Currently I’m trying to load some images for training purpose, here is what i’m currently doing
sats = [np.array(Image.open(cdir + "/x/" + name).convert('RGB'),dtype="float32") for name in names] masks = [np.array(Image.open(cdir + "/y/" + name),dtype="float32") for name in names]
But this takes almost all space in colab, when running on the full dataset. So my question is can I use a better api, which will partially load data, so I don’t run out of memory ?
When you are working on optimizing inference scenarios for the best performance, you may underestimate the effect of data preprocessing. These are the operations required before forwarding an input sample through the model. This post highlights the impact of the data preprocessing on inference performance and how you can easily speed it up on the … Continued
When you are working on optimizing inference scenarios for the best performance, you may underestimate the effect of data preprocessing. These are the operations required before forwarding an input sample through the model. This post highlights the impact of the data preprocessing on inference performance and how you can easily speed it up on the GPU, using NVIDIA DALI and NVIDIA Triton Inference Server.
Does preprocessing matter?
Regardless of a particular model that you want to run inference on, some degree of data preprocessing is required. In computer vision applications, the input operations usually include decoding, resizing, and normalizing to a standardized format accepted by the neural network. Speech recognition models, on the other hand, may require calculating certain features, like a spectrogram, and some raw audio sample processing, such as pre-emphasis and dithering.
Often, preprocessing routines that you use for inference are similar to the ones used as an input pipeline for the model training. Implementing both using the same tools can save you some boilerplate and code repetition. Ensuring that the preprocessing operations used for inference are defined identically as they were when the model was trained is key to achieving high accuracy.
The more complicated a preprocessing pipeline is for a given model, the bigger fraction of the entire inference time that it takes. It means that accelerating only the network processing time does not yield proportional improvement in overall inference latency. This is especially true if you use CPU to prepare data before feeding it to the model.
What is NVIDIA DALI?
DALI is a data loading and preprocessing library to build highly optimized custom data processing pipelines used in deep learning applications. The set of operations that can be found in DALI includes, but is not limited to, data loading, decoding multiple formats of image, video, and audio, as well as a wide range of processing operators.
Figure 1. NVIDIA DALI workflow.
What makes DALI performant is that it offloads most of preprocessing computation to the GPU. It processes the whole batch of data at one time rather than running operators sample by sample, using the parallel nature of GPU computations. Because of that, DALI is successfully used to accelerate the training of many deep learning models in production. For more information, see the following posts:
Another advantage of DALI is its portability. After it’s defined, a pipeline can be used with most of the popular deep learning frameworks, namely TensorFlow, PyTorch, MXNet, and Paddle Paddle. However, the DALI utility is not limited to training. After you have trained your model with DALI as a preprocessing library, you can use the corresponding data processing pipeline for inference.
Triton model ensembles
Triton Inference Server greatly simplifies the deployment of AI models at scale in production. It is an open-source software that provides support for multiple backends that can run your neural network inference. However, running an inference may require more complex pipelines that also include preprocessing and postprocessing stages. All steps are not always all present, but whenever your use case includes more than just calculating the output of a neural network, Triton Server comes with a convenient solution that simplifies building such pipelines.
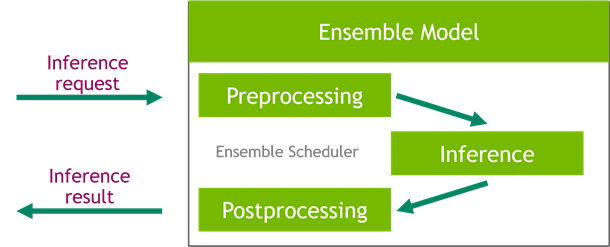
Among many useful scheduling mechanisms that the Triton Server platform provides is the ensemble scheduler, which is responsible for pipelining models participating in the inference process while ensuring efficiency and optimizing throughput.
Figure 2. Triton model ensemble scheme.
Using ensembles in Triton Server is easy and requires only preparing a single additional configuration file with a description of the pipeline. This file serves as a definition of a special ensemble model that is a facade encapsulating the whole inference process. With such a setup, you can send requests directly to the ensemble model, which hides the complexity of the pipeline. This can also reduce the communication overhead as the preprocessed data already resides on the GPU that is used to run the inference.
Introducing DALI backend
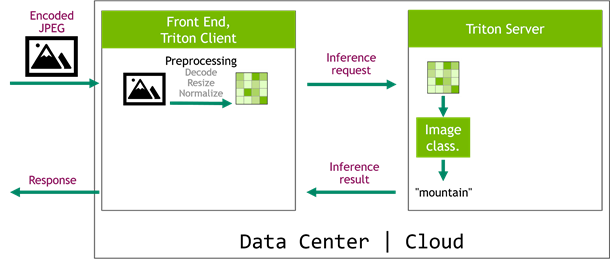
Here’s a real-life example: an image classification system. A picture is captured on the edge device and is sent to a frontend service. The frontend delegates inference to Triton Server that runs an image classification network, for example Inception v3. Typically, such networks require a decoded, normalized, and resized image as an input. Running those operations inside the client service (Figure 3) is time-consuming. On top of that, the decoded images increase network traffic, as they are bigger than the encoded images (Table 1). Still, this solution might be tempting, as it is easy to implement with popular libraries like OpenCV.
Resolution
Decoded image
Preprocessed image for Inception v3
Encoded image
720p
3.1 MB
1 MB
500 kB
1080p
6.2 MB
1 MB
700 kB
Table 1. Size comparison of the images for giver resolution. The encoded image size depends highly on its content and compression type.
Figure 3. Triton Server inference with client preprocessing.
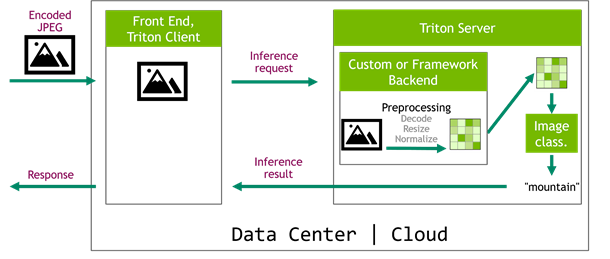
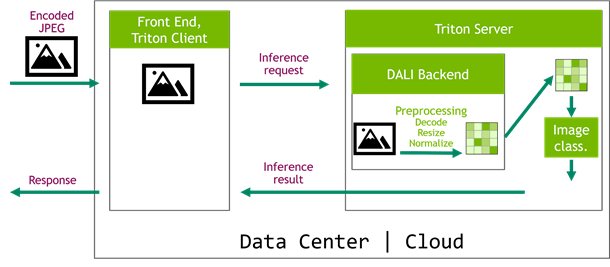
On the other hand, a significantly more performant scenario is the one that implements the preprocessing pipeline as a Triton Server backend (Figure 4). In this case, you can take advantage of the GPUs that are already used by the server. The role of the frontend service is now reduced to handling requests from edge devices and sending encoded images directly to Triton Server. This simplifies the architecture of the cloud system as all computationally intensive tasks are moved to the Triton Server, which can be easily scaled later.
The preprocessing part could be implemented as a custom backend but that is quite complicated and low-level. It can also be written in one of the frameworks supported by Triton Server. However, if you’ve already have trained your network using the DALI input pipeline, you would probably like to reuse this code for inference.
Figure 4. Triton Server inference with server-side preprocessing using a custom or framework backend.
This is where the DALI backend comes in handy. Although DALI was initially designed to remove the preprocessing bottleneck during training, some of the features also come in handy in inference. In the image classification example, you put together a model ensemble, where the first step decodes, resizes, and normalizes the images using DALI GPU operators and sends the input data straight to the inference step (Figure 5).
Figure 5. Triton Server inference with server preprocessing using the DALI backend.
Image classification using Inception v3
How do you obtain a DALI model and put it into the model repository? Look at an example from the DALI backend repository.
Inception v3 is an example of an image classification neural network. All three of the preprocessing operations needed by this model (JPEG decoding, resizing, and normalizing) are good candidates for GPU parallelization. In DALI, they are GPU-powered.
The DALI model is going to be a part of the model ensemble. The following example shows the model repository directory structure, containing a DALI preprocessing model, TensorFlow Inception v3 model, and the model ensemble:
The remaining question is where to get the model.dali file from? This file contains a serialized DALI pipeline that you can get by calling the serialize method on a DALI pipeline instance. The following code example is the DALI preprocessing pipeline for the Inception example:
The code is rather straightforward. Note the presence of a fn.external_source operator; it’s a placeholder later used by Triton Server to provide data to the pipeline. You must also remember to set the name of fn.external_source the same way that you named the input in the DALI config.pbtxt file. For more information about building DALI pipelines, see NVIDIA DALI Documentation.
Performance results
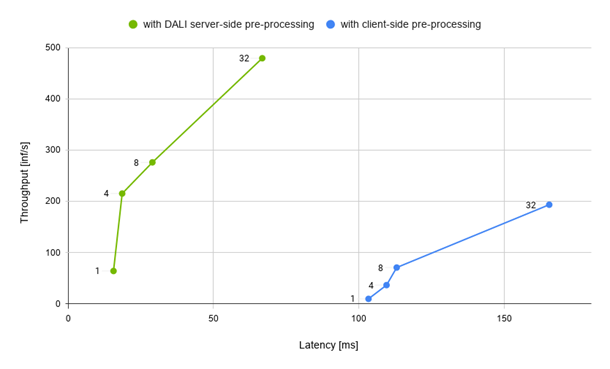
So how does the performance look? Figure 6 compares two Inception setup scenarios:
Client preprocessing: Samples are decoded, resized, and normalized in parallel using OpenCV.
Server preprocessing: The Python client script sends encoded images to the server, where the whole DALI preprocessing happens.
Figure 6. Throughput vs. latency plots for both scenarios with batches of size 1, 4, 8, 32. The more to the left and to the top, the better the result is. The performance results were collected on a DGX A100 machine.
Using DALI gives you significant leverage over client preprocessing. Figure 6 shows that DALI gives significantly better performance results both in terms of overall latency and throughput. This is possible thanks to the fact that DALI takes advantage of full GPU compute capabilities, such as the hardware JPEG decoder. Another important factor is the communication overhead. An example JPEG image used in the inference with the resolution of 1280×720 is about 306 kB whereas the same image after preprocessing yields a tensor that has about 1048 kB. This means that sending preprocessed data might cause about 3x the network traffic.
Naturally, the results differ according to your specific use case and your infrastructure. However, using DALI for preprocessing data in your inference scenario is worth a try.
How to get the DALI backend?
Starting from tritonserver:20.11-py3, DALI Backend is included in the Triton Server Docker container. Just download the latest version and you’re good to go. Moreover DALI, Triton Server, and the DALI backend for Triton Server are all open-source projects so that you can build the most up-to-date versions from source.
Whether helping the world understand our most immediate threats, like COVID-19, or seeing the future of landing humans on Mars, researchers are increasingly leaning on scientific visualization to analyze, understand and extract scientific insights. With large-scale simulations generating tens or even hundreds of terabytes of data, and with team members dispersed around the globe, researchers Read article >
Data science development faces many challenges in the areas of: Exploration and model development Training and evaluation Model scoring and inference Some estimates point to 70%-90% of the time is spent on experimentation – much of which will run fast and efficiently on GPU-enabled mobile and desktop workstations. Running on a Linux mobile workstation, for … Continued
Data science development faces many challenges in the areas of:
Exploration and model development
Training and evaluation
Model scoring and inference
Some estimates point to 70%-90% of the time is spent on experimentation – much of which will run fast and efficiently on GPU-enabled mobile and desktop workstations. Running on a Linux mobile workstation, for example, presents another set of challenges – including installing and configuring a data science stack, stack updates, driver installation and updates, support for needed Office productivity apps, and no easy or intuitive way to access helpful tools and software to accelerate development.
New Data Science Client and WSL2 to the rescue!
In a GTC Live session, Dima Rekesh, Karan Jhavar, and myself will discuss a new Data Science Client (DSC) and support for Windows Subsystem for Linux 2 (WSL2) to address the previously stated challenges. This makes it even more practical to run countless experiments locally before model training at scale, but also removes the complexities of a local data science stack while having compatibility with popular Microsoft Office applications.
When data scientists want or need unlimited experimentation for creativity and better models overall, The NVIDIA DSC is designed to make developers productive faster while providing simple access to common tools and frameworks (e.g. – Jupyter Notebooks, RAPIDS, etc.) to make data science development on workstations easier and more productive.
If you’d like to learn more, we encourage you to register for the NVIDIA GTC Conference and attend the LIVE session:
Note: For those not familiar with the NVIDIA Data Science Stack, it provides you with a complete system for the software you utilize every day. It’s pre-installed and tuned for NVIDIA GPUs. Included on pre-installed Ubuntu 20.04 Linux OS is Python 3.8, pandas, numpy, scipy, numba, scikit-learn, Tensorflow, PyTorch, Keras , RAPIDS (cudf, cuml, cugraph), cupy and many more. There is GPU accelerated python software that speeds up machine learning tasks 10x-30x faster. Examples include common ML algorithms, K-means, logistical and linear regression, KNN, Random Forest Classifier, and XGBoost Classifier using NVIDIA RAPIDS. Cuml is fully GPU accelerated and accepts CSV spreadsheet data or Parquet file formats.
More about the Data Science Client (DSC)
NVIDIA Data Science Client (DSC) is currently a Beta release and runs on your desktop as a status bar icon. It is optimized to use few system resources and monitors and updates itself, your NVIDIA Driver, CUDA SDK (including cuDNN), and all the Data Science Stack software described above. A GA released version of the DSC is expected late 2021.
DSC is a desktop complement of the command line-oriented data science stack. DSC is minimalist and unobtrusive. It is designed to target ease of use and reproducibility. The DSC also provides one-click access to common tools such as VS Code and Spyder, but places emphasis on Jupyter as the main development environment supporting a curated set of dockerized kernels – the majority of which are available as NGC assets.
The DSC also manages the latest set of NVIDIA GPU Cloud (NGC) containers. You can quickly launch NGC containers for RAPIDS/PyTorch/Tensorflow into a locally running Juypter notebook server as a tab in your Chrome browser in milliseconds. DSC and NVIDIA Data Science Stack (DSS) are running the same software you run in a VM in the Cloud. This gives confidence that the python source code developed on your NVIDIA GPU workstation or mobile will run everywhere with predictable results.
Learn more details about the Data Science Client (DSC) and how to download it.
Windows Subsystem for Linux 2 (WSL2) support
This is available now as part of a Public Preview running on pre-released versions of WIN10. Utilizing WSL2 is a technology that allows Windows desktop users to run a Linux OS shell. NVIDIA enabled CUDA to run at full performance in the WSL2 shell. NVIDIA is testing RAPIDS and the entire suite of Data Science Stack software with WSL2.
WSL2 means that my data science Python software including Juypter notebook plus Office Productivity software tools (Excel,Outlook, PowerPoint, etc..) run in a single-booted Windows 10 image. There is no longer a need for dual boot.
Data science workstations in action
NVIDIA knows of many data science workloads that run exceptionally well on mobile workstations built on the NVIDIA Data Science Stack. Some of these environments and workloads will be demonstrated in the following GTC21 sessions:
Machine Learning with PyTorch Lightning and Grid.ai from Your GPU Enabled Workstation [S32153]
From Laptops to SuperPODs: Seamless Scale for Model Development [S32160]
Eliminating Reproducibility and Portability Issues for Data Science Workflows, from Laptop to Cloud and Back [S32169]
Collaborative Debugging and Visualizing of Machine Learning Models on NVIDIA Workstations [S32156]
We have also seen many new and innovative deep learning workloads such as Heartex Label Studio that run well on mobile workstations.
As businesses extend the power of AI and data science to every developer, IT needs to deliver seamless, scalable access to supercomputing with cloud-like simplicity and security. At GTC21, we introduced the latest NVIDIA DGX SuperPOD, which gives business, IT and their users a platform for securing and scaling AI across the enterprise, with the Read article >
Applying for a home mortgage can resemble a part-time job. But whether consumers are seeking out a home loan, car loan or credit card, there’s an incredible amount of work going on behind the scenes in a bank’s decision — especially if it has to say no. To comply with an alphabet soup of financial Read article >
The factories of the future will have a soul — a “digital twin” that blends man and machine in stunning new ways. In a demo blending reality and virtual reality, robotics and AI, to manage one of BMW’s automotive factories, NVIDIA CEO Jensen Huang Monday rolled out a stunning vision of the future of manufacturing. Read article >
Breakthroughs in 3D model visualization, such as real-time ray–traced rendering and immersive virtual reality, are making architecture and design workflows faster, better and safer. At GTC this week, NVIDIA announced the newest advances for the AEC industry with the latest NVIDIA Ampere architecture-based enterprise desktop RTX GPUs, along with an expanded range of mobile laptop GPUs. AEC professionals will also want to learn more about NVIDIA Omniverse Enterprise, an open platform Read article >
NVIDIA technology has been behind some of the world’s most stunning virtual reality experiences. Each new generation of GPUs has raised the bar for VR environments, producing interactive experiences with photorealistic details to bring new levels of productivity, collaboration and fun. And with each GTC, we’ve introduced new technologies and software development kits that help Read article >
Developers can use cuQuantum to speed up quantum circuit simulations based on state vector, density matrix, and tensor network methods by orders of magnitude.
Quantum computing has the potential to offer giant leaps in computational capabilities. Until it becomes a reality, scientists, developers, and researchers are simulating quantum circuits on classical computers.
NVIDIA cuQuantum is an SDK of optimized libraries and tools for accelerating quantum computing workflows. Developers can use cuQuantum to speed up quantum circuit simulations based on state vector, density matrix, and tensor network methods by orders of magnitude.
The research community – including academia, laboratories, and private industry – are all using simulators to help design and verify algorithms to run on quantum computers. These simulators capture the properties of superposition and entanglement and are built on quantum circuit simulation frameworks including Qiskit, Cirq, ProjectQ, Q#, etc.
We showcase accelerated quantum circuit simulation results based on industry estimations, extrapolations, and benchmarks on real-world computers like ORNL’s Summit, and NVIDIA’s Selene, and reference collaborations with numerous industry partners.
“Using the Cotengra/Quimb packages, NVIDIA’s new cuQUANTUM SDK, and the Selene supercomputer, we’ve generated a sample of the Sycamore quantum circuit at depth=20 in record time (less than 10 minutes). This sets the benchmark for quantum circuit simulation performance and will help advance the field of quantum computing by improving our ability to verify the behavior of quantum circuits.”
Johnnie Gray, Research Scientist, Caltech Garnet Chan, Bren Professor of Chemistry, Caltech
Learn more about cuQuantum, our latest benchmark results, and apply for early interest today here.

 When you are working on optimizing inference scenarios for the best performance, you may underestimate the effect of data preprocessing. These are the operations required before forwarding an input sample through the model. This post highlights the impact of the data preprocessing on inference performance and how you can easily speed it up on the …
When you are working on optimizing inference scenarios for the best performance, you may underestimate the effect of data preprocessing. These are the operations required before forwarding an input sample through the model. This post highlights the impact of the data preprocessing on inference performance and how you can easily speed it up on the … 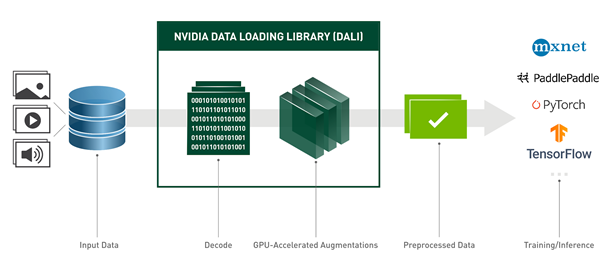
 Data science development faces many challenges in the areas of: Exploration and model development Training and evaluation Model scoring and inference Some estimates point to 70%-90% of the time is spent on experimentation – much of which will run fast and efficiently on GPU-enabled mobile and desktop workstations. Running on a Linux mobile workstation, for …
Data science development faces many challenges in the areas of: Exploration and model development Training and evaluation Model scoring and inference Some estimates point to 70%-90% of the time is spent on experimentation – much of which will run fast and efficiently on GPU-enabled mobile and desktop workstations. Running on a Linux mobile workstation, for …  Developers can use cuQuantum to speed up quantum circuit simulations based on state vector, density matrix, and tensor network methods by orders of magnitude.
Developers can use cuQuantum to speed up quantum circuit simulations based on state vector, density matrix, and tensor network methods by orders of magnitude.