The Jetson AGX Orin Developer Kit offers 8X the performance of the last generation, offering the most powerful AI supercomputer for advanced robotics, and embedded and edge computing.
Availability of the the NVIDIA Jetson AGX Orin Developer Kit was announced today at NVIDIA GTC. The platform is the world’s most powerful, compact, and energy-efficient AI supercomputer for advanced robotics, autonomous machines, and next-generation embedded and edge computing.
Jetson AGX Orin delivers up to 275 trillion operations per second (TOPS). It gives customers more than 8X the processing power of its predecessor Jetson AGX Xavier, while maintaining the same small form factor and pin compatibility. It features an NVIDIA Ampere Architecture GPU, Arm Cortex-A78AE CPU, next-generation deep learning and vision accelerators, high-speed interfaces, faster memory bandwidth, and multimodal sensor support to feed multiple, concurrent AI application pipelines.
The NVIDIA Jetson AGX Orin Developer Kit is perfect for prototyping advanced AI-powered robots and edge AI applications for manufacturing, logistics, retail, agriculture, healthcare, and more.
“As AI transforms manufacturing, healthcare, retail, transportation, smart cities, and other essential sectors of the economy, demand for processing continues to surge,” said Deepu Talla, vice president and general manager of embedded and edge computing at NVIDIA. “A million developers and more than 6,000 companies have already turned to Jetson. The availability of Jetson AGX Orin will supercharge the efforts of the entire industry as it builds the next generation of robotics and edge AI products.”
Jetson AGX Orin Developer Kit features:
Up to 275 TOPS and 8X the performance of the last generation, plus high-speed interface support for multiple sensors.
An NVIDIA Ampere Architecture GPU and 12-core Arm Cortex-A78AE 64-bit CPU, together with next-generation deep learning and vision accelerators.
High-speed I/O, 204.8GB/s of memory bandwidth, and 32GB of DRAM capable of feeding multiple concurrent AI application pipelines.
The Jetson AGX Orin Developer Kit has the computing capability of more than eight Jetson AGX Xavier systems. It integrates the latest NVIDIA GPU technology with the world’s most advanced deep learning software stack, delivering the flexibility to create sophisticated AI solutions now and well into the future. The developer kit can emulate all the production Jetson AGX Orin and Orin NX modules, set for release Q4 2022.
Customers using the Jetson AGX Orin Developer Kit can leverage the full NVIDIA CUDA-X accelerated computing stack.This suite includes pretrained models from the NVIDIA NGC catalog and the latest NVIDIA application frameworks and tools for application development and optimization, such as Isaac, Metropolis, TAO, and Omniverse.
These tools reduce time and cost for production-quality AI deployments. Developers can access the largest, most complex models needed to solve robotics and edge AI challenges in 3D perception, natural language understanding, multisensor fusion, and more.
Developer kit pricing and availability
The NVIDIA Jetson AGX Orin Developer Kit is available now at $1,999. Production modules will be available in Q4 2022 starting at $399.
Learn more about this new Jetson offering and attend an upcoming dedicated GTC session.
Downloadable documentation, software, and other resources are available in the Jetson Download Center.
Learn about all of the new applications, features, and functions released for developers to build, extend, and connect 3D tools and platforms to the Omniverse ecosystem seamlessly.
Developers, creators, and enterprises around the world are using NVIDIA Omniverse—the real-time collaboration and simulation platform for 3D design—to enhance complex workflows and develop for 3D worlds faster. At NVIDIA GTC, we showcased how the platform’s ecosystem is expanding, from new Omniverse Connectors and asset libraries to updated Omniverse apps and features.
With these latest releases and capabilities, Omniverse developers can build, extend, and connect 3D tools and platforms to the Omniverse ecosystem more easily than ever before.
Omniverse Kit
Omniverse Kit is a powerful toolkit on which Omniverse applications are built.
The latest version includes core functionality and rendering improvements for 3rd party renderer integrations and Arbitrary Output Variables (AOV) support.
Key updates:
Manipulator Framework: Create 3D manipulators within the viewport.
Hydra Delegates: Add hydra-based renderers to Kit based applications.
WARP in Omnigraph: Create GPU-accelerated Omnigraph compute nodes using Python syntax.
MDL Python Support Added: Enhance ability to integrate MDL through Python.
Figure 1. Hydra Support in NVIDIA Omniverse.
Omniverse Nucleus
Omniverse Nucleus Workstation and Enterprise Nucleus Server were updated with a new navigator and several features requested from the community.
Key feature:
DeepSearch, a new AI-based search microservice for Nucleus. Users can search through massive, untagged databases of assets using natural language or images. Now available for early access to Omniverse Enterprise customers.
Figure 2. A new ability to connect and view multiple Nucleus instances in a shared Navigator makes it easier to find and search for projects.
Omniverse Cloud
At GTC, we announced Omniverse Cloud, a suite of cloud services that provide instant access to the NVIDIA Omniverse platform. Omniverse Cloud encompasses several services, including Nucleus Cloud, now in early access, plus Omniverse Create and View apps streaming from the cloud.
Figure 3. Until now, individual or teams of designers, creators, engineers, and researchers have hosted NVIDIA Omniverse on their RTX-powered laptops, desktops, or data centers.
Omniverse Apps 2022.1 updates
Omniverse Create
With Omniverse Create advanced scene composition users can interactively simulate, and render scenes in Pixar USD in real time.
Key updates:
General animation keyframing and curve editing.
ActionGraph based on Omnigraph to map keyboard shortcuts and your own user interface buttons.
vMaterials 2.0 additions. Access a massive library of over 900 physical materials.
Animation Graph (beta):Bring characters to life with our new node-based graph editor for runtime animation blending and playback.
Figure 4. Omniverse Create 2022.1 overview.
Omniverse View
With Omniverse View, project reviewers can collaboratively review 3D design projects in stunning photorealism.
Key updates releasing March 30:
Markup: Add editable text, shapes, and scribbles to convey comments.
Measure: A variety of snapping methods are available to measure between entities and create desired dimensions.
Turntable: Rotate objects on a virtual turntable to see how light affects the model.
Teleport: Move around large scenes by jumping great distances to place the camera in an area.
Waypoints 2.0: Edit or reorder waypoints, and easily create a 3D slide deck walkthrough.
Figure 5. Create an immersive VR experience with the teleport tool in Omniverse View.
Omniverse Machinima
With Omniverse Machinima, users can collaborate in real time to animate and manipulate characters and their virtual world environments.
Key updates:
Track and capture motion in real time using a single camera, with live conversion from 2D camera capture to 3D model in the Maxine Pose Estimation workflow.
Faster and easier to use sequencer with tools such as splitting, looping, hold, and scale, and even more “drag and drop” functionality.
Animation Retargeting (beta): Easily remap skeletal animations from one biped to another, with presets for popular character systems like Reallusion Character Creator 3.
Figure 6. Join the Omniverse Machinima challenge.
Omniverse XR App
Coming soon to beta, the new Omniverse XR App lets you bring your 3D work into human scale. View, review, and annotate Omniverse scenes, manipulate 3D objects, control the lighting all in VR.
Figure 7. Bring your 3D work into human scale using Omniverse scenes.
New developer tools
Omniverse Code
Omniverse Code is the integrated development environment that helps developers build Kit-based extensions, apps, and microservices easier than ever. Key features, releasing March 30, include new interactive documentation and templates along with Omniverse Replicator extensions.
Figure 8. Omniverse Code (left) alongside Microsoft Visual Studio (right).
Omniverse Replicator
NVIDIA Omniverse Replicator is a framework built on the Omniverse platform that enables physically accurate 3D synthetic data generation to accelerate training and accuracy of perception networks. Omniverse Replicator is now available as a set of Omniverse Extensions, with content, and examples within Omniverse Code App in the Omniverse Launcher.
Figure 9. Images from Omniverse Marbles.
Omniverse Avatar
NVIDIA Omniverse Avatar, a technology platform for generating interactive AI avatars, connects NVIDIA technologies in speech AI, computer vision, natural language understanding, recommendation engines, and simulation technologies. While currently under development, developers and artists can get started with one piece of the Avatar technology, Omniverse Audio2Face.
Figure 10. NVIDIA CEO Jensen Huang kicks off GTC with a keynote that presents the latest breakthroughs including Omniverse Avatar.
Partner ecosystem updates
New support for the Omniverse ecosystem provided by leading 3D marketplaces and digital asset libraries gives creators an even easier way to build their scenes. TurboSquid by Shutterstock,Sketchfab, Twinbru, and newly added Reallusion’s ActorCore assets are searchable directly inside the Omniverse App asset browser. Joining our catalog of Omniverse-ready assets alongside CGTrader is A23D, bringing 40,000 Omniverse-ready assets to users.
New Omniverse connections
Adobe Substance 3D Material Extension: Import Substance 3D asset files into any Omniverse App.
Adobe Substance 3D Painter Connector: Apply textures, materials, and masks or UV mapping onto 3D assets with Adobe Substance 3D Painter, releasing March 28.
Unreal Engine 5: Send and sync model data and export Nanite Geometry to Omniverse Nucleus.
e-on VUE: Create beautiful CG environments including skies, terrains, roads, and rocks.
e-on PlantCatalog: Export a plant, enable live-sync, and edit in real time.
e-on PlantFactory: Create ultra-realistic, high polygon plants.
Maxon Cinema 4D: USD is now supported. Use the app in a connected workflow with OmniDrive.
Ipolog: Perform material provisioning and production logistics for manufacturing planners.
LumenRT for NVIDIA Omniverse, powered by Bentley iTwin: Allows engineering-grade, millimeter-accurate digital content to be visualized on multiple devices and form factors.
Figure 11. ITER fusion reactor model rendered in LumenRT for NVIDIA Omniverse, powered by Bentley iTwin. Image courtesy of Bentley Systems and ITER.
Supported Hydra renderers
Creators, designers, and developers can now integrate their favorite Hydra delegate renderers directly into their Omniverse workflows by building a Hydra render delegate themselves or using NVIDIA-built Hydra render delegates for Pixar HDStorm, Maxon RedShift, and OTOY Octane, with Blender Cycles, Chaos V-Ray, and Autodesk Arnold coming soon.
Figure 12. Integrate Hydra-delegate renderers directly into an Omniverse workflow with Hydra render delegates for Blender Cycles X (shown above.)
New CAD Importers
Manufacturing and product development workflows just became easier with the introduction of 26 CAD Importers to Omniverse. Developers, designers, and engineers can now easily bring in common CAD formats from leading ISV applications directly into Omniverse.
Figure 13. Omniverse CAD Importer.
Explore more at GTC
Join Omniverse Developer Days at GTC, which will showcase the many ways power users and developers can build extensions and apps on the platform. Hear from Omniverse engineering leaders and industry experts as they share new insights about 3D virtual world building, simulation, rendering, and more.
Additional resources
Learn more by diving into the Omniverse Resource Center, which details how developers can build custom applications and extensions for the platform.
Ultra rapid nanopore sequencing is bringing us one step closer to same-day whole genome genetic diagnosis.
Fast and cost-effective whole genome sequencing and analysis can be critical in a diagnostic setting. Recent advances in accelerated clinical sequencing, such as the world-record-setting DNA sequencing technique for rapid diagnosis, are bringing us one step closer to same-day, whole-genome genetic diagnosis.
A team led by Stanford University School of Medicine, NVIDIA, Google, UCSC and Oxford Nanopore Technologies (ONT) recently used this technique to identify disease-associated genetic variants that resulted in a diagnosis in just over 7 hours, with results published earlier this year in the New England Journal of Medicine.
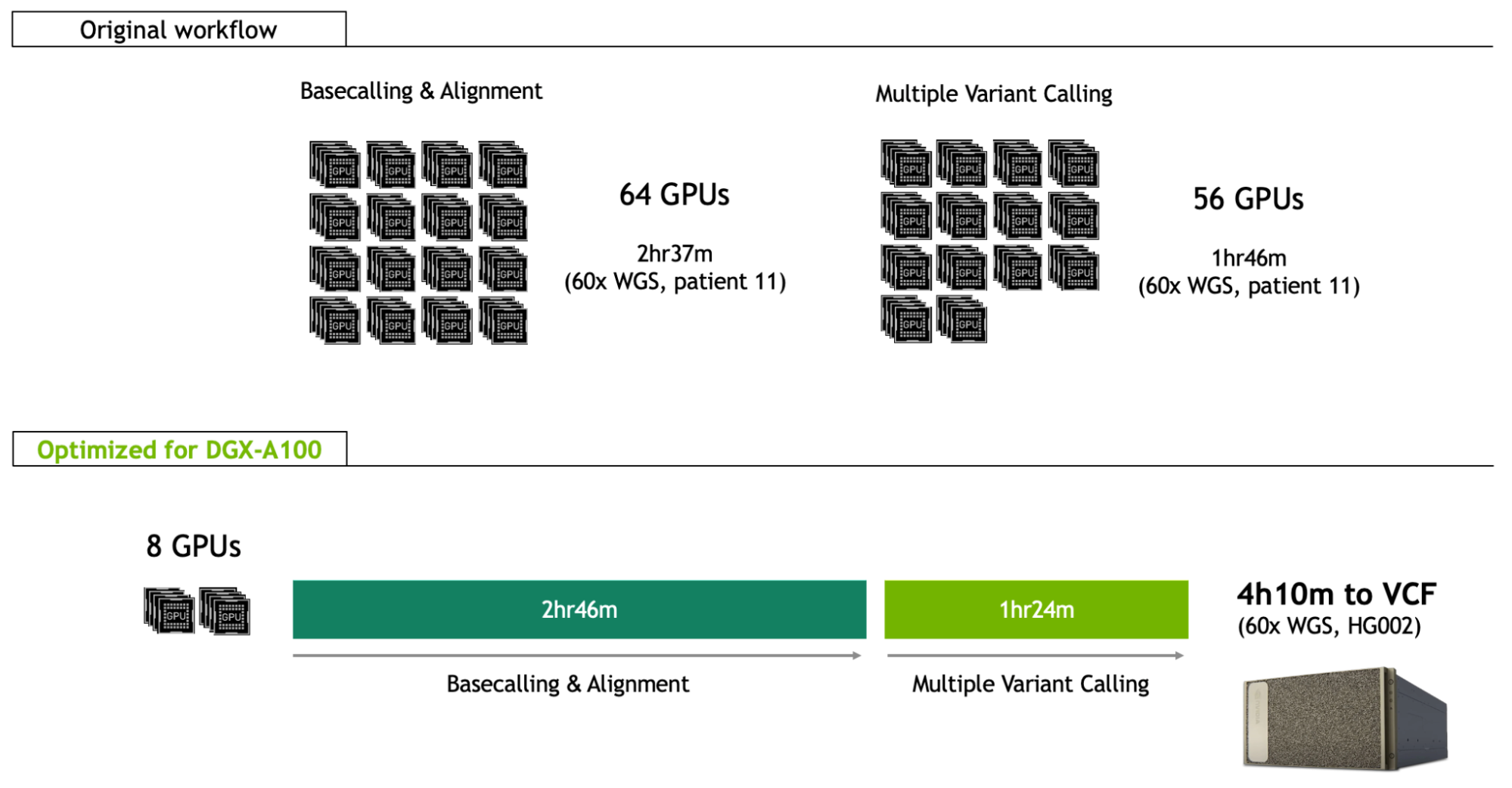
This record-beating end-to-end genomic workflow is reliant on innovative technology and high-performance computation. Nanopore sequencing was implemented across 48 flow cells, with optimized methods enabling pore occupancy at 82%, rapidly generating 202 Gb in just a couple of hours. Analysis of the output was distributed across a Google Cloud computing environment, including basecalling and alignment across 16 instances of 4 x V100 GPUs (64 GPUs total), and variant calling across 14 instances of 4 x P100 GPUs (56 GPUs total).
Since the January NEJM publication, the NVIDIA Clara team has been optimizing the same whole genome workflow for the DGX-A100, giving clinicians and researchers the ability to deploy the same analysis as the world record approach on just eight A100 GPUs, and in just 4h10m for a 60x whole genome (Figure 1; benchmarked on the HG002 reference sample).
Figure 1.Optimized nanopore sequencing workflow on NVIDIA DGX-A100
Not only does this enable fast analysis in a single server (8-GPU) framework, but it also lowers the cost per sample by two-thirds, from $568 to $183.
Basecalling and alignment
Basecalling is the process of classifying raw instrument signals into the bases A, C, G, and T of the genome. It is a computationally critical step in ensuring accuracy in all downstream analysis tasks. It is also an important data reduction step, reducing resultant data by approximately 10x.
At ~340 bytes per base, a single 30x coverage whole genome can easily be multiple terabytes in raw signals, as opposed to hundreds of gigabytes when processed. As such, it is beneficial for compute speed to rival sequencing output speed, which is non-trivial at a pace of ~450 bases per second through the 128,000 pores across 48 flow cells.
ONT’s PromethION P48 sequencer can generate as much as 10 terabases in a 72-hour run, equivalent to 96 human genomes (30x coverage).
The rapid classification task required for this already benefits from deep learning innovation and GPU acceleration. The core data processing toolkit for this purpose, Guppy, uses a recurrent neural network (RNN) for basecalling, with the option of two different architectures of either smaller (faster) or larger (higher accuracy) recurrent layer sizes.
The main computational bottleneck in basecalling is the RNN kernel, which has benefited from GPU integration with ONT sequencers, such as the desktop GridION Mk1 that includes a single V100 GPU and the handheld MinION Mk1C that includes a Jetson Edge platform.
Alignment is the process of taking the resultant basecalled fragments of DNA, now in the form of character strings of As, Cs, Gs, and Ts, and determining the genome location where those fragments originated, assembling a full genome from the massively parallelized sequencing process. This essentially rebuilds the full length genome from many 100-100,000bp long reads. For the world-record-setting sample, this totaled around 13million reads.
For the original world-record analysis, basecalling and alignment were run on separate instances of Guppy and Minimap2, respectively. In migrating this to a single-server DGX-A100 solution, and using Guppy’s integrated minimap2 aligner, you immediately save time on I/O. Through balancing of basecalling and alignment across the DGX eight A100 GPUs and 96 CPU threads, respectively, the two processes can be overlapped perfectly to align reads concurrently with basecalling, resulting in no impact on total runtime (
This brings the runtime of the basecalling and alignment step on the DGX-A100 to 2h 46m, which can also be overlapped with the sequencing itself. It is similar to the sequencing time expected for a 60x sample.
Variant calling
Variant calling is the portion of the workflow designed to identify all of the points in the newly assembled individual’s genome that differ from expected, compared to a reference genome. This involves scanning the full breadth of the genome to look for different types of variation. For example, this might include small single-base-pair variants all the way to large structural variants covering thousands of base-pairs. The world record pipeline used PEPPER-Margin-DeepVariant for small variants, and Sniffles for structural variants.
The PEPPER-Margin-DeepVariant approach is designed to optimize small variant calling for the long reads produced by nanopore sequencing.
PEPPER identifies candidate variants through an RNN consisting of two bidirectional, gated, recurrent unit layers and a linear transformation layer.
Margin then uses a hidden Markov model approach for a process called haplotyping, determining which variants have been inherited together from the maternal or paternal chromosomes. It passes this information to Google DeepVariant to use for maximum heterozygous variant calling accuracy.
DeepVariant classifies final variants through a deep convolutional neural network, which is built on the Inception v2 architecture adapted specifically for DNA read pile-up input images.
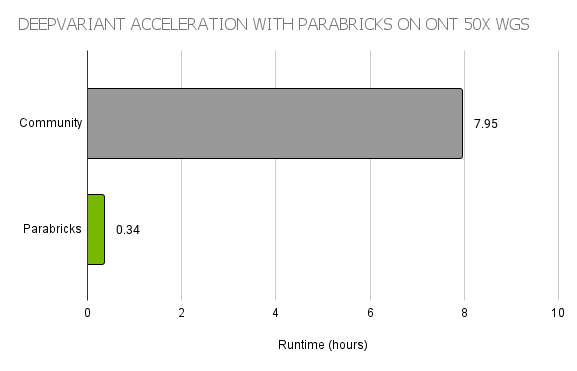
Overall, PEPPER-Margin-DeepVariant allows the faster neural network of PEPPER to scan the whole genome for candidates, and then uses the larger neural network of DeepVariant for high accuracy variant calling of those candidates. To accelerate this pipeline, the world-record workflow used Parabricks DeepVariant, a GPU-accelerated implementation providing >20x faster runtimes than the open-source version on CPU (Figure 2).
The Clara team took this acceleration further by modifying PEPPER-Margin to run in an integrated fashion, splitting the data by chromosome and running the programs concurrently on GPU. PEPPER was also optimized for pipeline parameters such as batch sizes, number of workers, and number of callers, as well as upgrading PyTorch to enable support for NVIDIA Ampere Architecture acceleration of the RNN inference bottleneck.
For structural variant calling, Sniffles was upgraded to the recently released Sniffles 2, which is considerably more efficient, at 38x acceleration on CPU alone.
All these improvements put the runtime of the multiple variant calling stage at 1h 24m on the DGX-A100.
Figure 2. Parabricks DeepVariant enables fast runtimes on ONT data
Powering real-time sequencing with NVIDIA DGX-A100
By bringing the world-record DNA sequencing technique for critical care patients to the DGX A100, the NVIDIA Clara team is powering real-time sequencing, simplifying a complex workflow on a single server, and cutting analysis costs by two-thirds. These improvements better enable long-read whole genome sequencing in a clinical care setting and help rare and undiagnosed disease patients get answers faster.
I’m currently doing a tutorial showing me how to use TensorFlow in a general sense but for the project I’m working on I have images that are originating from my project. How do I create a custom model to train the neural network on with my images instead of one of the preset ones in most tutorials?
Lucid Group may be a newcomer to the electric vehicle market, but its entrance has been grand. The electric automaker announced at GTC that its current and future fleets are built on NVIDIA DRIVE Hyperion for programmable, intelligent capabilities. By developing on the scalable, software-defined platform, Lucid ensures its vehicles are always at the cutting Read article >
NVIDIA today introduced Clara Holoscan MGX™, a platform for the medical device industry to develop and deploy real-time AI applications at the edge, specifically designed to meet required regulatory standards.
NVIDIA today announced the availability of the NVIDIA® Jetson AGX Orin™ developer kit, the world’s most powerful, compact and energy-efficient AI supercomputer for advanced robotics, autonomous machines, and next-generation embedded and edge computing.
Next time socks, cereal or sandpaper shows up in hours delivered to your doorstep, consider the behind-the-scenes logistics acrobatics that help get them there so fast. Order fulfillment is a massive industry of moving parts. Heavily supported by autonomous mobile robots (AMRs), warehouses can span 1 million square feet, expanding and reconfiguring to meet demands. Read article >
NVIDIA today announced Omniverse Cloud, a suite of cloud services that gives artists, creators, designers and developers instant access to the NVIDIA Omniverse™ platform for 3D design collaboration and simulation from up to billions of devices.
When it comes to creating and connecting virtual worlds, over 150,000 individuals have downloaded NVIDIA Omniverse to make huge leaps in transforming 3D design workflows and achieve new heights of real-time, physically accurate simulations. At GTC, NVIDIA today announced new releases and updates for Omniverse — including the latest Omniverse Connectors and libraries — expanding Read article >

 The Jetson AGX Orin Developer Kit offers 8X the performance of the last generation, offering the most powerful AI supercomputer for advanced robotics, and embedded and edge computing.
The Jetson AGX Orin Developer Kit offers 8X the performance of the last generation, offering the most powerful AI supercomputer for advanced robotics, and embedded and edge computing. Learn about all of the new applications, features, and functions released for developers to build, extend, and connect 3D tools and platforms to the Omniverse ecosystem seamlessly.
Learn about all of the new applications, features, and functions released for developers to build, extend, and connect 3D tools and platforms to the Omniverse ecosystem seamlessly.



 Ultra rapid nanopore sequencing is bringing us one step closer to same-day whole genome genetic diagnosis.
Ultra rapid nanopore sequencing is bringing us one step closer to same-day whole genome genetic diagnosis.