Announcing NVIDIA Isaac Transport for ROS (NITROS) pipelines that use new ROS Humble features developed jointly with Open Robotics.
Working in collaboration since October 2021, NVIDIA and Open Robotics are introducing two important changes, now available in the Humble ROS 2 release for improved performance on compute platforms that offer hardware accelerators.
The new ROS 2 Humble hardware-acceleration features are called type adaptation and type negotiation. NVIDIA will release a software package-implementing type adaptation and type negotiation in the next NVIDIA Isaac ROS release (late June 2022).
These simple but powerful additions to the framework will significantly increase performance for developers seeking to incorporate AI/machine learning and computer vision functionality into their ROS-based applications.
“As ROS developers add more autonomy to their robot applications, the on-robot computers are becoming much more powerful. We have been working to evolve the ROS framework to make sure that it can take advantage of high-performance hardware resources in these edge computers,” said Brian Gerkey, CEO of Open Robotics.
“Working closely with the NVIDIA robotics team, we are excited to share new features (type adaptation and negotiation) in the Humble release that will benefit the entire ROS community’s efforts to embrace hardware acceleration.”
Eliminating overhead of hardware acceleration
Type adaptation
It is common for hardware accelerators to require a different data format to deliver optimal performance. Type adaptation (REP-2007) can now be used for ROS nodes to work in the format better suited for the hardware. Processing pipelines can eliminate memory copies between the CPU and the memory accelerator using the adapted type. Unnecessary memory copies consume CPU compute, waste power, and slow down performance, especially as the size of the images increases.
Type negotiation
Another new innovation is type negotiation (REP-2009). Different ROS nodes in a processing pipeline can advertise their supported types, so that formats yielding ideal performance are chosen. The ROS framework performs this negotiation process and maintains compatibility with legacy nodes that don’t support negotiation.
Accelerating processing pipelines using type adaptation and negotiation makes hardware accelerator zero-copy possible. This reduces software/CPU overhead and unlocks the potential of the underlying hardware. As roboticists migrate to more powerful compute platforms like NVIDIA Jetson Orin, they can expect to realize more of the performance gains enabled by the hardware.
These changes are done completely inside of ROS 2, which ensures compatibility with existing tools, workflows, and codebases.
Figure 1. Comparing hardware accelerated pipelines with and without type adaptation and negotiation
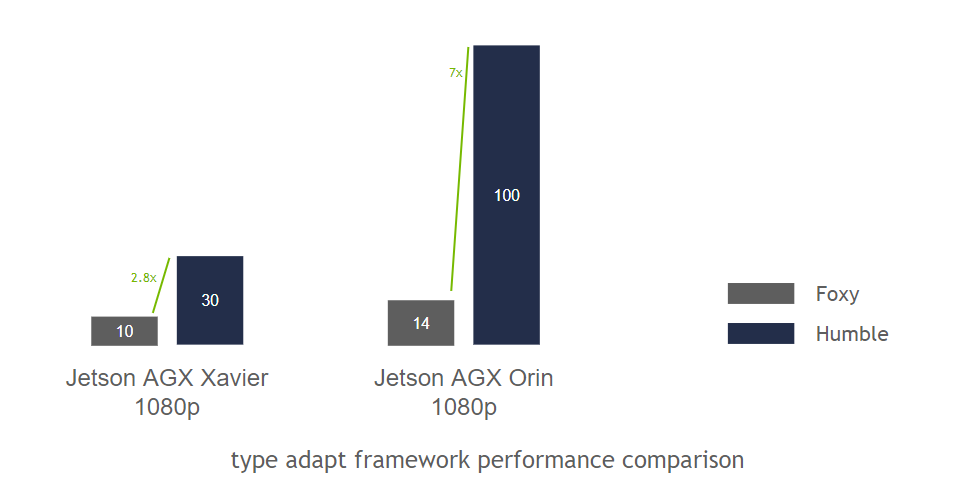
Type adaptation and negotiation have shown promising results. A benchmark consisting of a graph of ROS nodes, with minimal compute in each node, was run on ROS 2 Foxy and ROS 2 Humble so that we could observe the underlying framework performance. We ran this benchmark on Jetson AGX Xavier and the new Jetson AGX Orin. We observed a 3x improvement on Xavier and an impressive 7x improvement on Orin.
Figure 2. Type adaptation framework benchmark performance comparing ROS 2 Foxy and ROS 2 Humble on Jetson AGX Xavier and Jetson AGX Orin
Introducing NVIDIA Isaac for Transport for ROS
The NVIDIA implementation of type adaption and negotiation are called NITROS. These are ROS processing pipelines made up of Isaac ROS hardware accelerated modules (a.k.a. GEMs). These pipelines will be available in Isaac ROS Developer Preview (DP) scheduled for late June 2022. The first release of NITROS will include three pipelines and more are planned for later in the year.
In addition to the NITROS accelerated pipelines, the Isaac ROS DP release contains two new DNN-based GEMs designed to help roboticists with common perception tasks.
The first GEM, ESS, is a DNN for stereo camera disparity prediction. The network provides vision-based continuous depth perception for robotics applications.
The other GEM, Bi3D, is a DNN for vision-based obstacle prediction. The DNN, based on groundbreaking work from NVIDIA Research, is enhanced to detect free space with obstacle predictions simultaneously. The network predicts if an obstacle is within one of four programmable proximity fields from a stereo camera.
Bi3D is optimized to run on NVIDIA DLA hardware. Leveraging the DLA, both GPU and CPU compute resources are preserved.
Both Bi3D and ESS are pretrained for robotics applications using synthetic and real data and are intended for commercial use. These two new Isaac ROS GEMs join stereo_image_proc, a classic computer vision stereo depth disparity routine previously released, to offer three diverse, independent functions for stereo camera depth perception.
Figure 3. Comparison of results from synthetic camera image (top) and RGB stereo camera image capture with no active projection (bottom). From left to right: 3D DNN prediction for four proximity fields with ground free space; ESS DNN prediction for continuous depth; and classic CV stereo disparity function
Isaac ROS 2 GEM
Description
Image Pipeline
Camera Image Processing
NVBlox
3D Scene Reconstruction
Visual SLAM
VSLAM and Stereo Odometry
AprilTags
Apriltag Detection and Pose Estimation
Pose Estimation
3D Object Pose Estimation
Image Segmentation
Semantic Image Segmentation
Object Detection
DNN for Object Detection using DetectNet
DNN Inference
DNN Node for using Triton/TensorRT
Argus Camera
CSI/GSML Camera Support
Table 2. Available ROS GEM packages
Getting started
ROS developers interested in integrating NVIDIA AI Perception to their products should get started today with Isaac ROS.
hey dear, Can you please help me? I saw that you made dots and boxes game in your school project. Actually I have also to make this game and I have the same issue as you. Could you please show me how you did it? Thank you in advance.
Users can now produce 3D virtual worlds at human scale with the new Omniverse XR App available in beta from the NVIDIA Omniverse launcher.
Users can now produce 3D virtual worlds at human scale with the new Omniverse XR App available in beta from the NVIDIA Omniverse launcher.
At Computex this week, NVIDIA announced new releases and expansions to the collaborative graphic platform’s growing ecosystem, including the beta release of Omniverse XR. With this Omniverse app, creators and developers can drop into 3D scenes in VR and AR with full RTX ray tracing. Users can also review, manipulate, and annotate high-poly production assets without preprocessing.
Effortless, ray-traced VR
With the Omniverse XR App users can load Universal Scene Description (USD) production assets directly into the editor. You can jump directly into VR or AR and view or interact with them in ray-traced VR without preprocessing.
Unlike today’s interactive VR engines, Omniverse XR loads USD scenes directly for editing. This removes the need for pregenerated levels of detail since ray tracing is less sensitive to geometry complexity.
The scene below was modeled with 70 million polygons; with instancing, the total scene contains 18 billion polygons.
Figure 1. Production-quality USD-based assets load directly into a scene in Omniverse XR.
Realism out of the box
Fully raytraced VR accounts for a sizable contribution to realism. The human eye notices when contact shadows don’t reflect a scene’s geometry or when reflections don’t move with body motion.
With Omniverse XR, engineers, designers, and researchers are able to see soft shadows, translucency, and real reflections out of the box, making the experience feel truly immersive and realistic.
Figure 2. View a complete 3D scene in VR with the Omniverse XR App.
Navigate and manipulate in VR
Omniverse XR users can teleport and manipulate scene objects in VR. Currently, Oculus and HTC Vive controllers are supported. Since the Omniverse Kit uses real-time ray tracing, ray casting can be done with ease, leading to higher precision in close-range interactions.
Figure 3. Achieve precise object manipulation in Omniverse XR.
Continuous foveated rendering
Omniverse XR uses foveated rendering. This technique samples a region of an HMD screen at a higher shading rate and shrinks the number of pixels rendered to 30% of the image plane. These are pixels that a user won’t see in full resolution.
The foveation technique that comes with Omniverse XR is built specifically for real-time ray tracing. This removes the boundaries between resolution regions, avoiding the need to reshape an image plane when the fovea is off center.
Figure 4. Example of foveated rendering off (left) and on (right).
One-step AR streaming
With Omniverse XR, you can also experience tablet AR streaming, with the NVIDIA CloudXR streaming platform. This mode opens a virtual camera on the tablet, linked to the Omniverse XR session.
To use Tablet AR mode, content creators and developers can download the Omniverse Streaming Client for I/Os. It is available from the Apple Store for iPad I/Os 14.5 and later, or with an APK and code examples available for Android Tablets.
Figure 5. Experience tablet AR streaming.
Explore Omniverse XR
The Omniverse XR App is now available in beta from the Omniverse Launcher. To learn more, check out the tutorial video or attend the Q&A livestream on May 25 at 11 a.m. PDT / 8 p.m. CET.
Additional resources
Learn more by diving into the Omniverse Resource Center, which details how developers can build custom applications and extensions for the platform.
The future of content creation was on full display during the virtual NVIDIA keynote at COMPUTEX 2022, as the NVIDIA Studio platform expands with new Studio laptops and RTX-powered AI apps — all backed by the May Studio Driver released today.
More than 30 leading technology partners worldwide announced this week the first wave of NVIDIA Jetson AGX Orin-powered production systems at COMPUTEX in Taipei. New products are coming from a dozen Taiwan-based camera, sensor and hardware providers for use in edge AI, AIoT, robotics and embedded applications. Available worldwide since GTC in March, the NVIDIA Read article >
In the worldwide effort to halt climate change, Zac Smith is part of a growing movement to build data centers that deliver both high performance and energy efficiency. He’s head of edge infrastructure at Equinix, a global service provider that manages more than 240 data centers and is committed to becoming the first in its Read article >
Digital twins that revolutionize the way the most complex products are produced. Silicon and software that transforms data centers into AI factories. Gaming advances that bring the world’s most popular games to life. Taiwan has become the engine that brings the latest innovations to the world. So it only makes sense that NVIDIA leaders brought Read article >
NVIDIA today announced that Taiwan’s leading computer makers are set to release the first wave of systems powered by the NVIDIA Grace™ CPU Superchip and Grace Hopper Superchip for a wide range of workloads spanning digital twins, AI, high performance computing, cloud graphics and gaming.
This post presents an overview of NVIDIA Triton Model Analyzer and how it can be used to find the optimal AI model-serving configuration to satisfy application requirements.
Model deployment is a key phase of the machine learning lifecycle where a trained model is integrated into the existing application ecosystem. This tends to be one of the most cumbersome steps where various application and ecosystem constraints should be satisfied for a target hardware platform, all without compromising the model accuracy.
NVIDIA Triton Inference Server is an open-source model serving tool that simplifies inference and has several features to maximize hardware utilization and increase inference performance. This includes features like:
Concurrent model execution, which enables multiple instances of the same model to execute in parallel on the same system.
Dynamic batching, where client-side requests are grouped together on the server to form a larger batch.
There are several key decisions to be made when optimizing model deployment:
How many model instances should NVIDIA Triton run on the same CPU/GPU concurrently to maximize utilization?
How many incoming client requests should be dynamically batched together?
Which format should the model be served in?
At what precision should the outputs be computed?
These key decisions lead to a combinatorial explosion, where hundreds of possible configurations are available for each model and hardware choice. Often, this leads to wasted development time or costly subpar serving decisions.
In this post, we explore how the NVIDIA Triton Model Analyzer can automatically sweep through various serving configurations for your target hardware platform and find the best model configurations based on your application’s needs. This can improve developer productivity while increasing the utilization of serving hardware at the same time.
NVIDIA Triton Model Analyzer
NVIDIA Triton Model Analyzer is a versatile CLI tool that helps with a better understanding of the compute and memory requirements of models served through NVIDIA Triton Inference Server. This enables you to characterize the tradeoffs between different configurations and choose the best one for your use case.
NVIDIA Triton Model Analyzer can be used with all the model formats that NVIDIA Triton Inference Server supports: TensorRT, TensorFlow, PyTorch, ONNX, OpenVINO, and others.
You can specify your application constraints (latency, throughput, or memory) to find the serving configurations that satisfy them. For example, a virtual assistant application might have a certain latency budget for the interaction to feel real-time for the end user. An offline processing workflow should be optimized for throughput to reduce the amount of required hardware and to keep the cost as low as possible. The available memory in the model serving hardware may be limited and necessitate the serving configuration to be optimized for memory.
Figure. 1. Overview of NVIDIA Triton Model Analyzer.
As an example, we take a pretrained model and show how to use NVIDIA Triton Model Analyzer and optimize the serving of this model on a VM instance on Google Cloud Platform. However, the steps shown here can be used on any public cloud or on-premises with any model type that NVIDIA Triton Inference Server supports.
Creating the model
In this post, we use the pretrained BERT Large model from Hugging Face in PyTorch format. NVIDIA Triton Inference Server can serve PyTorch models using its LibTorch backend for TorchScript models or using its Python backend for pure PyTorch models. To get the best performance, we recommend converting PyTorch models to TorchScript format. To this end, use the tracing functionality of PyTorch.
Begin by pulling the PyTorch container from NGC and install the transformers package within the container. If it is your first time using NGC, create an account. We use the 22.04 releases of the relevant tools throughout this post, which were the latest at the time of writing. NVIDIA Triton has a monthly release cadence and ships a new version at the end of every month.
When the transformers package is installed, run the following Python code to download the pretrained BERT Large model and trace it into TorchScript format.
The first step in using NVIDIA Triton Inference Server to serve your models is to create a model repository. In this repository, you include a model configuration file that provides information about the model. At a minimum, a model configuration file must specify the backend, the maximum batch size for the model, and the input/output structure.
For this model, the following code example is the model configuration file. For more information, see Model Configuration.
After naming the model configuration file as config.pbtxt, create a model repository by following the repository layout structure. The folder structure of the model repository should be similar to the following:
Now that you have the Model Analyzer image built, spin up the container:
docker run -it --rm --gpus all
-v /var/run/docker.sock:/var/run/docker.sock
-v :/models
-v :/output
-v :/config
--net=host model-analyzer
Different hardware configurations might lead to different optimal serving configurations. As such, it is important to run Model Analyzer on the target hardware platform where the models will be eventually served from.
For reproducibility of the results we present in this post, we ran our experiments in the public cloud. Specifically, we used an a2-highgpu-1g instance on Google Cloud Platform with a single NVIDIA A100 GPU.
A100 GPUs support Multi-Instance GPU (MIG), which can maximize the GPU utilization by splitting up a single A100 GPU up to seven partitions with hardware-level isolation that can independently run NVIDIA Triton servers. For the sake of simplicity, we did not use MIG for this post. For more information, see Deploying NVIDIA Triton at Scale with MIG and Kubernetes.
Model Analyzer supports automatic and manual sweeping through different configurations for NVIDIA Triton models. Automatic configuration search is the default behavior and enables dynamic batching for all configurations. In this mode, Model Analyzer sweeps through different batch sizes and the number of instances of a model that can handle incoming requests simultaneously.
The default ranges swept through are up to five instances of a model and up to a batch size of 128. These defaults can be changed.
Now create a configuration file named sweep.yaml to analyze the BERT Large model prepared earlier and perform an automatic sweep through the possible configurations.
Using the preceding configuration, you can get the top line and the bottom line numbers for the model throughput and latency, respectively.
Model Analyzer also writes the collected measurements to checkpoint files when profiling. These are located within the specified checkpoint directory. You can use the profiled checkpoints to create data tables, summaries, and detailed reports of the results.
With the configuration file in place, you are now ready to run Model Analyzer:
model-analyzer profile -f /config/sweep.yaml
As a sample, Table 1 shows a few rows from the results. Each row corresponds to an experiment run on a model configuration under a hypothetical client load.
Model
Batch
Concurrency
Model Config Path
Instance Group
Satisfies Constraints
Throughput (infer/sec)
p99 Latency (ms)
bert-large
1
16
bert-large_config_8
2/GPU
Yes
139
150.9
bert-large
1
32
bert-large_config_8
2/GPU
Yes
128
222.1
bert-large
1
8
bert-large_config_8
2/GPU
Yes
123
79.6
bert-large
1
64
bert-large_config_8
2/GPU
Yes
114
442.6
…
…
…
…
…
…
…
…
bert-large
1
16
bert-large_config_default
1/GPU
Yes
66
219.1
Table 1. Sample output from an automatic sweep
To get a more detailed report of each model configuration tested, use the model-analyzer report command:
This generates a report that details the following:
The hardware the analysis was run on
A plot of throughput with respect to latency
A plot of GPU memory with respect to latency
A report for the chosen configurations in the CLI
This is a great start for any MLOps team to start their analysis before putting a model in production.
Different stakeholders, differing constraints
In a typical production environment, there are multiple teams that should work symbiotically to deploy AI models at a large scale in production. For example, there might be an MLOps team responsible for the model serving pipeline stability and handling the changes in the service-level agreements (SLAs) imposed by the applications. Separately, the infrastructure team is usually responsible for the entire GPU/CPU farm.
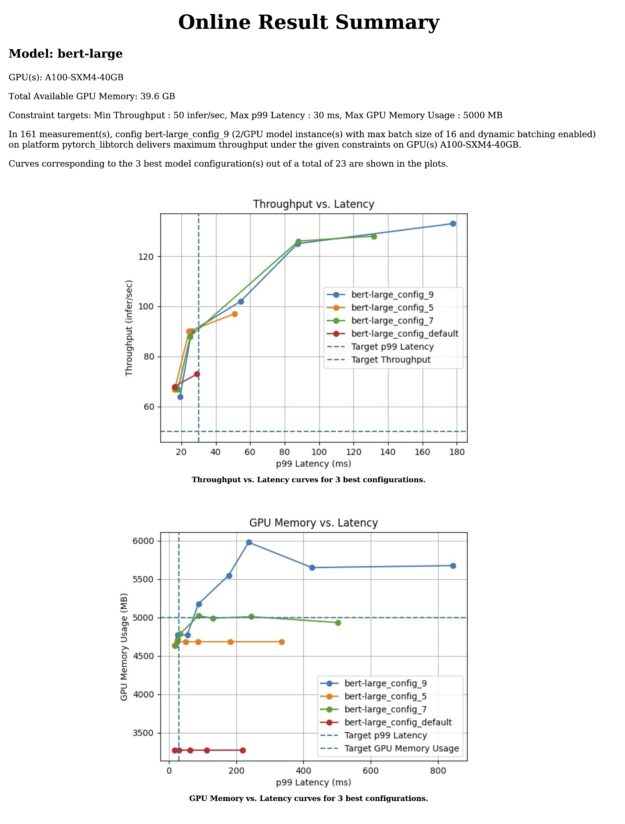
Assume that a product team requested that the MLOps team serve BERT Large with 99% of the requests processed within a latency budget of 30 ms. The MLOps team should consider various serving configurations on the available hardware to satisfy that requirement. Using Model Analyzer removes most of the friction in doing so.
The following code example is an example of a configuration file named latency_constraint.yaml, where we added a constraint on the 99th percentile of measured latency values to satisfy the given SLA.
Because you have the checkpoints from the previous sweep, you can reuse them for the SLA analysis. Running the following command gives you the top three configurations satisfying the latency constraint:
model-analyzer analyze -f latency_constraint.yaml
Table 2 shows the measurements taken for the top three configurations and how they compare to the default configuration.
Model Config Name
Max Batch Size
Dynamic Batching
Instance Count
p99 Latency (ms)
Throughput (infer/sec)
Max CPU Memory Usage (MB)
Max GPU Memory Usage (MB)
Average GPU Utilization (%)
bert-large_config_10
1
Enabled
3/GPU
29.278
92.0
0
6026.0
32.1
bert-large_config_5
1
Enabled
2/GPU
24.269
90.0
0
4683.0
23.3
bert-large_config_9
16
Enabled
2/GPU
25.985
90.0
0
4767.0
13.6
bert-large_config_default
64
Disabled
1/GPU
29.14
73.0
0
3268.0
19.2
Table 2. How each configuration satisfies the latency constraint specified
In large-scale production, the software and the hardware constraints affect the SLA in production.
Assume that the constraints of the application have changed. The team would now like to satisfy a p99 latency of 50 ms along with a throughput of 30+ inferences per second for the same model. Also assume that the infrastructure team is able to spare 5,000 MB of GPU memory for its use. Manually finding a serving configuration to satisfy the stakeholders becomes harder and harder as the number of constraints increases. This is where the need for a solution like Model Analyzer becomes more obvious as you can now specify all of our constraints together in a single configuration file.
The following sample configuration file named multiple_constraint.yaml combines throughput, latency, and GPU memory constraints:
Model Analyzer now finds the serving configurations given below as the top three options and shows how they compare to the default configuration.
Model Config Name
Max Batch Size
Dynamic Batching
Instance Count
p99 Latency (ms)
Throughput (infer/sec)
Max CPU Memory Usage (MB)
Max GPU Memory Usage (MB)
Average GPU Utilization (%)
bert-large_config_9
16
Enabled
2/GPU
25.985
90.0
0
4767.0
13.6
bert-large_config_5
1
Enabled
2/GPU
24.269
90.0
0
4683.0
23.3
bert-large_config_7
4
Enabled
2/GPU
25.216
88.0
0
4717.0
38.7
bert-large_config_default
64
Disabled
1/GPU
29.14
73.0
0
3268.0
19.2
Table 3. How each configuration satisfies all three constraints specified.
NVIDIA Triton Model Analyzer also generates plots and a more detailed report (Figure 2).
Figure 2. Sample report generated by NVIDIA Triton Model Analyzer
Summary
As enterprises find themselves serving more and more models in production, it becomes more and more difficult to make model serving decisions manually or based on heuristics. Doing this manually results in wasted development time or subpar model serving decisions, which necessitates automated tooling.
In this post, we explored how NVIDIA Triton Model Analyzer enables finding model serving configurations satisfying the application SLAs and requirements of various stakeholders. We showed how Model Analyzer can be used to sweep through various configurations, and how it can be used to satisfy specified serving constraints.
Even though we focused on a single model for this post, there are plans to have Model Analyzer perform the same analysis for multiple models at the same time. For example, you could define constraints on different models running on the same GPU and optimize each.
We hope you share our excitement about how much development time Model Analyzer will save and enable your MLOps teams to make well-informed decisions. For more information, see the /triton-inference-server/model_analyzer GitHub repo.
Using an NVIDIA Triton Inference Server, industrial manufacturer Sansera improved quality control and documentation through a custom AI pipeline.
Implementing quality control and assurance methodology in manufacturing processes and quality management systems ensures that end products meet customer requirements and satisfaction. Surface defect detection systems can use image data to perform inspections and classifications for delivering high-quality products. With advancements in AI, real-time defect detection is streamlined and automated using sensors and pretrained AI models for replicable quality control.
Sweden-based company Sansera—a producer of connecting rods for diesel engines—collaborated with AI company Aixia to implement an automated, deep learning defect detection system in their production process using computer vision.
Found in buses, trucks, and ships, every rod in the manufacturing production process must be high quality, consistent, reliable, and documented. It is imperative that the high-resolution, visual inspection system detects and classifies defects in real time.
To help Sansera reach its manufacturing process quality control goals, Aixia developed and deployed a rod inspection and detection pipeline at Sansera’s production site. At the heart of the pipeline, is an NVIDIA Triton Inference Server deployed on the NVIDIA Jetson edge AI platform and data center servers. It is implemented on an x86 server with NVIDIA A10 GPUs for inference.
Using a quality vision inspection system, robots lift and display connecting rods to a set of AI-enabled cameras. The cameras take multiple photos to capture imprints and serial numbers, which are sent through AI-based computer vision models for inspection in a controlled lighting environment. The evaluations are performed in sequence and the results provide quality control documentation. Several deep learning inferences are performed per camera view.
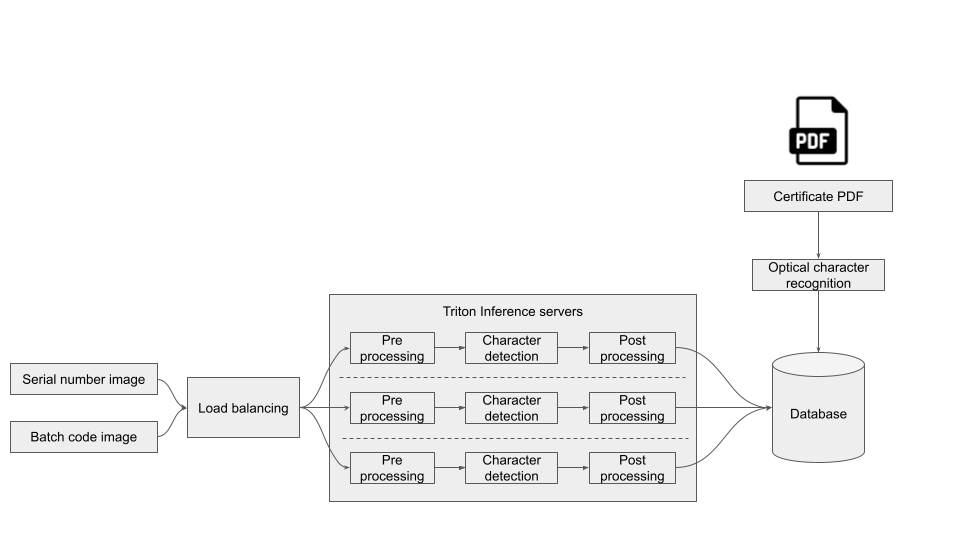
Figure 1. Automatic inspection of a connecting rod. A robot picks up the rod for three cameras mounted left, right, and bottom.
Each connecting rod is inspected and documented properly before release. The job of this inference workflow is to detect the imprints, inspect their quality, and provide necessary details for the product documentation. The workflow is deployed and optimized on an NVIDIA Triton Inference Server, using different frameworks and consolidates quality use cases in a streamlined fashion.
Several models, in both pre-and post-processing, are consolidated within one server instance.
Figure 2. Scalable deployment of NVIDIA Triton inference server with here the pre-and post-processing of the image.
Using NVIDIA Triton, Aixia deploys optimized versions of the pretrained models, in the data center using high-performance GPUs, or on the edge close to the data using the Jetson edge AI platform.

") Announcing NVIDIA Isaac Transport for ROS (NITROS) pipelines that use new ROS Humble features developed jointly with Open Robotics.
Announcing NVIDIA Isaac Transport for ROS (NITROS) pipelines that use new ROS Humble features developed jointly with Open Robotics.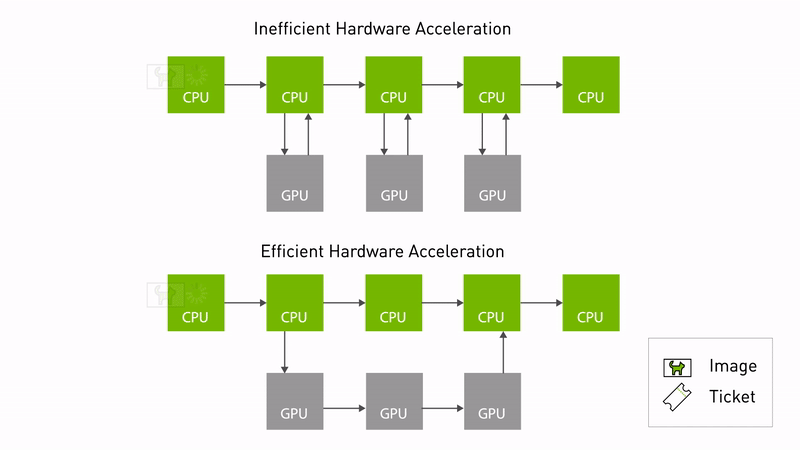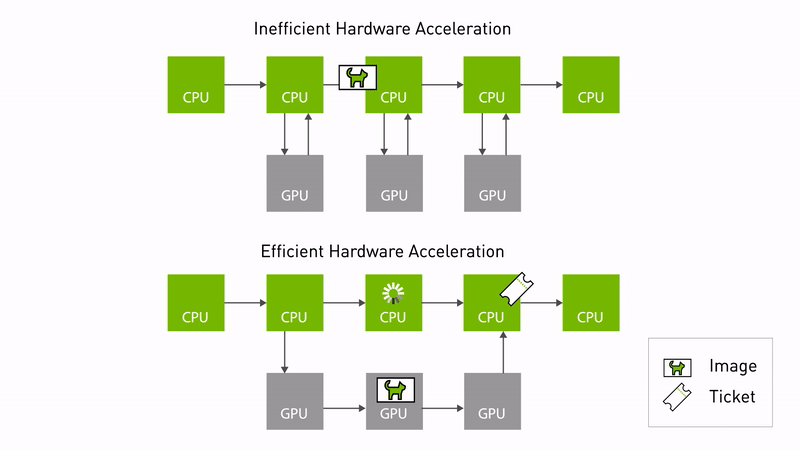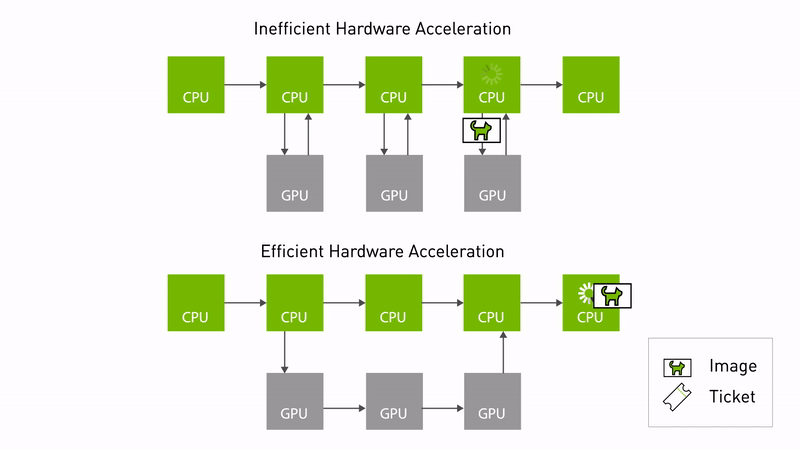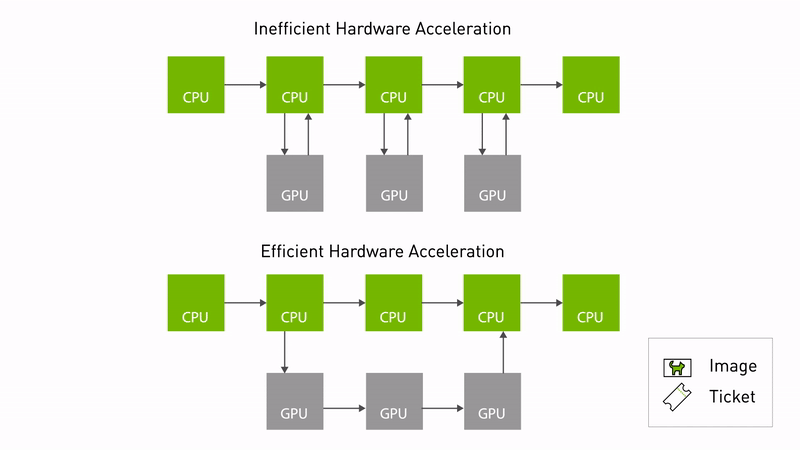


 Users can now produce 3D virtual worlds at human scale with the new Omniverse XR App available in beta from the NVIDIA Omniverse launcher.
Users can now produce 3D virtual worlds at human scale with the new Omniverse XR App available in beta from the NVIDIA Omniverse launcher.
 This post presents an overview of NVIDIA Triton Model Analyzer and how it can be used to find the optimal AI model-serving configuration to satisfy application requirements.
This post presents an overview of NVIDIA Triton Model Analyzer and how it can be used to find the optimal AI model-serving configuration to satisfy application requirements.
 Using an NVIDIA Triton Inference Server, industrial manufacturer Sansera improved quality control and documentation through a custom AI pipeline.
Using an NVIDIA Triton Inference Server, industrial manufacturer Sansera improved quality control and documentation through a custom AI pipeline.