
This week, the 23rd Annual Conference of the International Speech Communication Association (INTERSPEECH 2022) is being held in Incheon, South Korea, representing one of the world’s most extensive conferences on research and technology of spoken language understanding and processing. Over 2,000 experts in speech-related research fields gather to take part in oral presentations and poster sessions and to collaborate with streamed events across the globe.
We are excited to be a Diamond Sponsor of INTERSPEECH 2022, where we will be showcasing nearly 50 research publications and supporting a number of workshops, special sessions and tutorials. We welcome in-person attendees to drop by the Google booth to meet our researchers and participate in Q&As and demonstrations of some of our latest speech technologies, which help to improve accessibility and provide convenience in communication for billions of users. In addition, online attendees are encouraged to visit our virtual booth in GatherTown where you can get up-to-date information on research and opportunities at Google. You can also learn more about the Google research being presented at INTERSPEECH 2022 below (Google affiliations in bold).
Organizing Committee
Industry Liaisons include: Bhuvana Ramabahdran
Area Chairs include: John Hershey, Heiga Zen, Shrikanth Narayanan, Bastiaan Kleijn
ISCA Fellows
Include: Tara Sainath, Heiga Zen
Publications
Production Federated Keyword Spotting via Distillation, Filtering, and Joint Federated-Centralized Training
Andrew Hard, Kurt Partridge, Neng Chen, Sean Augenstein, Aishanee Shah, Hyun Jin Park, Alex Park, Sara Ng, Jessica Nguyen, Ignacio Lopez Moreno, Rajiv Mathews, Françoise Beaufays
Leveraging Unsupervised and Weakly-Supervised Data to Improve Direct Speech-to-Speech Translation
Ye Jia, Yifan Ding, Ankur Bapna, Colin Cherry, Yu Zhang, Alexis Conneau, Nobu Morioka
Sentence-Select: Large-Scale Language Model Data Selection for Rare-Word Speech Recognition
W. Ronny Huang, Cal Peyser, Tara N. Sainath, Ruoming Pang, Trevor Strohman, Shankar Kumar
UserLibri: A Dataset for ASR Personalization Using Only Text
Theresa Breiner, Swaroop Ramaswamy, Ehsan Variani, Shefali Garg, Rajiv Mathews, Khe Chai Sim, Kilol Gupta, Mingqing Chen, Lara McConnaughey
SNRi Target Training for Joint Speech Enhancement and Recognition
Yuma Koizumi, Shigeki Karita, Arun Narayanan, Sankaran Panchapagesan, Michiel Bacchiani
Turn-Taking Prediction for Natural Conversational Speech
Shuo-Yiin Chang, Bo Li, Tara Sainath, Chao Zhang, Trevor Strohman, Qiao Liang, Yanzhang He
Streaming Intended Query Detection Using E2E Modeling for Continued Conversation
Shuo-Yiin Chang, Guru Prakash, Zelin Wu, Tara Sainath, Bo Li, Qiao Liang, Adam Stambler, Shyam Upadhyay, Manaal Faruqui, Trevor Strohman
Improving Distortion Robustness of Self-Supervised Speech Processing Tasks with Domain Adaptation
Kuan Po Huang, Yu-Kuan Fu, Yu Zhang, Hung-yi Lee
XLS-R: Self-Supervised Cross-Lingual Speech Representation Learning at Scale
Arun Babu, Changhan Wang, Andros Tjandra, Kushal Lakhotia, Qiantong Xu, Naman Goyal, Kritika Singh, Patrick von Platen, Yatharth Saraf, Juan Pino, Alexei Baevski, Alexis Conneau, Michael Auli
Extracting Targeted Training Data from ASR Models, and How to Mitigate It
Ehsan Amid, Om Thakkar, Arun Narayanan, Rajiv Mathews, Françoise Beaufays
Detecting Unintended Memorization in Language-Model-Fused ASR
W. Ronny Huang, Steve Chien, Om Thakkar, Rajiv Mathews
AVATAR: Unconstrained Audiovisual Speech Recognition
Valentin Gabeur, Paul Hongsuck Seo, Arsha Nagrani, Chen Sun, Karteek Alahari, Cordelia Schmid
End-to-End Multi-talker Audio-Visual ASR Using an Active Speaker Attention Module
Richard Rose, Olivier Siohan
Transformer-Based Video Front-Ends for Audio-Visual Speech Recognition for Single and Multi-person Video
Dmitriy Serdyuk, Otavio Braga, Olivier Siohan
Unsupervised Data Selection via Discrete Speech Representation for ASR
Zhiyun Lu, Yongqiang Wang, Yu Zhang, Wei Han, Zhehuai Chen, Parisa Haghani
Non-parallel Voice Conversion for ASR Augmentation
Gary Wang, Andrew Rosenberg, Bhuvana Ramabhadran, Fadi Biadsy, Jesse Emond, Yinghui Huang, Pedro J. Moreno
Ultra-Low-Bitrate Speech Coding with Pre-trained Transformers
Ali Siahkoohi, Michael Chinen, Tom Denton, W. Bastiaan Kleijn, Jan Skoglund
Streaming End-to-End Multilingual Speech Recognition with Joint Language Identification
Chao Zhang, Bo Li, Tara Sainath, Trevor Strohman, Sepand Mavandadi, Shuo-Yiin Chang, Parisa Haghani
Improving Deliberation by Text-Only and Semi-supervised Training
Ke Hu, Tara N. Sainath, Yanzhang He, Rohit Prabhavalkar, Trevor Strohman, Sepand Mavandadi, Weiran Wang
E2E Segmenter: Joint Segmenting and Decoding for Long-Form ASR
W. Ronny Huang, Shuo-yiin Chang, David Rybach, Rohit Prabhavalkar, Tara N. Sainath, Cyril Allauzen, Cal Peyser, Zhiyun Lu
CycleGAN-Based Unpaired Speech Dereverberation
Alexis Conneau, Ankur Bapna, Yu Zhang, Min Ma, Patrick von Platen, Anton Lozhkov, Colin Cherry, Ye Jia, Clara Rivera, Mihir Kale, Daan van Esch, Vera Axelrod, Simran Khanuja, Jonathan Clark, Orhan Firat, Michael Auli, Sebastian Ruder, Jason Riesa, Melvin Johnson
TRILLsson: Distilled Universal Paralinguistic Speech Representations (see blog post)
Joel Shor, Subhashini Venugopalan
Learning Neural Audio Features Without Supervision
Sarthak Yadav, Neil Zeghidour
SpeechPainter: Text-Conditioned Speech Inpainting
Zalan Borsos, Matthew Sharifi, Marco Tagliasacchi
SpecGrad: Diffusion Probabilistic Model-Based Neural Vocoder with Adaptive Noise Spectral Shaping
Yuma Koizumi, Heiga Zen, Kohei Yatabe, Nanxin Chen, Michiel Bacchiani
Distance-Based Sound Separation
Katharine Patterson, Kevin Wilson, Scott Wisdom, John R. Hershey
Analysis of Self-Attention Head Diversity for Conformer-Based Automatic Speech Recognition
Kartik Audhkhasi, Yinghui Huang, Bhuvana Ramabhadran, Pedro J. Moreno
Improving Rare Word Recognition with LM-Aware MWER Training
Wang Weiran, Tongzhou Chen, Tara Sainath, Ehsan Variani, Rohit Prabhavalkar, W. Ronny Huang, Bhuvana Ramabhadran, Neeraj Gaur, Sepand Mavandadi, Cal Peyser, Trevor Strohman, Yanzhang He, David Rybach
MAESTRO: Matched Speech Text Representations Through Modality Matching
Zhehuai Chen, Yu Zhang, Andrew Rosenberg, Bhuvana Ramabhadran, Pedro J. Moreno, Ankur Bapna, Heiga Zen
Pseudo Label is Better Than Human Label
Dongseong Hwang, Khe Chai Sim, Zhouyuan Huo, Trevor Strohman
On the Optimal Interpolation Weights for Hybrid Autoregressive Transducer Model
Ehsan Variani, Michael Riley, David Rybach, Cyril Allauzen, Tongzhou Chen, Bhuvana Ramabhadran
Streaming Align-Refine for Non-autoregressive Deliberation
Wang Weiran, Ke Hu, Tara Sainath
Federated Pruning: Improving Neural Network Efficiency with Federated Learning
Rongmei Lin*, Yonghui Xiao, Tien-Ju Yang, Ding Zhao, Li Xiong, Giovanni Motta, Françoise Beaufays
A Unified Cascaded Encoder ASR Model for Dynamic Model Sizes
Shaojin Ding, Weiran Wang, Ding Zhao, Tara N Sainath, Yanzhang He, Robert David, Rami Botros, Xin Wang, Rina Panigrahy, Qiao Liang, Dongseong Hwang, Ian McGraw, Rohit Prabhavalkar, Trevor Strohman
4-Bit Conformer with Native Quantization Aware Training for Speech Recognition
Shaojin Ding, Phoenix Meadowlark, Yanzhang He, Lukasz Lew, Shivani Agrawal, Oleg Rybakov
Visually-Aware Acoustic Event Detection Using Heterogeneous Graphs
Amir Shirian, Krishna Somandepalli, Victor Sanchez, Tanaya Guha
A Conformer-Based Waveform-Domain Neural Acoustic Echo Canceller Optimized for ASR Accuracy
Sankaran Panchapagesan, Arun Narayanan, Turaj Zakizadeh Shabestary, Shuai Shao, Nathan Howard, Alex Park, James Walker, Alexander Gruenstein
Reducing Domain Mismatch in Self-Supervised Speech Pre-training
Murali Karthick Baskar, Andrew Rosenberg, Bhuvana Ramabhadran, Yu Zhang, Nicolás Serrano
On-the-Fly ASR Corrections with Audio Exemplars
Golan Pundak, Tsendsuren Munkhdalai, Khe Chai Sim
A Language Agnostic Multilingual Streaming On-Device ASR System
Bo Li, Tara Sainath, Ruoming Pang*, Shuo-Yiin Chang, Qiumin Xu, Trevor Strohman, Vince Chen, Qiao Liang, Heguang Liu, Yanzhang He, Parisa Haghani, Sameer Bidichandani
XTREME-S: Evaluating Cross-Lingual Speech Representations
Alexis Conneau, Ankur Bapna, Yu Zhang, Min Ma, Patrick von Platen, Anton Lozhkov, Colin Cherry, Ye Jia, Clara Rivera, Mihir Kale, Daan van Esch, Vera Axelrod, Simran Khanuja, Jonathan Clark, Orhan Firat, Michael Auli, Sebastian Ruder, Jason Riesa, Melvin Johnson
Towards Disentangled Speech Representations
Cal Peyser, Ronny Huang, Andrew Rosenberg, Tara Sainath, Michael Picheny, Kyunghyun Cho
Personal VAD 2.0: Optimizing Personal Voice Activity Detection for On-Device Speech Recognition
Shaojin Ding, Rajeev Rikhye, Qiao Liang, Yanzhang He, Quan Wang, Arun Narayanan, Tom O’Malley, Ian McGraw
A Universally-Deployable ASR Frontend for Joint Acoustic Echo Cancellation, Speech Enhancement, and Voice Separation
Tom O’Malley, Arun Narayanan, Quan Wang
Training Text-To-Speech Systems From Synthetic Data: A Practical Approach For Accent Transfer Tasks
Lev Finkelstein, Heiga Zen, Norman Casagrande, Chun-an Chan, Ye Jia, Tom Kenter, Alex Petelin, Jonathan Shen*, Vincent Wan, Yu Zhang, Yonghui Wu, Robert Clark
A Scalable Model Specialization Framework for Training and Inference Using Submodels and Its Application to Speech Model Personalization
Fadi Biadsy, Youzheng Chen, Xia Zhang, Oleg Rybakov, Andrew Rosenberg, Pedro Moreno
Text-Driven Separation of Arbitrary Sounds
Kevin Kilgour, Beat Gfeller, Qingqing Huang, Aren Jansen, Scott Wisdom, Marco Tagliasacchi
Workshops, Tutorials & Special Sessions
The VoxCeleb Speaker Recognition Challenge 2022 (VoxSRC-22)
Organizers include: Arsha Nagrani
Self-Supervised Representation Learning for Speech Processing
Organizers include: Tara Sainath
Learning from Weak Labels
Organizers include: Ankit Shah
RNN Transducers for Named Entity Recognition with Constraints on Alignment for Understanding Medical Conversations
Authors: Hagen Soltau, Izhak Shafran, Mingqiu Wang, Laurent El Shafey
Listening with Googlears: Low-Latency Neural Multiframe Beamforming and Equalization for Hearing Aids
Authors: Samuel Yang, Scott Wisdom, Chet Gnegy, Richard F. Lyon, Sagar Savla
Using Rater and System Metadata to Explain Variance in the VoiceMOS Challenge 2022 Dataset
Authors: Michael Chinen, Jan Skoglund, Chandan K. A. Reddy, Alessandro Ragano, Andrew Hines
Incremental Layer-Wise Self-Supervised Learning for Efficient Unsupervised Speech Domain Adaptation On Device
Authors: Zhouyuan Huo, Dongseong Hwang, Khe Chai Sim, Shefali Garg, Ananya Misra, Nikhil Siddhartha, Trevor Strohman, Françoise Beaufays
Trustworthy Speech Processing
Organizers include: Shrikanth Narayanan
*Work done while at Google. ↩
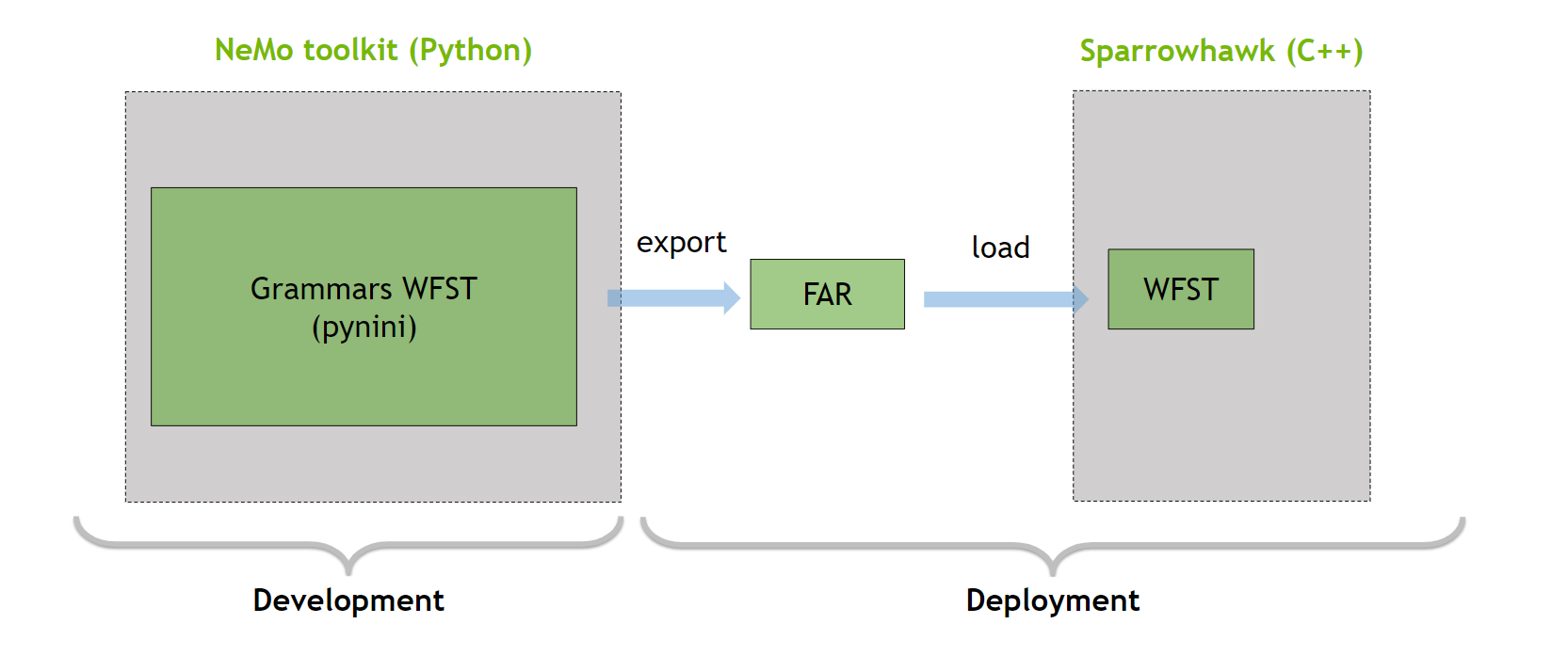
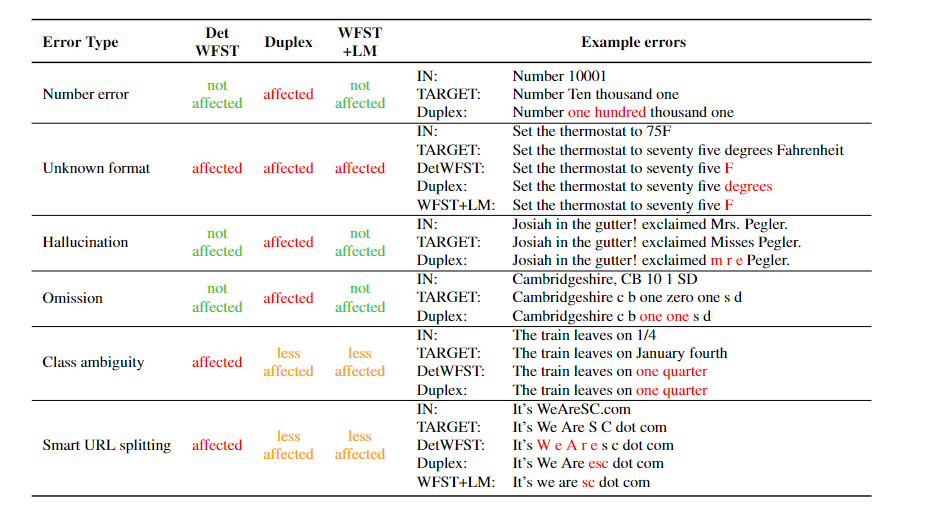
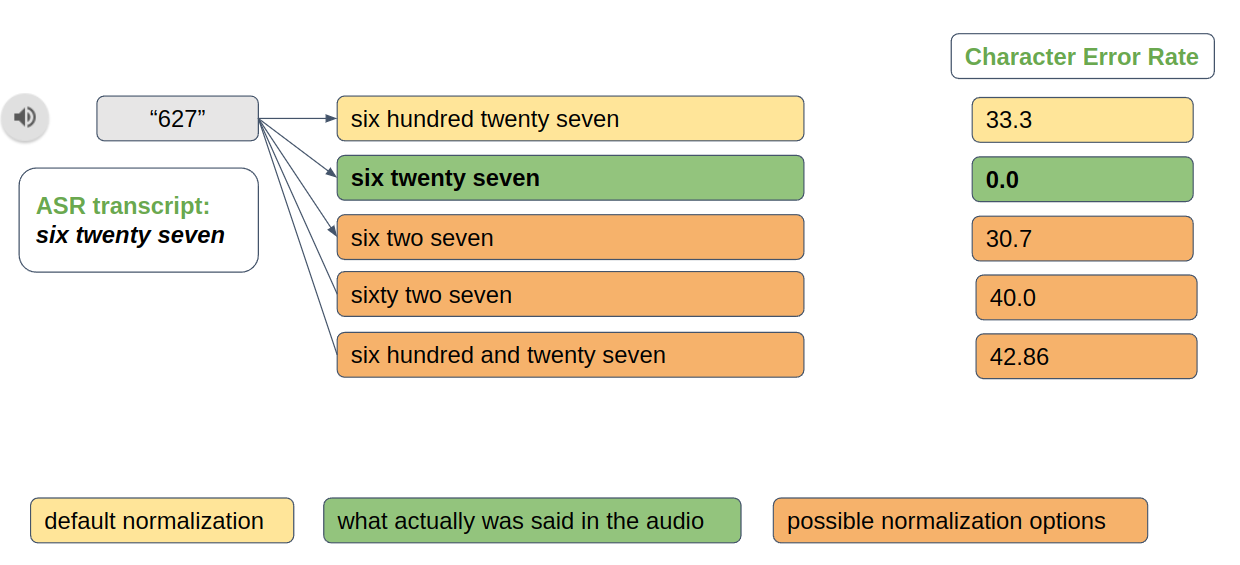
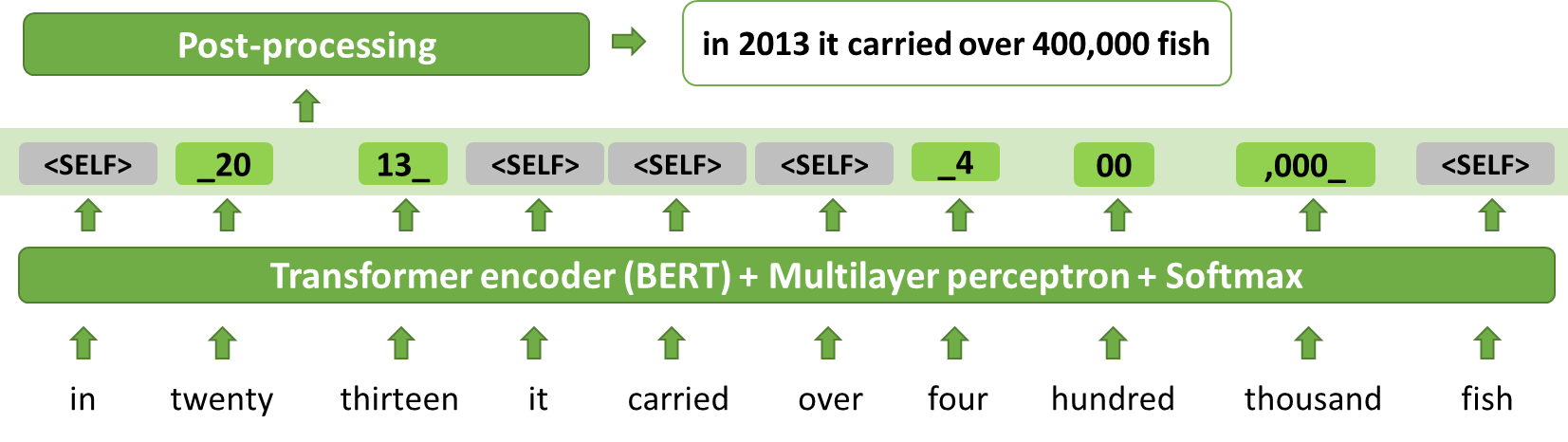
 Text normalization (TN) converts text from written form into its verbalized form, and it is an essential preprocessing step before text-to-speech (TTS). TN…
Text normalization (TN) converts text from written form into its verbalized form, and it is an essential preprocessing step before text-to-speech (TTS). TN…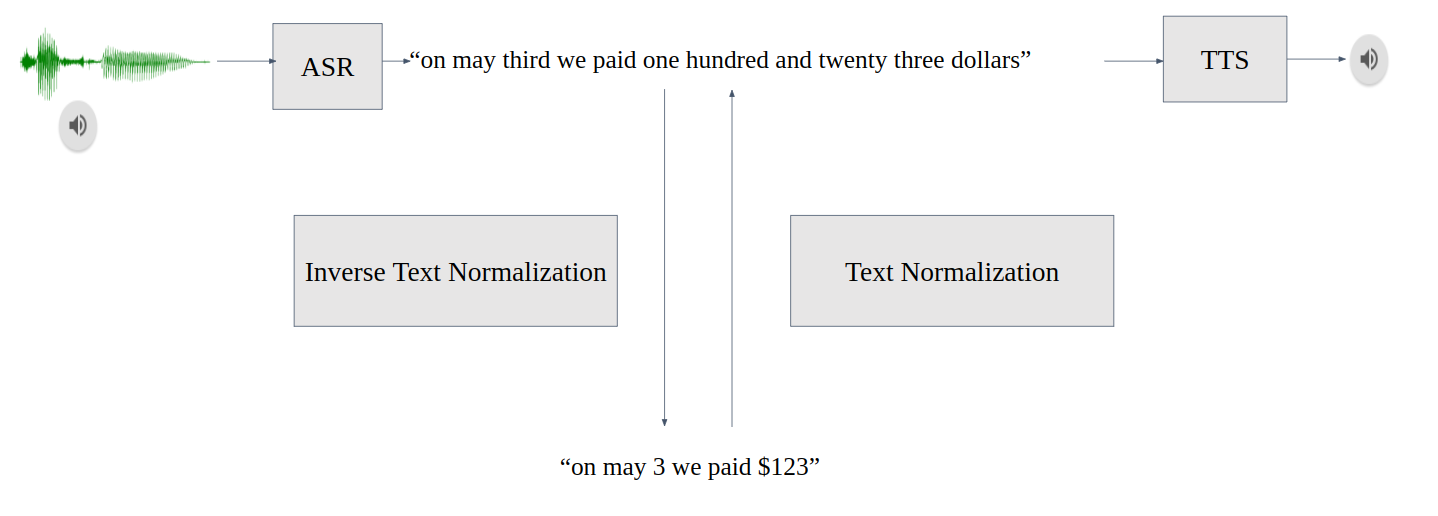



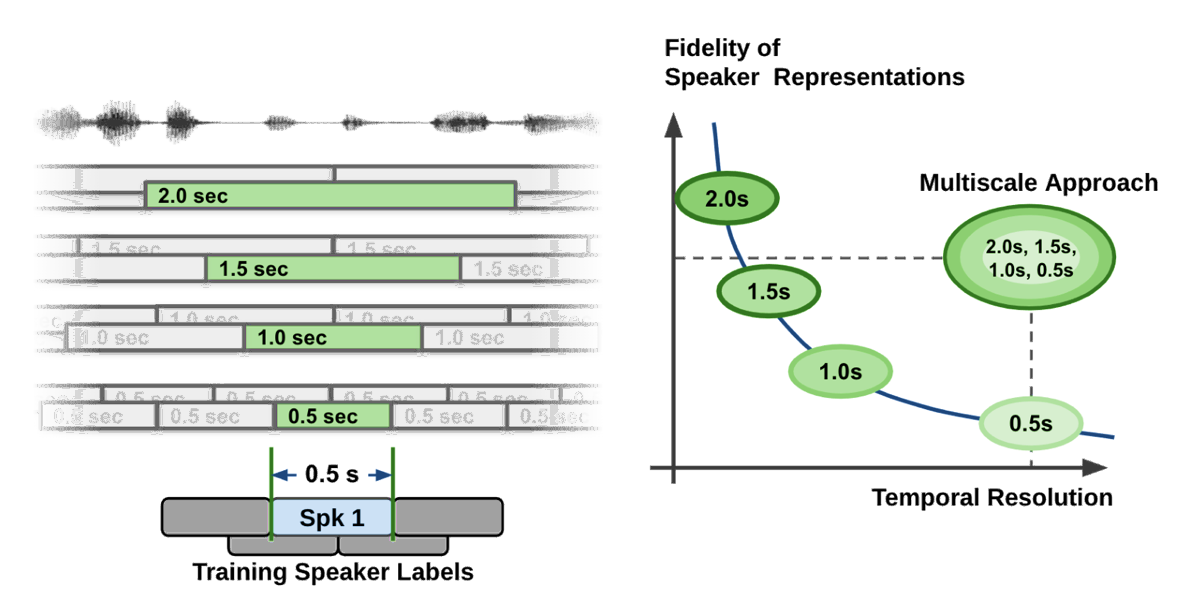
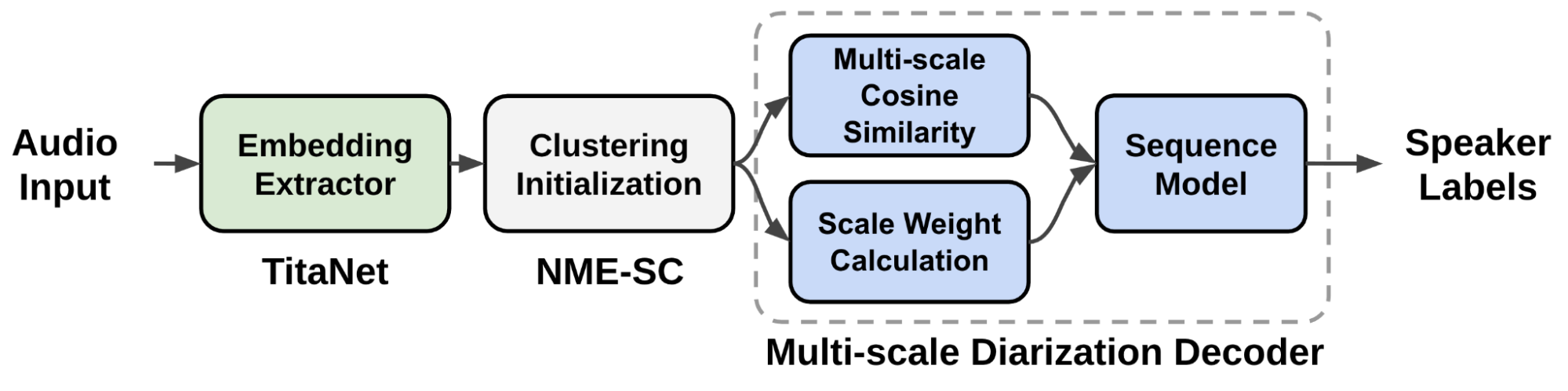
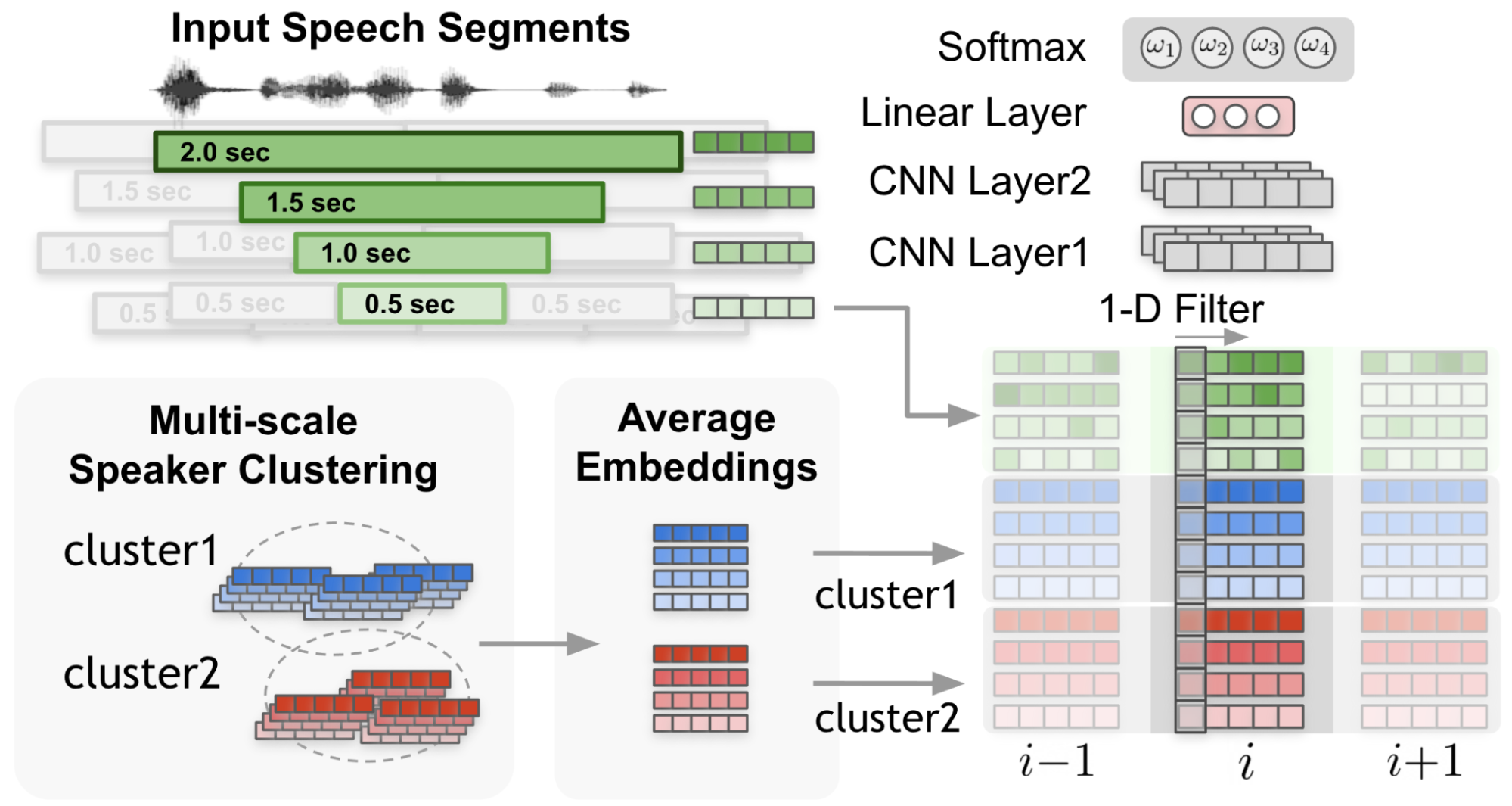
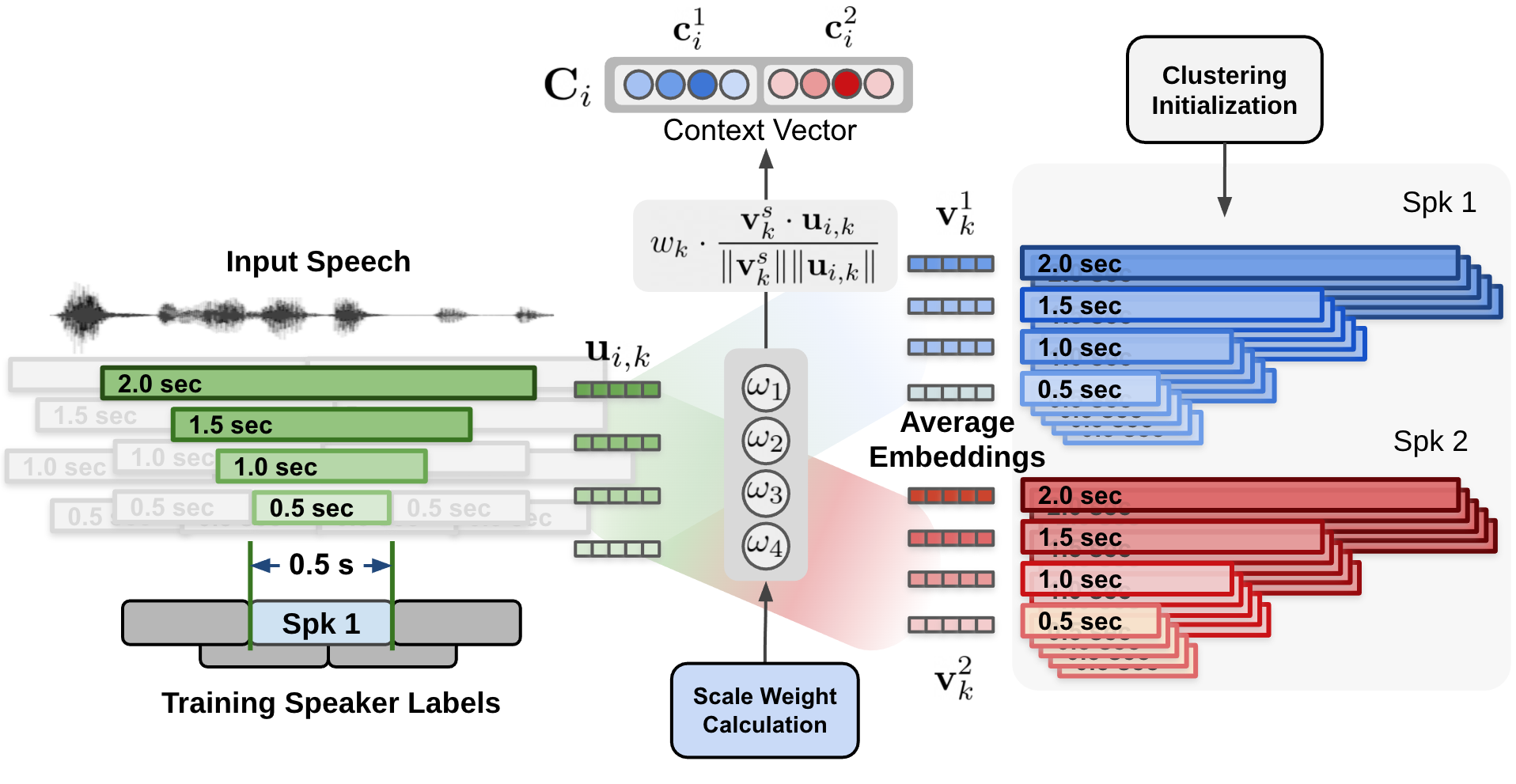
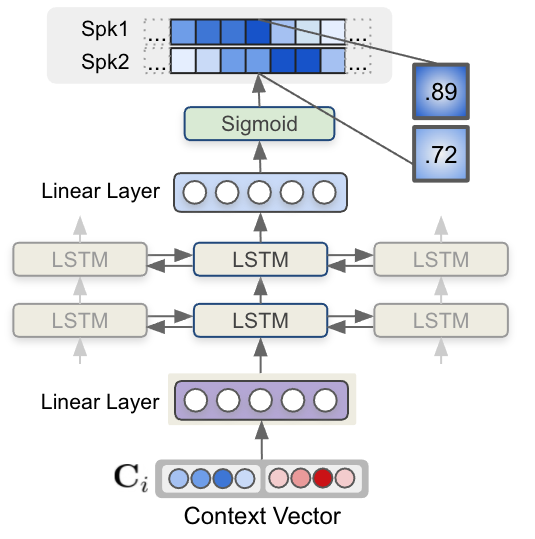
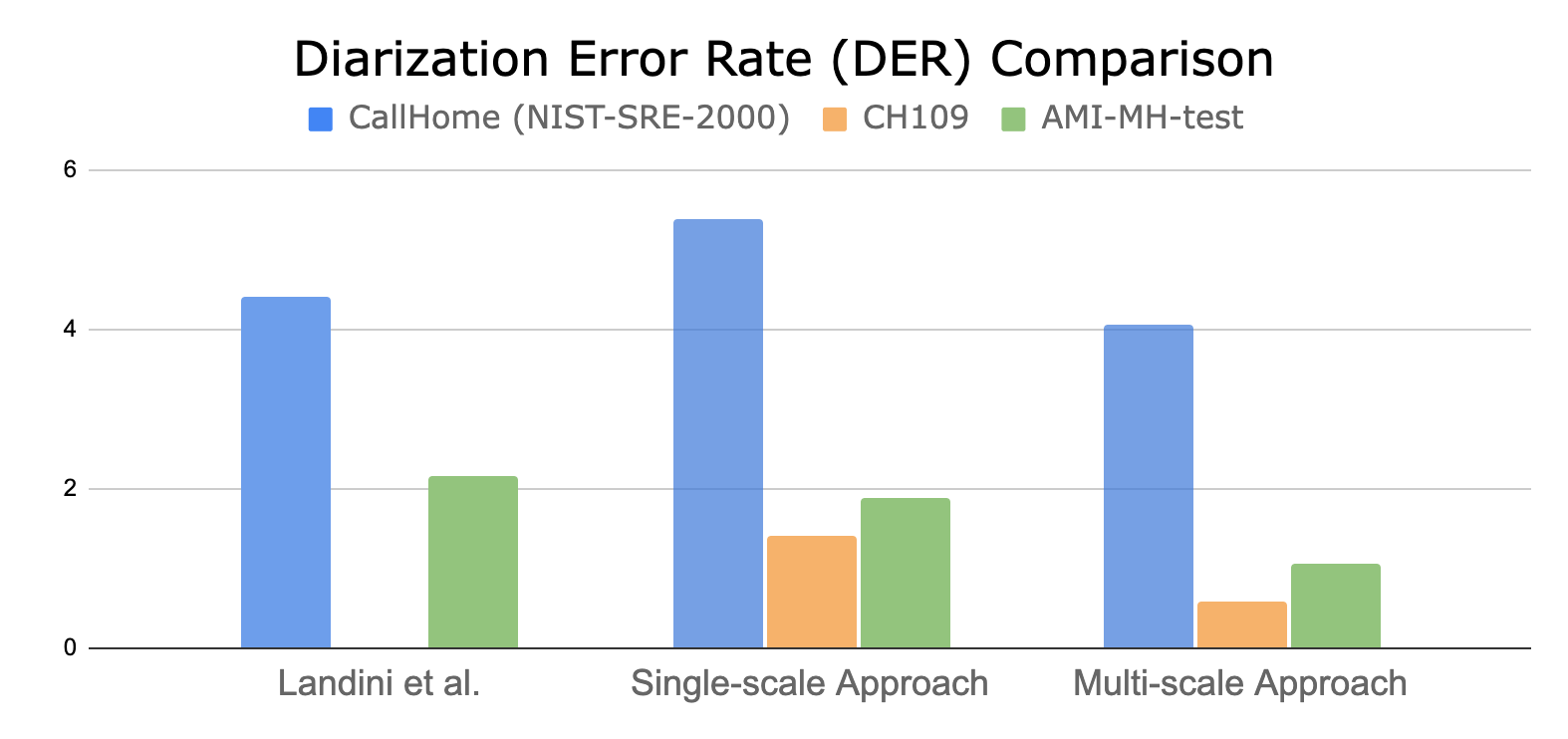
 Speaker diarization is the process of segmenting audio recordings by speaker labels and aims to answer the question “Who spoke when?”. It makes a clear…
Speaker diarization is the process of segmenting audio recordings by speaker labels and aims to answer the question “Who spoke when?”. It makes a clear…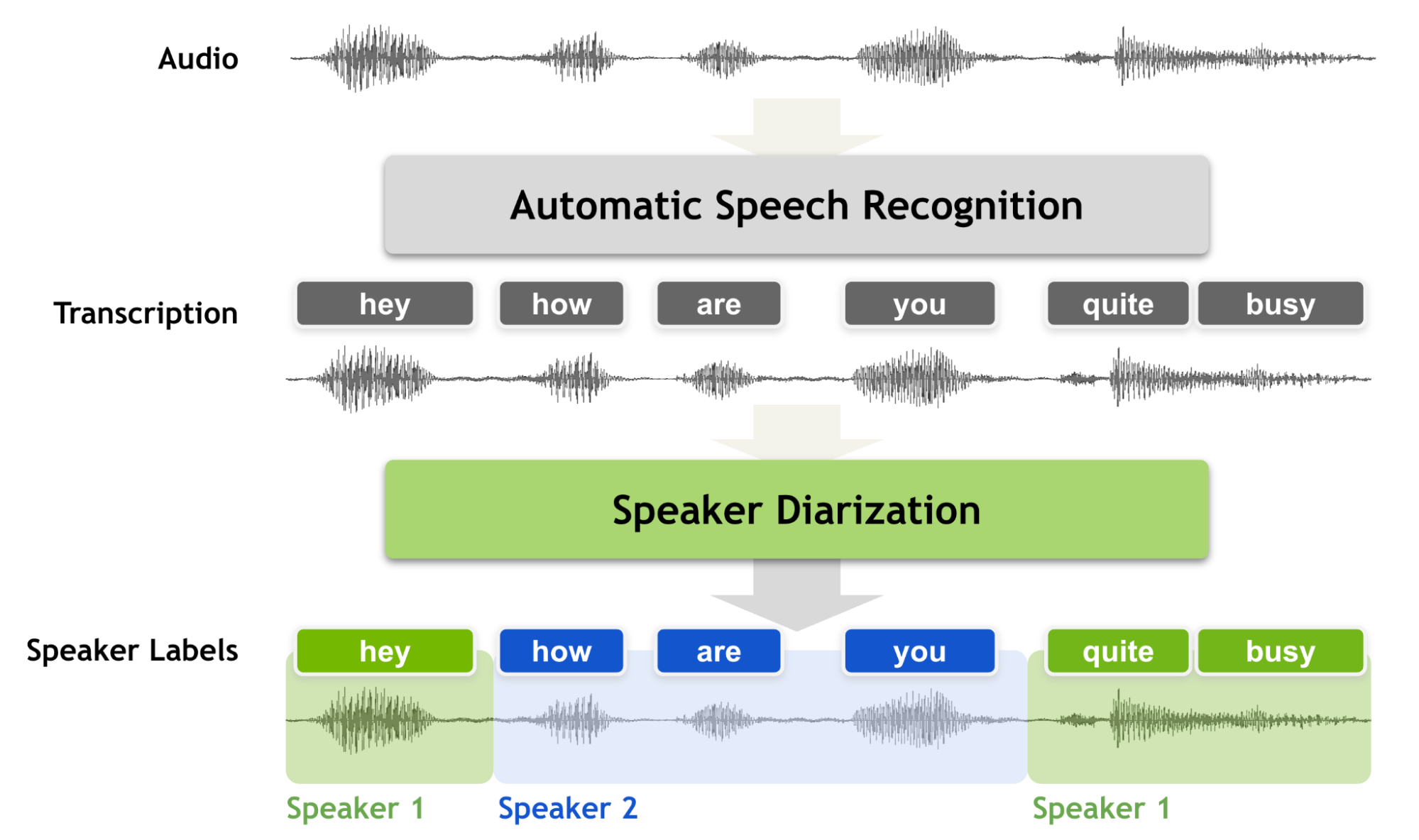











 Learn about new CUDA features, digital twins for weather and climate, quantum circuit simulations, and much more with these GTC 2022 sessions.
Learn about new CUDA features, digital twins for weather and climate, quantum circuit simulations, and much more with these GTC 2022 sessions.  There is an abundance of market-approved medical AI software that can be used to improve patient care and hospital operations, but we have not yet seen these…
There is an abundance of market-approved medical AI software that can be used to improve patient care and hospital operations, but we have not yet seen these…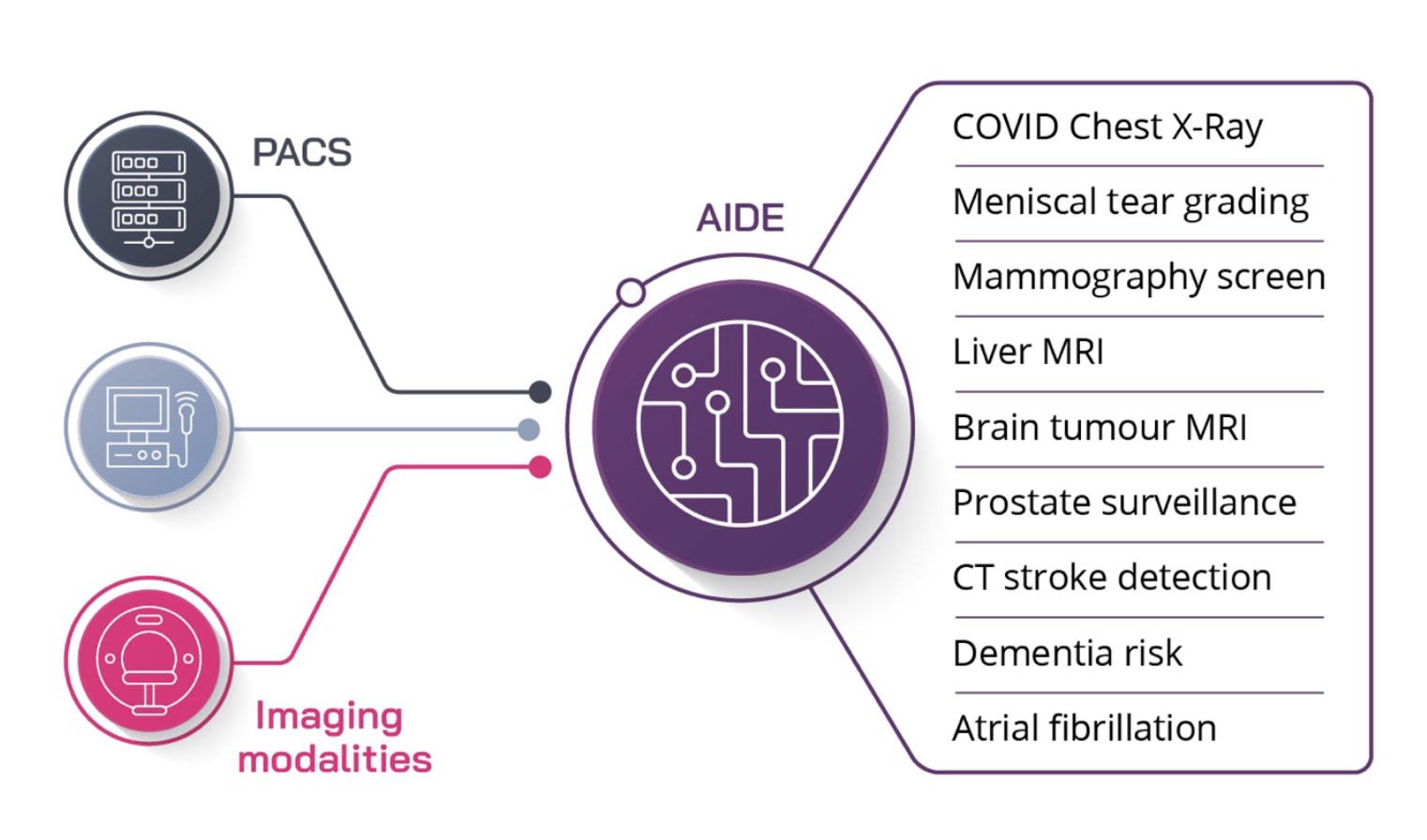
 Join us for these featured GTC 2022 sessions to learn about optimizing PyTorch models, accelerating graph neural networks, improving GPU performance with…
Join us for these featured GTC 2022 sessions to learn about optimizing PyTorch models, accelerating graph neural networks, improving GPU performance with…