 Notable sessions in the making of Green Planet AR, animating realistic digital humans, building a power industry digital twin, and making virtual production more accessible.
Notable sessions in the making of Green Planet AR, animating realistic digital humans, building a power industry digital twin, and making virtual production more accessible.
Looking for different topic areas? Keep an eye out for our other posts!
Join us at GTC, March 21-24, to explore the latest technology and research across AI, computer vision, data science, robotics, and more!
With over 900 options to choose from, our NVIDIA experts put together some can’t-miss sessions to help get you started:
AR / VR
How to Design Collaborative AR and VR worlds in Omniverse
Omer Shapira, Senior Engineer, Omniverse, NVIDIA
This session introduces Omniverse XR and is led by the engineer building this solution. Omer Shapira will discuss Omniverse’s real-time ray-traced XR renderer, Omniverse’s Autograph system for visual programming, and show how customers are using Omniverse’s XR tools to do everything together—from design reviews to hangouts.
NVIDIA’s New Tools and SDKs for XR Development
Ingo Esser, Principal Developer Technology Engineer, NVIDIA
Peter Pang, Senior Product Manager, NVIDIA
Jason Mawdsley, Director, AI Gaming and Head of AI Gaming Products, NVIDIA
Tion Thomas, RTXGI SDK Producer, NVIDIASirisha Rella, Product Marketing Manager, NVIDIA
Stephanie Rubenstein, Product Marketing Manager, NVIDIA
Experts across the NVIDIA SDK teams are presenting the latest updates and best practices for DLSS, RTXGI, and Riva in XR development. They are also introducing the new VR Capture and Replay tool, which is being released at GTC as early access.
Bring the Green Planet into Your Hands with 5G, AR, and Edge Compute
Stephen Stewart, CTO, Factory 42
This session is a great example of how AR experiences can encourage positive change. Learn how NVIDIA CloudXR helped deliver an innovative mobile AR experience, through a 5G private network, to thousands of people in Piccadilly Circus, London. Deep dive into the challenges of bringing the natural worlds in the Green Planet AR experience—inspired by the BBC’s Green Planet TV series—into the hands of so many people.
Rendering
Connect with the Experts: Getting Started with Ray Tracing and NVIDIA’s Ray Tracing Developer Tools
Aurelio Reis, Director, Graphics Developer Tools, NVIDIA
Jeffrey Kiel, Senior Engineering Manager, Graphics Developer Tools, NVIDIA
Aurelio Reis and Jeff Kiel bring more than 35 years of combined experience building graphics developer tools. This includes real-time ray-tracing solutions such as Nsight Graphics, making this a great session for developers to get their questions answered directly from the team developing the tools.
The Making of Unity’s Latest Flagship Demo, An Achievement in Graphics and Rendering
Mark Schoennagel, Senior Developer Advocate, Unity
Mark Schoennegal has lived through the renaissance of the 3D industry, from the first ray-traced animations all the way through to today’s blockbuster AAA game titles. In this session, he will share how Unity’s award-winning demo team pushes the boundaries of graphics and rendering to achieve realistic digital humans in Enemies.
NVIDIA DLSS Overview and Game Integrations
Andrew Edelsten, Director, Developer Technologies (Deep Learning), NVIDIA
This session is the perfect primer for anyone interested in integrating DLSS to boost game frame rates. Andrew Edelsten, a director with over 20 years of experience in gaming and visual arts, will give a behind-the-scenes look at the underlying technology that powers DLSS and how to get started.
Simulation / Modeling / Design
Accelerating the Next Wave of Innovation and Discovery
Ian Buck, Vice President and General Manager of Accelerated Computing, NVIDIA
Join this special session with Ian Buck, vice president and general manager of Accelerated Computing at NVIDIA and inventor of CUDA. Buck will dive into the latest news, innovations, and technologies that will help companies, industries, and nations reap the benefits of AI supercomputing.
A Vision of the Metaverse: How We will Build Connected Virtual Worlds
Rev Lebaredian, VP Omniverse & Simulation Technology, NVIDIA
Dean Takahashi, Lead Writer, Venture Beat
Virginie Maillard, Global Head of Simulation and Digital Twin Research, Siemens
Amy Bunszel, Executive VP, AEC Design Solutions, Autodesk
Timoni West, VP Augmented, Virtual, and Mixed Reality, Unity
Lori Hufford, VP Engineering Collaboration, Bentley Systems
The speakers within this panel are from some of the largest and most reputable technology companies in the world. The session itself will dive into the future of these 3D virtual worlds and also look at how these companies’ technologies will work together to make it all happen.
The Importance of Digital Humans for Industries
Sarah Bacha, Head of Research and Innovation, Cedrus Digital
Markus Gross, Vice President of Research, Walt Disney Studios
Vladimir Mastilovic, VP of Digital Humans Technology, Epic Games
Matt Workman, Developer, Cine Tracer
Simon Yuen, Director of Graphics and AI, NVIDIA
John Martin II, VP of Product Marketing, Reallusion
Erroll Wood, Principal Scientist, Microsoft
These leaders in research and graphics will talk through the effect that digital humans will have on our professional workloads and how they’ll change our daily lives in the future. These accomplished panelists are technical and business leaders at top software, research, and technology companies.
Case Study on Developing Digital Twins for the Power Industry using Modulus and Omniverse
Stefan Lichtenberger, Technical Portfolio Manager, Siemens Energy
Ram Cherukuri, Senior Product Manager, NVIDIA
In this joint talk with Siemens Energy, we’ll cover building a digital twin of a heat-recovery steam generator unit by simulating the corrosive effects of heat, water, and other conditions on metal over time for predictive maintenance. Learn how the NVIDIA Modulus framework was used to create the underlying physics machine language digital twin model that’s connected, simulated, and visualized in Omniverse.
Video Streaming / Conferencing
Project Starline: A High-fidelity Telepresence System
Harris Nover, Software Engineer, Google
Jason Lawrence, Research Scientist, Google
Imagine sitting and looking through a pane of glass and there you see another person, digitally created but also so real, on the other side. This science-fiction scenario has become reality, combining a 3D representation compressed and rendered in real time, giving the sense that you are in fact present in the same place, communicating together. Harris Nover and Jason Lawrence from Google will walk you through this breakthrough technology.
Put Your Body into It! Easy Talent Tracking in Virtual Environments
Øystein Larsen, Chief Creative Officer, Pixotope
Catch this full feature session from Øystein Larsen to see how this visual effects award-winning creator manipulates what’s possible in a virtual environment with the power of NVIDIA RTX and Maxine.
How Avaya’s Real-time Cloud Media Processing Core Maintains Ultra-low Latency with Maxine
Stephen Whynot, Cloud Media Architect, Avaya
See just what NVIDIA Maxine brings to the table in video streaming alterations and improvements, while still maintaining real-time accuracy with this breakout session by Stephen Whynot from Avaya.

 Join experts from NVIDIA at the Healthcare and Life Sciences Developer Summit at GTC; attend Omniverse sessions at GDC; and get hands-on NVIDIA Deep Learning Institute training at GTC.
Join experts from NVIDIA at the Healthcare and Life Sciences Developer Summit at GTC; attend Omniverse sessions at GDC; and get hands-on NVIDIA Deep Learning Institute training at GTC.

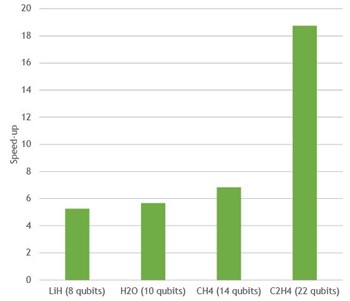
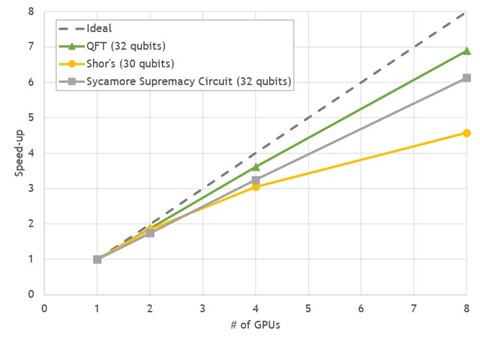
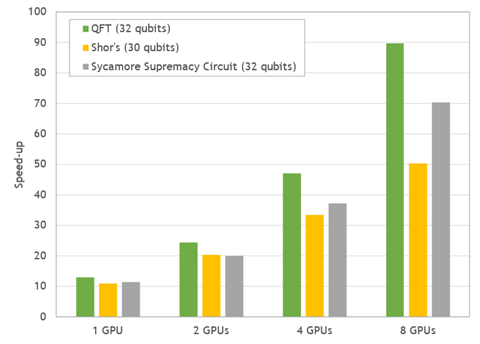
 cuStateVec is a library for acceleration of state vector-based quantum circuit simulation. We discuss APIs, integrations, and benchmarks.
cuStateVec is a library for acceleration of state vector-based quantum circuit simulation. We discuss APIs, integrations, and benchmarks.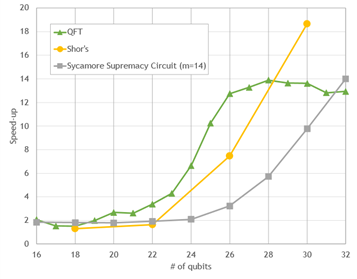
 Great sessions on custom computer vision models, expressive TTS, localized NLP, scalable recommenders, and commercial and healthcare robotics apps.
Great sessions on custom computer vision models, expressive TTS, localized NLP, scalable recommenders, and commercial and healthcare robotics apps.

 Is your network getting long in the tooth and are you thinking about an upgrade? This blog will cover three areas to consider when updating your data center network.
Is your network getting long in the tooth and are you thinking about an upgrade? This blog will cover three areas to consider when updating your data center network.