
Current deep reinforcement learning (RL) methods can train specialist artificial agents that excel at decision-making on various individual tasks in specific environments, such as Go or StarCraft. However, little progress has been made to extend these results to generalist agents that would not only be capable of performing many different tasks, but also upon a variety of environments with potentially distinct embodiments.
Looking across recent progress in the fields of natural language processing, vision, and generative models (such as PaLM, Imagen, and Flamingo), we see that breakthroughs in making general-purpose models are often achieved by scaling up Transformer-based models and training them on large and semantically diverse datasets. It is natural to wonder, can a similar strategy be used in building generalist agents for sequential decision making? Can such models also enable fast adaptation to new tasks, similar to PaLM and Flamingo?
As an initial step to answer these questions, in our recent paper “Multi-Game Decision Transformers” we explore how to build a generalist agent to play many video games simultaneously. Our model trains an agent that can play 41 Atari games simultaneously at close-to-human performance and that can also be quickly adapted to new games via fine-tuning. This approach significantly improves upon the few existing alternatives to learning multi-game agents, such as temporal difference (TD) learning or behavioral cloning (BC).
 |
| A Multi-Game Decision Transformer (MGDT) can play multiple games at desired level of competency from training on a range of trajectories spanning all levels of expertise. |
Don’t Optimize for Return, Just Ask for Optimality
In reinforcement learning, reward refers to the incentive signals that are relevant to completing a task, and return refers to cumulative rewards in a course of interactions between an agent and its surrounding environment. Traditional deep reinforcement learning agents (DQN, SimPLe, Dreamer, etc) are trained to optimize decisions to achieve the optimal return. At every time step, an agent observes the environment (some also consider the interactions that happened in the past) and decides what action to take to help itself achieve a higher return magnitude in future interactions.
In this work, we use Decision Transformers as our backbone approach to training an RL agent. A Decision Transformer is a sequence model that predicts future actions by considering past interactions between an agent and the surrounding environment, and (most importantly) a desired return to be achieved in future interactions. Instead of learning a policy to achieve high return magnitude as in traditional reinforcement learning, Decision Transformers map diverse experiences, ranging from expert-level to beginner-level, to their corresponding return magnitude during training. The idea is that training an agent on a range of experiences (from beginner to expert level) exposes the model to a wider range of variations in gameplay, which in turn helps it extract useful rules of gameplay that allow it to succeed under any circumstance. So during inference, the Decision Transformer can achieve any return value in the range it has seen during training, including the optimal return.
But, how do you know if a return is both optimal and stably achievable in a given environment? Previous applications of Decision Transformers relied on customized definitions of the desired return for each individual task, which required manually defining a plausible and informative range of scalar values that are appropriately interpretable signals for each specific game — a task that is non-trivial and rather unscalable. To address this issue, we instead model a distribution of return magnitudes based on past interactions with the environment during training. At inference time, we simply add an optimality bias that increases the probability of generating actions that are associated with higher returns.
To more comprehensively capture spatial-temporal patterns of agent-environment interactions, we also modified the Decision Transformer architecture to consider image patches instead of a global image representation. Patches allow the model to focus on local dynamics, which helps model game specific information in further detail.
These pieces together give us the backbone of Multi-Game Decision Transformers:
 |
| Each observation image is divided into a set of M patches of pixels which are denoted O. Return R, action a, and reward r follows these image patches in each input casual sequence. A Decision Transformer is trained to predict the next input (except for the image patches) to establish causality. |
Training a Multi-Game Decision Transformer to Play 41 Games at Once
We train one Decision Transformer agent on a large (~1B) and broad set of gameplay experiences from 41 Atari games. In our experiments, this agent, which we call the Multi-Game Decision Transformer (MGDT), clearly outperforms existing reinforcement learning and behavioral cloning methods — by almost 2 times — on learning to play 41 games simultaneously and performs near human-level competency (100% in the following figure corresponds to the level of human gameplay). These results hold when comparing across training methods in both settings where a policy must be learned from static datasets (offline) as well as those where new data can be gathered from interacting with the environment (online).
 |
| Each bar is a combined score across 41 games, where 100% indicates human-level performance. Each blue bar is from a model trained on 41 games simultaneously, whereas each gray bar is from 41 specialist agents. Multi-Game Decision Transformer achieves human-level performance, significantly better than other multi-game agents, even comparable to specialist agents. |
This result indicates that Decision Transformers are well-suited for multi-task, multi-environment, and multi-embodiment agents.
A concurrent work, “A Generalist Agent”, shows a similar result, demonstrating that large transformer-based sequence models can memorize expert behaviors very well across many more environments. In addition, their work and our work have nicely complementary findings: They show it’s possible to train across a wide range of environments beyond Atari games, while we show it’s possible and useful to train across a wide range of experiences.
In addition to the performance shown above, empirically we found that MGDT trained on a wide variety of experience is better than MDGT trained only on expert-level demonstrations or simply cloning demonstration behaviors.
Scaling Up Multi-Game Model Size to Achieve Better Performance
Argurably, scale has become the main driving force in many recent machine learning breakthroughs, and it is usually achieved by increasing the number of parameters in a transformer-based model. Our observation on Multi-Game Decision Transformers is similar: the performance increases predictably with larger model size. In particular, its performance appears to have not yet hit a ceiling, and compared to other learning systems performance gains are more significant with increases in model size.
 |
| Performance of Multi-Game Decision Transformer (shown by the blue line) increases predictably with larger model size, whereas other models do not. |
Pre-trained Multi-Game Decision Transformers Are Fast Learners
Another benefit of MGDTs is that they can learn how to play a new game from very few gameplay demonstrations (which don’t need to all be expert-level). In that sense, MGDTs can be considered pre-trained models capable of being fine-tuned rapidly on small new gameplay data. Compared with other popular pre-training methods, it clearly shows consistent advantages in obtaining higher scores.
 |
| Multi-Game Decision Transformer pre-training (DT pre-training, shown in light blue) demonstrates consistent advantages over other popular models in adaptation to new tasks. |
Where Is the Agent Looking?
In addition to the quantitative evaluation, it’s insightful (and fun) to visualize the agent’s behavior. By probing the attention heads, we find that the MGDT model consistently places weight in its field of view to areas of the observed images that contain meaningful game entities. We visualize the model’s attention when predicting the next action for various games and find it consistently attends to entities such as the agent’s on screen avatar, agent’s free movement space, non-agent objects, and key environment features. For example, in an interactive setting, having an accurate world model requires knowing how and when to focus on known objects (e.g., currently present obstacles) as well as expecting and/or planning over future unknowns (e.g., negative space). This diverse allocation of attention to many key components of each environment ultimately improves performance.
 |
| Here we can see the amount of weight the model places on each key asset of the game scene. Brighter red indicates more emphasis on that patch of pixels. |
The Future of Large-Scale Generalist Agents
This work is an important step in demonstrating the possibility of training general-purpose agents across many environments, embodiments, and behavior styles. We have shown the benefit of increased scale on performance and the potential with further scaling. These findings seem to point to a generalization narrative similar to other domains like vision and language — we look forward to exploring the great potential of scaling data and learning from diverse experiences.
We look forward to future research towards developing performant agents for multi-environment and multi-embodiment settings. Our code and model checkpoints can soon be accessed here.
Acknowledgements
We’d like to thank all remaining authors of the paper including Igor Mordatch, Ofir Nachum Menjiao Yang, Lisa Lee, Daniel Freeman, Sergio Guadarrama, Ian Fischer, Eric Jang, Henryk Michalewski.
 Nsight Graphics 2022.3 and Nsight Aftermath 2022.2 have just been released and are now available to download. Nsight Graphics 2022.3 The Nsight Graphics 2022.3 release…
Nsight Graphics 2022.3 and Nsight Aftermath 2022.2 have just been released and are now available to download. Nsight Graphics 2022.3 The Nsight Graphics 2022.3 release… If you’re wondering how an AI server is different from an AI workstation, you’re not the only one. Assuming strictly AI use cases with minimal graphics workload, obvious…
If you’re wondering how an AI server is different from an AI workstation, you’re not the only one. Assuming strictly AI use cases with minimal graphics workload, obvious… In the old days of 10 Mbps Ethernet, long before Time-Sensitive Networking became a thing, state-of-the-art shared networks basically required that packets would collide. For the…
In the old days of 10 Mbps Ethernet, long before Time-Sensitive Networking became a thing, state-of-the-art shared networks basically required that packets would collide. For the…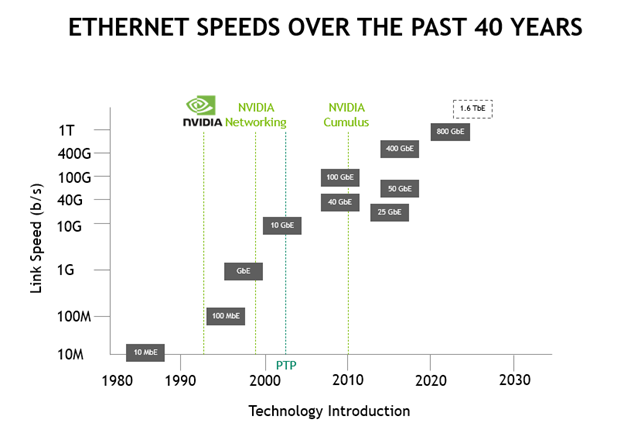



") Artificial intelligence (AI) is becoming pervasive in the enterprise. Speech recognition, recommenders, and fraud detection are just a few applications among hundreds being driven…
Artificial intelligence (AI) is becoming pervasive in the enterprise. Speech recognition, recommenders, and fraud detection are just a few applications among hundreds being driven… The acceleration of digital transformation within data centers and the associated application proliferation is exposing new attack surfaces to potential security threats. These new…
The acceleration of digital transformation within data centers and the associated application proliferation is exposing new attack surfaces to potential security threats. These new…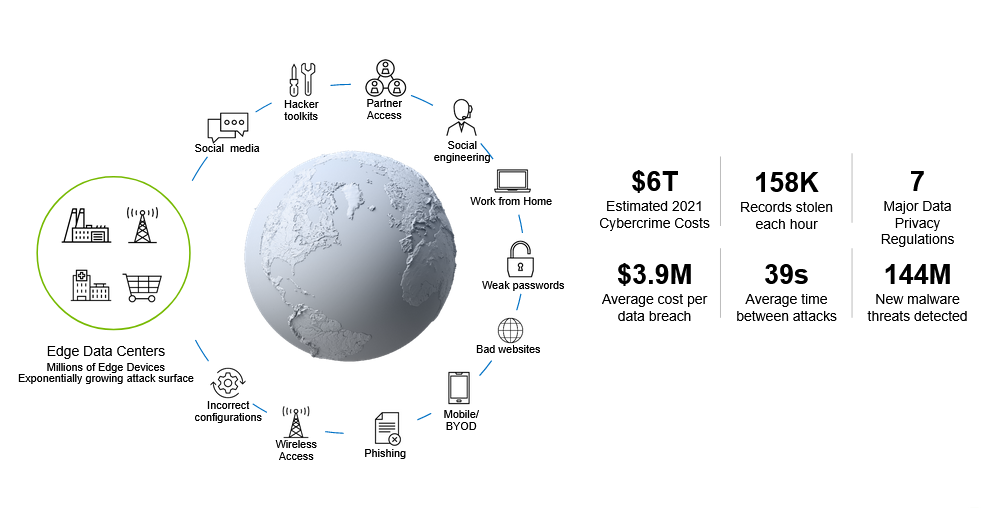
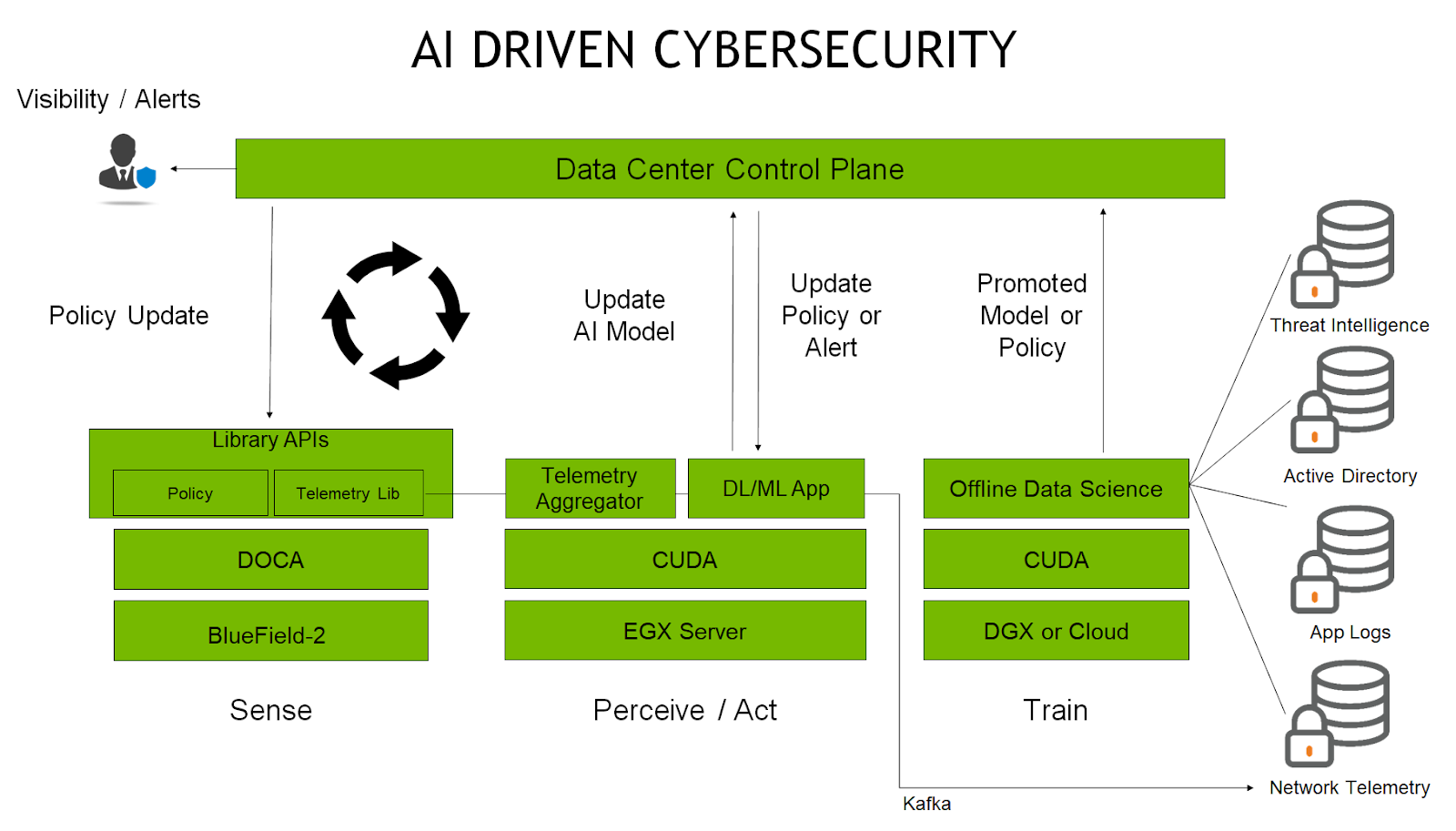
 The new ‘Level Up with NVIDIA’ webinar series offers creators and developers the opportunity to learn more about the NVIDIA RTX platform, interact with NVIDIA experts, and ask…
The new ‘Level Up with NVIDIA’ webinar series offers creators and developers the opportunity to learn more about the NVIDIA RTX platform, interact with NVIDIA experts, and ask…