
 This post covers how network professionals can update their data center network infrastructure and protocol stack.
This post covers how network professionals can update their data center network infrastructure and protocol stack.
Data centers can be optimized by updating key network architectures in two ways: through networking technologies or operational efficiency in NetDevOps. In this post, we identify and evaluate technologies that you can apply to your network architecture to optimize your network.
We address five updates that you should consider for improving your data center:
- Replace layer 2 VLANs with VXLAN.
- Use Address Resolution Protocol (ARP) suppression to reduce broadcast propagation.
- Replace multi-chassis link aggregation group (MLAG) with EVPN multihoming.
- Handle traffic balancing with equal-cost multi-path (ECMP) routing and UCMP.
- Accommodate traffic polarization with adaptive routing.
Replace VLANs with VXLANs
VXLAN is an overlay technology that uses encapsulation to allow a layer 2 overlay VLANs to span across layer 3 networks. Layer 2 networks have some inherent disadvantages:
- Because they rely on spanning tree protocol (STP), the capability for redundancy and multiple paths is limited by the functionality of spanning tree.
- They can only operate within one subnet, and redundancy is normally only limited to two devices due to MLAG.
- Any path-level redundancy requires the Link Aggregation Control Protocol (LACP), the standard redundancy technology for ports.
VXLAN overcomes these deficiencies and allows the network operator to optimize on a layer 3 routed fabric. A layer 2 overlay can still be accomplished, but no longer requires spanning tree for control plane convergence due to the reliance of EVPN as the control plane.
EVPN exchanges MAC information through a BGP address family, instead of relying on the inefficiencies of broadcast flood and learn. Plus, VXLAN uses a 24-bit ID that can define up to 16 million virtual networks, whereas VLAN only has a 12-bit ID and is limited to 4094 virtual networks.
Use ARP suppression to reduce broadcast propagation
Broadcast traffic in data centers with VXLAN can be further optimized with ARP suppression. ARP suppression helps reduce traffic by using EVPN to proxy responses to ARP requests directly to clients from the ToR virtual tunnel end point (VTEP).
- Without ARP suppression, all ARP requests are broadcast throughout the entire VXLAN fabric, sent to every VTEP that has a VNI for the network.
- With ARP suppression enabled, MAC addresses learned over EVPN are passed down to the ARP control plane.
The leaf switch, which acts as the VTEP, responds directly back to the ARP requester through a proxy ARP reply.
Because the IP-to-MAC mappings are already communicated through the VXLAN control plane using EVPN type 2 messages, implementing ARP suppression enables optimization for faster resolution of the overlay control plane. It also reduces the amount of broadcast traffic in the fabric, as ARP suppression reduces the need for flooding ARP requests to every VTEP in the VXLAN infrastructure.
Replace MLAG with EVPN multihoming
Sometimes MLAG is still required in VXLAN environments for redundant host connectivity. EVPN multihoming is an opportunity to move off proprietary MLAG solutions that do not scale beyond one level of device redundancy.
As I mentioned earlier, VXLAN helps remove the need for back-to-back leaf-to-spine switch connections as required by MLAG. EVPN multihoming goes one step further and eliminates any need for MLAG in server-to-leaf connectivity.
Multihoming uses EVPN messages to communicate host connectivity, and it dynamically builds L2 adjacency to servers using host connectivity information. Where MLAG requires LAG IDs, multihoming uses Ethernet segment IDs. Interfaces are mapped to segments that act like logical connections to the same end host.
Additionally, moving to multihoming improves network vendor interoperability by using a protocol standard form of redundancy in the switch. Because multihoming uses BGP, an open standard protocol, any vendor implementing multihoming through the RFC specification can be part of the Ethernet segment.
ECMP and UCMP to handle traffic balancing
ECMP is a standard function in most layer 3 routing protocols where equal-cost routes are balanced across all available next-hop uplinks. Layer 2 control plane technologies like spanning-tree only allow equal-cost balancing by relying on external technologies like LACP.
ECMP is a native functionality in layer 3 routing, which enables you to get more efficiency out of your network devices.
There are cases where ECMP may lead to inefficient forwarding, specifically when doing a full layer 3 solution where point-to-point L3 links are used everywhere in the fabric, even to the host. In this case, you may want to balance traffic on a metric other than the number of links. UCMP can be useful here, as it uses BGP tags to create a distribution of traffic across hops to align better to your application distribution.
Accommodate traffic polarization with adaptive routing
Adaptive routing is an existing InfiniBand technology adopted by Ethernet switching. Adaptive routing monitors link bandwidth, link utilization, switch buffers, and ECN/PFC to understand when traffic on a specific path has become congested and would benefit from being dynamically rerouted through a less congested path.
Based on meeting these metric’s thresholds, the switch can redirect traffic from one egress interface to another egress interface in the ECMP group. This helps in fully leveraging all links on the switch equally, without the threat of polarization creating an inefficient traffic flow.
The goal of adaptive routing is to take any manual tuning intervention out of the hands of a network admin and let the infrastructure handle the optimizations for aggregate flow balancing.
Conclusion
In this post, we covered some concepts available in data center networking that can help you optimize a network infrastructure by focusing on the protocol stack and data plane. These optimizations provide better network virtualization, help reduce unnecessary control traffic on the infrastructure, and balance traffic across existing layer 1 links to fully use all the bandwidth available.
- For more information, see the following resources:
NVIDIA Networking Solutions - EVPN Enhancements – ARP Suppression
- EVPN Multihoming
- Equal-Cost Multi-path Load Sharing – Hardware ECMP
- Unequal-Cost Multi-path with BGP Link Bandwidth
 Join expert speakers and the developer community at WeAreDevelopers World Congress June 14-15, to exchange ideas, share knowledge, and facilitate networking.
Join expert speakers and the developer community at WeAreDevelopers World Congress June 14-15, to exchange ideas, share knowledge, and facilitate networking.







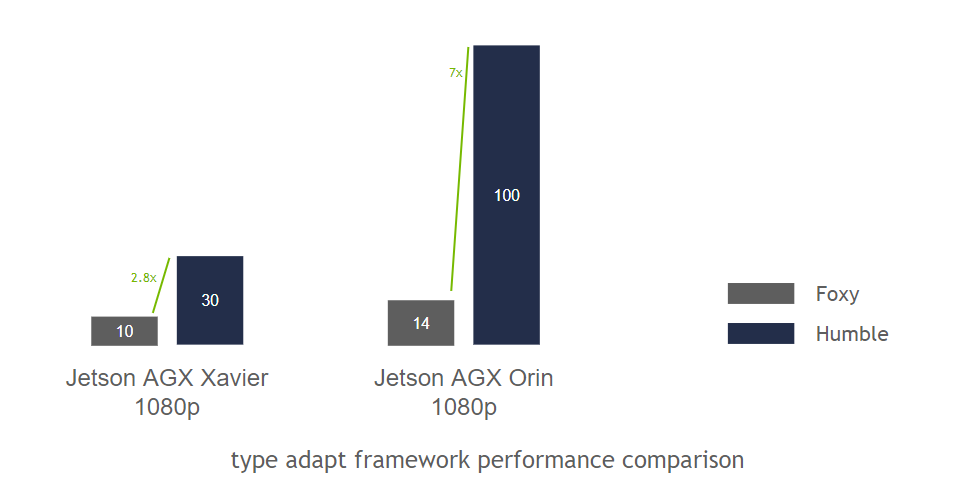
") Announcing NVIDIA Isaac Transport for ROS (NITROS) pipelines that use new ROS Humble features developed jointly with Open Robotics.
Announcing NVIDIA Isaac Transport for ROS (NITROS) pipelines that use new ROS Humble features developed jointly with Open Robotics.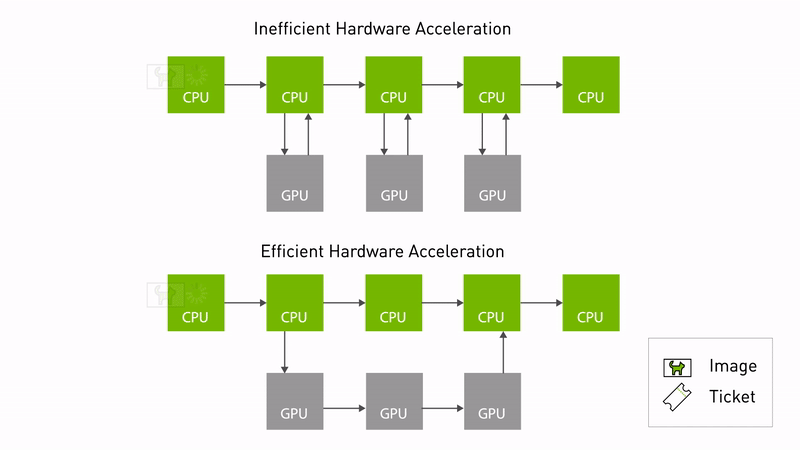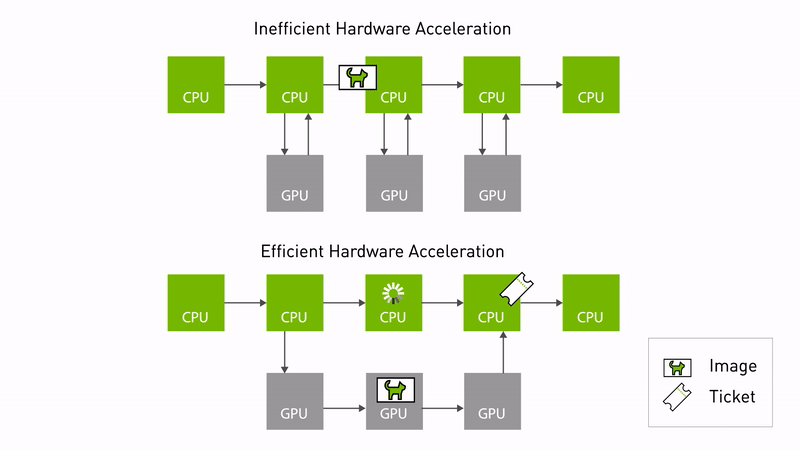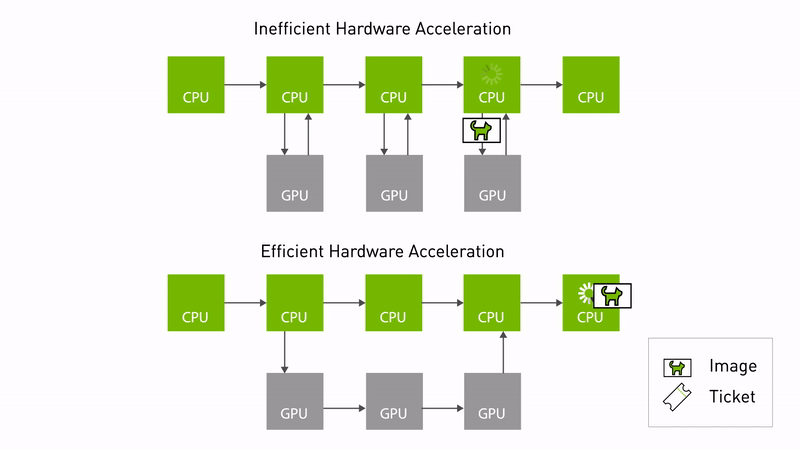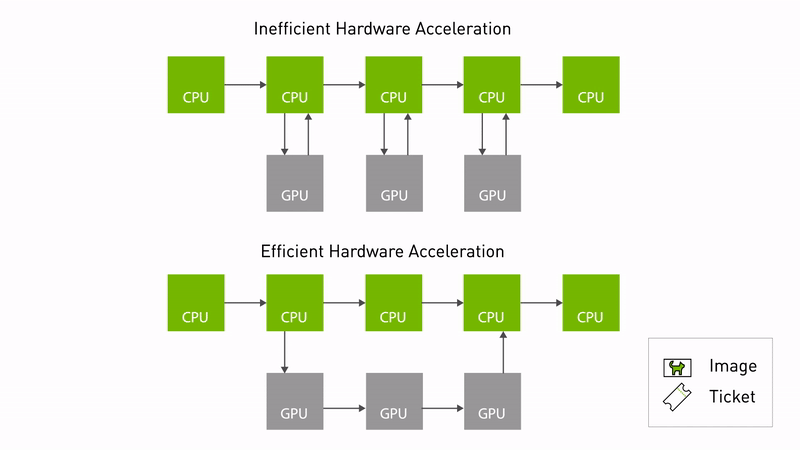


 Users can now produce 3D virtual worlds at human scale with the new Omniverse XR App available in beta from the NVIDIA Omniverse launcher.
Users can now produce 3D virtual worlds at human scale with the new Omniverse XR App available in beta from the NVIDIA Omniverse launcher.