA is as the DPU-enablement platform. DOCA enables the rapid consumption of DPU features into new and existing data center software stacks.
A modern data center consists of much more than simple network infrastructure. The key to operationally efficient and scalable data centers is software. Orchestration, provisioning, monitoring, and telemetry are all software components. Even the network infrastructure itself is mostly a function of software. The network OS used on the network nodes determines the feature set and drives many downstream decisions around operation tools and monitoring.
We call DOCA a software framework with an SDK, but it’s more than that. An SDK is a great place to start when thinking about what DOCA is and how to consume it. One frequent source of confusion is where components run. Which DOCA components are required on the host, and which are required on the DPU? Under which conditions would you need the SDK compared to the runtime environment? What are the DOCA libraries, exactly?
For those new to DOCA, this post demystifies some of the complexity around the DOCA stack and packaging. First, I’d like to revisit some terms and refine what they mean in the DOCA context.
This is a software development kit. In context, this is what an application developer would need to be able to write and compile software using DOCA. It contains runtimes, libraries, and drivers. Not everyone needs everything that is packaged with or is typically part of the SDK.
In a strict sense, an SDK is more about packaging software components, but it is also used to describe most concisely (though not entirely accurately) how the industry should think about what DOCA is and how to consume it. DOCA is primarily meant for use by application developers.
This is the set of components required to run or execute a DOCA application. It contains the linked libraries and drivers that a DOCA application must have to run. In terms of packaging, it doesn’t need to contain the header files and sources to be able to write and build (compile) applications. DOCA applications can be written and built for either x86 or Arm, so there are different runtime bundles for each architecture.
There are two different contexts here. In the broader and more general context, a library is a collection of resources used by applications. Library resources may include all sorts of data such as configuration, documentation, or help data; message templates; prewritten code; and subroutines, classes, values, or type specifications.
In the context of DOCA, libraries also provide a collection of more functional and useful behavior implementations. They provide well-defined interfaces by which that behavior is invoked.
For instance, the DOCA DPI library provides a framework for inspecting and acting on the contents of network packets.
To write a DPI application using the DPU RegEx accelerator from scratch would be a lot of work. You’d have to write all the preprocessing and postprocessing routines to parse packet headers and payload and then write a process to compile RegEx rules for the high-speed lookup on the accelerator.
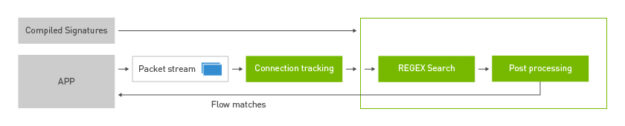
Device drivers provide an interface to a hardware device. This bit of software is the lowest level of abstraction. DOCA provides an additional layer of abstraction for the specific hardware functions of the DPU. This way, as the DPU hardware evolves, changes to the underlying hardware will not require DOCA applications to also update to follow new or different driver interfaces.
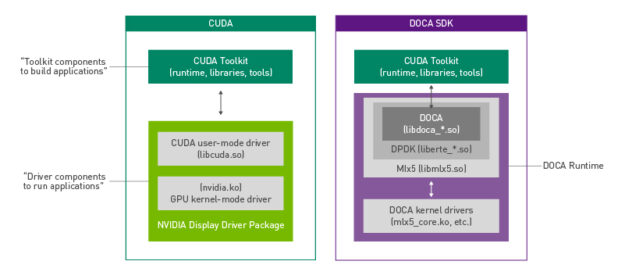
Another useful way to think about DOCA packaging is through its similarities to CUDA. The DOCA runtime is meant to include all the drivers and libraries in a similar vein to what the NVIDIA display driver package provides for CUDA.
Applications that must invoke CUDA libraries for GPU processing only need the NVIDIA display driver package installed. Likewise, DOCA applications need only the runtime package for the specific architecture. In both cases, you have an additional set of packages and tools for integrating GPU or DPU functionality and acceleration into applications.
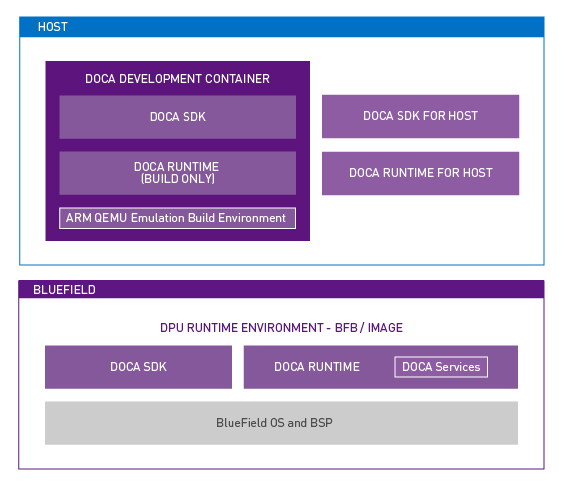
Another complicating factor can be sorting out which DOCA components are required on which platform. After all, the DPU runs its own OS, but also presents itself as a peripheral to the host OS.
DOCA applications can run on either the x86 host or on the DPU Arm cores. DOCA applications running on the x86 host are intended to use the DPU acceleration features through DOCA library calls. In terms of packaging, different OSs can mean different installation procedures for all these components, but luckily this isn’t as confusing as it seems for administrators.
For the NVIDIA BlueField DPU, all the runtime and SDK components are bundled with the OS image. It is possible to write, build, and compile DOCA applications on the DPU for rapid testing. All the DOCA components are there, but that isn’t always an ideal development environment. Having the SDK components built in and included with the DPU OS image makes it easier for everyone as it is the superset that contains the runtime components.
For the x86 host, there are many more individual components to consider. The packages that an administrator needs on the host depends, again, primarily on whether this host is a development environment or build server, and for which architecture. Or will the host run and execute applications that invoke DOCA libraries?
For x86 hosts destined to serve as a development environment, there is one additional consideration. For the development of DOCA applications that will run on x86 CPUs, an administrator needs the native x86 DOCA SDK for host packages. For developing Arm applications from an x86 host, NVIDIA has a prebuilt DOCA development container that manages all those cross-platform complexities.
In the simplest case for x86 hosts that only run or execute applications using DOCA, that’s what the DOCA Runtime for Host package would satisfy. It contains the minimum set of components to enable applications written using DOCA libraries to properly execute on the target machine. Figure 3 shows the different components across the two different OS domains.
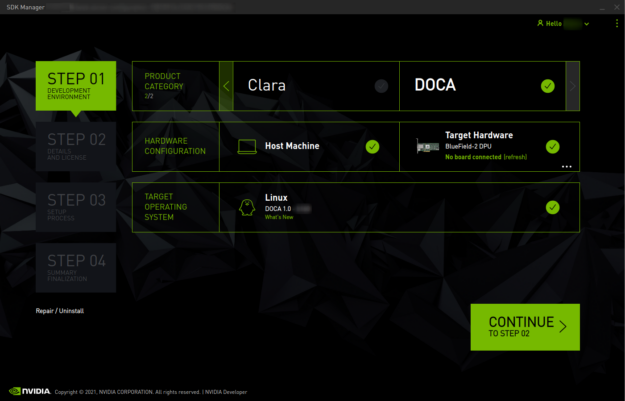
Now that I’ve explained how all that packaging works on the x86 host, I should mention that you have an easy way to get the right components installed in the right places. NVIDIA SDK Manager reduces the time and effort required to manage this packaging complexity. SDK Manager can not only install or repair the SDK components on the host but can also detect and install the OS onto the BlueField DPU, all through a graphical interface. Piece of cake!
Hopefully, this post goes a long way in helping you understand and demystify DOCA and its packaging. To download DOCA software and get started, see the NVIDIA DOCA developer page.
 Recreate the past with the new NVIDIA Omniverse retro design challenge.
Recreate the past with the new NVIDIA Omniverse retro design challenge.
Now’s your chance to use technologies of the future to recreate the past, with the new NVIDIA Omniverse Enter the Retroverse: A Graphics Flashback design challenge.
For this contest, we are asking creators to build and design their gaming space from the past—whether it’s a living room, bedroom, college dorm, or another area. The final submission can be big or small. Meaning you can create an entire room, or assemble a detailed close-up of a floor or desk from a space that inspired your passion for gaming or computer graphics.



Creators must use Omniverse to design the 3D space in a retro style from the 80s, 90s, or 2000s. NVIDIA is collaborating with TurboSquid by Shutterstock, a leading 3D marketplace, to provide pre-made assets of consoles.
Participants can use any of the pre-selected assets from TurboSquid to build and design their space. Feel free to re-texture the assets, or even model the classic consoles or PCs from scratch.
Use any 3D software, workflow, or Connector to assemble the retro scene, creating the final render in Omniverse Create.
Entries will be judged on various criteria, including the use of Omniverse Create, the quality of the final render, and overall originality.
The top three entries will receive an NVIDIA RTX A6000, GeForce RTX 3090, and GeForce RTX 3080 GPU, respectively.
The winners of the contest will be announced at our GTC conference in November.
Learn more about the Retroverse contest and start creating in Omniverse today. Share your submission on Twitter and Instagram by tagging @NVIDIAOmniverse with #CreateYourRetroverse.
For support and tips on how to get started, watch these tutorials, get help from Omniverse experts in the contest forum, and join our Discord server.
Dancing is a universal language found in nearly all cultures, and is an outlet many people use to express themselves on contemporary media platforms today. The ability to dance by composing movement patterns that align to music beats is a fundamental aspect of human behavior. However, dancing is a form of art that requires practice. In fact, professional training is often required to equip a dancer with a rich repertoire of dance motions needed to create expressive choreography. While this process is difficult for people, it is even more challenging for a machine learning (ML) model, because the task requires the ability to generate a continuous motion with high kinematic complexity, while capturing the non-linear relationship between the movements and the accompanying music.
In “AI Choreographer: Music-Conditioned 3D Dance Generation with AIST++”, presented at ICCV 2021, we propose a full-attention cross-modal Transformer (FACT) model can mimic and understand dance motions, and can even enhance a person’s ability to choreograph dance. Together with the model, we released a large-scale, multi-modal 3D dance motion dataset, AIST++, which contains 5.2 hours of 3D dance motion in 1408 sequences, covering 10 dance genres, each including multi-view videos with known camera poses. Through extensive user studies on AIST++, we find that the FACT model outperforms recent state-of-the-art methods, both qualitatively and quantitatively.
 |
 |
| We present a novel full-attention cross-modal transformer (FACT) network that can generate realistic 3D dance motion (right) conditioned on music and a new 3D dance dataset, AIST++ (left). |
We generate the proposed 3D motion dataset from the existing AIST Dance Database — a collection of videos of dance with musical accompaniment, but without any 3D information. AIST contains 10 dance genres: Old School (Break, Pop, Lock and Waack) and New School (Middle Hip-Hop, LA-style Hip-Hop, House, Krump, Street Jazz and Ballet Jazz). Although it contains multi-view videos of dancers, these cameras are not calibrated.
For our purposes, we recovered the camera calibration parameters and the 3D human motion in terms of parameters used by the widely used SMPL 3D model. The resulting database, AIST++, is a large-scale, 3D human dance motion dataset that contains a wide variety of 3D motion, paired with music. Each frame includes extensive annotations:
The motions are equally distributed among all 10 dance genres, covering a wide variety of music tempos in beat per minute (BPM). Each genre of dance contains 85% basic movements and 15% advanced movements (longer choreographies freely designed by the dancers).
The AIST++ dataset also contains multi-view synchronized image data, making it useful for other research directions, such as 2D/3D pose estimation. To our knowledge, AIST++ is the largest 3D human dance dataset with 1408 sequences, 30 subjects and 10 dance genres, and with both basic and advanced choreographies.
 |
| An example of a 3D dance sequence in the AIST++ dataset. Left: Three views of the dance video from the AIST database. Right: Reconstructed 3D motion visualized in 3D mesh (top) and skeletons (bottom). |
Because AIST is an instructional database, it records multiple dancers following the same choreography for different music with varying BPM, a common practice in dance. This posits a unique challenge in cross-modal sequence-to-sequence generation as the model needs to learn the one-to-many mapping between audio and motion. We carefully construct non-overlapping train and test subsets on AIST++ to ensure neither choreography nor music is shared across the subsets.
Full Attention Cross-Modal Transformer (FACT) Model
Using this data, we train the FACT model to generate 3D dance from music. The model begins by encoding seed motion and audio inputs using separate motion and audio transformers. The embeddings are then concatenated and sent to a cross-modal transformer, which learns the correspondence between both modalities and generates N future motion sequences. These sequences are then used to train the model in a self-supervised manner. All three transformers are jointly learned end-to-end. At test time, we apply this model in an autoregressive framework, where the predicted motion serves as the input to the next generation step. As a result, the FACT model is capable of generating long range dance motion frame-by-frame.
 |
| The FACT network takes in a music piece (Y) and a 2-second sequence of seed motion (X), then generates long-range future motions that correlate with the input music. |
FACT involves three key design choices that are critical for producing realistic 3D dance motion from music.
Results
We evaluate the performance based on three metrics:
Motion Quality: We calculate the Frechet Inception Distance (FID) between the real dance motion sequences in the AIST++ test set and 40 model generated motion sequences, each with 1200 frames (20 secs). We denote the FID based on the geometric and kinetic features as FIDg and FIDk, respectively.
Generation Diversity: Similar to prior work, to evaluate the model’s ability to generate divers dance motions, we calculate the average Euclidean distance in the feature space across 40 generated motions on the AIST++ test set, again comparing geometric feature space (Distg) and in the kinetic feature space (Distk).
 |
| Four different dance choreographies (right) generated using different music, but the same two second seed motion (left). The genres of the conditioning music are: Break, Ballet Jazz, Krump and Middle Hip-hop. The seed motion comes from hip-hop dance. |
Motion-Music Correlation: Because there is no well-designed metric to measure the correlation between input music (music beats) and generated 3D motion (kinematic beats), we propose a novel metric, called Beat Alignment Score (BeatAlign).
 |
| Kinetic velocity (blue curve) and kinematic beats (green dotted line) of the generated dance motion, as well as the music beats (orange dotted line). The kinematic beats are extracted by finding local minima from the kinetic velocity curve. |
Quantitative Evaluation
We compare the performance of FACT on each of these metrics to that of other state-of-the-art methods.
 |
| Compared to three recent state-of-the-art methods (Li et al., Dancenet, and Dance Revolution), the FACT model generates motions that are more realistic, better correlated with input music, and more diversified when conditioned on different music. *Note that the Li et al. generated motions are discontinuous, making the average kinetic feature distance abnormally high. |
We also perceptually evaluate the motion-music correlation with a user study in which each participant is asked to watch 10 videos showing one of our results and one random counterpart, and then select which dancer is more in sync with the music. The study consisted of 30 participants, ranging from professional dancers to people who rarely dance. Compared to each baseline, 81% prefered the FACT model output to that of Li et al., 71% prefered FACT to Dancenet, and 77% prefered it Dance Revolution. Interestingly, 75% of participants preferred the unpaired AIST++ dance motion to that generated by FACT, which is unsurprising since the original dance captures are highly expressive.
Qualitative Results
Compared with prior methods like DanceNet (left) and Li et. al. (middle), 3D dance generated using the FACT model (right) is more realistic and better correlated with input music.

More generated 3D dances using the FACT model.
 |
 |
 |
 |
Conclusion and Discussion
We present a model that can not only learn the audio-motion correspondence, but also can generate high quality 3D motion sequences conditioned on music. Because generating 3D movement from music is a nascent area of study, we hope our work will pave the way for future cross-modal audio to 3D motion generation. We are also releasing AIST++, the largest 3D human dance dataset to date. This proposed, multi-view, multi-genre, cross-modal 3D motion dataset can not only help research in the conditional 3D motion generation research but also human understanding research in general. We are releasing the code in our GitHub repository and the trained model here.
While our results show a promising direction in this problem of music conditioned 3D motion generation, there are more to be explored. First, our approach is kinematic-based and we do not reason about physical interactions between the dancer and the floor. Therefore the global translation can lead to artifacts, such as foot sliding and floating. Second, our model is currently deterministic. Exploring how to generate multiple realistic dances per music is an exciting direction.
Acknowledgements
We gratefully acknowledge the contribution of other co-authors, including Ruilong Li and David Ross. We thank Chen Sun, Austin Myers, Bryan Seybold and Abhijit Kundu for helpful discussions. We thank Emre Aksan and Jiaman Li for sharing their code. We also thank Kevin Murphy for the early attempts in this direction, as well as Peggy Chi and Pan Chen for the help on user study experiments.

Imagine you’re sitting in Discord chat, telling your buddies about the last heroic round of your favorite game, where you broke through the enemy’s defenses and cinched the victory on your own. Your friends think you’re bluffing and demand proof. With GeForce NOW’s content capture tools running automatically in the cloud, you’ll have all the Read article >
The post How to Use NVIDIA Highlights, Freestyle and Montage in GeForce NOW appeared first on The Official NVIDIA Blog.
Hi all, i am struggeling to get Tensorflow-Lite running on a Raspberry Pi 4. The problem is that the model (BirdNET-Lite on GitHub) uses one special operator from Tensorflow (RFFT) which has to be included. I would rather use a prebuilt bin than compiling myself. I have found the prebuilt bins from PINTO0309 in GitHub but don’t understand if they would be useable or if i have to look somewhere else. BirdNET is a software to identify birds by their sounds, and also a really cool (and free) app. Many thanks!
submitted by /u/FalsePlatinum
[visit reddit] [comments]
Hi, I thought this would be the right place to ask.
I have a python program that uses an audio and image classification, would I be able to convert them and use them on mobile?
If so what language would be best for the mobile application.
Thanks.
submitted by /u/why________________
[visit reddit] [comments]
A one liner : For the DevOps nerds, AutoDeploy allows configuration based MLOps.
For the rest : So you’re a data scientist and have the greatest model on planet earth to classify dogs and cats! :). What next? It’s a steeplearning cusrve from building your model to getting it to production. MLOps, Docker, Kubernetes, asynchronous, prometheus, logging, monitoring, versioning etc. Much more to do right before you The immediate next thoughts and tasks are
What if you could only configure a single file and get up and running with a single command. That is what AutoDeploy is!
Read our documentation to know how to get setup and get to serving your models.
Feature Support.
submitted by /u/kartik4949
[visit reddit] [comments]
AI is at play on a global stage, and local developers are stealing the show. Grassroot communities are essential to driving AI innovation, according to Kate Kallot, head of emerging areas at NVIDIA. On its opening day, Kallot gave a keynote speech at the largest AI Expo Africa to date, addressing a virtual crowd of Read article >
The post The Bright Continent: AI Fueling a Technological Revolution in Africa appeared first on The Official NVIDIA Blog.
The transportation industry is adding more torque toward realizing autonomy, electrification and sustainability. That was a key takeaway from Germany’s premier auto show, IAA Mobility 2021 (Internationale Automobil-Ausstellung), which took place this week in Munich. The event brought together leading automakers, as well as execs at companies that deliver mobility solutions spanning from electric vehicles Read article >
The post Autonomy, Electrification, Sustainability Take Center Stage at Germany’s IAA Auto Show appeared first on The Official NVIDIA Blog.